
c++ 多线程 0
1.1 何谓并发
最简单和最基本的并发,是指两个或更多独立的活动同时发生。 (注意区别于计算机中的并发情况!!!!!!!!!!见下面)
1.1.1 计算机系统中的并发:是指在单个系统里同时执行多个独立的任务,而非顺序的进行一些活动。
通过这个任务做一会儿,在切换到别的任务,再做一会儿的方式 ,让任务看起来是并行执行的,这种方式称为“任务的切换”,如今仍然叫做 并发。
应为 任务切换的太快 以至于感觉不到任务在何时会被挂起。 任务切换会给用户造成一种“并发的假象”。因为这种假象,当应用在任务切换的环境下和真
正并发环境下执行相比,行为还是有着微妙的不同。特别是对内存模型不正确的假设,在多线程环境中可能不会出现。
图1.1显示了一个计算机处理两个任务时的理想情景,每个任务被分为10个相等大小的块。在一个双核机器上,每个任务可以在各自的处理上执行。 在单核机器上做任务切换时,每个任务的块交织进行。但中间有一小段分隔; 为实现交织进行,每次从一个任务切换到另一个时都需要切换一次上下文,切换有时间开销。切换时,操作系统必须为当前运行的任务保存CPU的状态和指令指针,计算出要切换到哪个任务,并为即将切换到的任务重新加载处理器状态。 然后,CPU可能要将新任务的指令和数据的内存载入缓存中,这会阻止CPU执行任何指令,从而造成的更多的延迟。
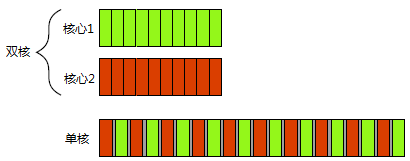
图 1.1 并发的两种方式:双核机器的真正并行 Vs. 单核机器的任务切换
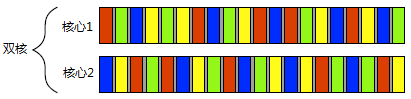
图 1.2 四个任务在两个核心之间的切换
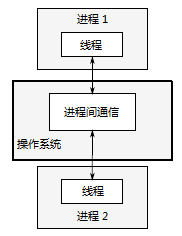
图 1.3 一对并发运行的进程之间的通信
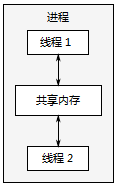
图 1.4 同一进程中的一对并发运行的线程之间的通信
清单 1.1 一个简单的Hello, Concurrent World程序:
#include <iostream>
#include <thread> //①
void hello() //②
{
std::cout << "Hello Concurrent World\n";
}
int main()
{
std::thread t(hello); //③
t.join(); //④
}
④这里调用join()的原因 这会导致调用线程(在main()中等待与std::thread对象相关联的线程,即这个例子中的t。
第2章 线程管理
主要内容
- 启动新线程
- 等待线程与分离线程
- 线程唯一标识符
2.1.1 启动线程
1 最简单的情况下,任务也会很简单,通常是无参数无返回(void-returning)的函数。这种函数在其所属线程上运行,直到函数执行完毕,线程也就结束了。
void do_some_work();
std::thread my_thread(do_some_work);
2 将带有函数调用符类型的实例传入std::thread类中,替换默认的构造函数。
class background_task{
public:
void operator()() const{ //这个类型重载了运算符()
do_something();
do_something_else();
}
};
background_task f;
std::thread my_thread(f);注意 :
当把函数对象传入到线程构造函数中时,需要避免“最令人头痛的语法解析”(C++’s most vexing parse, 中文简介)。
如果你传递了一个临时变量,而不是一个命名的变量;C++编译器会将其解析为函数声明,而不是类型对象的定义。
例如:
std::thread my_thread( background_task() );
这里相当与声明了一个名为my_thread的函数,这函数带有一个参数(函数指针指向没有参数并返回background_task对象的函数),返回一个std::thread对象的函数,而非启动了一个线程。
使用在前面命名函数对象的方式,或使用多组括号①, 或使用新统一的初始化语法②, lambda表达式也能避免这个问题 也可以避免这个问题。
如下所示:
std::thread my_thread( ( background_task() ) ); // 1
std::thread my_thread{ background_task() }; // 2==============================================================
启动了线程,你需要明确是要等待线程结束(join),还是让其自主运行(detach分离式)。
如果std::thread对象销毁之前还没有做出决定,程序就会终止(std::thread的析构函数会调用std::terminate())。
因此,即便是有异常存在,也需要确保线程能够正确的加入(joined)或分离(detached)。
清单2.1 函数已经结束,线程依旧访问局部变量
struct func{
int& i;
func( int& i_ ) : i(i_) {}
void operator() (){
for (unsigned j=0 ; j<1000000 ; ++j){
do_something(i); // 1. 潜在访问隐患:悬空引用
}
}
};
void oops(){
int some_local_state=0;
func my_func(some_local_state);
std::thread my_thread(my_func);
my_thread.detach(); // 2. 不等待线程结束
} // 3. 新线程可能还在运行
例子中,已经决定不等待线程结束(使用了detach()②),所以当oops()函数执行完成时③,新线程中的函数可能还在运行。如果线程还在运行,它就会去调用do_something(i)函数①,这时就会访问已经销毁的变量。如同一个单线程程序——允许在函数完成后继续持有局部变量的指针或引用;这种情况发生时,错误并不明显,会使多线程更容易出错。
2.1.2 等待线程完成
如果需要等待线程,相关的std::thread实例需要使用join()。清单2.1中,将my_thread.detach()替换为my_thread.join(),就可以确保局部变量在线程完成后,才被销毁。
调用join()的行为,还清理了线程相关的存储部分,这样std::thread对象将不再与已经完成的线程有任何关联。这意味着,只能对一个线程使用一次join();一旦已经使用过join(),std::thread对象就不能再次加入了,当对其使用joinable()时,将返回否(false)。
2.1.3 特殊情况下的等待
清单 2.2 等待线程完成
struct func; // 定义在清单2.1中
void f(){
int some_local_state=0;
func my_func(some_local_state);
std::thread t(my_func);
try{
do_something_in_current_thread();
}
catch(...){
t.join(); // 1
throw;
}
t.join(); // 2
}
清单2.2中 当函数正常退出时,会执行到②处;当函数执行过程中抛出异常,程序会执行到①处。try/catch块能轻易的捕获轻量级错误,所以这种情况,并非放之四海而皆准。如需确保线程在函数之前结束——查看是否因为线程函数使用了局部变量的引用,以及其他原因——而后再确定一下程序可能会退出的途径,无论正常与否,可以提供一个简洁的机制,来做解决这个问题。
一种方式是使用“资源获取即初始化方式”(RAII,Resource Acquisition Is Initialization),并且提供一个类,在析构函数中使用join(),如同下面清单中的代码。看它如何简化f()函数。
清单 2.3 使用RAII等待线程完成
class thread_guard
{
std::thread& t; //想想为什么是引用 thread_guard类设计时候!!!!
public:
explicit thread_guard( std::thread& t_ ):t(t_){ }
~thread_guard(){
if(t.joinable()) { //1
t.join(); // 2
}
}
thread_guard(thread_guard const&)=delete; // 3
thread_guard& operator=(thread_guard const&)=delete;
};
struct func; // 定义在清单2.1中
void f(){
int some_local_state=0;
func my_func(some_local_state);
std::thread t(my_func);
thread_guard g(t);
do_something_in_current_thread();
} // 4
当线程执行到④处时,局部对象就要被逆序销毁了。因此,thread_guard对象g是第一个被销毁的,这时线程在析构函数中被加入到②原始线程中。即使do_something_in_current_thread抛出一个异常,这个销毁依旧会发生。
在thread_guard的析构函数的测试中,首先判断线程是否已加入①,如果没有会调用**join()②进行加入。这很重要,因为join()**只能对给定的对象调用一次,所以对给已加入的线程再次进行加入操作时,将会导致错误。
拷贝构造函数和拷贝赋值操作被标记为=delete③,是为了不让编译器自动生成它们。直接对一个对象进行拷贝或赋值是危险的,因为这可能会弄丢已经加入的线程。通过删除声明,任何尝试给thread_guard对象赋值的操作都会引发一个编译错误。
如果不想等待线程结束,可以分离(detaching)线程,从而避免异常安全(exception-safety)问题。不过,就打破了线程与std::thread对象的联系,即使线程仍然在后台运行着,分离操作也能确保std::terminate()在std::thread对象销毁才被调用。
2.2 向线程函数传递参数
清单2.4中,向std::thread构造函数中传递一个参数很简单。需要注意的是,默认参数要拷贝到线程独立内存中,即使参数是引用的形式,也可以在新线程中进行访问。再来看一个例子:
void f(int i, std::string const& s);
std::thread t(f, 3, "hello");
代码创建了一个调用f(3, "hello")的线程。注意,函数f需要一个std::string对象作为第二个参数,但这里使用的是字符串的字面值,也就是char const *类型。之后,在线程的上下文中完成字面值向std::string对象的转化。需要特别要注意,当指向动态变量的指针作为参数传递给线程的情况,代码如下:
void f(int i,std::string const& s);
void oops(int some_param)
{
char buffer[1024]; // 1
sprintf(buffer, "%i",some_param);
std::thread t(f,3,buffer); // 2
t.detach();
}
这种情况下,buffer②是一个指针变量,指向本地变量,然后本地变量通过buffer传递到新线程中②。并且,函数有很有可能会在字面值转化成std::string对象之前崩溃(oops),从而导致一些未定义的行为。并且想要依赖隐式转换将字面值转换为函数期待的std::string对象,但因std::thread的构造函数会复制提供的变量,就只复制了没有转换成期望类型的字符串字面值。
解决方案就是在传递到std::thread构造函数之前就将字面值转化为std::string对象:
void f(int i,std::string const& s);
void not_oops(int some_param){
char buffer[1024];
sprintf(buffer,"%i",some_param);
std::thread t(f,3,std::string(buffer) ); // 使用std::string,避免悬垂指针
t.detach();
}
不过,也有成功的情况:复制一个引用。在线程更新数据结构时,会成功的传递一个引用:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
提供的参数可以"移动"(move),但不能"拷贝"(copy)。"移动"是指:原始对象中的数据转移给另一对象,而转移的这些数据就不再在原始对象中保存了。std::unique_ptr就是这样一种类型,这种类型为动态分配的对象提供内存自动管理机制。移动构造函数(move constructor)和移动赋值操作符(move assignment operator)允许一个对象在多个std::unique_ptr实现中传递。使用"移动"转移原对象后,就会留下一个空指针(NULL)。移动操作可以将对象转换成可接受的类型,例如:函数参数或函数返回的类型。当原对象是一个临时变量时,自动进行移动操作,但当原对象是一个命名变量,那么转移的时候就需要使用std::move()进行显示移动。下面展示std::move是如何转移一个动态对象到一个线程中去的:
void process_big_object(std::unique_ptr<big_object>);
std::unique_ptr<big_object> p(new big_object);
p->prepare_data(42);
std::thread t(process_big_object,std::move(p));
在std::thread的构造函数中指定std::move(p),big_object对象的所有权就被首先转移到新创建线程的的内部存储中,之后传递给process_big_object函数。
标准线程库中和std::unique_ptr在所属权上有相似语义类型的类有好几种,std::thread为其中之一。虽然,std::thread实例不像std::unique_ptr那样能占有一个动态对象的所有权,但是它能占有其他资源:每个实例都负责管理一个执行线程。执行线程的所有权可以在多个std::thread实例中互相转移,这是依赖于std::thread实例的可移动(movable)且不可复制(aren't copyable)性。不可复制保性证了在同一时间点,一个std::thread实例只能关联一个执行线程;可移动性使得程序员可以自己决定,哪个实例拥有实际执行线程的所有权。
2.3 转移线程所有权
假设要写一个在后台启动线程的函数,想通过新线程返回的所有权去调用这个函数,而不是等待线程结束再去调用;或完全与之相反的想法:创建一个线程,并在函数中转移所有权,都必须要等待线程结束。总之,新线程的所有权都需要转移。
这就是移动引入std::thread的原因,C++标准库中有很多资源占有(resource-owning)类型,比如std::ifstream,std::unique_ptr还有std::thread都是可移动(movable),但不可拷贝(not cpoyable)。
void some_function();
void some_other_function();
std::thread t1(some_function); // 1
std::thread t2=std::move(t1); //②
t1=std::thread(some_other_function);//③为什么不显式调用std::move()转移所有权呢?因为,所有者是一个临时对象——移动操作将会隐式的调用。明白了吧!!!!
std::thread t3; // ④ t3使用默认构造方式创建 ④,与任何执行线程都没有关联
t3=std::move(t2); // ⑤ ⑤完成后,t1与执行some_other_function的线程相关联,t2与任何线程都无关联,t3与执行some_function的线程相关联。
t1=std::move(t3); // 6 赋值操作将使程序崩溃
当显式使用std::move()创建t2后 ②,t1的所有权就转移给了t2。之后,t1和执行线程已经没有关联了;执行some_function的函数现在与t2关联。
调用std::move()将与t2关联线程的所有权转移到t3中⑤。因为t2是一个命名对象,需要显式的调用std::move()。
最后一个移动操作,将some_function线程的所有权转移⑥给t1。不过,t1已经有了一个关联的线程(执行some_other_function的线程),所以这里系统直接调用std::terminate()终止程序继续运行。终止操作将调用std::thread的析构函数,销毁所有对象。需要在线程对象被析构前,显式的等待线程完成,或者分离它;进行复制时也需要满足这些条件(说明:不能通过赋一个新值给std::thread对象的方式来"丢弃"一个线程)。


