实验一 感知器及其应用
| 博客班级 | https://edu.cnblogs.com/campus/ahgc/machinelearning |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/ahgc/machinelearning/homework/11950 |
| 作业目标 | 理解感知器算法原理,能实现感知器算法 |
| 学号 | 3180701329 |
实验一 感知器及其应用
【实验目的】
-
理解感知器算法原理,能实现感知器算法;
-
掌握机器学习算法的度量指标;
-
掌握最小二乘法进行参数估计基本原理;
-
针对特定应用场景及数据,能构建感知器模型并进行预测。
【实验内容】
-
安装Pycharm,注册学生版。
-
安装常见的机器学习库,如Scipy、Numpy、Pandas、Matplotlib,sklearn等。
-
编程实现感知器算法。
-
熟悉iris数据集,并能使用感知器算法对该数据集构建模型并应用。
【实验报告要求】
-
按实验内容撰写实验过程;
-
报告中涉及到的代码,每一行需要有详细的注释;
-
按自己的理解重新组织,禁止粘贴复制实验内容!
【实验过程】
二分类模型:
𝑓(𝑥) = 𝑠𝑖𝑔𝑛(𝑤 ∗ 𝑥 + 𝑏)
损失函数:
𝐿(𝑤, 𝑏) = −Σ𝑦𝑖(𝑤 ∗ 𝑥𝑖 + 𝑏)
算法
随即梯度下降法 Stochastic Gradient Descent
随机抽取一个误分类点使其梯度下降。
𝑤 = 𝑤 + 𝜂𝑦𝑖𝑥𝑖
𝑏 = 𝑏 + 𝜂𝑦
当实例点被误分类,即位于分离超平面的错误侧,则调整w, b的值,使分离超平面向该无分类点的一侧移动,直至误分类点被正确分类
拿出iris数据集中两个分类的数据和[sepal length,sepal width]作为特征
In[1]:
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
%matplotlib inline
In[2]:
# 导入数据
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)//将列名设置为特征
df['label'] = iris.target//增加一列为类别标签
In[3]:
#选择其中的4个特征进行训练
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']//将各个列重命名
df.label.value_counts()//确认数据出现的频率
Out[3]:

In[4]:
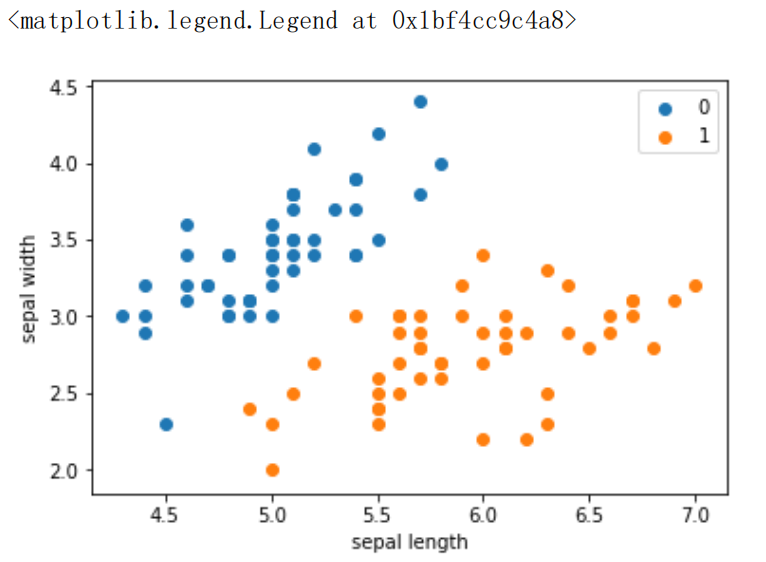
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')//绘制散点图
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.xlabel('sepal length')//给图加上图例
plt.ylabel('sepal width')
plt.legend()
Out[4]:
In[5]:
# 取前100条数据,为了方便展示,取2个特征
# 首先数据类型转换,为了后面的数学计算
data = np.array(df.iloc[:100, [0, 1, -1]])//按行索引,取出第0,1,-1列
In[6]:
X, y = data[:,:-1], data[:,-1]//X为sepal length,sepal width y为标签
In[7]:
y = np.array([1 if i == 1 else -1 for i in y])//将两个类别设重新设置为+1 —1
In[8]:
# 数据线性可分,二分类数据
# 此处为一元一次线性方程
class Model:
def __init__(self)://将参数w1,w2置为1 b置为0 学习率为0.1
self.w = np.ones(len(data[0])-1, dtype=np.float32) //data[0]为第一行的数据len(data[0]=3)这里取两个w权重参数
self.b = 0
self.l_rate = 0.1
# self.data = data
def sign(self, x, w, b):
y = np.dot(x, w) + b
return y
# 随机梯度下降法
def fit(self, X_train, y_train)://拟合训练数据求w和b
is_wrong = False//判断是否误分类
while not is_wrong:
wrong_count = 0
for d in range(len(X_train))://取出样例,不断的迭代
X = X_train[d]
y = y_train[d]
if y * self.sign(X, self.w, self.b) <= 0://根据错误的样本点不断的更新和迭代w和b的值(根据相乘结果是否为负来判断是否出错,本题将0也归为错误)
self.w = self.w + self.l_rate*np.dot(y, X)
self.b = self.b + self.l_rate*y
wrong_count += 1
if wrong_count == 0://直到误分类点为0 跳出循环
is_wrong = True
return 'Perceptron Model!'
def score(self):
pass
In[9]:
# 拟合
perceptron = Model()
perceptron.fit(X, y)
Out[9]:
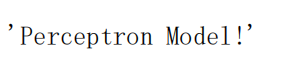
In[10]:
# 画出图形
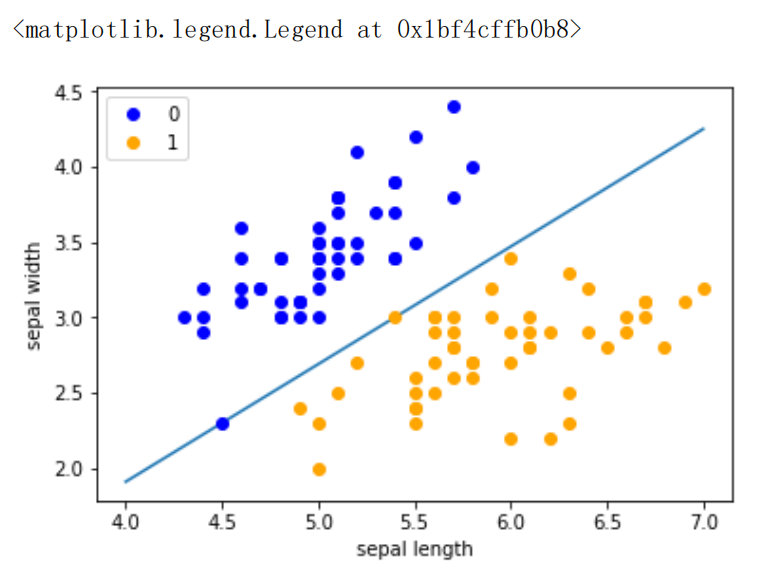
x_points = np.linspace(4, 7,10)//x轴的划分
y_ = -(perceptron.w[0]*x_points + perceptron.b)/perceptron.w[1]//绘制模型图像(数据、颜色、图例等信息)
plt.plot(x_points, y_)
plt.plot(data[:50, 0], data[:50, 1], 'bo', color='blue', label='0')
plt.plot(data[50:100, 0], data[50:100, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
Out[10]:
In[11]:
from sklearn.linear_model import Perceptron//定义感知机(下面将使用感知机)
In[13]:
clf = Perceptron(fit_intercept=False, max_iter=1000, shuffle=False)
clf.fit(X, y)//使用训练数据拟合
Out[13]:

In[14]:
# Weights assigned to the features.
print(clf.coef_)//输出感知机模型参数
In[15]:
# 截距 Constants in decision function.
print(clf.intercept_)//输出感知机模型参数
In[16]:
x_ponits = np.arange(4, 8)//确定x轴和y轴的值
y_ = -(clf.coef_[0][0]*x_ponits + clf.intercept_)/clf.coef_[0][1]
plt.plot(x_ponits, y_)//确定拟合的图像的具体信息(数据点,线,大小,粗细颜色等内容)
plt.plot(data[:50, 0], data[:50, 1], 'bo', color='blue', label='0')
plt.plot(data[50:100, 0], data[50:100, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
Out[16]:

【实验小结】
通过此次实验我理解了感知器算法的原理,能够基本实现感知器算法;掌握了机器学习算法的度量指标以及最小二乘法进行参数估计基本原理;学会了针对特定应用场景及数据来构建感知器模型并进行预测。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号