Spark官方自带了WordCount的样例,我们也可以自己实现,加深对Spark的理解。
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "D:/winutils/")
// 创建Spark配置,运行环境
val sparkConf = new SparkConf()
sparkConf.setAppName("WordCount")
sparkConf.setMaster("local")
// 创建Spark上下文对象
val sparkContext = new SparkContext(sparkConf)
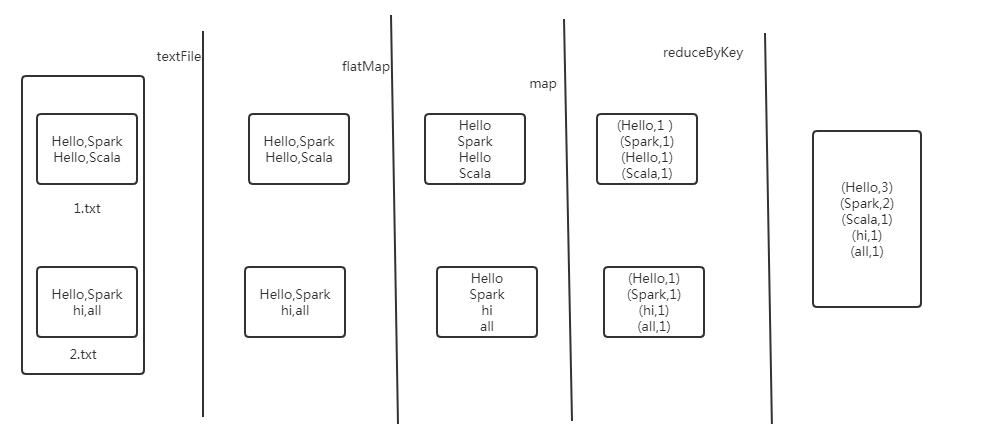
// 从文件逐行读取到rdd
val rdd = sparkContext.textFile("input/WordCountInput")
// 将每一行内容分解为一个一个的单词
val words = rdd.flatMap(line => line.split(","))
// 转换数据结果并进行统计
val count = words.map(word => (word, 1)).reduceByKey(_+_)
count.foreach(println(_))
}
}
每一步中Spark的操作如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号