通常当我们计算的数据超过了单机维度,比如我们的PC内存共8G,而需要计算的数据为100G,这时候我们通常选择大数据集群进行计算。
Spark是大数据处理的计算引擎。,这是它的发展是为了解决替代Hadoop的MapReduce计算引擎。
Hadoop的架构如下,核心包括两点:Hdfs和MapReduce。
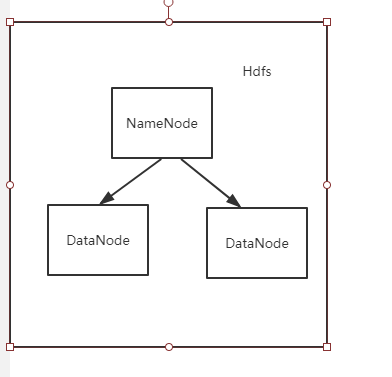
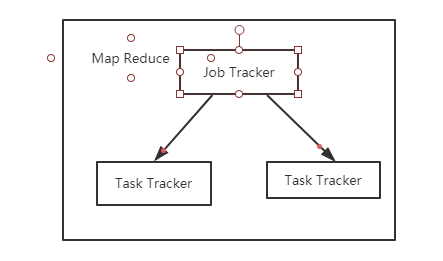
MapReduce的操作流程是 从存储介质读取数据 -》清洗计算 -》持久化到存储介质中。
这样的架构存在两个问题:
(1)不合适流式数据处理、机器学习及图挖掘等场景。
(2)数据持久化到磁盘中,I/O速度慢。
下面是Spark的架构及生态:
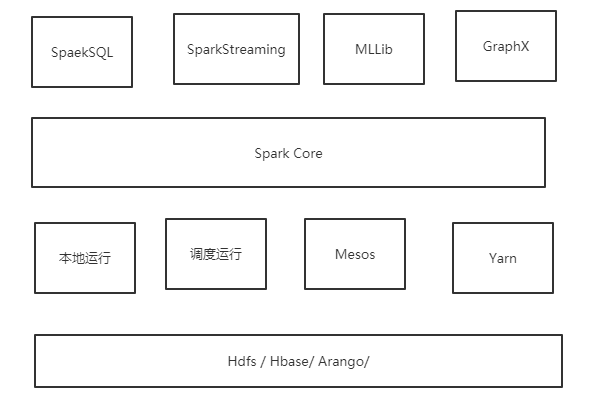
(1)SparkSQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作
(2)SparkStreaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据
(3)MLLib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
(4)GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
(5)Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的
(6) 本地运行模式(Local)应用程序程序运行在一台计算机,多用于本地测试及练习。
Spark组成如图:
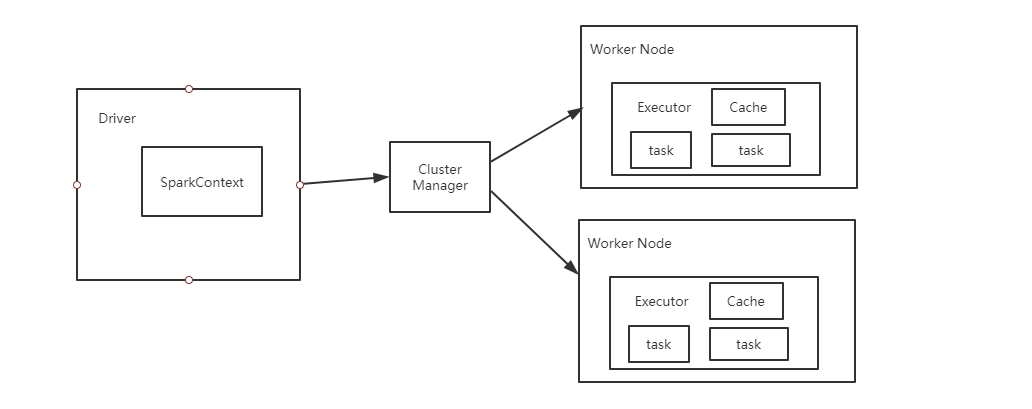
(1) Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器。
(2) Driver: 运行Application 的main()函数。
(3)Executor:执行器,是为某个Application运行在worker node上的一个进程
(4)Task:执行具体计算的线程。
Spark本身并没有分布式存储系统,因此Spark的分析数据来源大多来自Hadoop的分布式文件系统Hdfs。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号