
《利用Python 进行数据分析 第二版》 -第10章 数据聚合与分组操作
本章重点内容:
1、GroupBy机制
2、数据聚合
3、数据透视表与交叉表
接下来展开详细说明
1、GroupBy机制
数据分类汇整,根据不同的分类进行不同的操作是经常会用到的功能,所以如何分组分类就是一个比较重要的过程
pandas提供一个灵活的groupby接口,允许你以一种自然的方式对数据进行切片、切块和总结
通过文字描述比较难理解,我们可以看一个具体的例子,
首先,我们看一个简单的数据,如下:
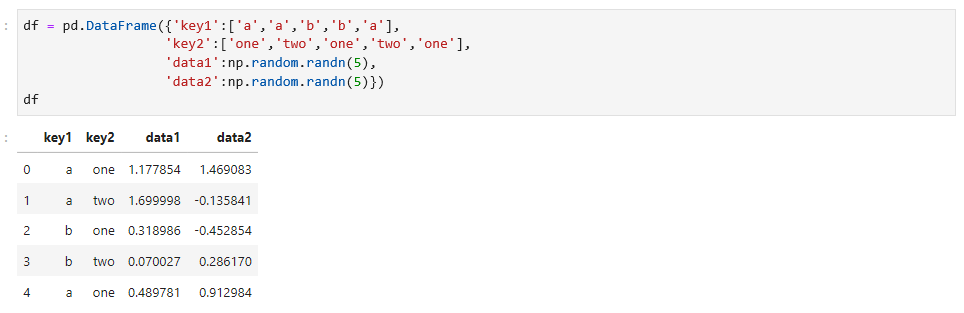
对于这个数据,你想通过key1,计算data1列的均值,可以通过groupby方法实现,如下:

示例中的grouped是聚类好的对象,可以对其进行不同的操作
可以根据多个纬度进行分类,求平均值,如下:
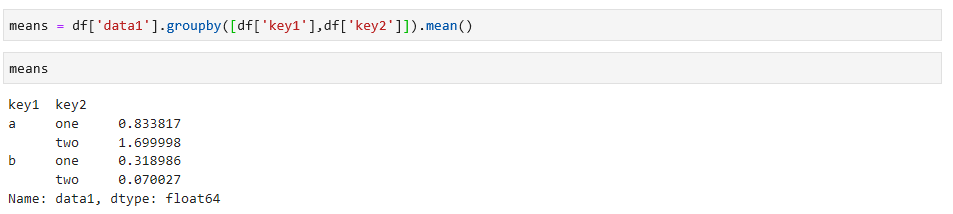
对于DataFrame类型数据,如果分组的依据是列,可以通过传递列名即可,会更简单易懂,如下:
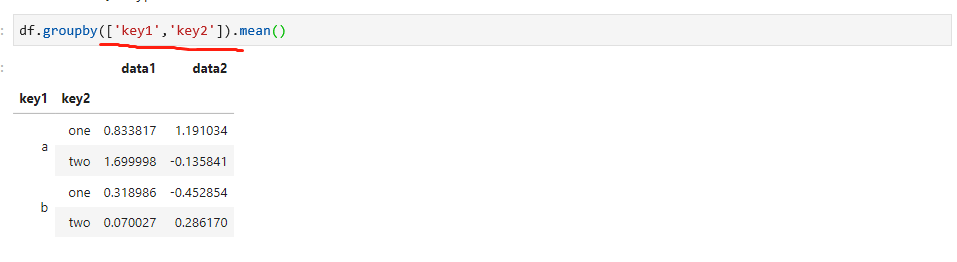
在这里要特别提醒一个地方,就是如果是根据多个纬度来分组,groupby中传递的参数,需要是一个数组形式,也就是需要用中括号
groupby有一个size属性,可以查看分组后信息的大小,如下:

GroupBy对象支持迭代,会生成一个包含组名和数据块的2维元组序列,例如看下如下代码,如果根据key1分组,那分组后的内容是什么?
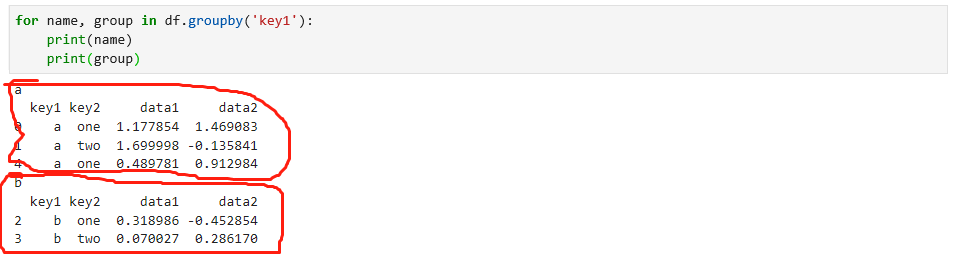
如果是多个纬度分组,会以第一个参数为键值,如下:

通过查看GroupBy对象的格式,我们会发现,有不同列的数据,所以在分组后,还可以选择一列或者所有列的子集,如下示例:

上面的代码,首先是通过key1、key2进行分组,分组后选择“data2”列的数据,计算平均值
2、数据聚合
聚合是指所有根据数组产生标量值得数据转换过程,之前的例子中已经使用了一些聚合操作,例如mean
groupby方法中有很多默认常用的聚合函数,例如sum、count、min等,也可以自定义聚合方法
如果是自定义聚合的方法,需要将函数传递给aggregate或agg方法,代码示例如下:
还是用以下数据集作为操作的示例:
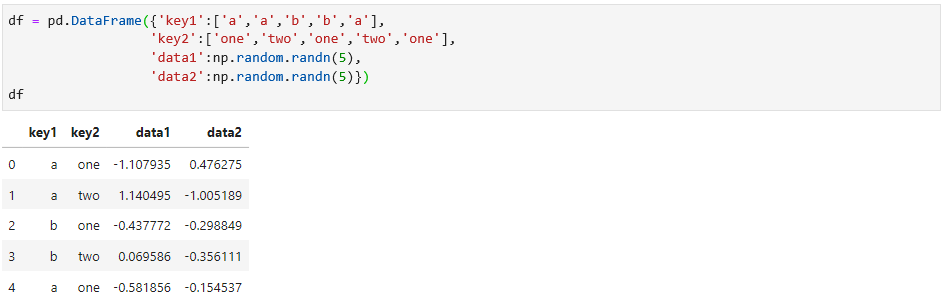
首先将该数据集用key1进行分组,操作如下:

然后我们自定义一个函数,如下:

我们把自定义的函数,用在我们已经分组的数据中,结果如下:

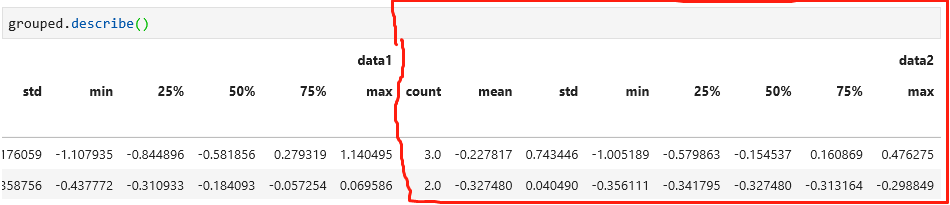
groupby对象有一个describe方法,虽然不是聚合函数,但是也能看到很多经常用到的聚合方法结果,如下:

3、数据透视表与交叉表
数据透视表是电子表格程序和其图数据分析软件中常见的数据汇总工具,除了上面提到的GroupBy机制,DataFrame拥有一个pivot_table方法,可以实现数据透视
看一个例子,还是以上面的df数据为例:
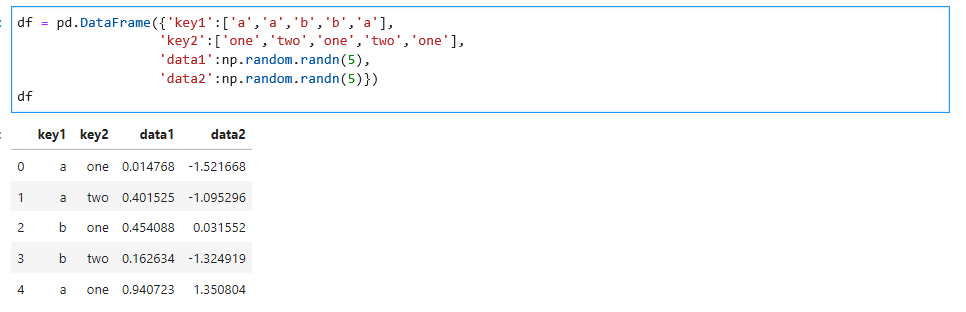
对上面的数据计算一张在行方向上按key1和key2排列的分组平均值得表,如下:
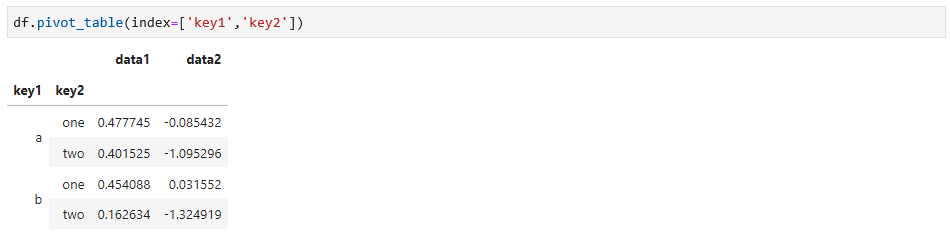
和之前使用Groupby实现的一样,这个方法,还可以有更多的功能,
如果我们只想聚合data1,根据key1分组,把key2放入表的列,如下:

通过这个数据,你会感觉到,有数据透视的处理逻辑了
交叉表是数据透视表的一个特殊情况,计算的是分组中的频率,可以通过pandas.crosstable函数更方便的实现,还是以上面的df数据为例,如下:
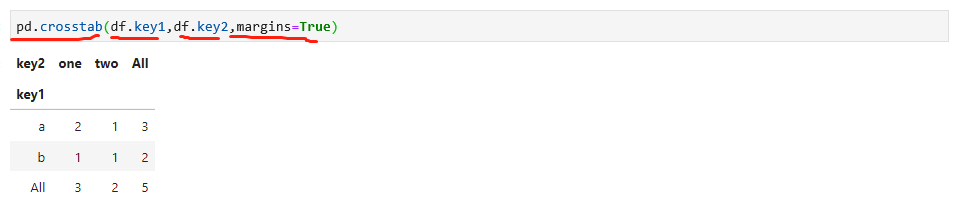
在此要特别说明,其中pd是pandas的别名,在导入的时候已经调整,所以读者要明白pd是什么,在本书中,作者默认采用以下别名,请特别注意

以上就是本章重点内容,祝学习愉快
以下链接,可以供你了解这个系列学习笔记的所有章节最新进度
