


《利用Python 进行数据分析 第二版》 -第8章 数据规整:连接、联合与重塑
本章重点内容:
1、分层索引
2、联合与合并数据集
3、重塑和透视
接下来分别详细说明
1、分层索引
分层索引是pandas的重要特性,先看一个分层结构的数据,如下:
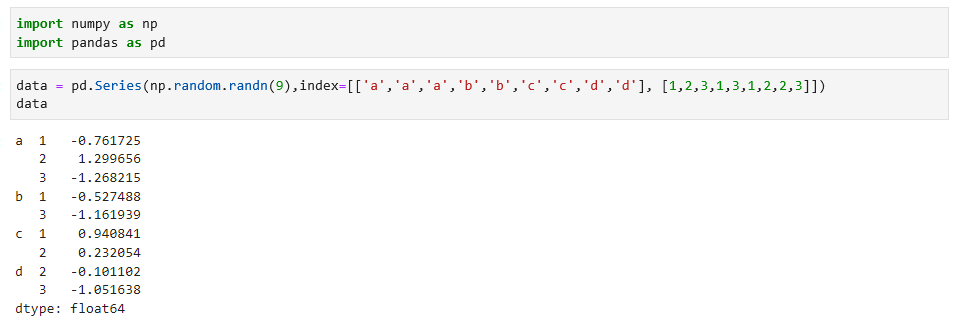
通过分层索引,可以简洁的选择出数据的子集,如下:

既然是分层索引,不仅仅局限在外层索引,还可以通过”内层“进行选择,如下:

分层索引的数据,可以通过unstack函数进行重新排列,如下:
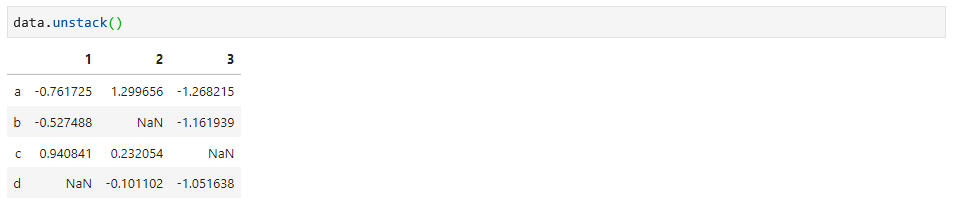
当然,也可以通过stack函数进行反向操作,如下:
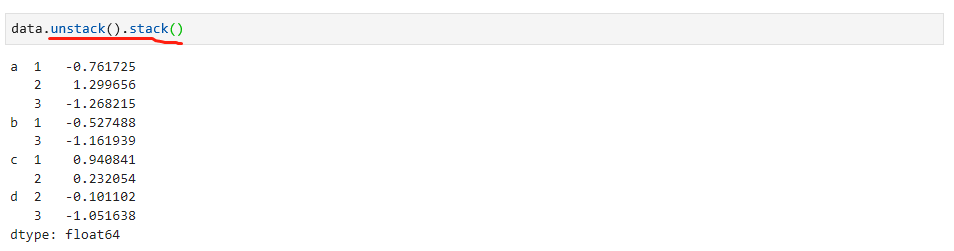
上面的数据案例是Series类型,DataFrame数据对象也是可以的,而且每个轴都可以拥有分层索引,看一个DataFrame的数据,如下:
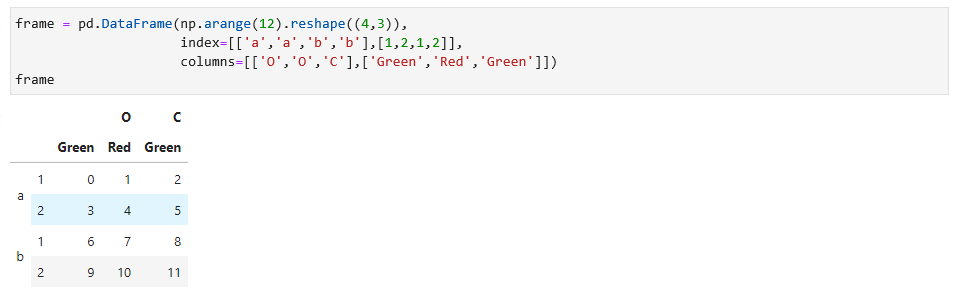
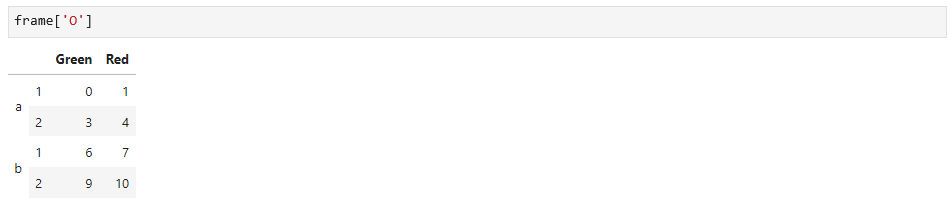
分层索引可以选择不同的列,如下:
2、联合与合并数据集
数据库风格的DataFrame连接
合并或连接操作通过一个或多个键连接行来联合数据集,pandas中的merge函数主要用于将各种join操作算法运用在数据上
先看两个数据:
数据1:

数据2:
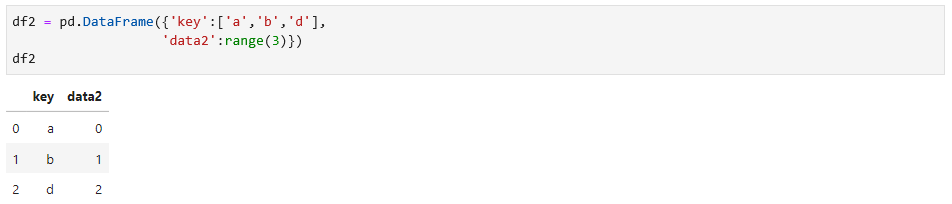
这两个数据有共同的列”key“,所以如果把这两个数据连接在一起,就可以使用merge函数,如下:
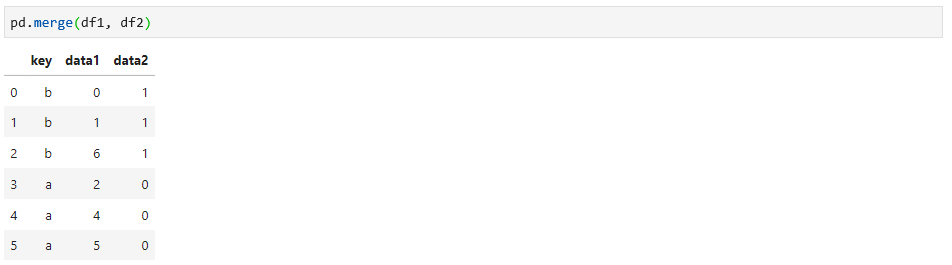
如果没有指定连接的列,merge函数会自动寻找两个数据中相同的列来进行连接,当然,你也可以通过指定列来连接,这是更显示的方式,如下:
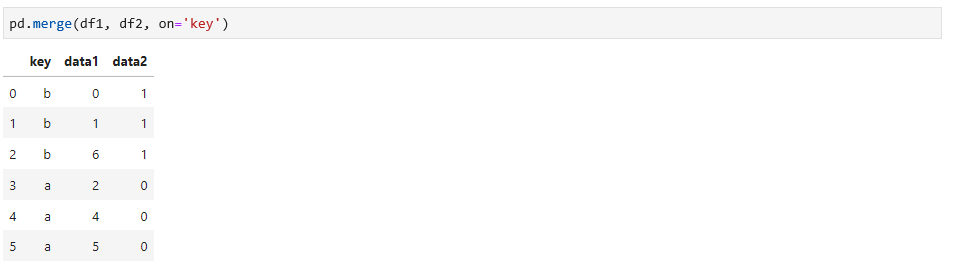
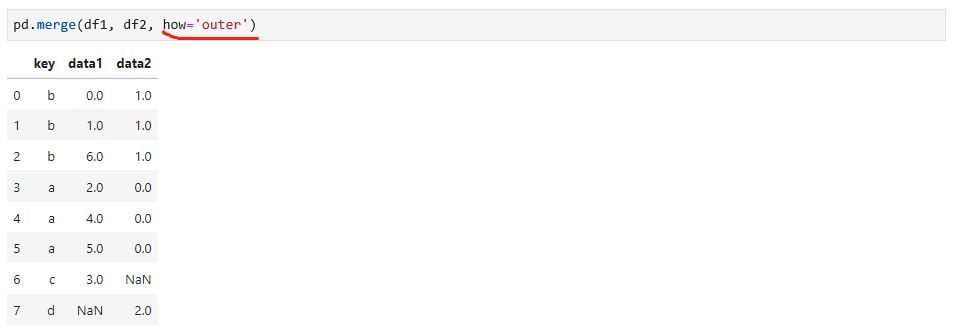
从结果你会发现,没有c和d的数据,merge函数默认情况下做的是内连接,也就是两个数据的交集,可以调整参数选择不同的连接方式,如下:
沿轴向连接
另一种数据组合操称为拼接,NumPy的concatenate函数可以实现该功能,如下:
先看一个数组数据:

如果想在每行都重复一次数据数据,可以通过拼接实现,如下:

在pandas中有一个concat函数能实现更多的功能,如下:
可以连接Series类型数据

通过concat函数可以直接拼接在一起,如下:

concat实现的功能是拼接,和前面讲过的merge函数不一样,如果对同样的数据,使用concat函数,你就发现他们两个的差异,如下:
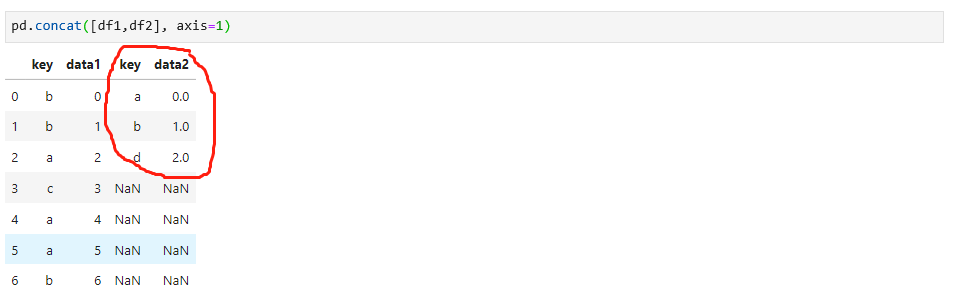
只是把两个数据拼接在一起,没有对应关系
3、重塑和透视
在调整数据的时候,需要”长“和”宽“之间转换,这个时候可以使用pivot和melt两个函数
首先看一个数据,如下:
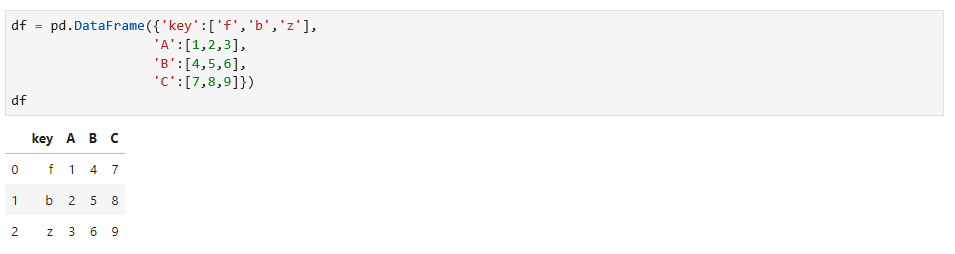
针对这个数据,可以用key作为分组指标,melt函数会进行转换,如下:
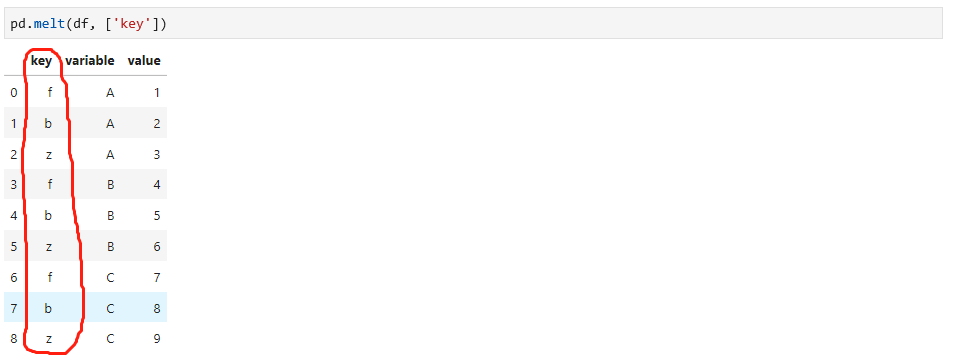
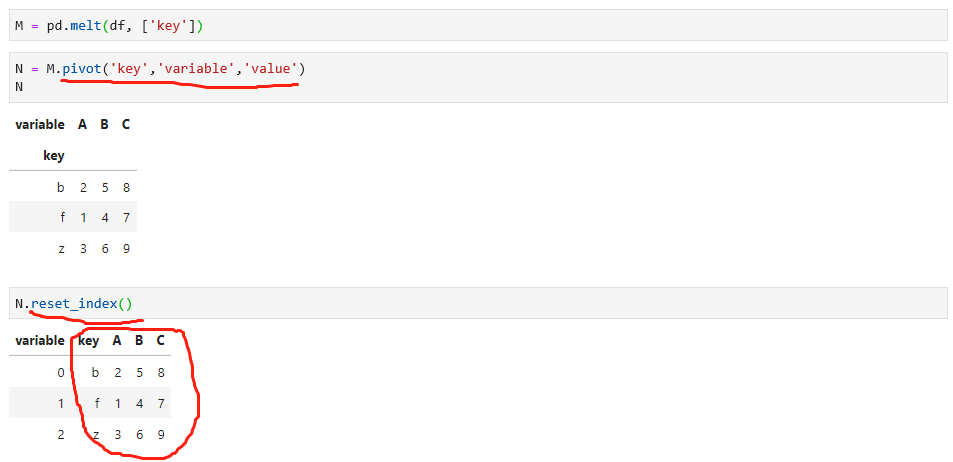
pivot函数是melt函数的反向操作,可以将数据恢复原样,如下:
以上就是本章重点内容,祝学习愉快
以下链接,可以供你了解这个系列学习笔记的所有章节最新进度
自学笔记系列:《利用Python 进行数据分析 第二版》 -写在开始之前

