SSD
复现内容
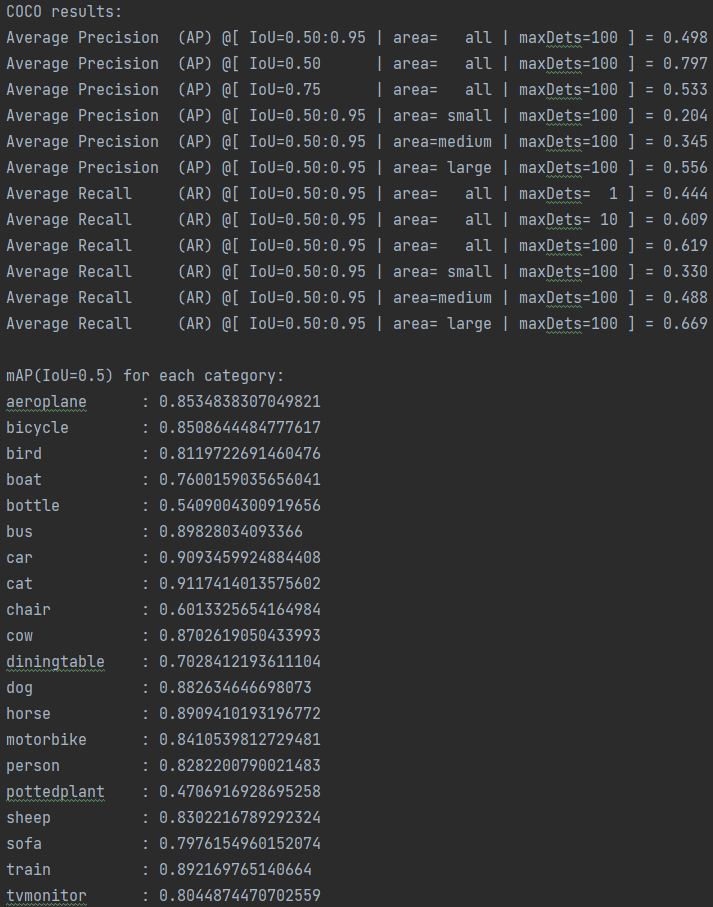
SSD论文在PASCAL VOC2007 test detection results的SSD300的前两行
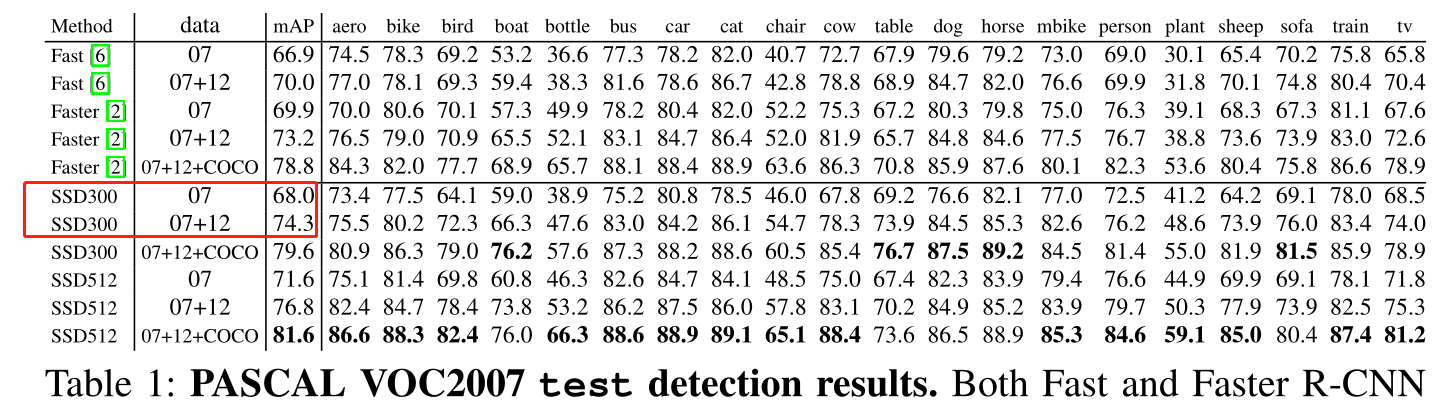
不过在论文SSD用的是VGG作为backbone,而我所用代码的backbone则是resnet50,其他方便我尽量与论文一致
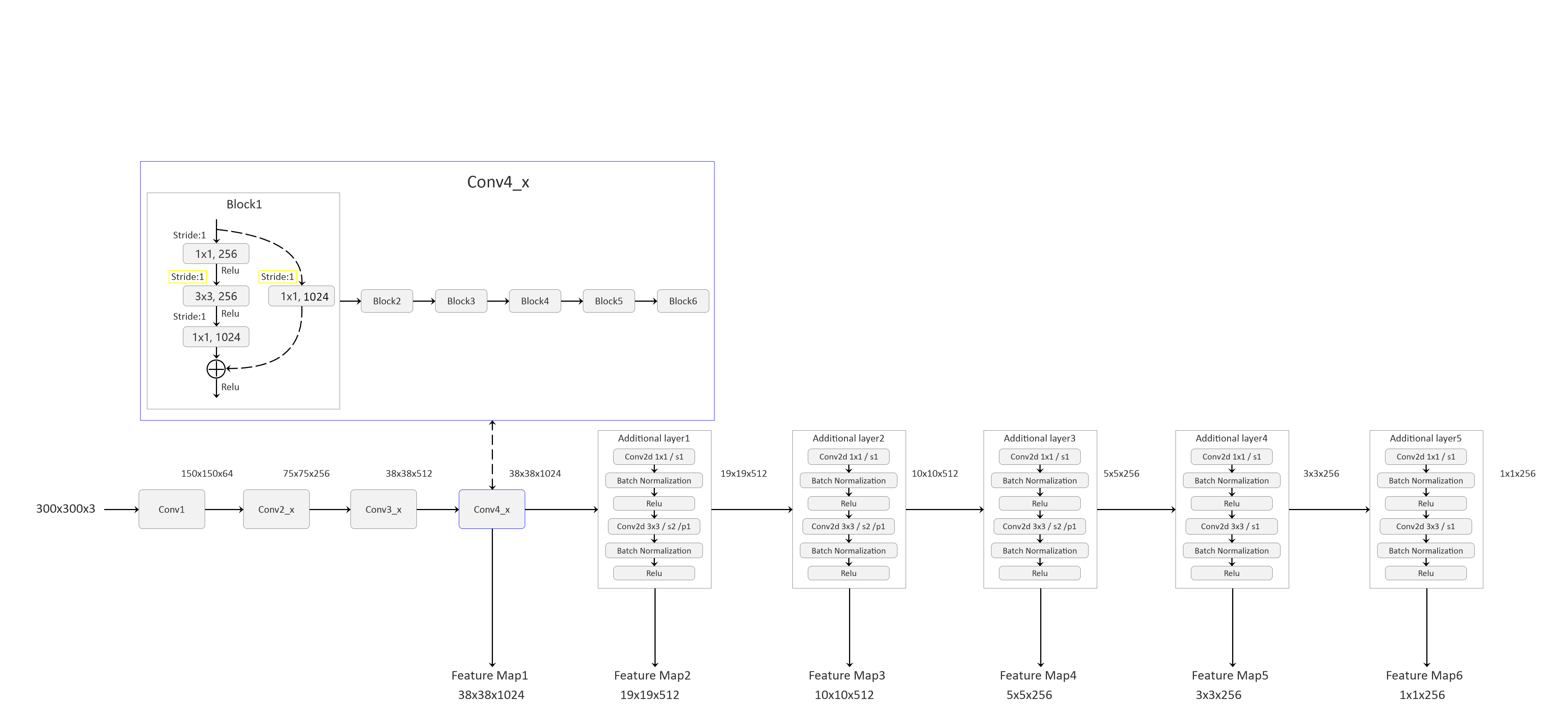
SSD框架结构
1 SSD代码采用resnet50(论文中是VGG),到conv4_x后面都丢弃 2 且在conv4_x中block1讲步距改为1,后面的block没有改动 3 在后面的添加层中加了bn层 4 利用nvidia的DALI包,来将图像预处理过程移至GPU中 5 利用混合精度可以加快训练,float16代替float32
复现结果
1 total param num 15,597,998 2 backbone: Resnet50 3 优化器:optimizer = torch.optim.SGD(params, lr=0.001, momentum=0.9, weight_decay=1e-4) 4 学习率每几epoch更新一次lr-step-size=5,每次为上次的几倍,gamma=0.3 5 损失函数=类别损失:nn.CrossEntropyLoss()+边界框损失nn.SmoothL1Loss() 6 batch=8/多GPU每块batch=2 7 加载完整预训练权重使用nvidia官方训练的
8 epoch = 30 9 每epoch,train:1m24s,test:,total:1h4m30s | 多GPU,train:1m53s,test:50s,total:1h28m37s | total:1h59m36s
10 训练集:PASCALVOC-2007trainval(5012)/2007trainval+2012trainval(16551) | 2012train(5717)
11 测试集:PASCALVOC-2007test(4952) || 2012val(5823)
12 GPU: NVIDIA GeForce RTX 3070ti(8G) | 4 x Tesla V100(32G) | 1x Tesla V100(32G)
13 推理时间:0.0112s,89fps
07
训练集:PASCALVOC-2007trainval(5012)
测试集:PASCALVOC-2007test(4952)
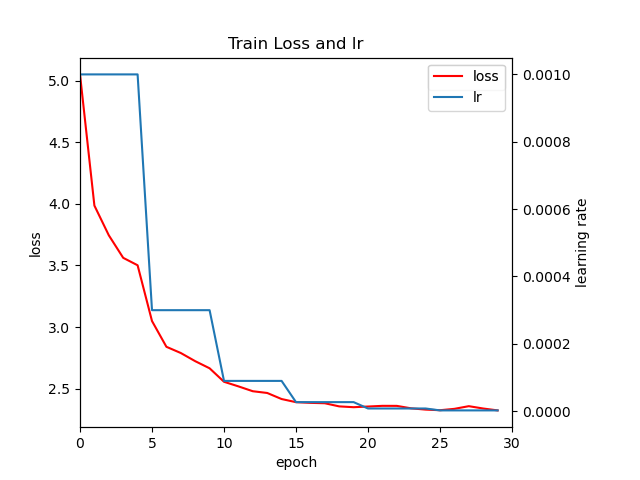
loss,lr随epoch变化图
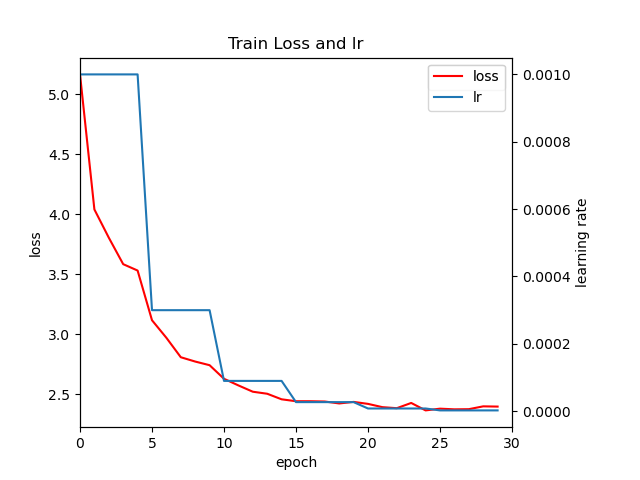
IOU为0.5的map,大概在76%左右
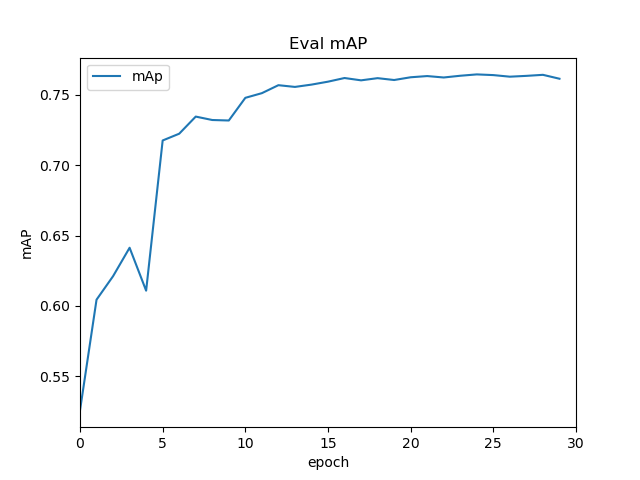
加载训练后的权重,在测试集(2007test)上对模型进行验证
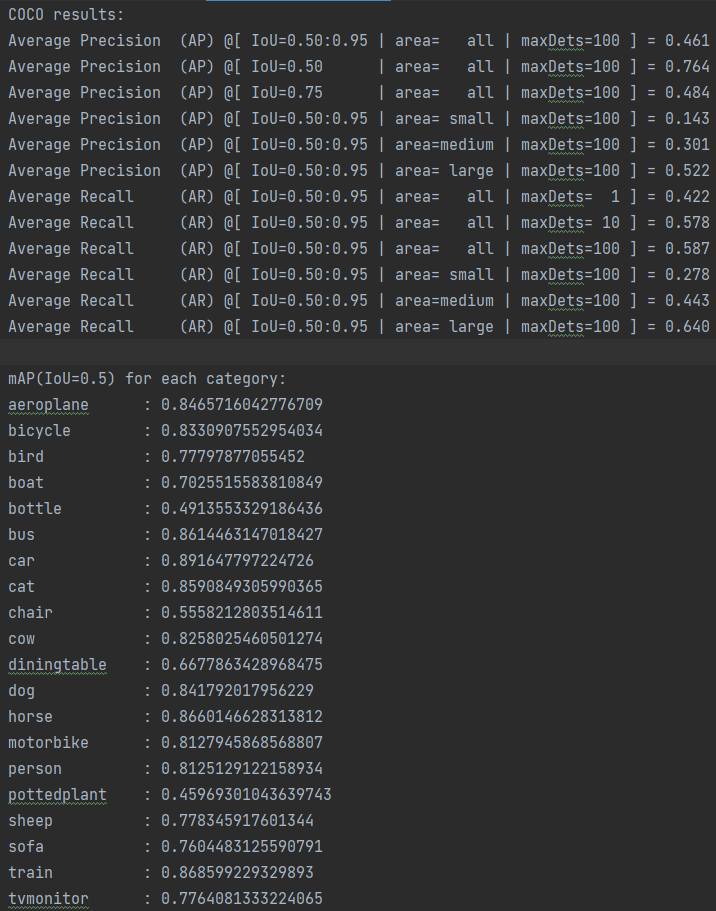
07+12
训练集:2007trainval+2012trainval(16551)
测试集:PASCALVOC-2007test(4952)
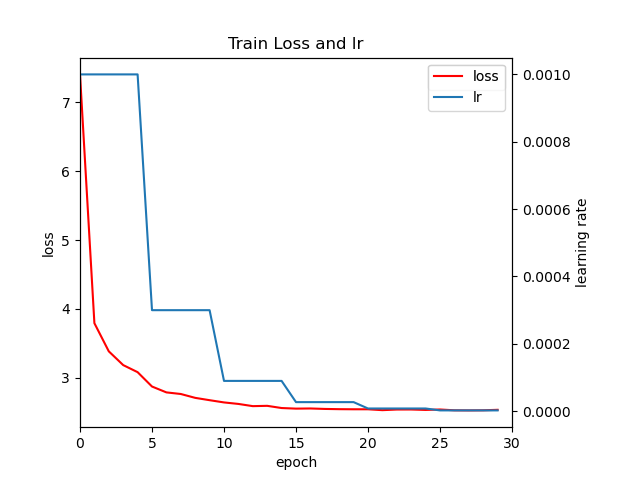
loss,lr随epoch变化图
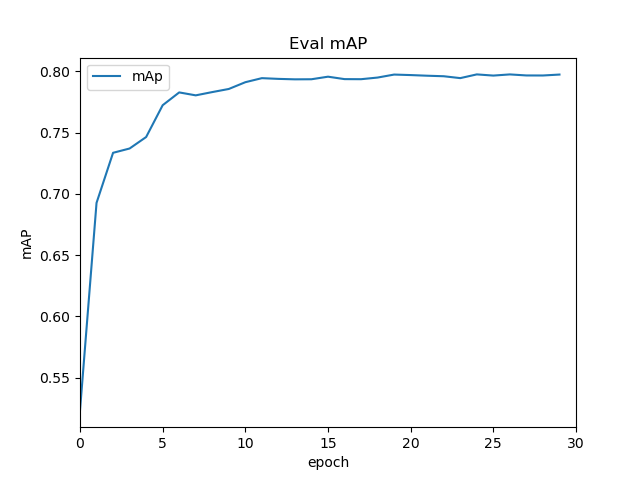
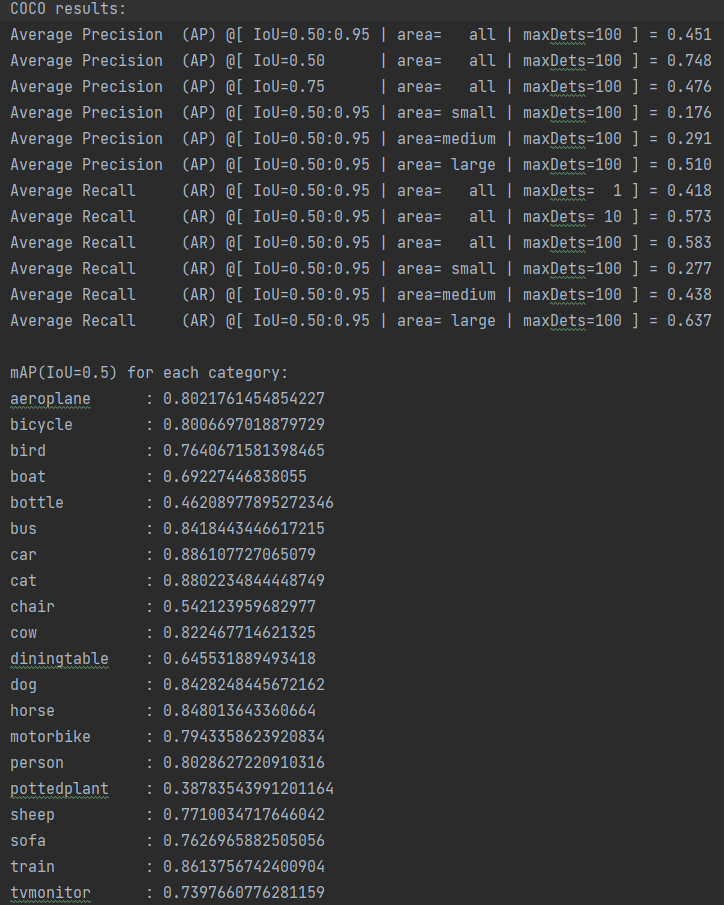
IOU为0.5的map,大概在79.6%左右
加载训练后的权重,在测试集(2007test)上对模型进行验证
07与07+12对比
利用wandb记录模型的训练过程,不同数据集的loss、mAP(IOU=0.5)对比

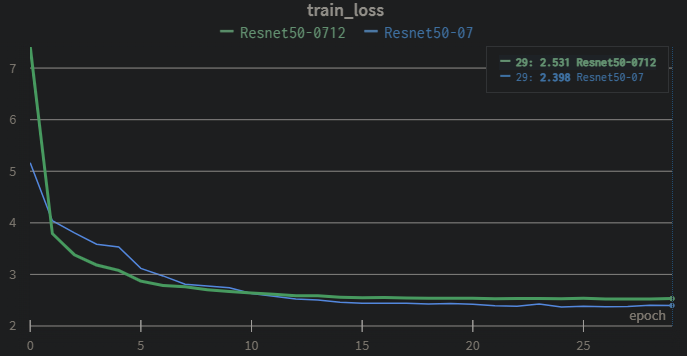
可以得出结论:更多的训练集,可以让模型达到更好的效果,相比论文的VGGbackbone,能看出resnet50作为backbone的效果更好,
论文给出以07trainval作为训练集,test作为测试集的mAP结果:论文68%,实验76%,而用07+12作为训练集在07test集上结果:论文74.3,实验79%
12

不知道为什么SSD的loss相比faster rcnn显的很大,最后模型收敛后还有2.5的loss
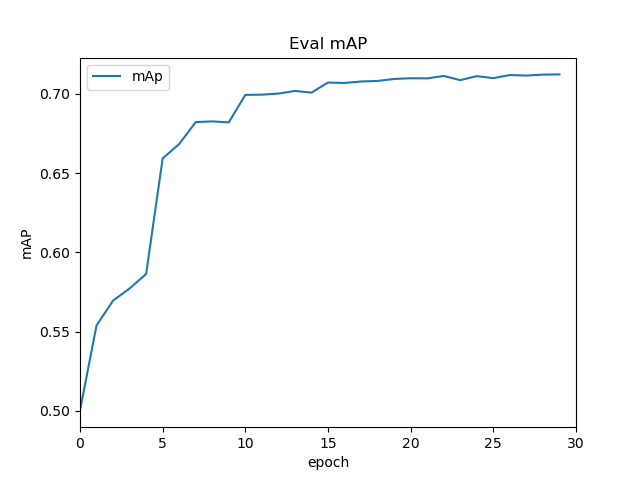
三个不同数据集进行对比
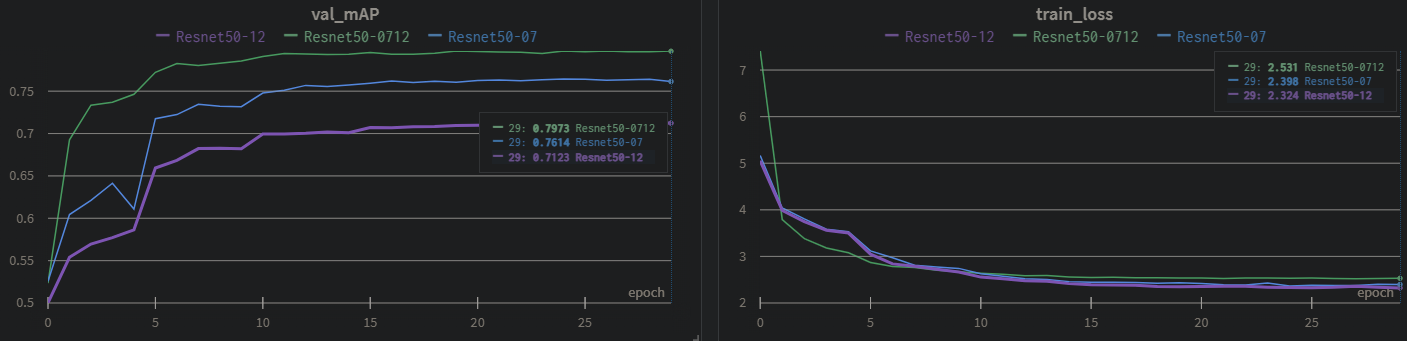
不过这里12 的测试集用的是12val,可能做不了对比,必须再在07的test上进行测试一遍,因此博主又利用12train训练的权重在07test上测试了
发现iou0.5接近75%,还是比07(trainval)少,
不过能得出的一个结论是:数据越多越好的,比如用07+12(trainval),在07test上可以得到很好结果
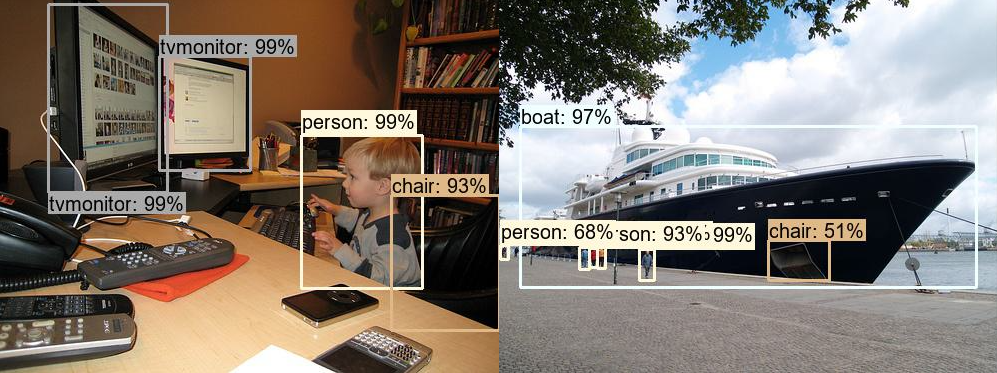
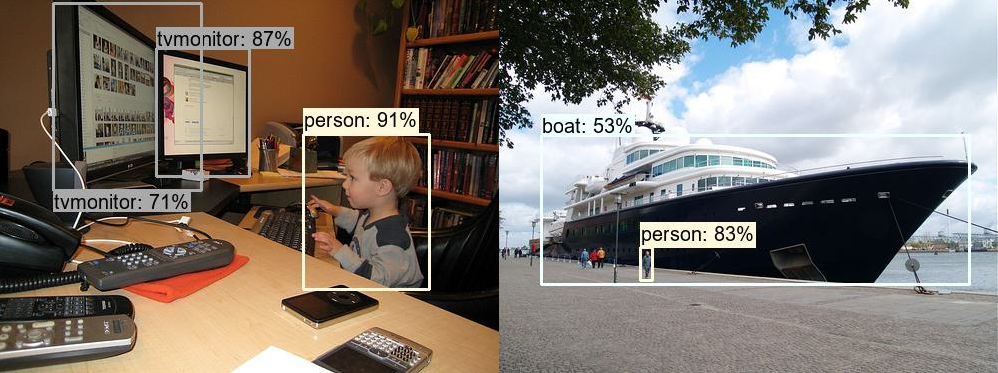
预测结果展示
即使是使用了07+12的训练集,最后的随机选择2张图片的预测结果,相比faster r-cnn(以resnet50-fpn为backbone)来说,感觉效果还是差了点,特别是小目标的检测效果
SSD,07+12为训练集的权重预测结果
faster r-cnn(以resnet50-fpn为backbone)