Hash学习笔记
@
Hash简介:
对于某些题目而言,在判断相等的时候,有时我们来不及或不会打一些算法了,甚至有时候连状压都会炸,这个时候,Hash无非是最好的选择。
Hash能够将一些状态通过一些方式把他们压缩到一个区间里面的某些值,并用bool类型来判重就可以了,耶!
一道不错的模版。KMP乱入
这道题是字符串Hash。
我们定义两个互质的常量,\(b\)与\(h\)。(注意\(b<h\))
对于一个字符串\(a\),我们定义他的Hash函数值为\(C(a,n)\),代表\(a\)字符串从\(1\)到\(n\)的字符子串的Hash值,函数的解析式是什么呢?
我们就定义为:
妈妈,我终于会写数学公式了
现在,我们设A字符串长度为\(n\),那我们就是求\(C(a,i(i\in[1,n]))\)
怎么求?
暴力每次把1到i的子串算一遍
肯定有更简便的做法。
但是问题怎么求?我们设\(m\)为B串的长度,\(ed=C(B,m)\)
那么,我们就要求\(a\)串中任意一个长度为\(m\)的子串的Hash值来做比较,首先,设这个子串的最左边的字符在\(a\)的位置为\(l\),而最右边的为\(r\),且\(r-l+1=m\),那么,我们现在已经知道了\(C(a,r)\)与\(C(a,l-1)\)
那么怎么搞?
那么我们是不是要将\(C(a,r)\)与\(C(a,l-1)\)中\([1,l-1]\)的部分抵消掉。
不不不。
仔细观察,我们发现,在\(C(a,r)\)中\(C(a,l-1)\)的值被放大了\(b^{m}\)。
因为\(r-(l-1)=r-l+1=m\)
那么,式子出来了。
那么,这样只要枚举r,然后就可以计算出在A中\(r-n+1\)到\(r\)的子串的Hash值了。
不过得先算出\(b^{m}\)。。。
当Hash值相同时,即为相等。
Hash为什么不会冲突?
我怎么知道,好像因为生日悖论,总之冲突的几率挺小的,当然\(h\)尽量定大一点的一个素数,如1e8+7与1e8+9,而\(b\)的取值随便啦。
不过,Hash冲突的几率还是让我们放不下心来(不过在比赛中一般可以认为不冲突),有时为了保险起见,许多都用双哈希或三哈希,即将\(h\)值换一换,一般双哈希取1e8+7与1e8+9,概率就已经很小的了。
当然\(h\)如果取\(2^{32}\)或\(2^{64}\),即为unsigned int或unsigned long long自然溢出,省去mod的时间也可以。
本代码只用单哈希。
#include<cstdio>
#include<cstring>
using namespace std;
typedef long long ll;
const ll h=100000007,b=130;//h的取值与b的取值
ll pp[1100000]/*求b的i0次方*/,tp[1100000]/*Hash值*/,n,m,ed,ans;
char st[1100000],stp[1100000];//A串与B串
int main()
{
scanf("%s%s",st+1,stp+1);n=strlen(st+1);m=strlen(stp+1);//长度
pp[1]=b;
for(int i=2;i<=n;i++)pp[i]=(pp[i-1]*b)%h;//计算
for(int i=1;i<=n;i++)tp[i]=(tp[i-1]*b+st[i])%h;//求Hash值
for(int i=1;i<=m;i++)ed=(ed*b+stp[i])%h;//求B串的Hash值
for(int i=m;i<=n;i++)
{
ll x;x=((tp[i]-tp[i-m]*pp[m])%h+h)%h;//求子串Hash值
ans+=(x==ed);//统计答案
}
printf("%lld\n",ans);
return 0;
}
Hash表
我们有时候需要表示一个集合{\(1,2,11,22,1000\)}
并且以后还要时不时的加入新的数,并且删除原有的数,还有查找一些数字是否存在。
离散化
你家离散化支持强制在线?
我们用一个长度为5的数组存,但是时间巨大,不得不让我们面壁思过考虑新的做法。
我们用Hash?
bool?你自己玩去吧,就算\(O(1)\)时间,空间定这么大,亏呀!
某大佬:Hash表是什么?直接Hash硬上就行了
好吧,Hash确实可以做,但是要你算出这个数字的位置,你就得定int了。。。

这个时候,我们不得不借力新的数据结构,Hash表!
What is this?
如同Hash一样,我们定义一个函数: \(C(x)=x\bmod k\),\(k\)你自己定。
我们让\(k=11\)。
那么我们定一个11的数组就好了,耶!
这很像Hash,但不是Hash。
如果是Hash就重复了,\(11,22\)
你自己撞枪口上还硬说Hash是错的
人家有自己的名字,Hash函数。不就是Hash
Hash函数适用于Hash表中。
继续。
那么,我们可以把11与22一起丢到0里面去,什么意思?
我们将每个位置定义一个单向链表,而\(last[i]\)记录的是最后一个丢到这个位置的节点的编号。
如图:
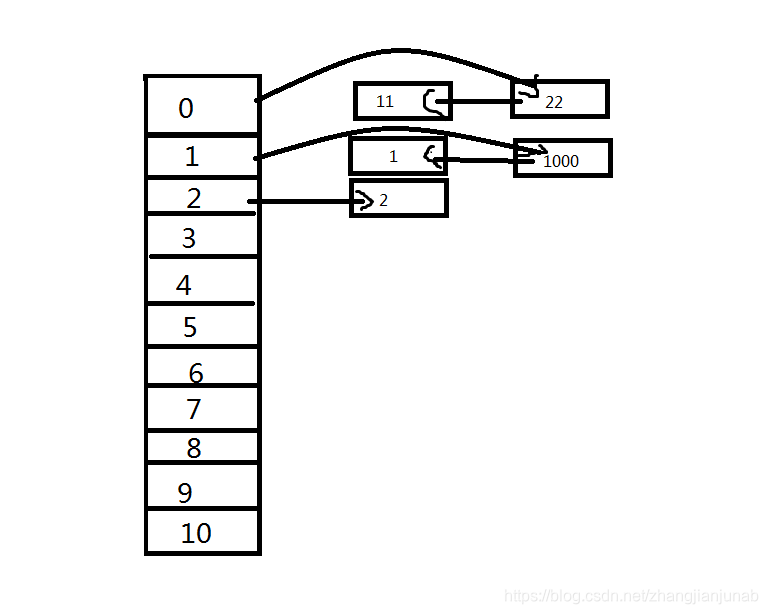
好丑。。。
图就是这样,一个单向链表,不过左边的那一个\(0,1,2,3,4,...,10\)不用定义,直接用\(last[i]\)代表第\(i\)个位置插入的最后一个数的编号是多少就行了。
找的话先计算一遍要找的数的函数值,然后找到位置跳链表就行了,速度也挺快的。
但是Hash表的速度取决与Hash函数的值分布的均不均匀。
比较均匀的Hash函数从书上学的分几类:
-
除余法。
就是模以一个数字\(k\)而已。但是如果运气不好定义的\(k\)是大部分数的公因数。。。那你就是非酋了。。。所以\(k\)最好定义一个大一点的质数,如:1000003、1000019、999979、100000007、100000009。 -
乘积取整法
乘一个在\((0,1)\)范围内的实数A,最好是无理数,\(\frac{\sqrt{5}-1}{2}\)是一个实际效果很好。貌似这句话有点眼熟。。。然后再取小数,乘以Hash表的大小向下取整。
不过这样的话,若数字集中一块,估计很快就凉了,而且各种操作还会导致速度变慢。 -
基数转换法
将原来的数字当成\(k(k>10)\)进制对待,然后转成10进制,就是转换过程稍稍慢了点。 -
平方取中法
将x取平方,然后根据Hash表实际大小能存多少位,来取中间几位,就是转换过程慢了点,但是分布就挺均匀的。
当然,只要速度快,都是好的Hash函数,Hash函数总的来说还是得根据题目定,不过因为是随机数据,我一般用除余法,方便,还挺快!
对于上面那道题,我们可以假设每个字符串的值就是他的Hash函数,\(b=300,h=100000007\),然后再用除余法走一遍,貌似没什么问题的样子。
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
typedef long long ll;
const ll b=300,h=100000007,k=1000019;//常数
struct node
{
ll l/*前一个插入到这个位置的数*/,y/*原本的数字*/;//单向链表
}a[310000];ll last[1100000]/*Hash表中的last数组*/,n,len/*整个hash表有多少节点*/;
char sp[30000];//char数组
inline ll Hash()//求每个字符串的hash值
{
ll ans=0,tlen=strlen(sp+1);
for(ll i=1;i<=tlen;i++)ans=(ans*b+sp[i])%h;
return ans;
}
inline void add(ll x)//添加x
{
ll y=x;x%=k;//除余法
for(ll i=last[x];i;i=a[i].l)
{
if(a[i].y==y)return ;//如果原本有的,就不加了。
}
a[++len].y=y;a[len].l=last[x];last[x]=len;//添加。
}
inline bool find(ll x)//寻找
{
ll y=x;x%=k;//除余法
for(ll i=last[x];i;i=a[i].l)
{
if(a[i].y==y)return true;//找到了,返回true
}
return false;
}
char st[2][10]={"no","yes"};
int main()
{
scanf("%lld",&n);
for(ll i=1;i<=n;i++)
{
scanf("%s",sp+1);
if(sp[1]=='a')
{
gets(sp);//注意,用get的话会把add与字符串中间的空格读进来,所以不用+1
add(Hash());//添加
}
else
{
gets(sp);//同理
printf("%s\n",st[ find(Hash()) ]);//寻找然后输出
}
}
return 0;
}
更多的题目来了。。。
暴力枚举子字符串长度,时间\(O(nlogn)\)我也不知道为什么
#include<cstdio>
#include<cstring>
#include<cstdlib>
using namespace std;
typedef long long ll;
const ll b=300,h=100000007;
ll hash[2100000],n,po[2100000];
char st[2100000];
inline ll inhash(ll x,ll y){return ((hash[y]-hash[x]*po[y-x])%h+h)%h;}//计算x+1到y的hash值
int main()
{
po[1]=b;
for(ll i=2;i<=1000000;i++)po[i]=(po[i-1]*b)%h;//计算阶乘
while(1)
{
scanf("%s",st+1);
n=strlen(st+1);
if(n==1 && st[1]=='.')break;
for(ll i=1;i<=n;i++)hash[i]=(hash[i-1]*b+st[i])%h;//计算hash值
for(ll i=1;i<=n;i++)
{
if(n%i==0)//一个优化
{
bool bk=true;
for(ll j=i;j<=n;j+=i)
{
if(inhash(j-i,j)!=hash[i])//判断
{
bk=false;
break;
}
}
if(bk==true)//可以,输出
{
printf("%lld\n",n/i);
break;
}
}
}
}
return 0;
}
暴力枚举前缀长度,每次\(O(n)\)。。。
#include<cstdio>
#include<cstring>
using namespace std;
typedef long long ll;
const ll b=300,h=100000009;
ll hash[510000],po[510000],n,ans[510000];
char st[510000];
inline ll inhash(ll x,ll y){return ((hash[y]-hash[x]*po[y-x])%h+h)%h;}//求[x+1,y]的hash值。
int main()
{
po[1]=b;
for(ll i=2;i<=400000;i++)po[i]=(po[i-1]*b)%h;//预处理阶乘
while(scanf("%s",st+1)!=EOF)
{
ans[0]=0;
n=strlen(st+1);
for(ll i=1;i<=n;i++)hash[i]=(hash[i-1]*b+st[i])%h;//hash值
for(ll i=1;i<=n;i++)
{
if(inhash(0,i)==inhash(n-i,n))ans[++ans[0]]=i;//记录
}
for(ll i=1;i<ans[0];i++)printf("%lld ",ans[i]);//输出
printf("%lld\n",ans[ans[0]]);
}
return 0;
}
没错,枚举那个位置是插进去的,然后推一下如何计算剔除这个位置的hash值,然后就没毛病了。
#include<cstdio>
#include<cstring>
#include<cstdlib>
using namespace std;
typedef long long ll;
const ll b=300,h=100000009;
ll po[2100000],hash[2100000],n,m,kk/*kk就是个优化*/,ans,cnt=0,sit=0;/*统计答案三人组*/
char st[2100000];
inline ll inhash(ll x,ll y){return ((hash[y]-hash[x]*po[y-x])%h+h)%h;}//求出[x+1,y]的hash值。
inline ll hash_hash(ll x,ll y,ll k)//在[x,y]的区间里把k剔除
{
ll xk=inhash(x-1,k-1),ky=inhash(k,y);//计算出两段hash值
return (xk*po[y-k]+ky)%h;//拼在一起
}
int main()
{
scanf("%lld",&n);
scanf("%s",st+1);
po[0]=1;/*因为在inhash中会出现po[0]的情况*/po[1]=b;
for(ll i=2;i<=n;i++)po[i]=(po[i-1]*b)%h;
for(ll i=1;i<=n;i++)hash[i]=(hash[i-1]*b+st[i])%h;
m=n/2+1;
kk=inhash(m,n);
for(ll i=1;i<=m;i++)//模拟字符在前一个字符串里
{
if(hash_hash(1,m,i)==kk)
{
if(ans==1)//判断
{
if(kk!=sit)//不是同一个字符串
{
printf("NOT UNIQUE\n");//不止一组解
return 0;
}
}
else ans++,cnt=i,sit=kk;//统计答案
}
if(ans==2)
{
printf("NOT UNIQUE\n");//不止一组解
return 0;
}
}
kk=inhash(0,m-1);//减少hash的步骤
for(ll i=m;i<=n;i++)//模拟字符在后一个字符串里
{
if(hash_hash(m,n,i)==kk)
{
if(ans==1)//判断
{
if(kk!=sit)//不是同一个字符串
{
printf("NOT UNIQUE\n");//不止一组解
return 0;
}
}
else ans++,cnt=i,sit=kk;//统计答案
}
}
if(ans==0)printf("NOT POSSIBLE\n");//输出
else//输出字符串
{
if(cnt<=m)
{
for(ll i=1;i<=m;i++)
{
if(i!=cnt)printf("%c",st[i]);
}
}
else
{
for(ll i=m;i<=n;i++)
{
if(i!=cnt)printf("%c",st[i]);
}
}
printf("\n");
}
return 0;
}
其实我也发现我代码有很多多余的判断,反正都A了,不管他
像上面一样?\(O(qnlogn)\),显然,毒瘤出题人不会让我们过。。。
我们考虑优化。
以前我们判断这个是否是循环节,我们都是for一遍,但是,有更好的方法。
假设当前区间为\([l,r]\),循环节长度为\(k(k|(r-l+1))\),那么,当\([l+k,r]\)的Hash值等于\([l,r-k]\)的Hash值时,就代表这个是循环节!
为什么?
假设长度为\(k\)的循环节在长度为\(n\)的字符串中标号为\(a_{1},a_{2},a_{3},...,a_{n/k}(a_{1},a_{2},a_{3}...\)的长度都为\(k)\)
那么,Hash值相等代表\(a_{1}=a_{2}...\),所以可以呀。
其实想想都觉的可以。。。
但是时间复杂度还是\(O(qn)\),如果可以过,就不会有出题人收到刀片的事情了。。。
由于我们判断了\(k\)是否是\(n\)的约束了,所以时间为\(O(q\sqrt{n})\)
但是还是不能过!
考虑循环节的性质,如果\(k\)是其中一个循环节,那么\(ki(ki|n)\)(ki代表\(k*i\),i为任意数字)也是一个循环节,所以我们先线性筛一遍,记录出每个数的最小约数,然后初始化\(now=n\)代表当前的循环节最小为\(now\),不断找\(n\)的约数\(k_{i}\)判断\(now\)能否继续分成\(k_{i}\)块,可以的话\(now/k_{i}\),代表当前的循环节还可以分下去,知道找完所有约数为止。
那么如何找到所有的约数?
由于我们记录了每个数的最小约数(记录这个会比较好写),那么初始化\(v=n\),然后不断取\(v\)的最小约数,然后再除于这个最小的约数,不断下去,就行了。
丑陋的卡常代码,为了卡常,我用了溢出的方法来进行模。
#include<cstdio>
#include<cstring>
#define RI register int//寄存器
using namespace std;
typedef unsigned long long ll;
const ll b=53;//一个非偶数质数
ll ans,n,m;
ll hash[510000],po[510000];//日常数组
char ss[510000];
inline void in(ll &x)//快读
{
x=0;char c=getchar();
while(c<'0' || c>'9')c=getchar();
while('0'<=c && c<='9')x=(x<<3)+(x<<1)+(c^48),c=getchar();
}
inline void out(ll x)//快输
{
register ll y=10;
while(y<=x)y=(y<<3)+(y<<1);
while(y!=1)y/=10,putchar(x/y+48),x%=y;
putchar('\n');
}
inline ll inhash(ll x,ll y){return hash[y]-hash[x]*po[y-x];}
inline bool check(ll x,ll y,ll t)//在x到y区间,循环节长度为t
{
register ll xt=inhash(x-1,y-t),yt=inhash(x+t-1,y);//卡常大法好
if(xt==yt)return true;
return false;
}
bool f[510000];
int pri[510000],next[510000];
inline void shuai()//欧拉筛
{
for(int i=2;i<=n;i++)
{
if(f[i]==false)
{
pri[++pri[0]]=i;
next[i]=i;//素数就时他自己
}
for(int j=1;j<=pri[0] && i*pri[j]<=n;j++)
{
f[i*pri[j]]=true;
next[i*pri[j]]=pri[j];//自己想想为什么是最小约数
if(i%pri[j]==0)break;
}
}
}
int main()
{
in(n);
scanf("%s",ss+1);
po[0]=1;po[1]=b;
for(RI i=2;i<=n;i++)po[i]=po[i-1]*b;
for(RI i=1;i<=n;i++)hash[i]=hash[i-1]*b+ss[i];
shuai();//初始化
in(m);
for(RI i=1;i<=m;i++)
{
ll l,r;in(l),in(r);
ll v=ans=r-l+1;//如文中所说,ans就是now
while(v!=1)
{
if(check(l,r,ans/next[v]))ans/=next[v];
v/=next[v];
}
printf("%llu\n",ans);//输出
}
return 0;
}
首先,记住两个数字,2333与98754321,膜了题解才AC,变态出题人!
把数组当成字符串,暴力枚举呀,用map判重突然发现这玩意挺牛逼的!,\(O(n\log^{2}{n})\),就是前一遍Hash,后一遍Hash。
其实虽然\(b,h\)参数并没变,但是两次Hash的方法不同也可以起到很厉害的作用。
优化:如果当前枚举的块的长度所分的块还没有\(anss\)(目前能获得的最大不同的段的个数)大,那么退役吧。。。 break
#include<cstdio>
#include<cstring>
#include<map>//map大法好呀!
#define N 200010//数组大小
using namespace std;
typedef long long ll;
const ll b=2333,h=98754321;//变态出题人
map<ll,bool> ss;//map
ll n;
ll hash1[N]/*正着*/,hash2[N]/*倒着*/,po[N],ans[N],anss/*记录能分成多少段*/,a[N];
inline ll inhash1(ll x,ll y){return ((hash1[y]-hash1[x]*po[y-x])%h+h)%h;}//正着[x+1,y]
inline ll inhash2(ll x,ll y){return ((hash2[x]-hash2[y]*po[y-x])%h+h)%h;}//倒着[x,y-1]
int main()
{
scanf("%lld",&n);
po[0]=1;
for(ll i=1;i<=n;i++)
{
scanf("%lld",&a[i]);
po[i]=(po[i-1]*b)%h;//次方
hash1[i]=(hash1[i-1]*b+a[i])%h;//正着
}
for(ll i=n;i>=1;i--)hash2[i]=(hash2[i+1]*b+a[i])%h;//倒着
for(ll i=1;i<=n;i++)
{
if(n/i<anss)break;//优化
ss.clear();//清空
ll now=0;//目前所能获得的最大块数
for(ll j=i;j<=n;j+=i)
{
ll zheng,dao;
zheng=inhash1(j-i,j);dao=inhash2(j-i+1,j+1);
if(!ss.count(zheng) || !ss.count(dao))//不用质疑,打&&会WA,可能是因为用Hash其中有一个会重复,这也体现了正着来一遍,反着来一遍可以起到判重作用
{
ss[zheng]=true;ss[dao]=true;//扔到map里面去
now++;
}
}
if(now==anss)ans[++ans[0]]=i;//新增答案
else if(now>anss)//更新新的答案
{
anss=now;
ans[ans[0]=1]=i;
}
}
printf("%lld %lld\n",anss,ans[0]);
for(ll i=1;i<ans[0];i++)printf("%lld ",ans[i]);
printf("%lld\n",ans[ans[0]]);//输出
return 0;
}
二分加Hash
首先串必须是偶数长度(不然你中间的字符去反后就不等于自己了)
而且,若\([l,r]\)是反对称,那么\([l-1,r-1]\)也是反对称。
正着一遍Hash,弄成反串再反着来一遍Hash,那么,假设我们有两个数字\(l,k\),那么,我们就是求\([l,l+2*k-1]\)。
那么,先用循环\(i\)枚举\(l+k-1\),然后,然后里面用二分枚举\(l\),然后用\(i\)和\(l\)计算出\(r\),设二分结果为\(x\),然后\(ans+=(i-x)+1\)
代码:
#include<cstdio>
#include<cstring>
#define N 1100000
using namespace std;
typedef long long ll;
const ll b=2333,h=100000007;
ll hash1[N]/*正着*/,hash2[N]/*反串反着哈希*/,po[N]/*次方*/,n,ans;
char st[N];
inline ll inhash1(ll x,ll y){return ((hash1[y]-hash1[x]*po[y-x])%h+h)%h;}//[x+1,y]
inline ll inhash2(ll x,ll y){return ((hash2[x]-hash2[y]*po[y-x])%h+h)%h;}//[x,y-1]
inline ll mymax(ll x,ll y){return x>y?x:y;}//取最大
inline bool check(ll l,ll r)
{
ll zh=inhash1(l-1,r)/*正着*/,da=inhash2(l,r+1)/*倒着*/;
return zh==da;
}
int main()
{
scanf("%lld",&n);
scanf("%s",st+1);
po[0]=1;
for(int i=1;i<=n;i++)
{
po[i]=(po[i-1]*b)%h;
hash1[i]=(hash1[i-1]*b+st[i])%h;
}
for(int i=n;i>=1;i--)hash2[i]=(hash2[i+1]*b+((st[i]-48)^1)+48)%h;//计算hash
for(int i=1;i<=n;i++)
{
ll l=mymax(1,i-(n-i)+1)/*计算l区间*/,r=i,mid,x=i+1/*记录答案*/;//二分
while(l<=r)
{
mid=(l+r)/2;
if(check(mid,i+(i-mid+1)))r=mid-1,x=mid;//成立,缩小限制
else l=mid+1;//不成立,放大限制
}
ans+=(i-x)+1;//统计
}
printf("%lld\n",ans);//输出
return 0;
}
终于来了道Hash表的题,但是好水。QAQ
#include<cstdio>
#include<cstring>
using namespace std;
typedef long long ll;
const int k=2999999;//一个好看的质数。。。
struct node
{
int l;
ll x;
}hash[2100000];int len,last[k];
inline void add(ll x)//x肯定没出现过
{
ll y=x;x%=k;//转换
hash[++len].x=y;hash[len].l=last[x];last[x]=len;
}
inline bool find(ll x)//找到x
{
ll y=x;x%=k;
for(int i=last[x];i;i=hash[i].l)//找Hash表
{
if(hash[i].x==y)return 1;
}
return 0;
}
int main()
{
ll A,B,C,x=1,id=0;scanf("%lld%lld%lld",&A,&B,&C);A%=C;//不加也可以QAQ
while(!find(x))
{
if(id==2000000){id=-1;break;}//-1判断
add(x);//添加
x=(A*x+(x%B))%C;id++;//更新
}
printf("%lld\n",id);
return 0;
}
这道题的话,一个支持删除的Hash表,也不是很难码。
先说做法,维护\(l,r\)两个下标指针,每次用循环让\(r++\),然后找一下有没有与第\(r\)个位置重复的,有,就让\(l\)等于他,同时删掉之前的数字,然后用\(ans\)记录最大的区间。
#include<cstdio>
#include<cstring>
#include<cstdlib>
using namespace std;
typedef long long ll;
const ll k=2999999;
struct node
{
ll l,x,id;
}hash[1100000];ll last[k],len;
ll a[1100000],n,ans;
inline void add(ll x,ll id)//添加
{
ll y=x;x%=k;
hash[++len].id=id;hash[len].x=y;hash[len].l=last[x];last[x]=len;
}
inline ll find(ll x)//返回重复的ID
{
ll y=x;x%=k;
for(ll i=last[x];i;i=hash[i].l)
{
if(hash[i].x==y)return hash[i].id;
}
return 0;//没有返回0
}
inline void del(ll x,ll id)//删除编号为id的
{
x%=k;
if(last[x]==id)last[x]=hash[id].l;//如果是最后一个插入的
else//否则像单向链表一样删除
{
ll pre=last[x];//之前的节点
for(int i=hash[pre].l;i;i=hash[i].l)//枚举那个节点被删除
{
if(hash[i].id==id)//判断
{
hash[pre].l=hash[i].l;
return ;
}
pre=i;//更新
}
}
}
inline ll mymax(ll x,ll y){return x>y?x:y;}//取最大
int main()
{
scanf("%lld",&n);
for(ll i=1;i<=n;i++)scanf("%lld",&a[i]);//输入
ll l=1;
for(ll i=1;i<=n;i++)
{
ll tkk=find(a[i]);//找到重复的位置
for(;l<=tkk;l++)del(a[l],l);//删除
add(a[i],i);//添加
ans=mymax(ans,i-l+1);//记录
}
printf("%lld\n",ans);
return 0;
}
终于在今天做完哈希和哈希表这一章节了。
注意事项
在设置指数时不能有两个位置重复,例如在二维hash中,如果把\((i,j)\)的指数设置成了\(i+j\),那么\((1,2)\)和\((2,1)\)的位置可以互通,就不能保证数字的唯一性了。
同时参数的设置最好比数域要大,字符串的Hash,\(b\)就要比'z'要大,不然举个例子,数域是在\(1-9\)的,我设置一个\(3\),那是不是以为着\(1\)号位的\(9\)可以看作\(2\)号位的\(3\),模数就不说了,你设置这么小能起到判重的作用吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号