面向对象
注:此博客大量借鉴了大佬的博客,当然也做了一些修改,因此标上转载。
面向对象
注:为了阅读起来比较轻松,可以选择先阅读继承一块
三. UML画图
一. 什么是面向对象
1. 诞生的使命
在很久很久╭(╯^╰)╮以前,编程人员大部分都采用面向过程,面向过程是什么?
面向对象就是这样,从繁到简,一步一步将大问题拆解成一个个步骤,在不断化为小问题,估计大家许多人现在打代码都是用面向过程的思想的。
可以说,在做一个小游戏的时候,我们都在用这样的思想,小游戏还好,到大游戏就会有巨大的麻烦了!QAQ
有时候,游戏更新一些东西,游戏代码越长,要改的地方越多,完全摸不着头脑,有时候少加了,就成为了让玩家所唾弃的BUG,然后就被一群人骂了又骂!
在这种情况下,面向对象等一批新的思想诞生了!
面向对象,顾名思义就是将一个问题化成一个个对象来进行解决,对象如同物体,而我们每次改一个东西只需要跑到指定的一些对象里面就行了,方便,简单。
2. 封装
既然是对象,就如同一个人,有自己公开、保护与私有的信息。
比如一个人,我们穿什么衣服,就是公开的,而自己生了什么病,就是保护的,因为通常你不想让别人知道,但是又会被继承到其他类里面,而你的隐私就是私有信息,不会被继承也不想被别人知道。
3. 继承
有时候有一些类型会与其他类型有关联,就可以用继承来实现,比如:
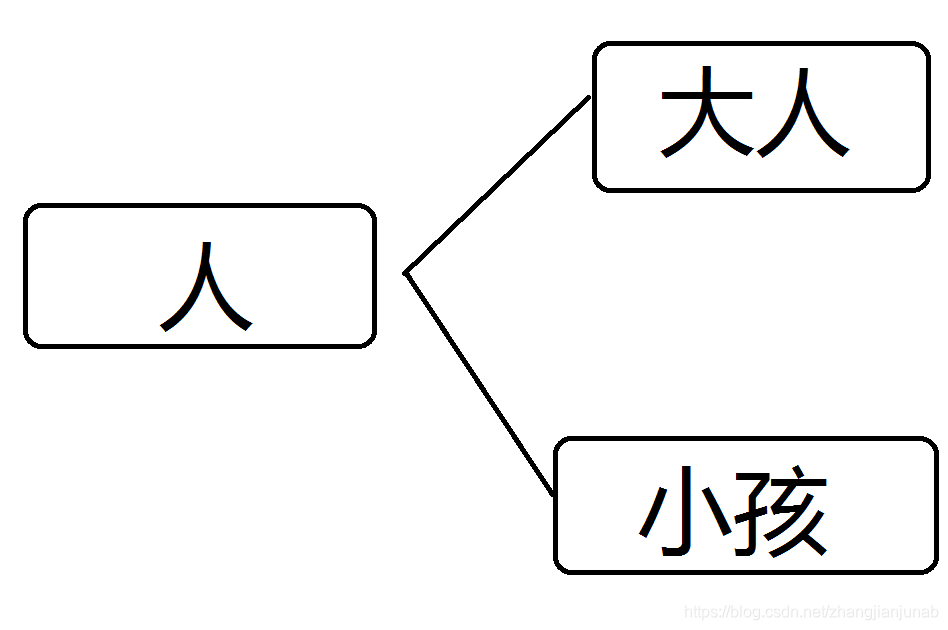
大人是人的一种,小孩也是,因此他们都可以继承人的功能,就叫继承。
同时继承完后,大人与小孩也可以有自己的一些不同的功能比如婴儿的无理取闹。
4. 多态
多态性是指相同的操作或函数、过程可作用于多种类型的对象上并获得不同的结果。不同的对象,收到同一消息可以产生不同的结果,这种现象称为多态性。
多态性允许每个对象以适合自身的方式去响应共同的消息。
多态性增强了软件的灵活性和重用性。
5. 意义
纵观面向对象思想的三大特征,它们是紧密相关、不可分割的。通过封装,我们将现实世界中的数据和对数据进行操作的动作捆绑到一起成了类,然后再通过类定义对象,很好地实现了对现实世界事物的抽象和描述;通过继承,可以在旧类型的基础上快速派生得到新的类型,很好地实现了设计和代码的复用;同时,多态机制保证了在继承的同时,还有机会对已有行为进行重新定义,满足了不断出现的新需求的需要。
正是因为面向对象思想的封装、继承和多态这三大特性,使得面向对象思想在程序设计中有着不可替代的优势。
(1) 容易设计和实现。
面向对象思想强调从客观存在的事物(对象)出发来认识问题和分析解决问题,因为这种方式更加符合我们认识事物的规律,所以大大降低了问题的理解难度。面向对象思想所运用的封装、继承与多态等基本原则,符合人类日常的思维习惯,使得采用面向对象思想设计的程序结构清晰、更容易设计和实现。
(2) 复用设计和代码,开发效率和系统质量都得到提高。
面向对象思想的继承和多态,强调了程序设计和代码的重用,这在设计新系统的时候,可以最大限度地重用已有的、经过大量实践检验的设计和代码,使系统能够满足新的业务需求并具有较高的质量。同时,因为可以复用以前的设计和代码,大大提高了开发效率。
(3) 容易扩展。
开发大型系统的时候,最担心的就是需求的变更以及对系统进行扩展。利用面向对象思想继承、封装和多态的特性,可以设计出“高内聚、低耦合”的系统结构,可让系统更灵活、更易扩展,从而轻松应对系统的扩展需求,降低维护成本。
扩展
高内聚,低耦合是软件工程中的一个概念,通常用以判断一个软件设计的好坏。所谓的高内聚,是指一个软件模块是由相关性很强的代码组成,只负责某项单一任务,也就是常说的“单一责任原则”。而低耦合指的是在一个完整的系统中,模块与模块之间,尽可能地保持相互独立。换句话说,也就是让每个模块尽可能的独立完成某个特定的子功能。模块与模块之间的接口,尽量的少而简单。
高内聚低耦合的系统具有更好的重用性、可维护性和扩展性,可以更高效的完成系统的开发、维护和扩展,持续地支持业务的发展。因而,它可以作为判断一个软件设计好坏的标准,自然也是我们软件设计的目标。
面向对象程序设计思想在软件开发中的这些优势,使其成为当前最为流行的程序设计思想之一,是每个进入C++世界的程序员都需要理解和掌握的。它就像程序设计中的《易筋经》般博大精深,而这里所介绍的只是面向对象思想最基础的入门知识,要完全领会和灵活运用面向对象思想,还需要在实践中不断学习和总结。在理解概念的同时,更要着重体会如何利用面向对象思想来分析问题设计程序,只有这样才能增加软件设计和开发的功力,成为真正的高手。
二. 实现(C++)
1. 封装的实现
C++为我们专门提供了一个叫class的类,是专门为面向对象设计所提供的。
申明如下:
class 类名
{
public : //不打括号
// 公有成员,通常用来描述这类对象的相同行为
protected: //不打括号
// 保护型成员
private: //不打括号
// 私有成员,通常用来描述这类对象的共同属性
};//有个分号表示结束
当然,我们省掉其中几个也没问题,比如:
class 类名
{
public :
};//有个分号表示结束
但么,如果不打public什么的会不会报错?
不会,class会自动把他归为private。
大佬的一张图片 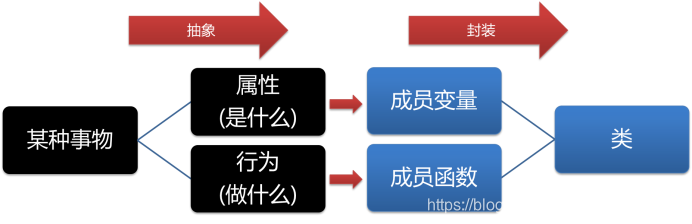
扩展1:为类设计对程序员友好的接口
我们所设计的类不仅供我们自己使用,更多时候它还会提供给其他程序员使用,以达到代码复用或者实现团队协作的目的。这时,类的接口设计的好坏,将会影响到他人能否正确并轻松地使用我们所设计的类。因此,它也成为了衡量一个程序员水平高低的重要标准。
类的接口,就像类的使用说明书一样,是向类的使用者说明它所需要的资源及它所能够提供的服务等。只要类的接口对程序员友好,从接口就可以轻松地知道如何正确地使用这个类。要做到这一点,应当遵守下面这些设计原则。
l 遵循变量与函数的命名规则
成员变量也是变量,成员函数也是函数。所以,作为类的接口的它们,在命名的时候也同样应该遵守普遍的命名规则,让它们的名字能够准确而简洁地表达它们的含义。
l 简化类的视图
接口,代表了类所能够向用户提供的服务。所以,在进行类的接口设计时,只需要将必要的成员函数公有(public)就可以了,使用受保护的(protected)或者私有的(private)成员来向用户隐藏不必要的细节。因为隐藏了用户不应该访问的内容,自然也就减少了用户犯错误的机会。
l 使用用户的词汇
类设计出来最终是让用户使用的,所以在设计类的接口时,应该从用户的角度出发,使用用户所熟悉的词汇,让用户在阅读类的接口时,不需要学习新的词汇或概念,这样可以平滑用户的学习曲线,让我们的类使用起来更容易。
除了在类中定义变量和函数来表示类的属性和行为之外,还可以使用public、protected及private这三个关键字来对这些成员进行修饰,指定它们的访问级别。按照访问级别的不同,类的所有成员被分成了三个部分。通常,使用public修饰的成员外界可以访问,我们会在public部分定义类的行为,提供公共的函数接口供外部访问;使用protected修饰的成员只有类自己和它的派生类可以访问,所以在protected部分,我们可以定义遗传给下一代子类的属性和行为;最后private修饰的成员只有类自己可以访问,所以在private部分,我们可以定义这个类所私有的属性和行为。关于类的继承方式和访问控制,稍后将进行详细介绍。这里先来看一个实际的例子。例如,要定义一个类来描述老师这一类对象,通过对这类对象的抽象,我们发现老师这类对象拥有只有自己和子类可以访问的姓名属性和大家都可以访问的上课行为。当然,老师还有很多其他属性和行为,这里根据需要作了简化。最后,我们使用面向对象的封装机制,将这些属性和行为捆绑到一起,就有了老师这个类的声明。
// 老师
class Teacher
{
// 成员函数
// 描述对象的行为
public: // 公有部分,供外界访问
void GiveLesson(); // 上课
// 成员变量
// 描述对象的属性
protected:// 受保护部分,自己和子类访问
string m_strName; // 姓名
private:
};
通过这段代码,我们声明了一个Teacher类,它是所有老师这种对象的一个抽象描述。这个类有一个public关键字修饰的成员函数GiveLesson(),它代表老师这类对象拥有大家都可以访问的行为——上课。它还有一个protected关键字修饰的变量m_strName,表示老师这类对象的只有它自己和子类可以访问的属性——姓名。这样,通过在一个类中声明函数描述对象的行为,声明变量描述对象的属性,就完整地声明了一个可以用于描述某类对象的类。
完成类的声明之后,我们还需要对类的行为进行具体的定义。类成员函数的具体定义可以直接在类中声明成员函数的时候同时完成:
class Teacher
{
// 成员函数
// 描述对象的行为
public:
// 声明成员函数的同时完成其定义
void GiveLesson()
{
cout<<"老师上课。"<<endl;
};
//…
};
更多时候,我们只是将类的声明放在头文件(比如,Teacher.h文件)中,而将成员函数的具体实现放在类的外部定义,也就是相应的源文件(比如,Teacher.cpp)中。在类的外部定义类的成员函数时,我们需要在源文件中引入类声明所在的头文件,并且在函数名之前还要用“::”域操作符指出这个函数所属的类。例如:
#ifndef _TEACHER_H // 定义头文件宏,防止头文件被重复引入
#define _TEACHER_H // 在稍后的7.3.1小节中会有详细介绍
// Teacher.h 类的声明文件
class Teacher
{
// …
public:
void GiveLesson(); // 只声明,不定义
};
#endif
// Teacher.cpp 类的定义文件
// 引入类声明所在的头文件
#include "Teacher.h"
// 在Teacher类外完成成员函数的定义
void Teacher::GiveLesson()
{
cout<<"老师上课。"<<endl;
}
这里可以看到,成员函数的定义跟普通函数并无二致,同样都是用函数来完成某个动作,只是成员函数所表示的是某类对象的动作。例如,这里只是输出一个字符串表示老师上课的动作。当然,在实际应用中,类成员函数还可以对成员变量进行访问,所完成的动作也要比这复杂得多。
扩展:1
当然,这样有什么用?
-
公有类型
公有类型的成员用关键字public修饰,在成员变量或者成员函数前加上public关键字就表示这是一个公有类型的成员。公有类型的成员的访问不受限制,在类的内外都可以访问,但它更多的还是作为类提供给外界访问的接口,是类跟外界交流的通道,外界通过访问公有类型的成员完成跟类的交互。例如Teacher类的表示上课行为的GiveLesson()成员函数,这是它向外界提供的服务,应该被外界访问,所以这个成员函数应该设置为公有类型。 -
保护类型
保护类型的成员用关键字protected修饰,其声明格式跟public类型相同。保护类型的成员在类的外部无法访问,但是可以在类的内部及继承这个类而得的派生类中访问,它主要用于将属性或者方法遗传给它的下一代子类。例如,对于Teacher类的表示姓名属性的m_strName成员变量,谁也不愿意自己的名字被别人修改,所以应该限制外界对它的访问;而显然自己可以修改自己的名字,所以Teacher类内部可以访问这个成员变量;同时,如果Teacher类有派生类,比如表示大学老师的Lecturer,我们也希望这个成员变量可以遗传给派生类,使其派生类也拥有这个成员变量,可以对其进行访问。经过这样的分析,把m_strName成员变量设置为保护类型最为合适。 -
私有类型
私有类型的成员用关键字private修饰,其声明格式跟public类型相同。私有类型的成员只能在类的内部被访问,所有来自外部的访问都是非法的,这样就把类的成员完全隐藏在类当中,很好地保护了类中数据和行为的安全。所以,赶快把我们的钱包声明为私有成员吧,这样小偷就不会访问到它了。
这里需要说明的是,如果class关键字定义的类当中类成员没有显式地说明它的访问级别,那么默认情况下它就是私有类型,外界是无法访问的,由此可见类其实是非常“自私”的(相反地,由struct定义的类中,默认的访问级别为公有类型)。
扩展2
知道更多:C++中用以声明类的另一个关键字——struct
在C++中,要声明一个类,除了使用正牌的“class”关键字之外,之前在3.8节中介绍过的用来定义结构体的“struct”关键字也同样可以用来声明一个类。在语法上,“class”和“struct”非常相似,两者都可以用来声明类,而两者唯一的区别就是,在没有指定访问级别的默认情况下,用“class”声明的类当中的成员是私有的(private),而用“struct”声明的类当中的成员是公有的(public)。例如:
// 使用“struct”定义一个Rect类
struct Rect
{
// 没有访问权限说明
// 类的成员函数,默认情况下是公有的(public)
int GetArea()
{
return m_nW * m_nH;
}
// 类的成员变量,默认情况下也是公有的(public)
int m_nW;
int m_nH;
};
这里,我们使用“struct”声明了一个Rect类,因为没有使用public等关键字显式地指明类成员的访问控制,在默认情况下,类成员都是公有的,所以可以直接访问。例如:
Rect rect;
// 直接访问成员变量
rect.m_nH = 3;
rect.m_nW = 4;
// 直接访问成员函数
cout<<"Rect的面积是:"<<rect.GetArea()<<endl;
这两个关键字的默认访问控制要么过于保守,要么过于开放,这种“一刀切”的方式显然无法适应于所有情况。所以无论是使用“class”还是“struct”声明一个类,我们都应该在声明中明确指出各个成员的合适的访问级别,而不应该依赖于关键字的默认行为。
“class”和“struct”除了上面这点在类成员默认访问级别上的差异之外,从“感觉”上讲,大多数程序员都认为它们仍有差异:“struct”仅像一堆缺乏封装的开放的内存位,更多时候它是用以表示比较复杂的数据;而“class”更像活的并且可靠的现实实体,它可以提供服务、有牢固的封装机制和定义良好的接口。既然大家都这么“感觉”,那么仅仅在类只有很少的方法并且有较多公有数据时,才使用“struct”关键字来声明类;否则,使用“class”关键字更合适。
扩展3:class的申明
class的申明很简单,就不讲了。
class Teacher;//申明
class Teacher
{
//操作
};
同时,class内的函数应该在类内申明,不能在类外申明,如果要在类外定义函数,那么要用::作用域申明这个函数在哪个类里面的。
2. 友元函数与友元类
class中的保护类和私有类就这么封死了吗?
不不不,就比如你的老婆可以“看”你的钱包一样QAQ,所以,C++专门为我们提供了一个叫friend的东西,他可以申明友元函数与友元类,友元函数的申明是这样的:
class 类名
{
friend 返回值类型 函数名(形式参数列表);
// 类的其他声明和定义…
};
就可以定义友元函数了,友元函数一般放在类的外面,这个友元函数可以调用这个类里面的保护类和私有类的变量,是不是特别厉害?
比如:
class child
{
friend void GG(child xx);//友元函数
//friend void GG(child);也可以
private:
int tt;
};
void GG(child xx)
{
xx.tt++;
}
而友元类则更牛逼,申明如下:
class classmate
{
friend class teacher;//友元类
private:
int tt;
};
class teacher
{
private:
int kk;
};
而friend的申明可以放在任何类型里面,都没有影响
这个可以让teacher的类里面的所有函数都可以访问到classmate的保护类与私有类。
再举个栗子:
#include<cstdio>
using namespace std;
class mother;
class child;
class father
{
friend class child;
public:
father()
{
xx=1;
}
private:
int xx;
}ss;
class mother
{
friend class child;
public:
mother()
{
yy=1;
}
private:
int yy;
}st;
class child
{
public:
child()
{
yy=2;
}
void kk(father x){yy=x.xx;}
void print()
{
printf("%d\n",yy);
}
private:
int yy;
}sst;
int main()
{
sst.kk(ss);
sst.print();
return 0;
}
扩展
友元虽然能给我们带来一定的便利,但是在使用友元的时候,还应该注意以下几点:
l 友元关系不能被继承。这一点很好理解,我们跟某个类是朋友(即是某个类的友元类),并不表示我们跟这个类的儿子(派生类)同样是朋友。
l 友元关系不能传递,比如teacher是classmate的友元类,而classmate是pat的友元类,而不代表teacher是pat的友元类。
l 友元关系是单向的,不具有交换性。比如,TaxationDep类是Teacher类的友元类,税务官员可以检查老师的工资,但这并不表示Teacher类也是TaxationDep类的友元类,老师也可以检查税务官员的工资。
l 将某个函数或者类声明为友元,即意味着对方是经过审核认证的,是值得信赖的,所以才授权给它访问自己的隐藏信息。这也提示我们在将函数或类声明为友元之前,有必要对其进行一定的审核。只有值得信赖的函数和类才能将其声明为友元。
友元的使用并没有破坏封装
在友元函数或者友元类中,我们可以直接访问类的保护或私有类型的成员,这个“后门”打开后,很多人担心这样会让类的隐藏信息暴露出来,破坏类的封装。但事实是,合理地使用友元,不仅不会破坏封装,反而会增强封装。
在面向对象的设计中,我们强调的是“高内聚、低耦合”的设计原则。当一个类的不同成员变量拥有两个不同的生命周期时,为了保持类的“高内聚”,我们经常需要将这些不同生命周期的成员变量分割成两部分,也就是将一个类分割成两个类。在这种情况下,被分割的两部分通常需要直接存取彼此的数据。实现这种情况的最安全途径就是使这两个类成为彼此的友元。但是,一些“高手”想当然地认为友元破坏了类的封装,转而通过提供公有的 get()和set()成员函数使两部分可以互相访问数据。实际上,他们不知道这样的做法正是破坏了封装。在大多数情况下,这些 get()和set()成员函数和公有数据一样差劲:它们仅仅隐藏了私有数据的名称,而没有隐藏对私有数据的访问。
友元的使用,只是向必要的客户公开类的隐藏数据,比如Teacher类只是向TaxationDep类公开它的隐藏数据,只是让税务官可以知道它的工资是多少。这要远比使用公有的get()/set()成员函数,而让全世界都可以知道它的工资要安全隐蔽的多。
3. 重载运算符
如果要想对两个对象进行操作,比如两个对象相加,最直观的方式就是像数学式子一样,用表示相应意义的操作符来连接两个对象,以此表达对这两个对象的操作。在本质上,操作符就相当于一个函数,它有自己的参数,可以用来接收操作符所操作的数据;也有自己的函数名,就是操作符号;同时也有返回值,用于返回结果数据。而在使用上,只需要用操作符连接被操作的两个对象,比函数调用简单直观得多,代码的可读性更好。所以在表达一些常见的操作时,比如对两个对象的加减操作,我们往往通过重载这个类的相应意义的操作符来完成。在C++中有许多内置的数据类型,包括int、char、string等,而这些内置的数据类型都有许多已经定义的操作符可以用来表达它们之间的操作。比如,我们可以用“+”操作符来表达两个对象之间的“加和”操作,用它连接两个int对象,得到的“加和”操作结果就是这两个数的和,而用它连接两个string对象,得到的“加和”操作结果就是将两个字符串连接到一起。例如:
int a = 3;
int b = 4;
// 使用加法操作符“+”获得两个int类型变量的和
int c = a + b;
cout<<a<<" + "<<b<< " = "<<c<<endl;
string strSub1("Hello ");
string strSub2("C++");
// 使用加法操作符“+”获得两个string类型变量的连接结果
string strCombin = strSub1 + strSub2;
cout<<strSub1<<"+ "<<strSub2<<" = "<<strCombin<<endl;
这种用操作符来表达对象之间的操作关系的方式,用抽象性的操作符表达了具体的操作过程,从而隐藏了操作过程的具体细节,既直观又自然,也就更便于使用。对于内置的数据类型,C++已经提供了丰富的操作符供我们选择使用以完成常见的操作,比如表示数学运算的“+”(加)、“-”(减)、“*”(乘)、“/”(除)。但是对于我们新定义的类而言,其两个对象之间是不能用这些操作符直接进行操作的。比如,分别定义了Father类和Mother类的两个对象,我们希望可以用加法操作符“+”连接这两个对象,进而通过运算得出一个Baby类的对象:
// 分别定义Father类和Mother类的对象
Father father;
Mother mother;
// 用加法操作符“+”连接两个对象,运算得到Baby类的对象
Baby baby = father + mother;
以上语句所表达的是一件显而易见的事情,但是,如果没有对Father类的加法操作符“+”进行定义,Father类是不知道如何和一个Mother类的对象加起来创建一个Baby类对象的,这样的语句会出现编译错误,一件显而易见的事情在C++中却行不通。但幸运的是,C++允许我们对这些操作符进行重载,让我们可以对操作符的行为进行自定义。既然是自定义,自然是想干啥就干啥,自然也就可以让Father类对象加上Mother类对象得到Baby类对象,让上面的代码成为可能。
在功能上,重载操作符等同于类的成员函数,两者并无本质上的差别,可以简单地将重载操作符看成是一类比较特殊的成员函数。虽然成员函数可以提供跟操作符相同的功能,但是运用操作符可以让语句更加自然简洁,也更具可读性。比如,“a.add(b)”调用函数add()以实现两个对象a和b相加,但是表达相同意义的“a + b”语句,远比“a.add(b)”更直观也更容易让人理解。
在C++中,声明重载操作符的语法格式如下:
class 类名
{
public:
返回值类型 operator 操作符 (参数列表)
{
// 操作符的具体运算过程
}
};
从这里可以看到,重载操作符和类的成员函数在本质上虽然相同,但在形式上还是存在一些细微的差别。普通成员函数以标识符(不以数字为首的字符串)作为函数名,而重载操作符以“operator 操作符”作为函数名。其中的“operator”表示这是一个重载的操作符函数,而其后的操作符就是我们要定义的符号。
在使用上,当使用操作符连接两个对象进行运算时,实际上相当于调用第一个对象的操作符函数,而第二个对象则作为这个操作符函数的参数。例如,使用加法操作符对两个对象进行运算:
a + b;
这条语句实际上等同于:
a.operator + (b);
“a + b”表示调用的是对象a的操作符“operator +”,而对象b则是这个操作符函数的参数。理解了这些,要想让“father + mother”得到baby对象,只需要定义Father类的“+”操作符函数(因为father位于操作符之前,所以我们定义father所属的Father类的操作符),使其可以接受一个Mother类的对象作为参数,并返回一个Baby类的对象就可以了:
// 母亲类
class Mother
{
// 省略具体定义
};
// 孩子类
class Baby
{
public:
// 孩子类的构造函数
Baby(string strName)
: m_strName(strName)
{}
private:
// 孩子的名字
string m_strName;
};
// 父亲类
class Father
{
public:
// 重载操作符“+”,返回值为Baby类型,参数为Mother类型
Baby operator + (const Mother& mom)
{
// 创建一个Baby对象并返回,省略创建过程…
return Baby("MiaoMiao");
}
};
在Father类的重载操作符“+”中,它可以接受一个Mother类的对象作为参数,并在其中创建一个Baby类的对象作为操作符的返回值。这样就完整地表达了一个Father类的对象加上一个Mother类的对象得到一个Baby类的对象的意义,现在就可以方便地使用操作符“+”将Father类的对象和Mother类的对象相加而得到一个Baby类的对象了。需要注意的是,这里我们只是定义了Father类的“+”操作符,所以在用它计算的时候,只能是Father类的对象放在“+”之前,而如果希望Mother类的对象也可以放在“+”之前,相应地就同样需要定义Mother类的“+”操作符。
当然,需要注意,这里在class内重载运算符,第一个要省略,自动默认成一个this指针,类型是什么呢,比如在父亲类,this就是父亲类类型的指针,因此代码中operator+后面的参数列表才只有一个Mother,同时如果要调用Mother的私有类,还得在Mother里面添加Father类为友元类或者Baby Father::operator+(const Mother&),同时Father类要在Mother上面定义,因为用到了::,就必须在申明friend时将函数在class内申明同时要在申明friend前申明。
同时,应该要注意,重载运算符的访问等级应该是public。
一个栗子:
#include<cstdio>
using namespace std;
class Teacher;
class classmate;//申明类
// Teacher Teacher::operator+(classmate Chen);不能这么整,大概意思是因为类以内的函数不能在类外申明
class Teacher
{
public:
// 重载操作符“+”,返回值为Baby类型,参数为Mother类型
Teacher operator+(classmate Chen);
void ttu(int x){kk=x;}//一个接口
private:
int kk;
};
class classmate
{
friend Teacher Teacher::operator+(classmate Chen);
public:
void ttu(int x){tt=x;}//一个接口
private:
int tt;
};
Teacher Teacher::operator+(classmate Chen)
{
Teacher tt;tt.kk=this->kk+Chen.tt;
return tt;
}
int main()
{
Teacher s1,s3;classmate s2;
s1.ttu(1);s2.ttu(2);s3=s1+s2;
return 0;
}
上面在class内申明我们叫方法一。
方法二呢也是我个人比较喜欢的,在class外进行定义!
#include<cstdio>
using namespace std;
class Teacher;
class classmate;//申明类
Teacher operator+(Teacher,classmate);//申明
class Teacher
{
friend Teacher operator+(Teacher,classmate);//友元函数
public:
// 重载操作符“+”,返回值为Baby类型,参数为Mother类型
void ttu(int x){kk=x;}//一个接口
private:
int kk;
};
class classmate
{
friend Teacher operator+(Teacher,classmate);//友元函数
public:
void ttu(int x){tt=x;}//一个接口
private:
int tt;
};
Teacher operator+(Teacher MrChen,classmate Ken)//完成申明
{
Teacher tt;tt.kk=MrChen.kk+Ken.tt;
return tt;
}
int main()
{
Teacher s1,s3;classmate s2;
s1.ttu(1);s2.ttu(2);s3=s1+s2;
return 0;
}
4. class的构造函数与析构函数
建立对象
完成某个类的声明并且定义其成员函数之后,这个类就可以使用了。一个定义完成的类就相当于一种新的数据类型,我们可以用它来定义变量,也就是创建这个类所描述的对象,表示现实世界中的各种实体。比如前面完成了Teacher类的声明和定义,就可以用它来创建一个Teacher类的对象,用它来表示某一位具体的老师。创建类的对象的方式跟定义变量的方式相似,只需要将定义完成的类当作某种数据类型,用之前我们定义变量的方式来定义对象,而定义得到的变量就是这个类的对象。其语法格式如下:
类名 对象名;
其中,类名就是定义好的类的名字,对象名就是要定义的对象的名字,例如:
// 定义一个Teacher类型的对象MrChen,代表陈老师
Teacher MrChen;
这样就得到了一个Teacher类的对象MrChen,它代表学校中具体的某位陈老师。得到类的对象后,就可以通过“.”操作符访问这个类提供的公有成员,包括读写其公有成员变量和调用其公有成员函数,从而访问其属性或者是完成其动作。其语法格式如下:
对象名.公有成员变量;
对象名.公有成员函数;
例如,要让刚才定义的对象MrChen进行“上课”的动作,就可以通过“.”调用它的表示上课行为的成员函数:
// 调用对象所属类的成员函数,表示这位老师开始上课
MrChen.GiveLesson();
这样,该对象就会执行Teacher类中定义的GiveLesson()成员函数,完成上课的具体动作。
除了直接使用对象之外,跟普通的数据类型可以使用相应类型的指针来访问它所指向的数据一样,对于自己定义的类,我们同样可以把它当作数据类型来定义指针,把它指向某个具体的对象,进而通过指针来访问该对象的成员。例如:
// 定义一个可以指向Teacher类型对象的指针pMrChen,初始化为空指针
Teacher* pMrChen = nullptr;
// 用“&”操作符取得MrChen对象的地址赋值给指针pMrChen,
// 也就是将pMrChen指针指向MrChen对象
pMrChen = &MrChen;
这里,我们首先把Teacher类当作数据类型,使用像普通数据类型定义指针一样的形式,定义了一个可以指向Teacher类型对象的指针pMrChen,然后通过“&”操作符取得MrChen对象的地址并赋值给该指针,这样就将该指针指向了MrChen对象。
除了可以使用“&”操作符取得已有对象的地址,并用这个地址对指针进行赋值来将指针指向某个对象之外,还可以使用“new”关键字直接创建一个对象并返回该对象的地址,再用这个地址对指针进行赋值,同样可以创建新的对象并将指针指向这个新的对象。例如:
// 创建一个新的Teacher对象
// 并让pMrChen指针指向这个新对象
Teacher* pMrChen = new Teacher();
这里,“new”关键字会负责完成Teacher对象的创建,并返回这个对象的地址,然后再将这个返回的对象地址赋值给pMrChen指针,这样就同时完成了对象的创建和指针的赋值。
有了指向对象的指针,就可以利用“->”操作符(这个操作符是不是很像一根针?)通过指针访问该对象的成员。例如:
// 通过指针访问对象的成员
pMrChen->GiveLesson();
这里需要特别注意的是,跟普通的变量不同,使用“new”关键字创建的对象无法在其生命周期结束后自动销毁,所以我们必须在对象使用完毕后,用“delete”关键字人为地销毁这个对象,释放其占用的内存。例如:
// 销毁指针所指向的对象
delete pMrChen;
pMrChen = nullptr; // 指向的对象销毁后,重新成为空指针
“delete”关键字首先会对pMrChen所指向的Teacher对象进行一些Teacher类所特有的清理工作,然后释放掉这个对象所占用的内存,整个对象也就销毁了。当对象被销毁后,原来指向这个对象的指针就成了一个指向无效地址的“野指针”,为了防止这个“野指针”被错误地再次使用,在用delete关键字销毁对象后,紧接着我们通常将这个指针赋值为nullptr,使其成为一个空指针,避免它的再次使用。
同时,在定义时建一个Teacher对象也可以。
class Teacher
{
//......
}MrChen;
最佳实践:无须在“new”之后或者“delete”之前测试指针是否为nullptr
很多有经验的C++程序员都会强调,为了增加代码的健壮性,我们在使用指针之前,应该先判断指针是否为nullptr,确定其有效之后才能使用。应当说,在使用指针访问类的成员时,这样的检查是必要的。而如果是在“new”创建对象之后和“delete”销毁对象之前进行检查,则完全是画蛇添足。
一方面,使用“new”创建新对象时,如果系统无法为创建新的对象分配足够的内存而导致创建对象失败,则会抛出一个std::bad_alloc异常,“new”操作永远不会返回nullptr。另一方面,C++语言也保证,如果指针p是一个nullptr,则“delete p”不作任何事情,自然也不会有错误发生。所以,在使用“new”创建对象之后和“delete”关键字销毁对象之前,都无需对指针的有效性进行检查,直接使用就好。
// 创建对象
Teacher* p = new Teacher();
// 直接使用指针p访问对象…
// 销毁对象
delete p;
// 销毁对象之后,才需要将指针赋值为nullptr,避免“野指针”的出现
p = nullptr;
构建函数
在现实世界中,每个事物都有其生命周期,会在某个时候出现也会在另外一个时候消亡。程序是对现实世界的反映,其中的对象就代表了现实世界的各种事物,自然也就同样有生命周期,也会被创建和销毁。一个对象的创建和销毁,往往是其一生中非常重要的时刻,需要处理很多复杂的事情。例如,在创建对象的时候,需要进行很多初始化工作,设置某些属性的初始值;而在销毁对象的时候,需要进行一些清理工作,最重要的是把申请的资源释放掉,把打开的文件关闭掉,就像一个人离开人世时,应该把该还的钱还了,干干净净地走。为了完成对象的生与死这两件大事,C++中的类专门提供了两个特殊的函数——构造函数(Constructor)和析构函数(Destructor),它们的特殊之处就在于,它们会在对象创建和销毁的时候被自动调用,分别用来处理对象的创建和销毁的复杂工作。
由于构造函数会在对象创建的时候被自动调用,所以我们可以用它来完成很多不便在对象创建完成后进行的事情,比如可以在构造函数中对对象的某些属性进行初始化,使得对象一旦被创建就有比较合理的初始值。这就像人的性别是在娘胎里确定的,一旦出生就有了明确的性别。C++规定每个类都必须有构造函数,如果一个类没有显式地声明构造函数,那么编译器也会为它产生一个默认的构造函数,只是这个默认构造函数没有参数,也不做任何额外的事情而已。而如果我们想在构造函数中完成一些特殊的任务,就需要自己为类添加构造函数了。可以通过如下的方式为类添加构造函数:
class 类名
{
public:
类名(参数列表)
{
// 对类进行构造,完成初始化工作
}
};
注意一点,构造函数一般放在public里面,这样在构造的时候才会被调用,那么什么情况放在保护类或者私有类?后面扩展有讲。
那么现在就可以在定义对象的时候,将参数写在对象名之后的括号中,这种定义对象的形式会调用带参数的构造函数Teacher(string strName),进而给定这个对象的名字属性。
// 使用参数,创建一个名为“WangGang”的对象
Teacher MrWang("WangGang");
当然,如果没有参数,括号也可以省略不打。
// 使用参数,创建一个名为“WangGang”的对象
Teacher MrWang;//默认调用public里面的构造函数
如果定义class数组怎么办?
#include<cstdio>
#include<cstring>
using namespace std;
class human
{
public:
human(int kk)
{
tt=kk;
}
int tt;
};
int main()
{
human ss[20](2);//20个位置的构造函数的参数都是2
printf("%d\n",ss[2].tt);
return 0;
}
或者
#include<cstdio>
#include<cstring>
using namespace std;
class human
{
public:
human(int kk)
{
tt=kk;
}
int tt;
}ss[20](2);//20个位置的构造函数的参数都是2
int main()
{
printf("%d\n",ss[2].tt);
return 0;
}
不过VScode给我弹出了一个警告,希望大家知道的可以回复我一下,谢谢。
当然,有时候我们会遇到一个尴尬的情况,什么?
就是当我们在构造函数中要给变量赋值的时候打的心慌慌。
代码又长,十分烦
所以C++还有一种打法。
class 类名
{
public:
// 使用初始化属性列表的构造函数
类名(参数列表)
: 成员变量1(初始值1),成员变量2(初始值2)… // 初始化属性列表
{
}
// 类的其他声明和定义
};
在进入构造函数执行之前,系统将完成成员变量的创建并使用其后括号内的初始值对其进行赋值。这些初始值可以是构造函数的参数,也可以是成员变量的某个合理初始值。如果一个类有多个成员变量需要通过这种方式进行初始化,那么多个变量之间可以使用逗号分隔。
不过目前并没有找到可以在:后初始化数组的方法,只能在函数里面打memset来初始化了QAQ。
当然,并不是只要求class只能有一个构造函数,还可有多个,不过构造函数的参数列表不能完全相同,至于为什么,在多态里面的扩展:重载里面会提到相同函数名时C++所用到的重写。
一个小栗子:
#include<cstdio>
#include<cstring>
using namespace std;
class Teacher
{
public:
// 使用初始化属性列表的构造函数
Teacher(int x)
: a(x) // 初始化属性列表
{
;
}
Teacher(int x,int y)
: a(x+y)
//委托别的构造函数的构造函数好像没有初始化列表
{
;
}
int a;
// 类的其他声明和定义
}kk(1,2);//两个参数,代表调用Teacher(int x,int y)
int main()
{
printf("%d\n",kk.a);
return 0;
}
在C++中,根据初始条件的不同,我们往往需要用多种方式创建一个对象,所以一个类常常有多个不同参数形式的构造函数,分别负责以不同的方式创建对象。而在这些构造函数中,往往有一些大家都需要完成的工作,一个构造函数完成的工作很可能是另一个构造函数所需要完成工作的一部分。
为了避免重复代码的出现,我们只需要在某个特定构造函数中实现这些共同功能,而在需要这些共同功能的构造函数中,直接调用这个特定构造函数就可以了。这种方式被称为委托调用构造函数
#include<cstdio>
#include<cstring>
using namespace std;
class Teacher
{
public:
// 使用初始化属性列表的构造函数
Teacher(int x)
: a(x) // 初始化属性列表
{
;
}
Teacher(int x,int y):Teacher(x)//委托调用另外一个构造函数
//委托别的构造函数的构造函数好像没有初始化列表
{
;
}
int a;
// 类的其他声明和定义
}kk(1,2);
int main()
{
printf("%d\n",kk.a);
return 0;
}
同时我也有疑惑:委托别的构造函数的构造函数好像没有初始化列表,是这样吗?
希望大家在看博客的同时知道或实验出来的话可以教一下我,毕竟我看大佬的博客好像也没讲QAQ,谢谢大家QAQ
当然,因为对委托调用构造函数有一点疑惑,所以我也不打算乱用
析构函数
当一个使用定义变量的形式创建的对象使用完毕离开其作用域之后,这个对象会被自动销毁。而对于使用new关键字创建的对象,则需要在使用完毕后,通过delete关键字主动销毁对象。但无论是哪种方式,对象在使用完毕后都需要销毁,也就是完成一些必要的清理工作,比如释放申请的内存、关闭打开的文件等。
跟对象的创建比较复杂,需要专门的构造函数来完成一样,对象的销毁也比较复杂,同样需要专门的析构函数来完成。同为类当中负责对象创建与销毁的特殊函数,两者有很多相似之处。首先是它们都会被自动调用,只不过一个是在创建对象时,而另一个是在销毁对象时。其次,两者的函数名都是由类名构成,只不过析构函数名在类名前加了个“~”符号以跟构造函数名相区别。再其次,两者都没有返回值,两者都是公有的(public)访问级别。最后,如果没有必要,两者在类中都是可以省略的。如果类当中没有显式地声明构造函数和析构函数,编译器也会自动为其产生默认的函数。而两者唯一的不同之处在于,构造函数可以有多种形式的参数,而析构函数却不接受任何参数。析构函数格式:
class 类名
{
public: // 公有的访问级别
// …
// 析构函数
// 在类名前加上“~”构成析构函数名
~类名() // 不接受任何参数
{
// 进行清理工作
};
// …
};
当然,因为构造函数的问题,所以我也不知道析构函数有没有委托调用这一说,所以说QMQ,拜托了。。。(不过应该是没有的)
扩展
设计模式:像建筑师一样思考
上面的工资程序是否已经太过复杂,让你的头感到有点隐隐作痛?
如果是,那么你一定需要来一片程序员专用的特效止痛片——设计模式。
设计模式(Design Pattern)是由Erich Gamma等4人在90年代从建筑设计领域引入到软件设计领域的一个概念。他们发现,在建筑领域存在这样一种复用设计方案的方法,那就是在某些外部环境相似,功能需求相同的地方,建筑师们所采用的设计方案也是相似的,一个地方的设计方案同时可以在另外一个相似的地方复用。这样就大大提高了设计的效率节约了成本。他们将这一复用设计的方法从建筑领域引入到软件设计领域,从而提出了设计模式的概念。他们总结了软件设计领域中最常见的23种模式,使其成为那些在软体设计中普遍存在(反复出现)的各种问题的解决方案。并且,这些解决方案是经过实践检验的,当我们在开发中遇到(因为这些问题的普遍性,我们也一定会经常遇到)相似的问题时,只要直接采用这些解决方案,复用前人的设计成果就可以很好地解决今人的问题,这样可以节约设计成本,大大提高我们的开发效率。
那么,设计模式是如何做到这一点的呢?设计模式并不直接用来完成代码的编写,而是描述在各种不同情况下,要怎样解决问题的一种方案。面向对象设计模式通常以类或对象来描述其中的各个实体之间的关系和相互作用,但不涉及用来完成应用程序的特定类或对象。设计模式能使不稳定依赖于相对稳定、具体依赖于相对抽象,尽量避免会引起麻烦的紧耦合,以增强软件设计适应变化的能力。这样可以让我们的软件具有良好的结构,能够适应外部需求的变化,能够避免软件因为不断增加新功能而显得过于臃肿,最后陷入需求变化的深渊。另外一方面,设计模式都是前人优秀设计成果的总结,在面对相似问题的时候,直接复用这些经过实践检验的设计方案,不仅可以保证我们设计的质量,还可以节省设计时间,提高开发效率。从某种意义上说,设计模式可以说是程序员们的止痛药——再也没有需求变化带来的痛苦。
为了让大家真正地感受到设计模式的魅力,我们来看一看众多设计模式当中最简单的一个模式——单件模式(Singleton Pattern)。顾名思义,单件模式就是让某个类在任何时候都只能创建唯一的一个对象。这样的需求看起来比较特殊,但是有这种需求的场景却非常广泛,比如,我们要设计开发一个打印程序,我们只希望有一个Print Spooler对象,以避免两个打印动作同时输送至打印机中;在数据库连接中,我们也同样希望在程序中只有唯一的一个数据库连接以节省资源;在一个家庭中,我们都是一个老公只能有一个老婆,如果有多个老婆肯定会出问题。单件模式,就是用来保证对象能够被创建并且只能够被创建一次。在程序中,所有客户使用的对象都是唯一的一个对象。
我们都知道,对象的创建是通过构造函数来完成的,所以单件模式的实现关键是将类的构造函数设定为private访问级别,让外界无法通过构造函数自由地创建这个类的对象。取而代之的是,它会提供一个公有的静态的创建函数来负责对象的创建,而在这个创建函数中,我们就可以判断唯一的对象是否已经创建。如果尚未创建,则调用自己的构造函数创建对象并返回,如果已经创建,则直接返回已经创建的对象。这样,就保证了这个类的对象的唯一性。一个栗子:
// 使用单件模式
class 类名
{
// 其他属性和行为
//...
// 将构造函数私有化(private)
private:
SalarySys()
:m_nCount(0),
m_strFileName("SalaryData.txt")
{
// …
}
public:
// 提供一个公有的(public,为了让客户能够访问)静态的(static,为了让
// 客户可以在不创建对象的情况下直接访问)创建函数,
// 供外界获取构造函数的唯一对象
// 在这个函数中,对对象的创建行为进行控制,以保证对象的唯一性
static 类名* getInstance()//打*号的原因是因为他返回的是(类名)的指针
{
// 如果唯一的实例对象还没有创建,则创建实例对象
if ( nullptr == m_pInstance )
m_pInstance = new SalarySys();
// 如果已经创建实例对象,则直接返回这个实例对象
return m_pInstance;
};
private:
// 静态的对象指针,指向唯一的实例对象
// 为静态的唯一实例对象指针赋初始值,表示对象尚未创建
static 类名* m_pInstance = nullptr;
};
// …
int main()
{
// 第一次调用getInstance()函数,唯一的(类名)对象尚未创建,
// 则创建相应的对象并返回指向这个对象的指针
类名* 变量名1 = 类名::getInstance();
// …
// 第二次调用getInstance()函数,这时(类名)的对象已经创建,
// 则不再创建新对象而直接返回指向那个已创建对象的指针,保证对象的唯一性
类名* 变量名2 = 类名::getInstance();
// …
// 释放已创建的对象, pSalarySys1和pSalarySys2指向的是同一个对象,
// 使用pSalarySys1或pSalarySys2释放这个对象是等效的,并只需要释放一次
delete 变量名1;
变量名1 = 变量名2 = nullptr;
return 0;
}
经过单件模式的改写,对象的构造函数已经变成私有的,在主函数中就不能直接使用new关键字来创建一个实例对象,而只能通过它提供的公有的getInstance()函数来获得这个类的唯一实例对象。这里需要注意的是,为了实现单件模式,我们在类的m_pInstance成员变量和getInstance()成员函数前都加上了static关键字对其进行修饰,这表示这个成员变量和成员函数都将是静态的,我们可以通过类作用域符号(“::”)直接访问类的静态成员而无需任何类的实例对象。静态成员的这种特性,为我们以私有的构造函数之外的成员函数来创建类的对象提供了可能。同时,在getInstance()函数中我们可以对对象的创建行为进行控制:如果对象尚未创建,则创建对象;如果对象已经创建完成,则直接返回已经创建完成的对象,这样就有效地保证了其实例对象的唯一性。
纵观整个单件模式,它的实现关键是将构造函数私有化(用private修饰),这才构成了这个对象只能自己构建自己,防止了外界创建这个类的对象,将创建对象的权利收归自己所有。通过这样将自己封闭起来,也就只能孤孤单单一个人了。这个模式对于那些仍在过“光棍节”的朋友同样有启发意义,我们之所以是单件,并不是我们无法创建对象,只是因为我们自己把自己封闭(private)起来了,而要想摆脱单件的状态,只需要把我们的心敞开(public),自然会有人来敲门的。从看似枯燥乏味的程序代码中,我们也能感悟出人生哲理,真是人生如代码,代码似人生。
5. 拷贝构造函数
在C++世界中,除了需要使用构造函数直接创建一个新的对象之外,有时还需要根据已经存在的某个对象创建它的一个副本,就像那只叫做多利的羊一样,我们希望根据一只羊创建出来另外一只一模一样的羊。例如:
// 调用构造函数创建一个新对象shMother
Sheep shMother;
// 对shMother进行一些操作…
// 利用shMother对象创建一个一模一样的新对象shDolly作为其副本
Sheep shDolly(shMother);
在这里,首先创建了一个Sheep类的新对象shMother,然后对它进行了一些操作改变其成员变量等,接着用这个对象作为Sheep类的构造函数的参数,创建一个与shMother对象一模一样的副本shDolly。我们将这种可以接受某个对象作为参数并创建一个新对象作为其副本的构造函数称为拷贝构造函数。拷贝构造函数实际上是构造函数的表亲,在语法格式上,两者基本相似,两者拥有相同的函数名,只是拷贝构造函数的参数是这个类对象的引用,而它所创建得到的对象,是对那个作为参数的对象的一个拷贝,是它的一个副本。跟构造函数相似,默认情况下,如果一个类没有显式地定义其拷贝构造函数,编译器会为其创建一个默认的拷贝构造函数,以内存拷贝的方式将旧有对象内存空间中的数据拷贝到新对象的内存空间,以此来完成新对象的创建。因为我们上面的Sheep类没有定义拷贝构造函数,上面代码中shDolly这个对象的创建就是通过这种默认的拷贝构造函数的方式完成的。
使用default和delete关键字控制类的默认行为
为了提高开发效率,对于类中必需的某些特殊函数,比如构造函数、析构函数、赋值操作符等,如果我们没有在类当中显式地定义这些特殊函数,编译器就会为我们生成这些函数的默认版本。虽然这种机制可以为我们节省很多编写特殊函数的时间,但是在某些特殊情况下,比如我们不希望对象被复制,就不需要编译器生成的默认拷贝构造函数。这时候这种机制反倒成了画蛇添足,多此一举了。
为了取消编译器的这种默认行为,我们可以使用delete关键字来禁用某一个默认的特殊函数。比如,在默认情况下,即使我们没在类当中定义拷贝构造函数,编译器也会为我们生成默认的拷贝构造函数进而可以通过它完成对象的拷贝复制。而有的时候,我们不希望某个对象被复制,那就需要用delete禁用类当中的拷贝构造函数和赋值操作符,防止编译器为其生成默认函数:
class Sheep
{
// ...
// 禁用类的默认赋值操作符
Sheep& operator = (const Sheep&) = delete;
// 禁用类的默认拷贝构造函数
Sheep(const Sheep&) = delete;
};
现在,Sheep类就没有默认的赋值操作符和拷贝构造函数的实现了。如果这时还想对对象进行复制,就会导致编译错误,从而达到禁止对象被复制的目的。例如:
// 错误的对象复制行为
Sheep shDolly(shMother); // 错误:Sheep类的拷贝构造函数被禁用
Sheep shDolly = shMother; // 错误:Sheep类的赋值操作符被禁用
与delete关键字禁用默认函数相反地,我们也可以使用default关键字,显式地表明我们希望使用编译器为这些特殊函数生成的默认版本。还是上面的例子,如果我们希望对象可以以默认方式被复制:
class Sheep
{
// ...
// 使用默认的赋值操作符和拷贝构造函数
Sheep& operator = (const Sheep&) = default;
Sheep(const Sheep&) = default;
};
显式地使用default关键字来表明使用类的默认行为,对于编译器来说显然是多余的,因为即使我们不说明,它也会那么干。但是对于代码的阅读者而言,使用default关键字显式地表明使用特殊函数的默认版本,则意味着我们已经考虑过,这些特殊函数的默认版本已经满足我们的要求,无需自己另外定义。而将默认的操作留给编译器去实现,不仅可以节省时间提高效率,更重要的是,减少错误发生的机会,并且通常会产生更好的目标代码。
在大多数情况下,默认版本的拷贝构造函数已经能够满足我们拷贝复制对象的需要了,我们无需显式地定义拷贝构造函数。但在某些特殊情况下,特别是类当中有指针类型的成员变量的时候,以拷贝内存方式实现的默认拷贝构造函数只能复制指针成员变量的值,而不能复制指针所指向的内容,这样,新旧两个对象中不同的两个指针却指向了相同的内容,这显然是不合理的。默认的拷贝构造函数无法正确地完成这类对象的拷贝。在这种情况下,就需要自己定义类的拷贝构造函数,以自定义的方式完成像指针成员变量这样的需要特殊处理的内容的拷贝工作。例如,有一个Computer类,它有一个指针类型的成员变量m_pKeyboard,指向的是一个独立的Keboard对象,这时就需要定义Compuer类的拷贝构造函数来完成特殊的复制工作:
// 键盘类,因为结构简单,我们使用struct来定义
struct Keyboard
{
// 键盘的型
string m_strModel;
};
// 定义了拷贝构造函数的电脑类
class Computer
{
public:
// 默认构造函数
Computer()
: m_pKeyboard(nullptr),m_strModel("")
{}
// 拷贝构造函数,参数是const修饰的Computer类的引用
Computer(const Computer& com)
: m_strModel(com.m_strModel) // 直接使用初始化属性列表完成对象类型成员变量m_strModel的复制
{
// 创建新对象,完成指针类型成员变量m_pKeyboard的复制
// 获得已有对象com的指针类型成员变量m_pKeyboard
Keyboard* pOldKeyboard = com.GetKeyboard();
// 以pOldKeyboard所指向的Keyboard对象为蓝本,
// 创建一个新的Keyboard对象,并让m_Keyboard指向这个对象
if( nullptr != pOldKeyboard )
// 这里Keyboard对象的复制使用的是Keyboard类的默认拷贝构造函数
m_pKeyboard = new Keyboard(*(pOldKeyboard));
else
m_pKeyboard = nullptr; // 如果没有键盘
}
// 析构函数,
// 对于对象类型的成员变量m_strModel,会被自动销毁,无需在析构函数中进行处理
// 对于指针类型的成员变量m_pKeyboard,则需要在析构函数中主动销毁
~Computer()
{
delete m_pKeyboard;
m_pKeyboard = nullptr;
}
// 成员函数,设置或获得键盘对象指针
void SetKeyboard(Keyboard* pKeyboard)
{
m_pKeyboard = pKeyboard;
}
Keyboard* GetKeyboard() const
{
return m_pKeyboard;
}
private:
// 指针类型的成员变量
Keyboard* m_pKeyboard;
// 对象类型的成员变量
string m_strModel;
};
在这段代码中,我们为Computer类创建了一个自定义的拷贝构造函数。在这个拷贝构造函数中,对于对象类型的成员变量m_strModel,我们直接使用初始化属性列表就完成了成员变量的拷贝。而对于指针类型成员变量m_pKeyboard而言,它的拷贝并不是拷贝这个指针的值本身,而应该拷贝的是这个指针所指向的对象。所以,对于指针类型的成员变量,并不能直接采用内存拷贝的形式完成拷贝,那样只是拷贝了指针的值,而指针所指向的内容并没有得到拷贝。要完成指针类型成员变量的拷贝,首先应该获得已有对象的指针类型成员变量,进而通过它获得它所指向的对象,然后再创建一个副本并将新对象中相应的指针类型成员变量指向这个对象,比如我们这里的“m_pKeyboard = new Keyboard(*(pOldKeyboard));”,这样才完成了指针类型成员变量的复制。这个我们自己定义的拷贝构造函数不仅能够拷贝Computer类的对象类型成员变量m_strModel,也能够正确地完成指针类型成员变量m_pKeyboard的拷贝,最终才能完成对Computer对象的拷贝。例如:
// 引入断言所在的头文件
#include <assert.h>
//…
// 创建一个Computer对象oldcom
Computer oldcom;
// 创建oldcom的Keyboard对象并修改其属性
Keyboard keyboard;
keyboard.m_strModel = "Microsoft-101";
// 将键盘组装到oldcom上
oldcom.SetKeyboard(&keyboard);
// 以oldcom为蓝本,利用Computer类的拷贝构造函数创建新对象newcom
// 新的newcom对象是oldcom对象的一个副本
Computer newcom(oldcom);
// 使用断言判断两个Computer对象是否相同,
// 电脑型号应该相同
assert(newcom.GetModel() == oldcom.GetModel());
// 不同的Computer对象应该拥有不同的Keyboard对象
assert( newcom.GetKeyboard() != oldcom.GetKeyboard() );
// 因为是复制,不同的Keyboard对象应该是相同的型号
assert( newcom.GetKeyboard()->m_strModel
== oldcom.GetKeyboard()->m_strModel );
在C++中,除了使用拷贝构造函数创建对象的副本作为新的对象之外,在创建一个新对象之后,还常常将一个已有的对象直接赋值给它来完成新对象的初始化。例如:
// 创建一个新的对象
Computer newcom;
// 利用一个已有的对象对其进行赋值,完成初始化
newcom = oldcom;
赋值的过程,实际上也是一个拷贝的过程,就是将等号右边的对象拷贝到等号左边的对象。跟类的拷贝构造函数相似,如果没有显式地为类定义赋值操作符,编译器也会为其生成一个默认的赋值操作符,以内存拷贝的方式完成对象的赋值操作。因为同样是以内存拷贝的方式完成对象的复制,所以当类中有指针型成员变量时,也同样会遇到只能拷贝指针的值而无法拷贝指针所指向的内容的问题。因此,要完成带有指针型成员变量的类对象的赋值,必须对类的赋值操作符进行自定义,在其中以自定义的方式来完成指针型成员变量的复制。例如,Computer类中含有指针型成员变量m_pKeybard,可以这样自定义它的赋值操作符来完成其赋值操作。
// 定义了赋值操作符“=”的电脑类
class Computer
{
public:
// 自定义的赋值操作符
Computer& operator = (const Computer& com)
{
// 判断是否是自己给自己赋值
// 如果是自赋值,则直接返回对象本身
// 这里的this指针,是类当中隐含的一个指向自身对象的指针。
if( this == &com ) return *this;
// 直接完成对象型成员变量的赋值
m_strModel = com.m_strModel;
// 创建旧有对象的指针型成员变量所指对象的副本
// 并将被赋值对象相应的指针型成员变量指向这个副本对象
m_pKeyboard = new Keyboard(*(com.GetKeyboard()));
}
// …
};
在上面的赋值操作符函数中,我们首先判断这是不是一个自赋值操作。所谓自赋值,就是自己给自己赋值。例如:
// 用newcom给newcom赋值
newcom = newcom;
严格意义上说,这种自赋值操作是没有意义的,应该算是程序员的一个失误。但作为一个设计良好的赋值操作符,应该可以检测出这种失误并给予恰当的处理,将程序从程序员的失误中解救出来:
// 判断是否是自赋值操作
// 将this指针与传递进来的指向com对象的指针进行比较
// 如果相等,就是自赋值操作,直接返回这个对象本身
if( this == &com) return *this;
在赋值操作符函数中如果检测到这种自赋值操作,它就直接返回这个对象本身从而避免后面的复制操作。如果不是自赋值操作,对于对象型成员变量,使用“=”操作符直接完成其赋值;而对于指针型成员变量,则采用跟拷贝构造函数相似的方式,通过创建它所指向的对象的副本,并将左侧对象的相应指针型成员变量指向这个副本对象来完成其赋值。
另外值得注意的一点是,赋值操作符的返回值类型并不一定是这个类的引用,我们使用void代替也是可以的。例如:
class Computer
{
public:
// 以void作为返回值类型的赋值操作符
void operator = (const Computer& com)
{
// …
}
// …
};
以上的代码虽然在语法上正确,也能够实现单个对象的赋值操作,但是却无法实现如下形式的连续赋值操作:
newcom1 = (newcom2 = oldcom );
也就是先将oldcom赋值给newcom2(如果返回值类型是void,这一步是可以完成的),然后将“newcom2 = oldcom”的运算结果赋值给newcom1,而如果赋值操作符的返回值类型是void,也就意味着“newcom2 = oldcom”的运算结果是void类型,我们显然是不能将一个void类型数据赋值给一个Computer对象的。所以,为了实现上面这种形式的连续赋值,我们通常以这个类的引用(Computer&)作为赋值操作符的返回值类型,并在其中返回这个对象本身(“return *this”),已备用做下一步的继续赋值操作。
初始化列表构造函数
除了我们在上文中介绍的普通构造函数和拷贝构造函数之外,为了让对象的创建形式更加灵活,C++还提供了一种可以接受一个初始化列表(initializer list)为参数的构造函数,因此这种构造函数也被称为初始化列表构造函数。初始化列表由一对大括号(“{}”)构造而成,可以包含任意多个相同类型的数据元素。如果我们希望可以通过不定个数的相同类型数据来创建某个对象,比如,一个工资对象管理着不定个数的工资项目,包括基本工资,奖金,提成,补贴等等,有的人只有基本工资,而有的人全都有,为了创建工资对象形式上的统一,我们就希望这些不定个数的工资项目都可以用来创建工资对象。这时,我们就需要通过实现工资类的初始化列表构造函数来完成这一任务:
#include <iostream>
#include <vector>
#include <initializer_list> // 引入初始化列表所在头文件
using namespace std;
// 工资类
class Salary
{
public:
// 初始化列表构造函数
// 工资数据为int类型,所以其参数类型为initializer_list<int>
Salary(initializer_list<int> s)
{
// 以容器的形式访问初始化列表
// 获取其中的工资项目保存到工资类的vector容器
for(int i : s)
m_vecSalary.push_back(i);
}
// ..
// 获取工资总数
int GetTotal()
{
int nTotal = 0;
for(int i : m_vecSalary)
nTotal += i;
return nTotal;
}
private:
// 保存工资数据的vector容器
vector<int> m_vecSalary;
};
int main()
{
// 陈老师只有基本工资,“{}”表示初始化列表
Salary sChen{2200};
// 王老师既有基本工资还有奖金和补贴
Salary sWang{5000,9500,1003};
// 输出结果
cout<<"陈老师的工资:"<<sChen.GetTotal()<<endl;
cout<<"王老师的工资:"<<sWang.GetTotal()<<endl;
return 0;
}
从这里可以看到,虽然陈老师和王老师的工资项目各不相同,但是通过初始化列表构造函数,他们的工资对象都可以以统一的形式创建。而这正是初始化列表的意义所在,它可以让不同个数的同类型数据以相同的形式作为函数参数。换句话说,如果我们希望某个函数可以接受不定个数的同类型数据为参数,就可以用初始化列表作为参数类型。例如,我们可以为Salary类添加一个AddSalary()函数,用初始化列表作为参数,它就可以向Salary对象添加不定个数的工资项目:
// 以初始化列表为参数的普通函数
void AddSalary(initializer_list<int> s)
{
for(int i : s)
m_vecSalary.push_back(i);
}
// …
// 后来发现是陈老师的奖金和补贴忘了计算了,给他加上
// 这里的大括号{}就构成初始化列表
sChen.AddSalary({8200,6500});
6. 继承
考虑这样一个现实问题,学校中有多个老师,每个老师的名字、年龄等属性都各不相同,但这些老师都会备课上课,具有相同的行为。那么,我们如何在程序中表现这些老师呢?老师的具体个体虽多,但他们都属于同一类事物——老师。在C++中,我们用类的概念来描述某一类事物,而抽象正是这个过程的第一道工序。抽象一般分为属性抽象和行为抽象两种。前者寻找一类事物所共有的属性,比如老师们都有年龄、姓名等描述其状态的数据,然后用变量将它们表达出来,比如用m_nAge变量表达年龄,用m_strName变量表达姓名;而后者则寻找这类事物所共有的行为,比如老师都会备课、上课等,然后用函数将它们表达出来,比如用PrepareLesson()函数表达老师的备课行为,用GiveLesson()函数表达其上课行为。从这里也可以看出,整个抽象过程,是一个从具体(各个老师)到一般(变量和函数)的过程。
如果说抽象是将同类事物的共有属性和行为提取出来并将其用变量和函数表达出来,那么封装机制则是将它们捆绑在一起形成一个完整的类。在C++语言中,我们可以使用以前介绍的类(class)概念来封装分析得到的变量和函数,使其成为类的成员,从而表现这类事物的属性和行为。比如老师这类事物就可以封装为:
// 用Teacher类封装老师的属性和行为
class Teacher
{
// 构造函数
public:
// 根据名字构造老师对象
Teacher(string strName)
{
m_strName = strName;
};
// 用成员函数描述老师的行为
public:
void PrepareLesson(); // 备课
void GiveLesson(); // 上课
void ReviewHomework(); // 批改作业
// 其它成员函数…
// 用成员变量描述老师的属性
protected:
string m_strName; // 姓名
int m_nAge; // 年龄
bool m_bMale; // 性别
int m_nDuty; // 职务
private:
};
通过封装,可以将老师这类事物所共有的属性和行为紧密结合在Teacher类中,形成一个可重用的数据类型。从现实的老师到Teacher类,是一个从具体到抽象的过程,现在有了抽象的Teacher类,就可以用它来定义某个对象,进而用这个对象来描述某位具体的老师,这又是一个从抽象到具体的过程。例如:
// 定义Teacher类对象描述学校中的某位陈老师
Teacher MrChen("ChenLiangqiao");
// 学校中的某位王老师
Teacher MrWang("WangGang");
虽然MrChen和MrWang这两个对象都是Teacher类的对象,但是因为它们的属性不同,所以可以描述现实世界中的两位不同的老师。
通过类的封装,还可以很好地实现对事物的属性和行为的隐藏。因为访问控制的限制,外界是无法直接访问类的隐藏信息的,对于类当中的一些敏感数据,我们可以将其设置为保护或私有类型,这样就可以防止其被意外修改,实现对数据的隐藏。另外一方面,封装好的类通过特定的外部接口(公有的成员函数)向外提供服务。在这个过程中,外界看到的只是服务接口的名字和需要的参数,而并不知道类内部这些接口到底是如何具体实现的。这就很好地对外界隐藏了接口的具体实现细节,而仅仅把外界最关心的服务接口直接提供给它。通过这种方式,类实现了对行为的隐藏。
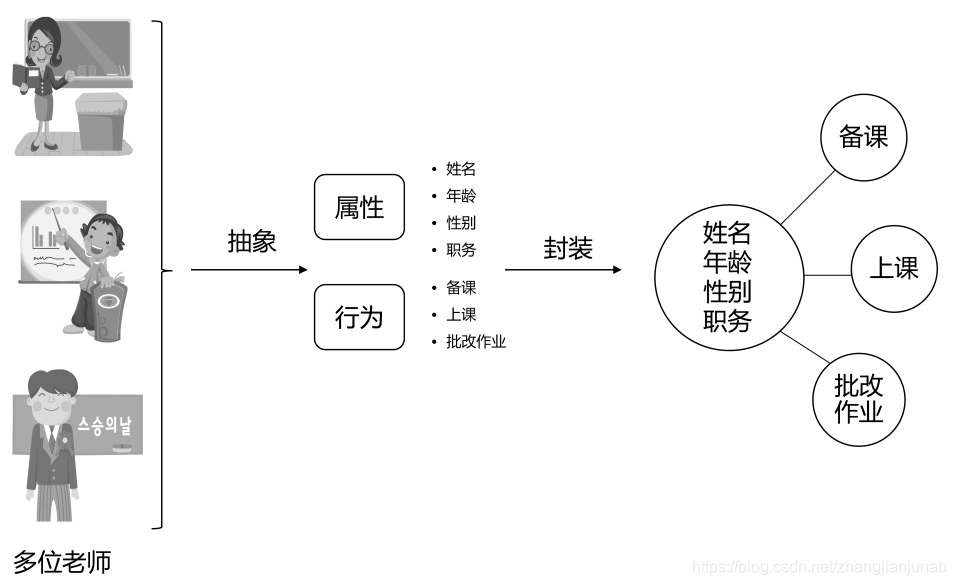
抽象与封装,用来将现实世界的事物转变成C++世界中的各个类,也就是用程序语言来描述现实世界。面向过程思想也有抽象这个过程,只是它的抽象仅针对现实世界中的过程,而面向对象思想的抽象不仅包括事物的数据,同时还包括事物的行为,更进一步地,面向对象利用封装将数据和行为有机地结合在一起而形成类,从而更加真实地反映现实世界。抽象与封装,完成了从现实世界中的具体事物到C++世界中类的过程,是将现实世界程序化的第一步,也是最重要的一步。
在理解了类机制是如何实现面向对象思想的封装特性之后,继续分析上面的例子。在现实世界中,我们发现老师和学生这两类不同的事物有一些相同的属性和行为,比如都有姓名、年龄、性别,都能走路、说话、吃饭等。为什么不同的事物会有相同的属性和行为呢?这是因为这些特征都是人类所共有的,老师和学生都是人类的一个子类别,所以都具有这些人类共同的属性和行为。像这种子类别和父类别拥有相同属性和行为的现象非常普遍。比如小汽车、卡车是汽车的某个子类别,它们都具有汽车的共有属性(发动机)和行为(行驶);电视机、电冰箱是家用电器的某个子类别,它们都具有家用电器的共有属性(用电)和行为(开启)。
在C++中,我们用类来表示某一类别的事物。既然父子两个类别的事物可能有相同的属性和行为,这也就意味着父类和子类当中应该有大量相同的成员变量和成员函数。那么,对于这些相同的成员,是否需要在父子两个类中都定义一次呢?显然不是。为了描述现实世界中的这种父类别和子类别之间的关系,C++提供了继承的机制。我们把表示父类别的类称为基类或者父类,而把从基类继承产生的表示子类别的类称为派生类或子类。继承允许我们在保持父类原有特性的基础上进行更加具体的说明或者扩展,从而形成新的子类。例如,可以说“老师是会上课的人”,那么就可以让老师这个子类从人这个父类继承,对于那些表现人类共有属性和行为的成员,老师类无需再次定义而直接从人类遗传获得,然后在老师子类中再添加上老师特有的表示上课行为的函数,通过继承与发展,我们就获得了一个既有人类的共有属性和行为,又有老师特有行为的老师类。
所谓继承,就是获得从父辈传下来的财富。在现实世界中,这个财富可能是金银珠宝,也可能是淳淳家风,而在C++世界中,这个财富就是父类的成员变量和成员函数。通过继承,子类可以轻松拥有父类的成员。而更重要的是,通过继承可以对父类的成员进行进一步的细化或者扩充来满足新的需求形成新的类。这样,当复用旧有的类形成新类时,只需要从旧有的类继承,然后修改或者扩充需要的成员即可。有了继承机制,C++不仅能够提高开发效率,同时也可以应对不断变化的需求,因此它也就成为了消灭“软件危机”的有力武器。
下面来看一个实际的例子,在现实世界中,有这样一颗“继承树”。
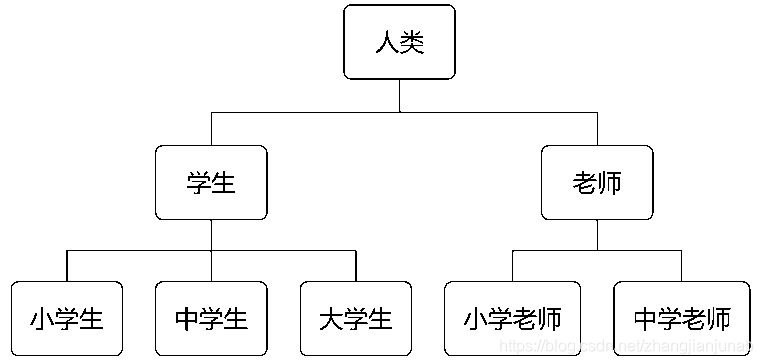
从这棵“继承树”中可以看到,老师和学生都继承自人类,这样,老师和学生就具有了人类的属性和行为,而小学生、中学生、大学生继承自学生这个类,他们不但具有人的属性和行为,同时还具有学生的属性和行为。通过继承,派生类不用再去重复设计和实现基类已有的属性和行为,只要直接通过继承就拥有了基类的属性和行为,从而实现设计和代码最大限度上的复用。
在C++中,派生类的声明方式如下:
class 派生类名 : 继承方式 基类名1, 继承方式 基类名2…
{
// 派生类新增加的属性和行为…
};
其中,派生类名就是我们要定义的新类的名字,而基类名是已经定义的类的名字。一个类可以同时继承多个类,如果只有一个基类,这种情况称为单继承,如果有多个基类,则称为多继承,这时派生类可以同时得到多个基类的特征,就如同我们身上既有父亲的特征,同时也有母亲的特征一样。但是,我们需要注意的是,多继承可能会带来成员的二义性,因为两个基类可能拥有同名的成员,如果都遗传到派生类中,则派生类中会出现两个同名的成员,这样在派生类中通过成员名访问来自基类的成员时,就不知道到底访问的是哪一个基类的成员,从而导致程序的二义性。所以,多继承只在极少数必要的时候才使用,更多时候我们使用的是单继承。
跟类成员的访问控制类似,继承方式也有public、protected和private三种。不同的继承方式决定了派生类如何访问从基类继承下来的成员,反映的是派生类和基类之间的关系:
(1) public。
public继承被称为类型继承,它表示派生类是基类的一个子类型,而基类中的公有和保护类型成员连同其访问级别直接遗传给派生类,不做任何改变。在基类中的public成员在派生类中也同样是public成员,在基类中的protected成员在派生类中也是protected成员。public继承反映了派生类和基类之间的一种“is-a”的关系,也就是父类别和子类别的关系。例如,老师是一个人(Teacher is-a Human),所以Teacher类应该以public方式继承自Human类。 public所反映的这种父类别和子类别的关系在现实世界中非常普遍,大到生物进化,小到组织体系,都可以用public继承来表达,所以它也是C++中最为常见的一种继承方式。
(2) private。
private继承被称为实现继承,它把基类的公有和保护类型成员都变成自己的私有(private)成员,这样,派生类将不再支持基类的公有接口,它只希望可以重用基类的实现而已。private继承所反映的是一种“用…实现”的关系,如果A类private继承自B类,仅仅是因为A类当中需要用到B类的某些已经存在的代码但又不想增加A类的接口,并不表示A类和B类之间有什么概念上的关系。从这个意义上讲,private继承纯粹是一种实现技术,对设计而言毫无意义。
(3) protected。
protected继承把基类的公有和保护类型成员变成自己的protected类型成员,以此来保护基类的所有公有接口不再被外界访问,只能由自身及自身的派生类访问。所以,当我们需要继承某个基类的成员并让这些成员可以继续遗传给下一代派生类,而同时又不希望这个基类的公有成员暴露出来的时候,就可以采用protected继承方式。
在了解了派生类的声明方式后,就可以用具体的代码来描述上面这棵继承树所表达的继承关系了。
// 定义基类Human
class Human
{
// 人类共有的行为,可以被外界访问,
// 访问级别设置为public级别
public:
void Walk(); // 走路
void Talk(); // 说话
// 人类共有的属性
// 因为需要遗传给派生类同时又防止外界的访问,
// 所以将其访问级别设置为protected类型
protected:
string m_strName; // 姓名
int m_nAge; // 年龄
bool m_bMale; // 性别
private: // 没有私有成员
};
// Teacher跟Human是“is-a”的关系,
// 所以Teacher采用public继承方式继承Human
class Teacher : public Human
{
// 在子类中添加老师特有的行为
public:
void PrepareLesson(); // 备课
void GiveLesson(); // 上课
void ReviewHomework(); // 批改作业
// 在子类中添加老师特有的属性
protected:
int m_nDuty; // 职务
private:
};
// 学生同样是人类,public继承方式继承Human类
class Student : public Human
{
// 在子类中添加学生特有的行为
public:
void AttendClass(); // 上课
void DoHomework(); // 做家庭作业
// 在子类中添加学生特有的属性
protected:
int m_nScore; // 考试成绩
private:
};
// 小学生是学生,所以public继承方式继承Student类
class Pupil : public Student
{
// 在子类中添加小学生特有的行为
public:
void PlayGame(); // 玩游戏
void WatchTV(); // 看电视
public:
// 对“做作业”的行为重新定义
void DoHomework();
protected:
private:
};
在这段代码中,首先声明了人(Human)这个基类,它定义了人这类事物应当具有的共有属性(姓名、年龄、性别)和行为(走路、说话)。因为老师是人的一种,是人这个类的具体化,所以我们以Human为基类,以public继承的方式定义Teacher这个派生类。通过继承,Teacher类不仅直接具有了Human类中公有和保护类型的成员,同时还根据需要添加了Teacher类自己所特有的属性(职务)和行为(备课、上课),这样就完成了对Human类的继承和扩展,得到的Teacher类是一个“会备课、上课的人类”。
// 定义一个Teacher对象
Teacher MrChen;
// 老师走进教室
// 我们在Teacher类中并没有定义Walk()成员函数,
// 这里是通过继承从基类Human中得到的成员函数
MrChen.Walk();
// 老师开始上课
// 这里调用的是Teacher自己定义的成员函数
MrChen.GiveLesson();
同理,我们还通过public继承Human类,同时增加了学生特有的属性(m_nScore)和行为(AttendClass()和DoHomwork()),定义了Student类。进而,又根据需要,以同样的方式从Student类继承得到了更加具体的Pupil类来表示小学生。通过继承,我们可以把整棵“继承树”完整清晰地表达出来。
仔细体会就会发现,整个继承的过程就是类的不断具体化、不断传承基类的属性和行为,同时发展自己特有属性和行为的过程。现实世界中的物种进化,通过子代吸收和保留部分父代的能力,同时根据环境的变化,对父代的能力做一些改进并增加一些新的能力来形成新的物种。继承,就是现实世界中这种进化过程在程序世界中的体现。所以,类的进化也遵循着与之类似的规则:
(1) 保留基类的属性和行为。
继承最大的目的就是复用基类的设计和实现,保留基类的属性和行为。对于派生类而言,不用自己白手起家,一切从零开始,只要通过继承就直接成了拥有基类丰富属性和行为的“富二代”。在上面的例子中,派生类Teacher通过继承Human基类,轻松拥有了Human类的所有公有和保护类型成员,这就像站在巨人的肩膀上,Teacher类只用很少的代码就拥有了基类遗传下来的姓名、年龄等属性和走路、说话等行为,实现了设计和代码的复用,同时注意,继承可以将构造函数与析构函数继承下去。
(2) 改进基类的属性和行为。
既然是进化,派生类就要有优于基类的地方,这些地方就表现在派生类对基类成员的修改。例如,Student类有表示“做作业”这个行为的DoHomework()成员函数,派生类Pupil本来直接继承Student类也就同样拥有了这个成员函数,但是,“小学生”做作业的方式是比较特殊的,基类定义的DoHomework()函数无法满足它的需求。所以派生类Pupil只好重新定义了DoHomework()成员函数,从而根据自己的实际情况对它做进一步的具体化,对它进行改写以适应新的需求。这样,基类和派生类都拥有DoHomework()成员函数,但派生类中的这个函数是经过改写后的更具体的更有针对性的,是对基类的一种改进。
(3) 添加新的属性和行为。
如果进化仅仅是对原有事物的改进,那么是远远不够的。进化还需要一些“革命性”的内容才能产生新的事物。所以在类的继承当中,派生类除了可以改进基类的属性和行为之外,更重要的是添加一些“革命性”的新属性和行为使其成为一个新的类。例如,Teacher类从Human类派生,它保留了基类的属性和行为,同时还根据需要添加了基类所没有的新属性(职务)和行为(备课、上课),正是这些新添加的属性和行为,使它从本质上区别于Human类,完成了从Human到Teacher的进化。
很显然,继承既很好地解决了设计和代码复用的问题——派生类继承保留了基类的属性和行为,同时又提供了一种扩展的方式来轻松应对新的需求——派生类可以改变基类的行为同时根据需要添加新的属性和行为,而这正是面向对象思想的魅力所在。
既然继承可以带来这么多好处,不用费吹灰之力就可以复用以前的设计和代码,那么是不是可以在能够使用继承的地方就都使用继承,而且越多越好呢?
当然不是。人参再好,也不能当饭吃。正是因为继承太有用,带来了很多好处,所以往往会被初学者滥用,最后导致设计出一些“四不像”的怪物出来。在这里,我们要给继承的使用定几条规矩:
(1) 拥有相关性的两个类才能发生继承。
如果两个类(A和B)毫不相关,则不可以为了使B的功能更多而让B继承A。也就是说,不可以为了让“人”具有“飞行”的行为,而让“人”从“鸟”派生,那得到的就不再是“人”,而是“鸟人”了。不要觉得类的功能越多越好,在这里,要奉行“多一事不如少一事”的原则。
(2) 不要把组合当成继承。
如果类B有必要使用类A提供的服务,则要分两种情况考虑:
-
B是A的“一种”。若在逻辑上B是A的“一种”(a kind of),则允许B继承A。例如,老师(Teacher)是人(Human)的一种,是对人的特殊化具体化,那么Teacher就可以继承自Human。
-
A是B的“一部分”。若在逻辑上A是B的“一部分”(a part of),虽然两者也有相关性,但不允许B继承A。例如,键盘、显示器是电脑的一部分。
如果B不能继承A,但A是B的“一部分”,B又需要使用A提供的服务,那又该怎么办呢?让A的对象成为B的一个成员,用A和其他对象共同组合成B。这样在B中就可以访问A的对象,自然就可以获得A提供的服务了。例如,一台电脑需要键盘的输入服务和显示器的输出服务,而键盘和显示器是电脑的一部分,电脑不能从键盘和显示器派生,那么我们就把键盘和显示器的对象作为电脑的成员变量,同样可以获得它们提供的服务:
// 键盘
class Keyboard
{
public:
// 接收用户键盘输入
void Input()
{
cout<<"键盘输入"<<endl;
}
};
// 显示器
class Monitor
{
public:
// 显示画面
void Display()
{
cout<<"显示器输出"<<endl;
}
};
// 电脑
class Computer
{
public:
// 用键盘、显示器组合一台电脑
Computer( Keyboard* pKeyboard,
Monitor* pMonitor )
{
m_pKeyboard = pKeyboard;
m_pMonitor = pMonitor;
}
// 电脑的行为
// 其具体动作都交由其各个组成部分来完成
// 键盘负责用户输入
void Input()
{
m_pKeyboard->Input();
}
// 显示器负责显示画面
void Display()
{
m_pMonitor->Display();
}
// 电脑的各个组成部分
private:
Keyboard* m_pKeyboard = nullptr; // 键盘
Monitor* m_pMonitor = nullptr; // 显示器
// 其他组成部件对象
};
int main()
{
// 先创建键盘和显示器对象
Keyboard keyboard;
Monitor monitor;
// 用键盘和显示器对象组合成电脑
Computer com(&keyboard,&monitor);
// 电脑的输入和输出,实际上最终是交由键盘和显示器去完成
com.Input();
com.Display();
return 0;
}
在上面的代码中,电脑这个类由Keybord和 Monitor两个类的对象组成(当然,在具体实践中还应该有更多组成部分),它的所有功能都不是它自己实现的,而是由它转交给各个组成对象具体实现,它只是提供了一个统一的对外接口而已。这种把几个类的对象结合在一起构成新类的方式就是组合。虽然电脑没有继承键盘和显示器,但是通过组合这种方式,电脑同样获得了键盘和显示器提供的服务,具备了输入和输出的功能。关于组合,还需要注意的是,这里使用了对象指针作为类成员变量来把各个对象组合起来,是因为电脑是一个可以插拔的系统,键盘和显示器都是可以更换的。键盘可以在这台电脑上使用,也可以在另外的电脑上使用,电脑和键盘的生命周期是不同的各自独立的。所以这里采用对象指针作为成员变量,两个对象可以各自独立地创建后再组合起来,也可以拆分后另作他用。而如果遇到整体和部分密不可分的情况,两者具有相同的生命周期,比如一个人和组成这个人的胳膊、大腿等,这时就该直接采用对象作为成员变量了。例如:
// 胳膊
class Arm
{
public:
// 胳膊提供的服务,拥抱
void Hug()
{
cout<<"用手拥抱"<<endl;
}
};
// 脚
class Leg
{
public:
// 脚提供的服务,走路
void Walk()
{
cout<<"用脚走路"<<endl;
}
};
// 身体
class Body
{
public:
// 身体提供的服务,都各自交由组成身体的各个部分去完成
void Hug()
{
arm.Hug();
}
void Walk()
{
leg.Walk();
}
private:
// 组成身体的各个部分,因为它们与Body有着共同的生命周期,
// 所以这里使用对象作为类的成员变量
Arm arm;
Leg leg;
};
int main()
{
// 在创建Body对象的时候,同时也创建了组成它的Arm和Leg对象
Body body;
// 使用Body提供的服务,这些服务最终由组成Body的Arm和Leg去完成
body.Hug();
body.Walk();
// 在Body对象销毁的同时,组成它的Arm和Leg对象也同时被销毁
return 0;
}
扩展1
有时候我们需要用指针表示一个类,那么,有时候我们并不打算用他这个类的专属指针,那该怎么办呢?
比如下面这一段:
class human
{
//定义
};
class Teacher:public human//类型继承
{
//定义
}MrChen;//怎么又是我QMQ
int main()
{
human* Aman=&(MrChen);//因为Teacher是human的派生类,所以可以用human的指针表示Teacher
return 0;
}
但是有个小毛病
#include<cstdio>
using namespace std;
class human
{
public:
void print_old()
{
printf("I don't know.\n");
}
};
class Teacher:public human//类型继承
{
public:
void print_weight()
{
printf("Don't ask me for this.\n");
}
}MrChen;//怎么又是我QMQ
int main()
{
human* Aman=&(MrChen);//因为Teacher是human的派生类,所以可以用human的指针表示Teacher
Aman->print_old();//调用print_old函数,因为print_old是在human里面的
// Aman->print_weight();不能这么打,因为print_weight是在Teacher新增加的。
((Teacher*)Aman)->print_weight();//用强制类型转换实现的,只能有基类强制转为派生类
return 0;
}
在最后几行我们可以看到human因为没有print_weight的函数不合常理,导致我们得用强制类型装换,而多重继承也是如此。
当然,一个基类的指针也可以转成他的派生类的派生类的指针,比如:
#include<cstdio>
using namespace std;
class human
{
public:
void print_old()
{
printf("I don't know.\n");
}
};
class Teacher:public human//类型继承
{
public:
void print_weight()
{
printf("Don't ask me for this.\n");
}
}MrChen;//怎么又是我QMQ
class Headmaster:public Teacher//类型继承
{
public:
void print_height()
{
printf("Don't ask me for this,too.\n");
}
}MrsLin;
int main()
{
human* Aman=&(MrChen);//因为Teacher是human的派生类,所以可以用human的指针表示Teacher
Aman->print_old();//调用print_old函数,因为print_old是在human里面的
// Aman->print_height();不能这么打,因为print_height是在Teacher新增加的。
((Teacher*)Aman)->print_weight();//用强制类型转换实现的,只能有基类强制转为派生类
human* A_man=&(MrsLin);//定义一个human的指针指向Headmaster
((Headmaster*)Aman)->print_height();//强制转成Headmaster
return 0;
}
但是,我们并不能用Teacher的指针或者是Headmaster的指针指向human,其实这也很正常,这也同时体现了面向对象的继承思想。
6. 多态与虚函数
多态的基础实现(用大佬博客的QMQ)
在理解了面向对象的继承机制之后,我们知道了在大多数情况下派生类是基类的“一种”,就像“学生”是“人”类中的一种一样。既然“学生”是“人”的一种,那么在使用“人”这个概念的时候,这个“人”可以指的是“学生”,而“学生”也可以应用在“人”的场合。比如可以问“教室里有多少人”,实际上问的是“教室里有多少学生”。这种用基类指代派生类的关系反映到C++中,就是基类指针可以指向派生类的对象,而派生类的对象也可以当成基类对象使用。这样的解释对大家来说是不是很抽象呢?没关系,可以回想生活中经常遇到的一个场景:“上车的人请买票”。在这句话中,涉及一个类——人,以及它的一个动作——买票。但上车的人可能是老师、学生,也可能是工人、农民或者某个程序员,他们买票的方式也各不相同,有的投币,有的刷卡,可为什么售票员不说“上车的老师请刷卡买票”或者说“上车的工人请投币买票”,而仅仅说“上车的人请买票”就足够了呢?这是因为虽然上车的人可能是老师、学生、公司职员等,但他们都是“人”这个基类的派生类,所以这里就可以用基类“人”来指代所有派生类对象,通过基类的接口“买票”来调用派生类的对这个接口的具体实现来完成买票的具体动作。
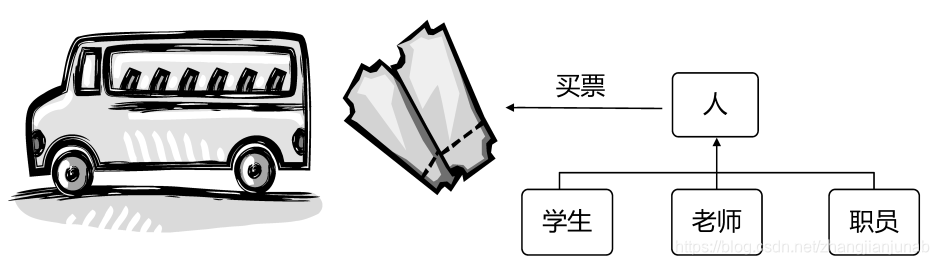
学习了前面的封装和继承,我们可以用C++把这个场景描述如下:
// “上车买票”演示程序
// 定义Human类,这个类有一个接口函数BuyTicket()表示买票的动作
class Human
{
// Human类的行为
public:
// 买票接口函数
void BuyTicket()
{
cout<<"人买票。"<<endl;
}
};
// 从“人”派生两个类,分别表示老师和学生
class Teacher : public Human
{
public:
// 对基类提供的接口函数重新定义,适应派生类的具体情况
void BuyTicket()
{
cout<<"老师投币买票。"<<endl;
}
};
class Student : public Human
{
public:
void BuyTicket()
{
cout<<"学生刷卡买票。"<<endl;
}
};
// 在主函数中模拟上车买票的场景
int main()
{
// 车上上来两个人,一个是老师,另一个是学生
// 基类指针指向派生类对象
Human* p1 = new Teacher();
Human* p2 = new Student();
// 上车的人请买票
p1->BuyTicket(); // 第一个人是老师,投币买票
p1->BuyTicket(); // 第二个人是学生,刷卡买票
// 销毁对象
delete p1;
delete p2;
p1 = p2 = nullptr;
return 0;
}
在这段代码中,我们先定义了一个基类Human,它有一个接口函数BuyTicket()表示“人”买票的动作。然后定义了它的两个派生类Teacher和Student,通过继承,这两个派生类本来已经直接拥有了BuyTicket()函数表示买票的行为,但是,“老师”和“学生”买票的行为是比较特殊的,所以我们又各自在派生类中对BuyTicket()函数作了重新定义以表达他们特殊的买票动作。在主函数中,我们模拟了“上车买票”这一场景:首先分别创建了Teacher和Student对象,并用基类Human的两个指针分别来指代这两个对象,然后通过Human类型的指针调用接口函数BuyTicket()函数来表达“上车的人请买票”的意思,完成Teacher和Student对象的买票动作。最后,程序的输出结果是:
人买票。
人买票。
细心的你一定已经注意到一件奇怪的问题:虽然Teacher和Student都各自重新定义了表示买票动作的BuyTicket()函数,虽然基类的指针指向的实际是派生类的对象,可是在用基类的指针调用这个函数时,得到的动作却是相同的,都是来自基类的动作。这显然是不合适的。虽然都是“人买票”,但是不同的人应该有不同的买票方式,如果这个人是老师就投币买票,如果是学生就该刷卡买票。根据“人”所指代的具体对象不同动作也应该有所不同。为了解决这个问题,C++提供了虚函数(virtual function)的机制。在基类的函数声明前加上virtual关键字,这个函数就成为了虚函数,而派生类中对这个虚函数的重新定义,无论是否显式地添加了virtual关键字,也仍然是虚函数。在类中拥有虚函数的情况下,如果通过基类指针调用类中的虚函数,那将调用这个指针实际所指向的具体对象(可能是基类对象,也可能是派生类对象,根据运行时情况而定)的虚函数,而不再是像上面的例子那样,基类指针指向的是派生类的对象,调用的却是基类的函数,也就完美地解决了上面的问。像这种在派生类中利用虚函数对基类的成员函数进行重新定义,并在运行时刻根据实际的对象来决定调用哪一个函数的机制,被称为函数重写(override) 。
扩展:重写
“嘿,编译器,我需要一个Add()函数,帮我搬一个Add()函数箱子过来。”
“老板,我这有好几个Add()函数箱子呢,有的可以做int类型数据的加法,有的可以做float类型数据的加法,有的甚至还可以做字符串的加法,你到底要哪个Add()函数箱子呢?”
“这么多?我就想要一个可以计算两个int类型数据之和的Add()函数箱子。”
“我明白了,老板你要的是贴有‘int Add(int a, int b)’标签的函数箱子。”
“干吗这么多函数箱子都叫Add啊,不怕搞混淆了吗?”
所谓重载(overload)函数,就是让具有相似功能的函数拥有相同的函数名。反过来讲,也就是同一个函数名可以用于功能相似但又各有差异的多个函数。这里大家可能会问,一个函数名表示一个意义不是很好吗,为什么要用一个函数名表示多个意义呢?这样不会造成混乱吗?
回到我们刚才的那个例子,如果我们想要在程序中实现“加和”这个意义,很自然地,我们可以定义一个Add()函数:
int Add(int a, int b)
{
return a + b;
}
这个Add()函数可以计算两个整数的和,可是我们在程序中还可能需要计算其他类型数据的和,比如两个浮点数的和,这个Add()函数就无法计算了。为此,我们不得不实现另外一个AddFloat()函数来完成两个浮点数“加和”的计算:
float AddFloat(float a, float b)
{
return a + b;
}
AddFloat()函数可以暂时地解决问题,可是我们还可能会遇到更多种类型数据的“加和”,这样在我们的程序中,就可能出现AddDouble()、AddString()、AddHuman()等一系列表示“加和”意义的函数。同样是表示“加和”这个动作,却有着不同的函数名,这使得我们在调用这些函数的时候,还不得不人为地根据具体情况进行选择。这不仅非常麻烦,而且如果选择错误,还会导致结果出错。函数重载机制就是用来解决这个问题的。它可以让拥有相似功能的函数拥有相同的函数名,而在实际调用的时候,编译器会根据实际参数的个数和类型的不同,在多个同名的重载函数中进行匹配,最终确定调用哪个函数。这样省去了我们选择函数的麻烦,同时也让代码的形式更加统一一致。
准确地讲,两个函数,因为实现的功能相似,所以取相同的函数名,但是参数的个数或类型不同,就构成了函数重载,而这两个函数就被称为重载函数。
下面来看看如何使用函数重载来解决上文中Add()函数所遇到的问题:
// 定义第一个Add()函数,使其可以计算两个int型数据的和
int Add( int a, int b )
{
cout<<"int Add( int a, int b )被调用!"<<endl;
return a + b;
}
// 重载Add()函数,对其进行重新定义,
// 使其可以计算两个double型数据的和
double Add( double a, double b )
{
cout<<" double Add( double a, double b )被调用!"<<endl;
return a + b;
}
int main()
{
// 因为参数是整型数,其类型、个数
// 与int Add( int a, int b )匹配
// 所以int Add( int a, int b )被调用
int nSum = Add(2,3);
cout<<" 2 + 3 = "<<nSum<<endl;
// 作为参数的小数会被表示成double类型,
// 其类型、个数与double Add( double a, double b )匹配
// 所以double Add( double a, double b )被调用
double fSum = Add(2.5,10.3);
cout<<" 2.5 + 10.3 = "<<fSum<<endl;
return 0;
}
经过以上这样的函数重载,编译器会根据实际调用函数时不同的参数类型和个数调用与之匹配的重载函数,这样虽然我们在代码形式上调用的都是Add()函数,可实际最终调用的却是重载函数的不同版本,从而得到正确的结果:
int Add( int a, int b )被调用!
2 + 3 = 5
double Add( double a, double b )被调用!
2.5 + 10.3 = 12.8
在这段程序中,根据计算的数据类型的不同,我们对Add()函数进行了重载,分别实现了其int类型版本和double类型版本。在输出结果中,我们可以清楚地看到第一次对Add()函数的调用,实际上执行的是int类型版本“int Add( int a, int b )”,而第二次执行的是double类型版本“double Add( double a, double b)”。为什么同样是对Add()函数的调用,两次执行的却是不同的函数呢?这是因为主函数在第一次调用Add()函数时,给出的实际参数“2”和“3”的类型为int类型,而在Add()函数的两个重载版本中,只有第一个int类型版本与之最为匹配,不仅参数类型相同,同时参数个数也相同,所以执行第一个int类型版本的Add()函数;而在第二次用“2.5”和“10.3”作为实际参数调用Add()函数时,因为小数常数在程序中会被表示成double类型,所以编译器会找到第二个double类型版本的Add()函数跟它匹配,所以最终会执行第二个Add()函数。
函数重载可以让我们以统一的代码形式调用那些功能相近的多个函数,这样可以简洁代码同时省去选择函数的麻烦。那么,什么时候需要使用函数重载呢?只要发现程序中有多个函数的功能相似,只是处理的数据不同,就可以使用函数重载。换句话说,只要多个函数表达的动作相同而动作的对象不同,就可以使用相同的函数名来表示相同的动作,而用不同的参数来表示不同的动作对象。需要注意的是,我们不要将不同功能的函数定义为重载函数,虽然这样做在语法上是可行的,但是这样做违背了“函数名应准确表达函数功能”的原则,很有可能导致对函数的误用。
我们知道,编译器是通过参数的类型和个数的不同来区分重载函数的不同版本的。所以,相同函数名的多个函数,只有相互之间的参数类型或者个数不同,才可以构成合法的重载函数的多个版本。例如:
// 参数类型不同构成合法的函数重载
int max(int a, int b);
float max(float a, float b);
double max(double a, double b);
以上三个函数分别接受两个int、float和double类型的参数,具有不同的参数类型,因此可以构成正确的函数重载。但要特别注意的是,如果两个函数仅仅是返回值类型不同,并不能构成函数重载,例如:
// 仅仅是函数返回值不同,不能构成合法的函数重载
int max(int a, int b);
float max(int a, int b);
这是因为函数调用时,函数的返回值有时并不是必需的,如果只是单纯调用函数而没有返回值,这时编译器就无法判断到底该调用哪一个重载函数了。
当定义了正确的重载函数后,在调用这些重载函数时,编译器就该忙活了,它需要根据我们在调用时给出的实际参数找到与之匹配的正确的重载函数版本。
首先,编译器会进行严格的参数匹配,包括参数的类型和个数。如果编译器发现某个重载函数的参数类型和个数都跟函数调用时的实际参数相匹配,则优先调用这个重载函数。例如:
// 调用int max(int a,int b)
int nMax = max(1, 2);
这里的实际参数“1”和“2”都是int类型,参数个数是两个,这就跟“int max(int a, int b)”这个重载函数严格匹配,所以这里调用的就是这个int版本的max()函数。
如果无法找到严格匹配的重载函数,那么编译器会尝试将参数类型转换为更高精度的类型去进行匹配,比如将char类型转换为int类型,将float类型转换为double类型等。如果转换类型后的参数能够找到与之匹配的重载函数,则调用此重载函数。例如:
// 调用int max(int a,int b)
char cMax = max('a','A');
这里的实际参数‘a’和‘A’是char类型,并没有与之匹配的重载函数,编译器会尝试将char类型的参数转换为更高精度的int类型,这时就会找到“int max(int a,int b)”与之匹配,所以这里实际调用的是int类型版本的max()函数。这里值得注意的是,参数可以从低精度的数据类型转化为高精度的数据类型进行匹配,但并不意味着高精度的数据类型也可以转化为低精度的数据类型进行匹配。这是因为在由高到低的转化中会有多种选择,反正都有精度损失,一个double类型的参数既可以转化为int类型也可以转化为short类型,这样编译器就不知道到底该调用哪一个版本的重载函数,自然也就无法完成重载了。
除了理解重载函数的匹配原则之外,在使用重载函数时,还要特别注意带参数默认值的函数可能给函数重载带来的麻烦。例如,有这样两个重载函数:
// 比较两个整型数的大小
int max(int a, int b);
// 比较三个整型数的大小,第三个数的默认值是0
int max(int a, int b , int c = 0);
当我们以
int nMax = max( 1, 2 );
的形式尝试调用这个重载函数时,从函数调用表达式中我们无法得知它到底是只有两个参数,还是拥有三个参数只不过第三个参数使用了默认参数,这就使得这个调用跟两个重载函数都能严格匹配,这时编译器就不知道到底该调用哪个重载函数版本了。所以在重载函数中应该尽量避免使用默认参数,让编译器能够准确无误地找到匹配的重载函数。
重写与重载的区别
实际上,它们都是C++中对函数行为进行重新定义的一种方式,同时,它们重新定义的函数名都跟原来的相同,所以它们才都姓“重”,只是因为它们发生的时间和位置不同,这才产生了“重载”和“重写”的区别。
重载(overload)是一个编译时概念,它发生在代码的同一层级。它表示在代码的同一层级(同一名字空间或者同一个类)中,一个函数因参数类型与个数不同可以有多个不同的实现。在编译时刻,编译器会根据函数调用的实际参数类型和个数来决定调用哪一个重载函数版本。
重写(override)是一个运行时概念,它发生在代码的不同层级(基类和派生类之间)。它表示在派生类中对基类中的虚函数进行重新定义,两者的函数名、参数类型和个数都完全相同,只是具体实现不同。而在运行时刻,如果是通过基类指针调用虚函数,它会根据这个指针实际指向的具体对象类型来选择调用基类或是派生类的重写函数。例如:
// 同一层级的两个同名函数因参数不同而形成重载
class Human
{
public:
virtual void Talk()
{
cout<<"Ahaa"<<endl;
}
virtual void Talk(string msg)
{
cout<<msg<<endl;
}
};
// 不同层级的两个同名且参数相同的函数形成重写
class Baby : public Human
{
public:
virtual void Talk()
{
cout<<"Ma-Ma"<<endl;
}
};
int main()
{
Human MrChen;
// 根据参数的不同来决定具体调用的重载函数,在编译时刻决定
MrChen.Talk(); // 调用无参数的Talk()
MrChen.Talk("Balala"); // 调用以string为参数的Talk(string)
Human* pBaby = new Baby();
// 根据指针指向的实际对象的不同来决定具体调用的重写函数,在运行时刻决定
pBaby->Talk(); // 调用Baby类的Talk()函数
delete pBaby;
pBaby = nullptr;
return 0;
}
在这个例子中,Human类当中的两个Talk()函数是重载函数,因为它们位于同一层级,拥有相同的函数名但是参数不同。而Baby类的Talk()函数则是对Human类的Talk()函数的重写了,因为它们位于不同层级(一个在基类,一个在派生类),但是函数名和参数都相同。可以记住这样一个简单的规则:相同层级不同参数是重载,不同层级相同参数是重写。
另外还需要注意的一点是,重载和重写的结合,会引起函数的隐藏(hide)。还是上面的例子:
Baby cici;
cici.Talk("Ba-Ba"); // 错误:Baby类中的Talk(string)函数被隐藏,无法调用
这样的结果是不是让人有点意外?本来,按照类的继承规则,Baby类也应该继承Human类的Talk(string)函数。然而,这里Baby类对Talk()函数的重写隐藏了从Human类继承的Talk(string)函数,所以才无法使用Baby类的对象直接调用基类的Talk(string)函数。一个曲线救国的方法是,可以通过基类的指针或类型转换,间接地实现对被隐藏函数的调用:
((Human)cici).Talk("Ba-Ba"); // 通过类型转换实现对被隐藏函数的调用
但是,值得告诫的是,不到万不得已,不要这样做。
回到多态基础实现的正题吧。
我们在这里对重载和重写进行比较,其意义并不在于让我们去做一个名词辨析的考试题(虽然这种题目在考试或者面试中也非常常见),而在于让我们理解C++中有这样两种对函数进行重新定义的方式,从而可以让我们在合适的地方使用合适的方式,充分发挥用函数解决问题的灵活性。
现在,就可以用虚函数来解决上面例子中的奇怪问题,让通过Human基类指针调用的BuyTicket()函数,可以根据指针所指向的真实对象来选择不同的买票动作:
// 经过虚函数机制改写后的“上车买票”演示程序
// 定义Human类,提供公有接口
class Human
{
// Human类的行为
public:
// 在函数前添加virtual关键字,将BuyTicket()函数声明为虚函数,
// 表示其派生类可能对这个虚函数进行重新定义以满足其特殊需要
virtual void BuyTicket()
{
cout<<"人买票。"<<endl;
}
};
// 在派生类中对虚函数进行重新定义
class Teacher : public Human
{
public:
// 根据实际情况重新定义基类的虚函数以满足自己的特殊需要
// 不同的买票方式
virtual void BuyTicket()
{
cout<<"老师投币买票。"<<endl;
}
};
class Student : public Human
{
public:
// 不同的买票方式
virtual void BuyTicket()
{
cout<<"学生刷卡买票。"<<endl;
}
};
// …
虚函数
在这个例子中,Human类当中的两个Talk()函数是重载函数,因为它们位于同一层级,拥有相同的函数名但是参数不同。而Baby类的Talk()函数则是对Human类的Talk()函数的重写了,因为它们位于不同层级(一个在基类,一个在派生类),但是函数名和参数都相同。可以记住这样一个简单的规则:相同层级不同参数是重载,不同层级相同参数是重写。
另外还需要注意的一点是,重载和重写的结合,会引起函数的隐藏(hide)。还是上面的例子:
Baby cici;
cici.Talk("Ba-Ba"); // 错误:Baby类中的Talk(string)函数被隐藏,无法调用
这样的结果是不是让人有点意外?本来,按照类的继承规则,Baby类也应该继承Human类的Talk(string)函数。然而,这里Baby类对Talk()函数的重写隐藏了从Human类继承的Talk(string)函数,所以才无法使用Baby类的对象直接调用基类的Talk(string)函数。一个曲线救国的方法是,可以通过基类的指针或类型转换,间接地实现对被隐藏函数的调用:
((Human)cici).Talk("Ba-Ba"); // 通过类型转换实现对被隐藏函数的调用
但是,值得告诫的是,不到万不得已,不要这样做。
我们在这里对重载和重写进行比较,其意义并不在于让我们去做一个名词辨析的考试题(虽然这种题目在考试或者面试中也非常常见),而在于让我们理解C++中有这样两种对函数进行重新定义的方式,从而可以让我们在合适的地方使用合适的方式,充分发挥用函数解决问题的灵活性。
现在,就可以用虚函数来解决上面例子中的奇怪问题,让通过Human基类指针调用的BuyTicket()函数,可以根据指针所指向的真实对象来选择不同的买票动作:
// 经过虚函数机制改写后的“上车买票”演示程序
// 定义Human类,提供公有接口
class Human
{
// Human类的行为
public:
// 在函数前添加virtual关键字,将BuyTicket()函数声明为虚函数,
// 表示其派生类可能对这个虚函数进行重新定义以满足其特殊需要
virtual void BuyTicket()
{
cout<<"人买票。"<<endl;
}
};
// 在派生类中对虚函数进行重新定义
class Teacher : public Human
{
public:
// 根据实际情况重新定义基类的虚函数以满足自己的特殊需要
// 不同的买票方式
virtual void BuyTicket()
{
cout<<"老师投币买票。"<<endl;
}
};
class Student : public Human
{
public:
// 不同的买票方式
virtual void BuyTicket()
{
cout<<"学生刷卡买票。"<<endl;
}
};
// …
虚函数机制的改写,只是在基类的BuyTicket()函数前加上了virtual关键字(派生类中的virtual关键字是可以省略的),使其成为了一个虚函数,其他代码没做任何修改,但是代码所执行的动作却发生了变化。Human基类的指针p1和p2对BuyTicket()函数的调用,不再执行基类的这个函数,而是根据这些指针在运行时刻所指向的真实对象类型来动态选择,指针指向哪个类型的对象就执行哪个类的BuyTicket()函数。例如,在执行“p1->BuyTicket()”语句的时候,p1指向的是一个Teacher类对象,那么这里执行的就是Teacher类的BuyTicket()函数,输出“老师投币买票”的内容。经过虚函数的改写,这个程序最后才输出符合实际的结果:
老师投币买票。
学生刷卡买票。
这里我们注意到,Human基类的BuyTicket()虚函数虽然定义了但从未被调用过。而这也恰好体现了虚函数“虚”的特征:虚函数是虚(virtual)的,不实在的,它只是提供一个公共的对外接口供派生类对其重写以提供更具体的服务,而一个基类的虚函数本身却很少被调用。更进一步地,我们还可以在虚函数声明后加上“= 0”的标记而不定义这个函数,从而把这个虚函数声明为纯虚函数。纯虚函数意味着基类不会实现这个虚函数,它的所有实现都留给其派生类去完成。在这里,Human基类中的BuyTicket()虚函数就从未被调用过,所以我们也可以把它声明为一个纯虚函数,也就相当于只是提供了一个“买票”动作的接口,而具体的买票方式则留给它的派生类去实现。例如:
// 使用纯虚函数BuyTicket()作为接口的Human类
class Human
{
// Human类的行为
public:
// 声明BuyTicket()函数为纯虚函数
// 在代码中,我们在函数声明后加上“= 0”来表示它是一个纯虚函数
virtual void BuyTicket() = 0;
};
当类中有纯虚函数时,这个类就成为了一个抽象类(abstract class),它仅用作被继承的基类,向外界提供一致的公有接口。同普通类相比,抽象类的使用有一些特殊之处。首先,因为抽象类中包含有尚未完工的纯虚函数,所以不能创建抽象类的具体对象。如果试图创建一个抽象类的对象,将产生一个编译错误。例如:
// 编译错误,不能创建抽象类的对象
Human aHuman;
同时,再给出一个栗子
#include<iostream>
using namespace std;
// 经过虚函数机制改写后的“上车买票”演示程序
// 定义Human类,提供公有接口
class Human
{
// Human类的行为
public:
// 在函数前添加virtual关键字,将BuyTicket()函数声明为虚函数,
// 表示其派生类可能对这个虚函数进行重新定义以满足其特殊需要
virtual void BuyTicket()
{
cout<<"人买票。"<<endl;
}
};
// 在派生类中对虚函数进行重新定义
class Teacher : public Human
{
public:
virtual void BuyTicket()=0;//中间多态定义一个纯虚函数
};
class Headmaster : public Teacher
{
public:
// 不同的买票方式
virtual void BuyTicket()
{
cout<<"校长刷卡买票。"<<endl;
}
};
// …
int main()
{
Human* kk=new Headmaster;
kk->BuyTicket();
return 0;
}
其次,如果某个类从抽象类派生,那么它必须实现其中的纯虚函数才能成为一个实体类,否则它将继续保持抽象类的特征,无法创建实体对象。例如:
class Student : public Human
{
public:
// 实现基类中的纯虚函数,让Student类成为一个实体类
virtual void BuyTicket()
{
cout<<"学生刷卡买票。"<<endl;
}
};
注:只要类里面有一个纯虚函数,这个类就是抽象类。
不知道为什么,构造函数或者析构函数打成纯虚函数会炸得很惨QAQ
使用virtual关键字将普通函数修饰成虚函数以形成多态的很重要的一个应用是,我们通常用它修饰基类的析构函数而使其成为一个虚函数,以确保在利用基类指针释放派生类对象时,派生类的析构函数能够得到正确执行。例如:
class Human
{
public:
// 用virtual修饰的析构函数
virtual ~Human()
{
cout<<"销毁Human对象"<<endl;
}
};
class Student : public Human
{
public:
// 重写析构函数,完成特殊的销毁工作
virtual ~Student()
{
cout<<"销毁Student对象"<<endl;
}
};
// 将一个Human类型的指针,指向一个Student类型的对象
Human* pHuman = new Student();
// …
// 利用Human类型的指针,释放它指向的Student类型的对象
// 因为析构函数是虚函数,所以这个指针所指向的Student对象的析构函数会被调用,
// 否则,会错误地调用Human类的析构函数
delete pHuman;
pHuman = nullptr;
注:当将上面的构造或析构函数继承下来再重写的时候,类型要打这个类型的构造或析构函数。
如在一个基类叫human,他的构造函数长这样:
human(...)
那么,当一个继承human类型的Teacher,他重写构造函数的格式长这样:
Teacher(...)//并不是human(...)
是不是十分神奇?一点都不
不要在构造函数或析构函数中调用虚函数
在上面的代码,我们看到。
delete pHuman;
先调用了Student的析构函数,在调用了human的析构函数。
我们知道,在基类的普通函数中,我们可以调用虚函数,而在执行的时候,它会根据具体的调用这个函数的对象而动态决定调用执行具体的某个派生类重写后的虚函数。这是C++多态机制的基本规则。然而,这个规则并不是放之四海皆准的。如果这个虚函数出现在基类的构造函数或者析构函数中,在创建或者销毁派生类对象时,它并不会如我们所愿地执行派生类重写后的虚函数,取而代之的是,它会直接执行这个基类自身的虚函数。换句话说,在基类构造或析构期间,虚函数是被禁止的。
为什么会有这么奇怪的行为?这是因为,在创建一个派生类的对象时,基类的构造函数是先于派生类的构造函数被执行的,如果我们在基类的构造函数中调用派生类重写的虚函数,而此时派生类对象尚未创建完成,其数据成员尚未被初始化,派生类的虚函数执行或多或少会涉及到它的数据成员,而对未初始化的数据成员进行访问,无疑是一场恶梦的开始。
在基类的析构函数中调用派生类的虚函数也存在相似的问题。基类的析构函数后于派生类的析构函数被执行,如果我们在基类的析构函数中调用派生类的虚函数,而此时派生类的数据成员已经被释放,如果虚函数中涉及对派生类已经释放的数据成员的访问,就成了未定义行为,后果自负。
为了阻止这些行为可能带来的危害,C++禁止了虚函数在构造函数和析构函数中的向下匹配。为了避免这种不一致的匹配规则所带来的歧义(你以为它会像普通函数中的虚函数一样,调用派生类的虚函数,而实际上它调用的却是基类自身的虚函数),最好的方法就是,不要在基类的构造函数和析构函数中调用虚函数。永绝后患!
同时,给出一个有趣的栗子:
#include<cstdio>
#include<iostream>
using namespace std;
class Human
{
public:
// 用virtual修饰的析构函数
virtual ~Human()
{
cout<<"销毁Human对象"<<endl;
}
};
class Student : public Human
{
public:
// 重写析构函数,完成特殊的销毁工作
virtual ~Student()
{
cout<<"销毁Student对象"<<endl;
}
};
class Middle : public Student
{
public:
// 重写析构函数,完成特殊的销毁工作
virtual ~Middle()
{
cout<<"销毁Middle对象"<<endl;
}
};
int main()
{
// 将一个Human类型的指针,指向一个Student类型的对象
Human* pHuman = new Middle();
// …
// 利用Human类型的指针,释放它指向的Student类型的对象
// 因为析构函数是虚函数,所以这个指针所指向的Student对象的析构函数会被调用,
// 否则,会错误地调用Human类的析构函数
delete pHuman;
pHuman = NULL;
return 0;
}
依次调用了三个析构函数,真有趣QMQ
可读性以及代码新能优化
当我们在派生类中重写基类的某个虚函数对其行为进行重新定义时,并不需要显式地使用virtual关键字来说明这是一个虚函数重写,只需要派生类和基类的两个函数的声明相同即可。例如上面例子中的Teacher类重写了Human类的BuyTicket()虚函数,其函数声明中的virtual关键字就是可选的。无须添加virtual关键字的虚函数重写虽然简便,但是却很容易让人晕头转向。因为如果派生类的重写虚函数之前没有virtual关键字,会让人对代码的真实意图产生疑问:这到底是一个普通的成员函数还是虚函数重写?这个函数是从基类继承而来的还是派生类新添加的?这些疑问在一定程度上影响了代码的可读性以及可维护性。所以,虽然在语法上不是必要的,但为了代码的可读性和可维护性,我们最好还是在派生类的虚函数前加上virtual关键字。
为了让代码的意义更加明晰,在 C++中,我们可以使用 override关键字来修饰一个重写的虚函数,从而让程序员可以在代码中更加清晰地表达自己对虚函数重写的实现意图,增加代码的可读性。例如:
class Student : public Human
{
public:
// 虽然没有virtual关键字,
// 但是override关键字一目了然地表明,这就是一个重写的虚函数
void BuyTicket() override
{
cout<<"学生刷卡买票。"<<endl;
}
// 错误:基类中没有DoHomework()这个虚函数,不能形成虚函数重写
void DoHomework() override
{
cout<<"完成家庭作业。"<<endl;
}
};
从这里可以看到,override关键字仅能对派生类重写的虚函数进行修饰,表达程序员的实现意图,而不能对普通成员函数进行修饰以形成重写。上面例子中的 DoHomework() 函数并没有基类的同名虚函数可供重写,所以添加在其后的 override关键字会引起一个编译错误。如果希望某个函数是虚函数重写,就在其函数声明后加上override关键字,这样可以很大程度地提高代码的可读性,同时也可以让代码严格符合程序员的意图。例如,程序员希望派生类的某个函数是虚函数重写而为其加上override修饰,编译器就会帮助检查是否能够真正形成虚函数重写,如果基类没有同名虚函数或者虚函数的函数形式不同无法形成重写,编译器会给出相应的错误提示信息,程序员可以根据这些信息作进一步的处理。
与override相对的,有的时候,我们还希望虚函数不被默认继承,阻止某个虚函数被派生类重写。在这种情况下,我们可以为虚函数加上 final 关键字来达到这个目的。例如:
// 学生类
class Student : public Human
{
public:
// final关键字表示这就是这个虚函数的最终(final)实现,
// 不能够被派生类重写进行重新定义
virtual void BuyTicket() final
{
cout<<"学生刷卡买票。"<<endl;
}
// 新增加的一个虚函数
// 没有final关键字修饰的虚函数,派生类可以对其进行重写重新定义
virtual void DoHomework() override
{
cout<<"完成家庭作业。"<<endl;
}
};
// 小学生类
class Pupil : public Student
{
public:
// 错误:不能对基类中使用final修饰的虚函数进行重写
// 这里表达的意义是,无论是Student还是派生的Pupil,买票的方式都是一样的,
// 无需也不能通过虚函数重写对其行为进行重新定义
virtual void BuyTicket()
{
cout<<"学生刷卡买票。"<<endl;
}
// 派生类对基类中没有final关键字修饰的虚函数进行重写
virtual void DoHomework() override
{
cout<<"小学生完成家庭作业。"<<endl;
}
};
既然虚函数的意义就是用来被重写以实现面向对象的多态机制,那么为什么我们还要使用final关键字来阻止虚函数重写的发生呢?任何事物都有其两面性,C++的虚函数重写也不例外。实际上,我们有很多正当的理由来阻止一个虚函数被它的派生类重写,其中最重要的一个理由就是这样做可以提高程序的性能。因为虚函数的调用需要查找类的虚函数表,如果程序中大量地使用了虚函数,那么将在虚函数的调用上浪费很多不必要的时间,从而影响程序性能。阻止不必要的虚函数重写,也就是减小了虚函数表的大小,自然也就减少了虚函数调用时的查表时间提高了程序性能。而这样做的另外一个理由是出于代码安全性的考虑,某些函数库出于扩展的需要,提供了一些虚函数作为接口供专业的程序员对其进行重写,从而对函数库的功能进行扩展。但是对于函数库的普通使用者而言,重写这些函数是非常危险的,因为知识或经验的不足很容易出错。所以有必要使用final关键字阻止这类重写的发生。
虚函数重写可以实现面向对象的多态机制,但过多的虚函数重写又会影响程序的性能,同时使得程序比较混乱。这时,我们就需要使用final关键字来阻止某些虚函数被无意义地重写,从而取得某种灵活性与性能之间的平衡。那么,什么时候该使用final而什么时候又不该使用呢?这里有一个简单的原则:如果某人重新定义了一个派生类并重写了基类的某个虚函数,那么会产生语义上的错误吗?如果会,则需要使用final关键字来阻止虚函数被重写。例如,上面例子中的Student有一个来自它的基类Human的虚函数 BuyTicker(),而当定义Student的派生类Pupil时,就不应该再重写这个虚函数了,因为无论是Student还是 Pupil,其BuyTicket()函数的行为应该是一样的,不需要重新定义。在这种情况下,就可以使用 final 关键字来阻止虚函数重写的发生。如果出于性能的要求,或者是我们只是简单地不希望虚函数被重写,通常,最好的做法就是在一开始的地方就不要让这个函数成为虚函数。
面向对象的多态机制为派生类修改基类的行为,并以一致的调用形式满足不同的需求提供了一种可能。合理利用多态机制,可以为程序开发带来更大的灵活性。
-
接口统一,高度复用
应用程序不必为每个派生类编写具体的函数调用,只需要在基类中定义好接口,然后针对接口编写函数调用,而具体实现再留给派生类自己去处理。这样就可以“以不变应万变”,可以应对需求的不断变化(需求发生了变化,只需要修改派生类的具体实现,而对函数的调用不需要改变),从而大大提高程序的可复用性(针对接口的复用)。 -
向后兼容,灵活扩展
派生类的行为可以通过基类的指针访问,可以很大程度上提高程序的可扩展性,因为一个基类的派生类可以很多,并且可以不断扩充。比如在上面的例子中,如果想要增加一种乘客类型,只需要添加一个Human的派生类,实现自己的BuyTicket()函数就可以了。在使用这个新创建的类的时候,无须修改程序代码中的调用形式。
三. UML画图
UML画图是处理面向对象关系的好东西,推介一些UML画图的好东西。
软件(免费):UMLet(需要JAVA)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号