Spark-Streaming (组件篇 二)
https://www.cnblogs.com/liuliliuli2017/p/6809094.html
Spark Streaming运行原理
spark程序是使用一个spark应用实例一次性对一批历史数据进行处理,spark streaming是将持续不断输入的数据流转换成多个batch分片,使用一批spark应用实例进行处理。
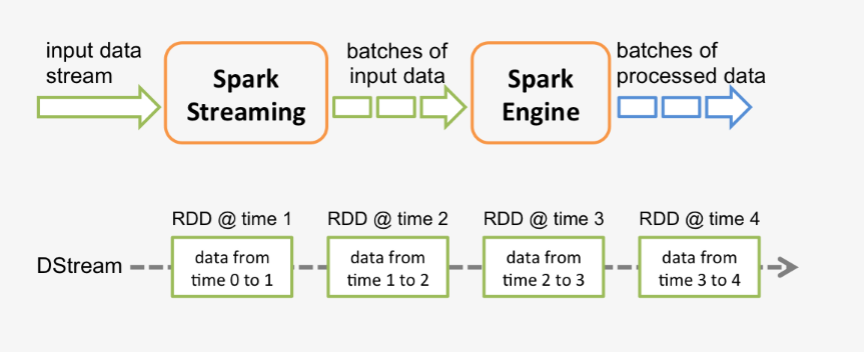
从原理上看,把传统的spark批处理程序变成streaming程序,spark需要构建什么?
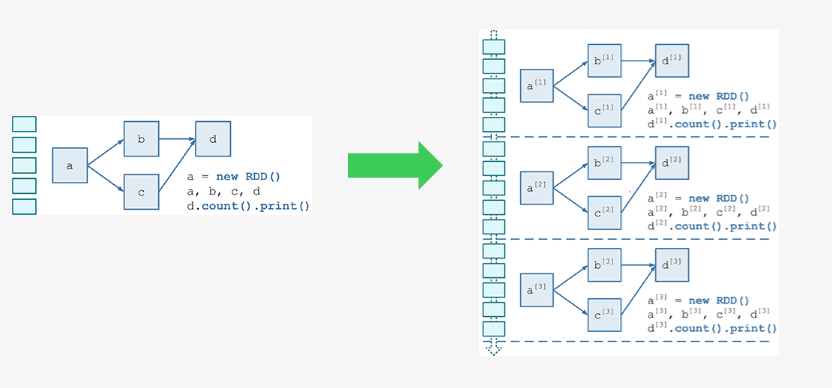
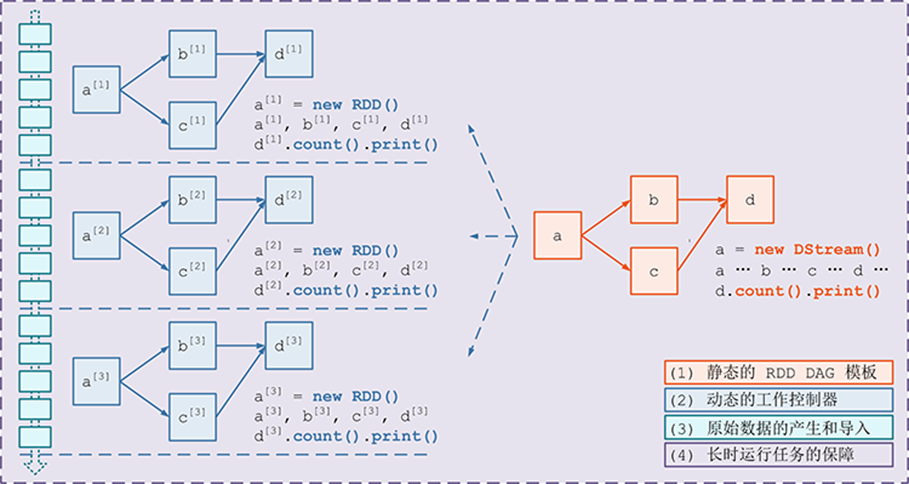
需要构建4个东西:
一个静态的 RDD DAG 的模板,来表示处理逻辑;
一个动态的工作控制器,将连续的 streaming data 切分数据片段,并按照模板复制出新的 RDD ;
DAG 的实例,对数据片段进行处理;
Receiver进行原始数据的产生和导入;Receiver将接收到的数据合并为数据块并存到内存或硬盘中,供后续batch RDD进行消费;
对长时运行任务的保障,包括输入数据的失效后的重构,处理任务的失败后的重调。
具体streaming的详细原理可以参考广点通出品的源码解析文章:
对于spark streaming需要注意以下三点:
- 尽量保证每个work节点中的数据不要落盘,以提升执行效率。
- 保证每个batch的数据能够在batch interval时间内处理完毕,以免造成数据堆积。
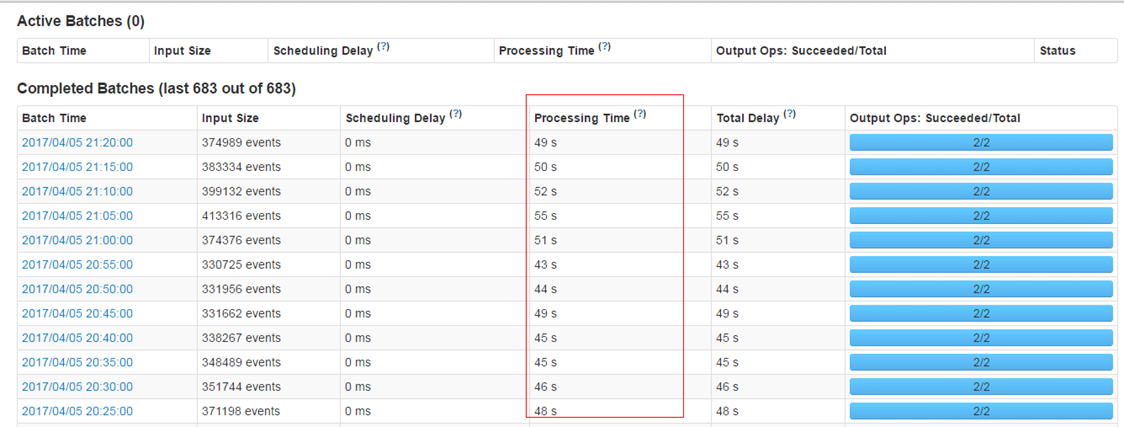
- 使用steven提供的框架进行数据接收时的预处理,减少不必要数据的存储和传输。从tdbank中接收后转储前进行过滤,而不是在task具体处理时才进行过滤。
状态管理函数
https://www.jianshu.com/p/a54b142067e5
https://my.oschina.net/u/3875806/blog/2985843
什么是状态管理函数
updateStateByKey
mapWithState
updateStateByKey和mapWithState的区别
适用场景
什么是状态管理函数
Spark Streaming中状态管理函数包括updateStateByKey和mapWithState,都是用来统计全局key的状态的变化的。它们以DStream中的数据进行按key做reduce操作,然后对各个批次的数据进行累加,在有新的数据信息进入或更新时。能够让用户保持想要的不论什么状。
updateStateByKey
updateStateByKey会统计全局的key的状态,不管又没有数据输入,它会在每一个批次间隔返回之前的key的状态。updateStateByKey会对已存在的key进行state的状态更新,同时还会对每个新出现的key执行相同的更新函数操作。如果通过更新函数对state更新后返回来为none,此时刻key对应的state状态会被删除(state可以是任意类型的数据的结构)。
mapWithState
mapWithState也会统计全局的key的状态,但是如果没有数据输入,便不会返回之前的key的状态,类似于增量的感觉。
updateStateByKey和mapWithState的区别
updateStateByKey可以在指定的批次间隔内返回之前的全部历史数据,包括新增的,改变的和没有改变的。由于updateStateByKey在使用的时候一定要做checkpoint,当数据量过大的时候,checkpoint会占据庞大的数据量,会影响性能,效率不高。
mapWithState只返回变化后的key的值,这样做的好处是,我们可以只是关心那些已经发生的变化的key,对于没有数据输入,则不会返回那些没有变化的key的数据。这样的话,即使数据量很大,checkpoint也不会像updateStateByKey那样,占用太多的存储,效率比较高(再生产环境中建议使用这个)。
适用场景
updateStateByKey可以用来统计历史数据。例如统计不同时间段用户平均消费金额,消费次数,消费总额,网站的不同时间段的访问量等指标
mapWithState可以用于一些实时性较高,延迟较少的一些场景,例如你在某宝上下单买了个东西,付款之后返回你账户里的余额信息。
posted on 2020-01-08 14:20 心有多大,世界就有多大 阅读(302) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号