Spark核心原理(核心篇 二)
目录
- 运行结构图 & 常用术语
- 消息通信原理
- 运行流程图
- 调度算法
- 容错及HA
- 监控
一、运行结构图 & 常用术语
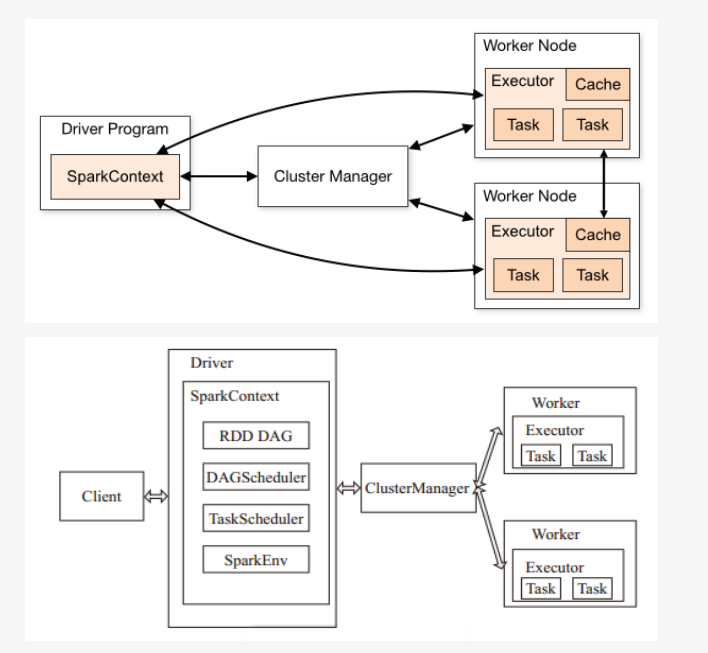
- Application: Appliction都是指用户编写的Spark应用程序,其中包括一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码
- SparkContext: Spark应用程序的入口,负责调度各个运算资源,协调各个Worker Node上的Executor
- Driver: Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,在执行阶段,Driver会将Task和Task所依赖的file和jar序列化后传递给对应的Worker机器。当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver
- Cluter Manager:指的是在集群上获取资源的外部服务。目前有三种类型
- Standalone : spark原生的资源管理,由Master负责资源的分配
- Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
- Hadoop Yarn: 主要是指Yarn中的ResourceManager
- Master: 作为整个集群的控制器,负责整个集群的正常运行。(注:如果是yarn cluster方式,是运行在nodemanager上的)
- Worker: 集群中任何可以运行Application代码的节点,在Standalone模式中指的是通过slave文件配置的Worker节点,在Spark on Yarn模式下就是NoteManager节点
- Executor: 某个Application运行在worker节点上的一个进程, 该进程负责运行某些Task, 并且负责将数据存到内存或磁盘上,每个Application都有各自独立的一批Executor, 在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutor Backend。一个CoarseGrainedExecutor Backend有且仅有一个Executor对象, 负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个oarseGrainedExecutor Backend能并行运行Task的数量取决与分配给它的cpu个数
- 作业(Job): 包含多个Task组成的并行计算,往往由Spark Action触发生成, 一个Application中往往会产生多个Job
- 调度阶段(Stage): 每个Job会被拆分成多组Task, 作为一个TaskSet, 其名称为Stage,Stage的划分和调度是有DAGScheduler来负责的,Stage有非最终的Stage(Shuffle Map Stage)和最终的Stage(Result Stage)两种,Stage的边界就是发生shuffle的地方
- Task: 被送到某个Executor上的工作单元,但hadoopMR中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理等是由TaskScheduler负责
- DAGScheduler: 根据Job构建基于Stage的DAG(Directed Acyclic Graph有向无环图),并提交Stage给TASkScheduler。 其划分Stage的依据是RDD之间的依赖的关系找出开销最小的调度方法,如下图

- TASKSedulter: 将TaskSET提交给worker运行,每个Executor运行什么Task就是在此处分配的. TaskScheduler维护所有TaskSet,当Executor向Driver发生心跳时,TaskScheduler会根据资源剩余情况分配相应的Task。另外TaskScheduler还维护着所有Task的运行标签,重试失败的Task。下图展示了TaskScheduler的作用

- 将这些术语串起来的运行层次图如下:

- Job=多个stage,Stage=多个同种task, Task分为ShuffleMapTask和ResultTask,Dependency分为ShuffleDependency和NarrowDependenc
二、 消息通信原理
三、 行流程图
1、任务启动流程图

A、构建Spark Application的运行环境,启动SparkContext
B、SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动StandaloneExecutorbackend,
C、Executor向SparkContext申请Task
D、SparkContext将应用程序分发给Executor
E、SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行
F、Task在Executor上运行,运行完释放所有资源
二、Spark作业和任务调度
DAGScheduler负责任务的逻辑调度,将作业拆分成不同阶段的具有依赖关系的任务集
TaskScheduler负责具体任务的调度执行

提交作业 –> 划分调度阶段 –> 提交调度阶段 –> 提交任务 –> 执行任务 –> 获取执行结果
- RDD在Spark中运行大概分为以下三步:
- 创建RDD对象
- DAGScheduler模块介入运算,计算RDD之间的依赖关系,RDD之间的依赖关系就形成了DAG
- 每一个Job被分为多个Stage。划分Stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个Stage,避免多个Stage之间的消息传递开销
- 以下面一个按 A-Z 首字母分类,查找相同首字母下不同姓名总个数的例子来看一下 RDD 是如何运行起来的

- 创建 RDD 上面的例子除去最后一个 collect 是个动作,不会创建 RDD 之外,前面四个转换都会创建出新的 RDD 。因此第一步就是创建好所有 RDD( 内部的五项信息 )?
- 创建执行计划 Spark 会尽可能地管道化,并基于是否要重新组织数据来划分 阶段 (stage) ,例如本例中的 groupBy() 转换就会将整个执行计划划分成两阶段执行。最终会产生一个 DAG(directed acyclic graph ,有向无环图 ) 作为逻辑执行计划
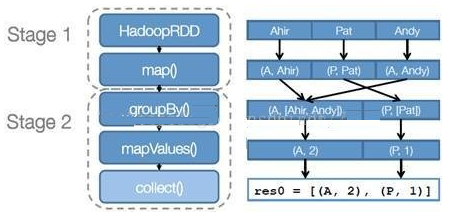
- 调度任务 将各阶段划分成不同的 任务 (task) ,每个任务都是数据和计算的合体。在进行下一阶段前,当前阶段的所有任务都要执行完成。因为下一阶段的第一个转换一定是重新组织数据的,所以必须等当前阶段所有结果数据都计算出来了才能继续
Spark运行特点:
- 每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行Task。这种Application隔离机制是有优势的,无论是从调度角度看(每个Driver调度他自己的任务),还是从运行角度看(来自不同Application的Task运行在不同JVM中),当然这样意味着Spark Application不能跨应用程序共享数据,除非将数据写入外部存储系统
- Spark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了
- 提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换
- Task采用了数据本地性和推测执行的优化机制
四、 调度算法
1、应用程序之间如何调度:
2、作业(Job)之间如何调度:
3、任务(Task)之间如何调度:
五、容错及HA
1、Executor异常
2、Worker异常
3、Master异常
六、监控
Spark提供了UI监控、Spark Metrics和REST 3种方式监控应用程序运行状态
posted on 2020-01-08 13:42 心有多大,世界就有多大 阅读(374) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号