

一对多表关联(转载虾皮工作室)
5、多表关联
多表关联和单表关联类似,它也是通过对原始数据进行一定的处理,从其中挖掘出关心的信息。下面进入这个实例。
5.1 实例描述
输入是两个文件,一个代表工厂表,包含工厂名列和地址编号列;另一个代表地址表,包含地址名列和地址编号列。要求从输入数据中找出工厂名和地址名的对应关系,输出"工厂名——地址名"表。
样例输入如下所示。
1)factory:
factoryname addressed
Beijing Red Star 1
Shenzhen Thunder 3
Guangzhou Honda 2
Beijing Rising 1
Guangzhou Development Bank 2
Tencent 3
Back of Beijing 1
2)address:
addressID addressname
1 Beijing
2 Guangzhou
3 Shenzhen
4 Xian
样例输出如下所示。
factoryname addressname
Back of Beijing Beijing
Beijing Red Star Beijing
Beijing Rising Beijing
Guangzhou Development Bank Guangzhou
Guangzhou Honda Guangzhou
Shenzhen Thunder Shenzhen
Tencent Shenzhen
5.2 设计思路
多表关联和单表关联相似,都类似于数据库中的自然连接。相比单表关联,多表关联的左右表和连接列更加清楚。所以可以采用和单表关联的相同的处理方式,map识别出输入的行属于哪个表之后,对其进行分割,将连接的列值保存在key中,另一列和左右表标识保存在value中,然后输出。reduce拿到连接结果之后,解析value内容,根据标志将左右表内容分开存放,然后求笛卡尔积,最后直接输出。
这个实例的具体分析参考单表关联实例。下面给出代码。
5.3 程序代码
程序代码如下所示:
package com.hebut.mr;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MTjoin {
public static int time = 0;
/*
* 在map中先区分输入行属于左表还是右表,然后对两列值进行分割,
* 保存连接列在key值,剩余列和左右表标志在value中,最后输出
*/
public static class Map extends Mapper<Object, Text, Text, Text> {
// 实现map函数
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();// 每行文件
String relationtype = new String();// 左右表标识
// 输入文件首行,不处理
if (line.contains("factoryname") == true
|| line.contains("addressed") == true) {
return;
}
// 输入的一行预处理文本
StringTokenizer itr = new StringTokenizer(line);
String mapkey = new String();
String mapvalue = new String();
int i = 0;
while (itr.hasMoreTokens()) {
// 先读取一个单词
String token = itr.nextToken();
// 判断该地址ID就把存到"values[0]"
if (token.charAt(0) >= '0' && token.charAt(0) <= '9') {
mapkey = token;
if (i > 0) {
relationtype = "1";
} else {
relationtype = "2";
}
continue;
}
// 存工厂名
mapvalue += token + " ";
i++;
}
// 输出左右表
context.write(new Text(mapkey), new Text(relationtype +"+"+ mapvalue));
}
}
/*
* reduce解析map输出,将value中数据按照左右表分别保存,
* 然后求出笛卡尔积,并输出。
*/
public static class Reduce extends Reducer<Text, Text, Text, Text> {
// 实现reduce函数
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// 输出表头
if (0 == time) {
context.write(new Text("factoryname"), newText("addressname"));
time++;
}
int factorynum = 0;
String[] factory = new String[10];
int addressnum = 0;
String[] address = new String[10];
Iterator ite = values.iterator();
while (ite.hasNext()) {
String record = ite.next().toString();
int len = record.length();
int i = 2;
if (0 == len) {
continue;
}
// 取得左右表标识
char relationtype = record.charAt(0);
// 左表
if ('1' == relationtype) {
factory[factorynum] = record.substring(i);
factorynum++;
}
// 右表
if ('2' == relationtype) {
address[addressnum] = record.substring(i);
addressnum++;
}
}
// 求笛卡尔积
if (0 != factorynum && 0 != addressnum) {
for (int m = 0; m < factorynum; m++) {
for (int n = 0; n < addressnum; n++) {
// 输出结果
context.write(new Text(factory[m]),
new Text(address[n]));
}
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// 这句话很关键
conf.set("mapred.job.tracker", "192.168.1.2:9001");
String[] ioArgs = new String[] { "MTjoin_in", "MTjoin_out" };
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Multiple Table Join <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "Multiple Table Join");
job.setJarByClass(MTjoin.class);
// 设置Map和Reduce处理类
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
5.4 代码结果
1)准备测试数据
通过Eclipse下面的"DFS Locations"在"/user/hadoop"目录下创建输入文件"MTjoin_in"文件夹(备注:"MTjoin_out"不需要创建。)如图5.4-1所示,已经成功创建。
图5.4-1 创建"MTjoin_in" 图5.4.2 上传两个数据表
然后在本地建立两个txt文件,通过Eclipse上传到"/user/hadoop/MTjoin_in"文件夹中,两个txt文件的内容如"实例描述"那两个文件一样。如图5.4-2所示,成功上传之后。
从SecureCRT远处查看"Master.Hadoop"的也能证实我们上传的两个文件。
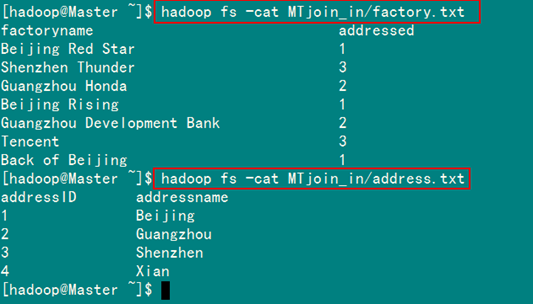
图5.4.3 两个数据表的内容
2)查看运行结果
这时我们右击Eclipse的"DFS Locations"中"/user/hadoop"文件夹进行刷新,这时会发现多出一个"MTjoin_out"文件夹,且里面有3个文件,然后打开双其"part-r-00000"文件,会在Eclipse中间把内容显示出来。如图5.4-4所示。
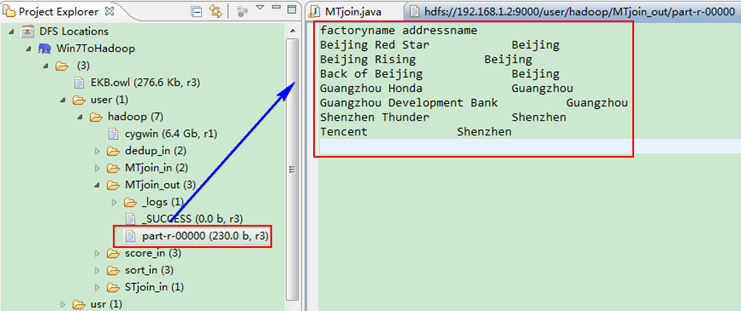
图5.4-4 运行结果

