2. 执行Spark SQL查询
2.1 命令行查询流程
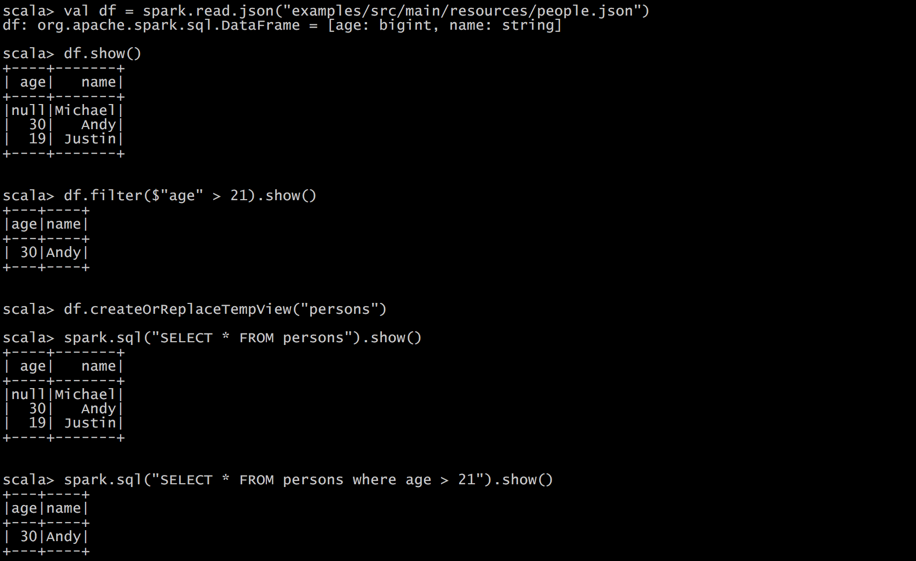
打开Spark shell
例子:查询大于21岁的用户
创建如下JSON文件,注意JSON的格式:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
2.2 IDEA创建Spark SQL程序
IDEA中程序的打包和运行方式都和SparkCore类似,Maven依赖中需要添加新的依赖项:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
程序如下:
package com.c.sparksql
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
/**
* Created by huicheng on 15/07/2019.
*/
object HelloWorld {
val logger = LoggerFactory.getLogger(HelloWorld.getClass)
def main(args: Array[String]) {
//创建 SparkConf()并设置App名称
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
val df = spark.read.json("examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdout
df.show()
df.filter($"age" > 21).show()
df.createOrReplaceTempView("persons")
spark.sql("SELECT * FROM persons where age > 21").show()
spark.stop()
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号