

(未完待续)集合框架——HashSet集合源码分析
本篇内容是对B站《韩顺平零基础30天学会java》中关于HashSet章节的一个知识回顾和总结
HashSet 相对比ArrayList、Vector及LinkedList,知识内容和难度有所提高,阅读源码更富有挑战性,不过越复杂的事物从另一方面也更加有意思
第一部分 模拟简单的HashSet底层结构
1.框架(纯总结)
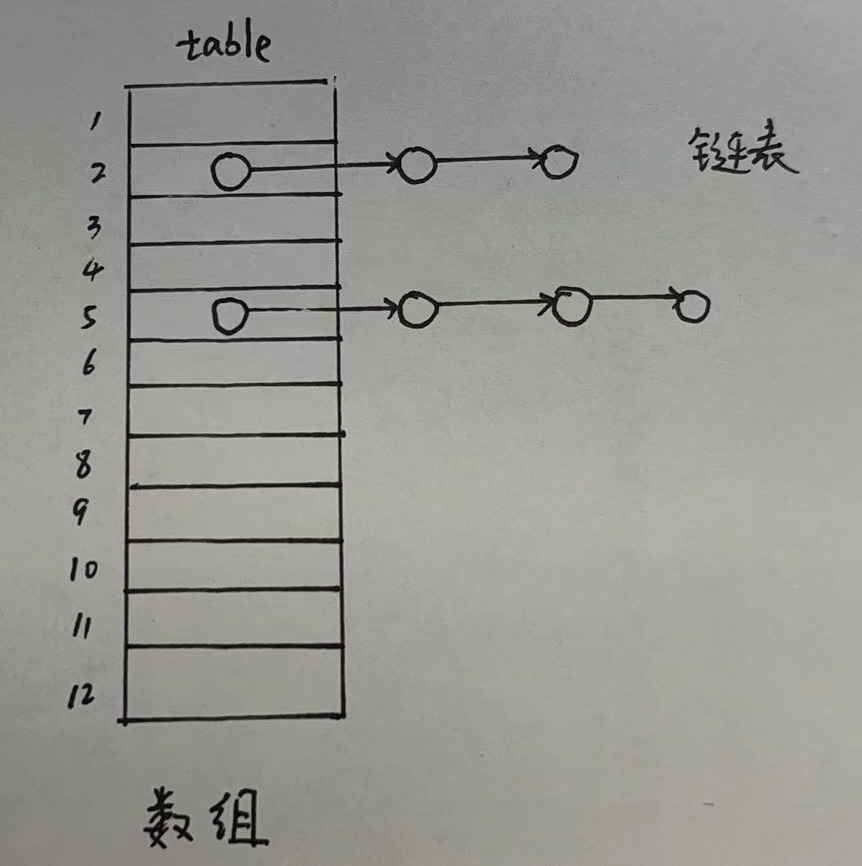
- HashSet底层为数组+链表+红黑树的结构
- 当且仅当数组容量达到64,某条链表的节点达到8,该条链表会从Node转换成TreeNode结构(即红黑树)
- 红黑树暂时没有学习,只知道是为了提高效率而采用的一种复杂的算单结构,有待后续课程中了解。
- HashSet底层为HashMap,存入元素或对象的基本原理是:
a. 创建Node类型数组table[],初始容量默认为16,扩容因子0.75,即存放元素个数达到12个会进行扩容,扩容系数为2
b. 根据存入数据的hash值计算出对应的table数组中的索引index
c. 首先跟数组中的元素进行对比(即链表的首个节点),如果节点为null,直接将元素存入table[index]
d. 如果根据index存入数组时,该table[index] != null,则遍历存储与该数组位置的链表,使用equals方法进行对比,当有相同的数据时,数据存入失败,当遍历完成没有相同的数据时,直接存放到该链表的结尾。
2.代码示例
public class HashSetStructure { public static void main(String[] args) { //模拟HashSet底层 //1.创建一个数组 表 Node[] table = new Node[16]; //2.创建节点 Node john = new Node("john", null); //假设"john"计算后的index=2 //3.将节点放到数组的第二个位置,假设"john"计算后的index=2 table[2] = john; //假设"jack"与"rose"计算后的index=2,且通过equals方法与"john"互相不相同 //4.创建新节点,并将新节点挂在上一个节点之后,形成一个单向链表, Node jack = new Node("jack", null); john.next = jack; Node rose = new Node("rose", null); jack.next = rose; //假设"lucy"计算后的index = 3 //5.将节点放到数组的第三个位置 Node lucy = new Node("lucy", null); table[3] = lucy; } } //节点,存放数据,指向下一个节点,从而形成链表 class Node { Object item; //实际存放的数据 Node next; //链表中本节点的下一个节点引用 public Node(Object item, Node next) { this.item = item; this.next = next; } }
简单来说就是以下的结构:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)