

linux c编程:标准IO库
前面介绍对文件进行操作的时候,使用的是open,read,write函数。这一章将要介绍基于流的文件操作方法:fopen,fread,fwrite。这两种方式的区别是什么呢。1种是缓冲文件系统,一种是非缓冲文件系统
缓冲文件系统就是采用fopen,fread,fwrite,fgetc,fputc,fputs等函数进行操作。缓冲文件系统的特点是:在内存开辟一个“缓冲区”,为程序中的每一个文件使用;当执行读文件的操作时,从磁盘文件将数据先读入内存“缓冲区”,装满后再从内存“缓冲区”依此读出需要的数据。执行写文件的操作时,先将数据写入内存“缓冲区”,待内存“缓冲区”装满后再写入文件。由此可以看出,内存“缓冲区”的大小,影响着实际操作外存的次数,内存“缓冲区”越大,则操作外存的次数就少,执行速度就快、效率高。一般来说,文件“缓冲区”的大小随机器 而定。fopen, fclose, fread, fwrite, fgetc, fgets, fputc, fputs, freopen, fseek, ftell, rewind等。
非缓冲系统:
缓冲文件系统是借助文件结构体指针来对文件进行管理,通过文件指针来对文件进行访问,既可以读写字符、字符串、格式化数据,也可以读写二进制数据。非缓冲文件系统依赖于操作系统,通过操作系统的功能对文件进行读写,是系统级的输入输出,它不设文件结构体指针,只能读写二进制文件,但效率高、速度快。
从上面的描述差异可以看出,fopen是c标准函数,具有良好的移植性; 而open是linux系统调用,移植性有限。如果从文件IO的角度来看,非缓冲系统属于低级IO函数,缓冲系统属于高级IO函数。低级和高级的简单区分标准是:谁离系统内核更近。低级文件IO运行在内核态,高级文件IO运行在用户态。
来看下面的代码
#include <stdio.h>
const char *pathname="/home/zhf/test1.txt
void read_file_by_stream(){
FILE *fp;
const char * type="r";
char *string;
int c;
fp=fopen(pathname,type);
c=fgetc(fp);
printf("%c",c);
}
在这里采用了fopen和fgetc函数来读文件打开和读取。
fopen的原型:
FILE *fopen(const char *restrict pathname, const char *restrict type);
打开方式参考如下:
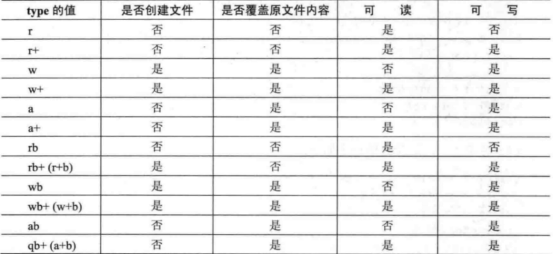
fgetc函数的原型:
int fgetc(FILE *fp); 返回的是读取到的一个字符。返回的是整型
前面的代码只能一次性读取一个字符,那么要读取整个文件的内容就要采集循环的方式了。代码修改如下
void read_file_by_stream(){
FILE *fp;
const char * type="r";
char *string;
int c;
fp=fopen(pathname,type);
if (ferror(fp)){
printf("open file error");
}
while((c=fgetc(fp)) != EOF){
printf("%c",c);
}
fclose(fp);
}
ferror是判断文件在打开的时候是否有错误,如果有则进行提示
c=fgetc(fp)) != EOF: 要判断是否读取到了文件的末尾,则采用和EOF进行比较的方式。 EOF是一个负值,一般为-1,因为fgetc的返回值是将unsigned char转换成int。 如果最高位为1也不会使返回值为负。因此只要fgetc的返回值不是EOF,则表明可以继续往下读取字符。
fgetc一次只能读取一个字符,这样的读取效率太低。是否能够做到一次读取一行的数据呢。 方法是用fgets函数
char *fgets(char *buf,int n,FILE *fp)
#include <stdio.h>
const char *pathname="/home/zhf/test1.txt";
void read_file_by_stream(){
FILE *fp;
const char * type="r";
char buf[100];
char *string;
int c;
fp=fopen(pathname,type);
if (ferror(fp)){
printf("open file error");
}
while(fgets(buf,10,fp) != NULL){
printf("The content is %s",buf);
}
fclose(fp);
}
当返回的指针不会空的时候,读取每行的数据
The content is abcde
The content is kjkl
当然也可以采用gets函数,区别在于无法指定缓冲区的长度,fgets必须指定缓冲区的长度。fgets一直读到下一个换行符为止,但是不超过n-1个字符。对应的输入函数分别是fputc和fputs这里就不再介绍了
前面介绍的fgetc,fgets都只能读取一个或者一行字符。且遇到如果文件中有null字符的时候则会停止。特别是网络操作的时候,会写入各种各样的符号。在这种情况下就需要用到二进制I/O,也就是fread和fwrite函数
fwrite:
- size_t fwrite(const void* buffer, size_t size, size_t count, FILE* stream);
- -- buffer:指向数据块的指针
- -- size:每个数据的大小,单位为Byte(例如:sizeof(int)就是4)
- -- count:数据个数
- -- stream:文件指针
调用格式:fwrite(buf,sizeof(buf),1,fp);成功写入返回值为1(即count)
调用格式:fwrite(buf,1,sizeof(buf),fp);成功写入则返回实际写入的数据个数(单位为Byte)
fread:
- size_t fread(void *buffer, size_t size, size_t count, FILE *stream);
- -- buffer:指向数据块的指针
- -- size:每个数据的大小,单位为Byte(例如:sizeof(int)就是4)
- -- count:数据个数
- -- stream:文件指针
(1) 调用格式:fread(buf,sizeof(buf),1,fp);
读取成功时:当读取的数据量正好是sizeof(buf)个Byte时,返回值为1(即count)
否则返回值为0(读取数据量小于sizeof(buf))
(2)调用格式:fread(buf,1,sizeof(buf),fp);
读取成功返回值为实际读回的数据个数(单位为Byte)
代码如下:
void read_file_by_binary(){
int flag;
FILE *fp;
FILE *fp1;
const char *type="a+";
char buf[20]="it is test\n";
char buffer[200];
fp=fopen(pathname,type);
fwrite(buf,sizeof(buf),1,fp);
fclose(fp);
fp1=fopen(pathname,type);
flag=fread(buffer,1,sizeof(buffer),fp1);
printf("%ld,%d",sizeof(buffer),flag);
printf("%s",buffer);
fclose(fp1);
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架