

python网络爬虫之使用scrapy下载文件
前面介绍了ImagesPipeline用于下载图片,Scrapy还提供了FilesPipeline用与文件下载。和之前的ImagesPipeline一样,FilesPipeline使用时只需要通过item的一个特殊字段将要下载的文件或图片的url传递给它们,它们便会自动将文件或图片下载到本地。将下载结果信息存入item的另一个特殊字段,便于用户在导出文件中查阅。工作流程如下:
1 在一个爬虫里,你抓取一个项目,把其中图片的URL放入 file_urls 组内。
2 项目从爬虫内返回,进入项目管道。
3 当项目进入 FilesPipeline,file_urls 组内的URLs将被Scrapy的调度器和下载器(这意味着调度器和下载器的中间件可以复用)安排下载,当优先级更高,会在其他页面被抓取前处理。项目会在这个特定的管道阶段保持“locker”的状态,直到完成文件的下载(或者由于某些原因未完成下载)。
4 当文件下载完后,另一个字段(files)将被更新到结构中。这个组将包含一个字典列表,其中包括下载文件的信息,比如下载路径、源抓取地址(从 file_urls 组获得)和图片的校验码(checksum)。 files 列表中的文件顺序将和源 file_urls 组保持一致。如果某个图片下载失败,将会记录下错误信息,图片也不会出现在 files 组中。
下面来看下如何使用:
第一步:在配置文件settings.py中启用FilesPipeline
ITEM_PIPELINES = {
'scrapy.pipelines.files.FilesPipeline':1,
}
第二步:在配置文件settings.py中设置文件下载路径
FILE_STORE='E:\scrapy_project\file_download\file'
第三步:在item.py中定义file_url和file两个字段
class FileDownloadItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
file_urls=scrapy.Field()
files=scrapy.Field()
这三步设置后以后,下面就来看下具体的下载了,我们从matplotlib网站上下载示例代码。网址是:http://matplotlib.org/examples/index.html
接下来来查看网页结构,如下

点击animate_decay后进入下载页面。Animate_decay的网页链接都在<div class=”toctree-wrapper compound”>元素下。
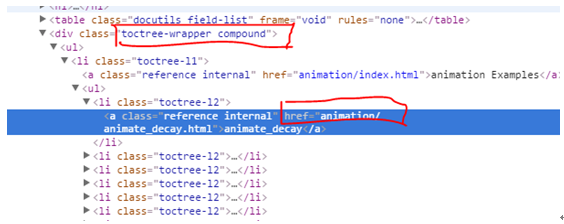
但是像animation Examples这种索引的链接我们是不需要的

通过这里我们可以首先写出我们的网页获取链接的方式:
def parse(self,response):
le=LinkExtractor(restrict_xpaths='//*[@id="matplotlib-examples"]/div',deny='/index.html$')
for link in le.extract_links(response):
yield Request(link.url,callback=self.parse_link)
restrict_xpaths设定网页链接的元素。Deny将上面的目录链接给屏蔽了。因此得到的都是具体的文件的下载链接
接下来进入下载页面,网页结构图如下:点击source_code就可以下载文件

网页结构如下

还有另外一种既包含代码链接,又包含图片链接的

从具体的文件下载链接来看有如下两种;
http://matplotlib.org/examples/pyplots/whats_new_99_mplot3d.py
http://matplotlib.org/mpl_examples/statistics/boxplot_demo.py
针对这两种方式获取对应的链接代码如下:
def parse_link(self,response):
pattern=re.compile('href=(.*\.py)')
div=response.xpath('/html/body/div[4]/div[1]/div/div')
p=div.xpath('//p')[0].extract()
link=re.findall(pattern,p)[0]
if ('/') in link: #针对包含文件,图片的下载链接方式生成:http://matplotlib.org/examples/pyplots/whats_new_99_mplot3d.py
href='http://matplotlib.org/'+link.split('/')[2]+'/'+link.split('/')[3]+'/'+link.split('/')[4]
else: #针对只包含文件的下载链接方式生成:http://matplotlib.org/mpl_examples/statistics/boxplot_demo.py
link=link.replace('"','')
scheme=urlparse(response.url).scheme
netloc=urlparse(response.url).netloc
temp=urlparse(response.url).path
path='/'+temp.split('/')[1]+'/'+temp.split('/')[2]+'/'+link
combine=(scheme,netloc,path,'','','')
href=urlunparse(combine)
# print href,os.path.splitext(href)[1]
file=FileDownloadItem()
file['file_urls']=[href]
return file
运行后出现如下的错误:提示ValueError: Missing scheme in request url: h。
2017-11-21 22:29:53 [scrapy] ERROR: Error processing {'file_urls': u'http://matplotlib.org/examples/api/agg_oo.htmlagg_oo.py'}
Traceback (most recent call last):
File "E:\python2.7.11\lib\site-packages\twisted\internet\defer.py", line 588, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "E:\python2.7.11\lib\site-packages\scrapy\pipelines\media.py", line 44, in process_item
requests = arg_to_iter(self.get_media_requests(item, info))
File "E:\python2.7.11\lib\site-packages\scrapy\pipelines\files.py", line 365, in get_media_requests
return [Request(x) for x in item.get(self.files_urls_field, [])]
File "E:\python2.7.11\lib\site-packages\scrapy\http\request\__init__.py", line 25, in __init__
self._set_url(url)
File "E:\python2.7.11\lib\site-packages\scrapy\http\request\__init__.py", line 57, in _set_url
raise ValueError('Missing scheme in request url: %s' % self._url)
ValueError: Missing scheme in request url: h
这个错误的意思是在url中丢失了scheme. 我们知道网址的一般结构是:scheme://host:port/path?。 这里的错误意思就是在scheme中没有找到http而只有一个h. 但是从log记录的来看,我们明明是生成了一个完整的网页呢。为什么会提示找不到呢。原因就在于下面的这个配置使用的是url列表形式
ITEM_PIPELINES = {
# 'file_download.pipelines.SomePipeline': 300,
'scrapy.pipelines.files.FilesPipeline':1,
}
而我们的代码对于item的赋值却是file['file_urls']=href 字符串的形式,因此如果用列表的方式来提取数据,只有h被提取出来了。因此代码需要成列表的赋值形式。修改为:file['file_urls']=[href]就可以了
程序运行成功。从保存路径来看,在download下面新建了一个full文件夹。然后下载的文件都保存在里面。但是文件名却是00f4d142b951f072.py这种形式的。这些文件名是由url的散列值的出来的。这种命名方式可以防止重名的文件相互冲突,但是这种文件名太不直观了,我们需要重新来定义下载的文件名名字

在FilesPipeline中,下载文件的函数是file_path。主体代码如下
Return的值就是文件路径。从下面看到是文件都是建立在full文件下面
media_guid = hashlib.sha1(to_bytes(url)).hexdigest()
media_ext = os.path.splitext(url)[1]
return 'full/%s%s' % (media_guid, media_ext)
media_guid得到的是url的散列值,作为文件名
media_ext得到的是文件的后缀名也就是.py
下面我们来重新写file_path函数用于生成我们自己的文件名
我们可以看到有很多网址是下面的形式,widgets是大类。后面的py文件是这个大类下的文件。我们需要将属于一个大类的文件归档到同一个文件夹下面。
http://matplotlib.org/examples/widgets/span_selector.py http://matplotlib.org/examples/widgets/rectangle_selector.py
http://matplotlib.org/examples/widgets/slider_demo.py
http://matplotlib.org/examples/widgets/radio_buttons.py
http://matplotlib.org/examples/widgets/menu.py
http://matplotlib.org/examples/widgets/multicursor.py
http://matplotlib.org/examples/widgets/lasso_selector_demo.py
比如网页为http://matplotlib.org/examples/widgets/span_selector.py
urlparse(request.url).path 得到的结果是examples/widgets/span_selector.py
dirname(path)得到的结果是examples/widgets
basename(dirname(path))得到的结果是widgets
join(basename(dirname(str)),basename(str))得到的结果是widgets\ span_selector.py
重写pipeline.py如下:
from scrapy.pipelines.files import FilesPipeline
from urlparse import urlparse
from os.path import basename,dirname,join
class FileDownloadPipeline(FilesPipeline):
def file_path(self, request, response=None, info=None):
path=urlparse(request.url).path
temp=join(basename(dirname(path)),basename(path))
return '%s/%s' % (basename(dirname(path)), basename(path))
运行程序发现生成的文件名还是散列值的。原因在于在之前的setting.py中,我们设置的是'scrapy.pipelines.files.FilesPipeline':1
这将会直接采用FilesPipeline。现在我们重写了FilesPipeline就需要更改这个设置,改为FileDownloadPipeline
ITEM_PIPELINES = {
# 'file_download.pipelines.SomePipeline': 300,
# 'scrapy.pipelines.files.FilesPipeline':1,
'file_download.pipelines.FileDownloadPipeline':1,
}
再次运行,得到如下的结果:同一类的文件都被归类到了同一个文件夹下面。

且文件名采用的是更直观的方式。这样比散列值的文件名看起来直观多了

matplotlib文件打包的下载链接如下,有需要的可以下载
https://files.cnblogs.com/files/zhanghongfeng/matplotlib.rar
scrapy工程代码如下:
https://files.cnblogs.com/files/zhanghongfeng/file_download.rar


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架