

python网络爬虫之scrapy 工程创建以及原理介绍
执行scrapy startproject XXXX的命令,就会在对应的目录下生成工程
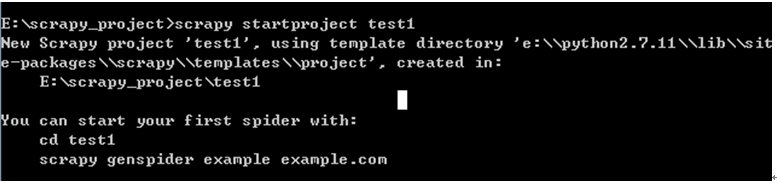
在pycharm中打开此工程目录:并在Run中选择Edit Configuration
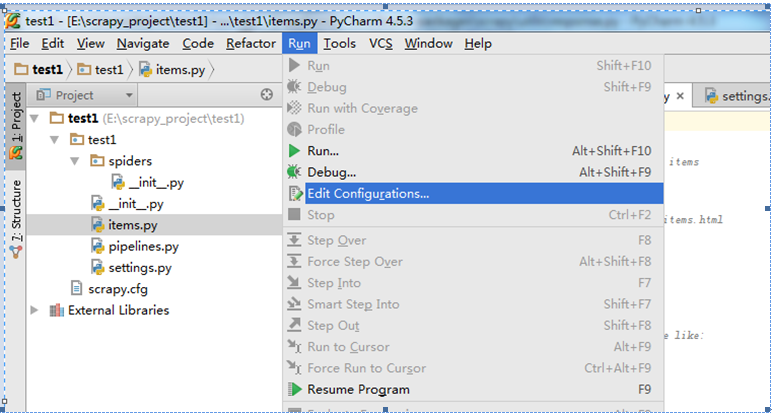
点击+创建一个Python
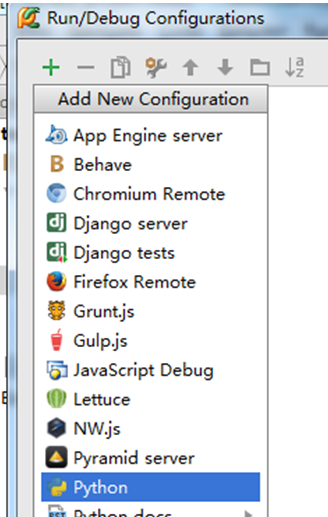
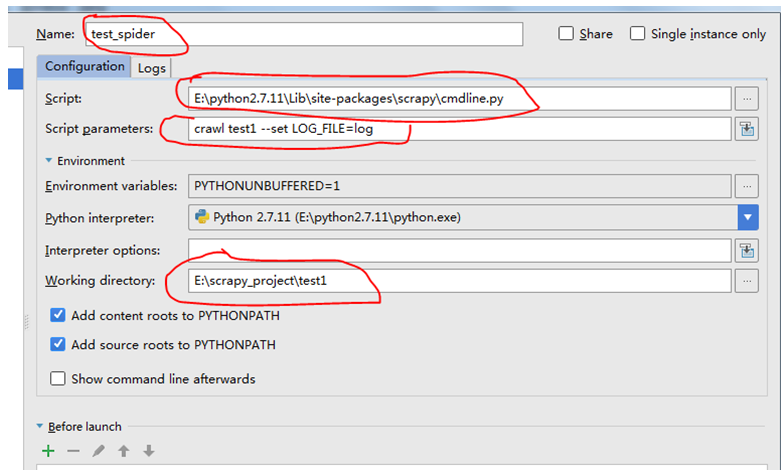
命令爬虫的名字,本例中以test_spider为例。并在script中输入安装scrapy的cmdline.py的路径。
在工程目录test1->spiders下面创建一个python文件,名字和上图中的name一致,这里都是test_spider
在代码中加入简单的代码:如下新建一个类名字为testSpider。注意类中必须添加name字段。这个设置爬虫工程的名称且必须和创建工程的scrapy startproject test1一样,因此这里为name=test1.
# -*- coding:UTF-8 -*- #
from scrapy.spiders import Spider
from scrapy.selector import Selector
from test1.items import Test1Item
from scrapy.utils.response import open_in_browser
class testSpider(Spider):
name="test1"
def parse(self, response):
pass
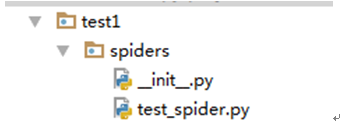
名字如果不一致,会出现报错:
如果改成这样:name=test2
class testSpider(Spider):
name="test2"
def parse(self, response):
pass
会产生如下错误:Spider not found: “test1”
下面来介绍下Scrapy工作原理:
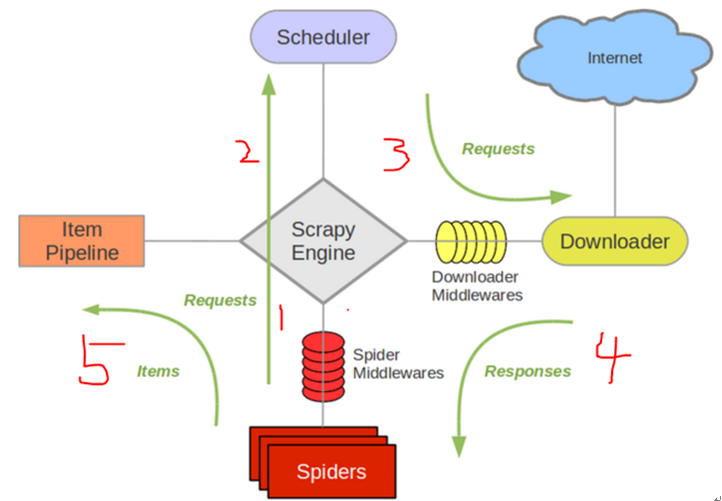
按照上面的图来说下scrapy的工作流程:
1.引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。 图中步骤1
如具体的spider函数中会定义:allowd_domains以及start_urls两个变量
allowd_domains=['http://www.xunread.com/']
start_urls=["http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/index.shtml"]
此时会将这2个变量发给引擎
2.引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。 图中步骤2
引擎获取到要爬去的URL后,进行网站链接
4.调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。 图中步骤3
5.一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。 图中步骤4
此时代码中通过sel=Selector(response)获取到下载的页面
def parse(self,response):
sel=Selector(response)
7.Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。步骤5
具体对item的处理过程在parse函数中. 并将处理的结果传入pipeline.py进行处理
8.引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。至此一个完整的一个网页调度流程结束。如果parse函数有继续返回网页,则从头开始上面的过程
9.(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
各模块的介绍如下:
组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
下载器中间件(Downloader
middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
数据流详细过程如下:
Scrapy中的数据流由执行引擎控制,其过程如下:
1.引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。 步骤1
2.引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
3.引擎向调度器请求下一个要爬取的URL。
4.调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
5.一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
6.引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
7.Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
8.引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
9.(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架