
数据驱动JSON+YAML+CSV+Excel
数据驱动:
在自动化测试中,把测试中使用到的数据分离出来
把测试数据放在Json文件中
新建文件“xxx.json”
放在JSON文件中,花括号开头(字典类型)
注意事项:
1、JSON中对象的属性名必须为双引号,属性值如果是字符串也必须是双引号
2、JSON中只要设计到字符串,就必须使用双引号
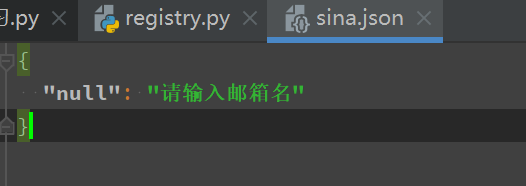
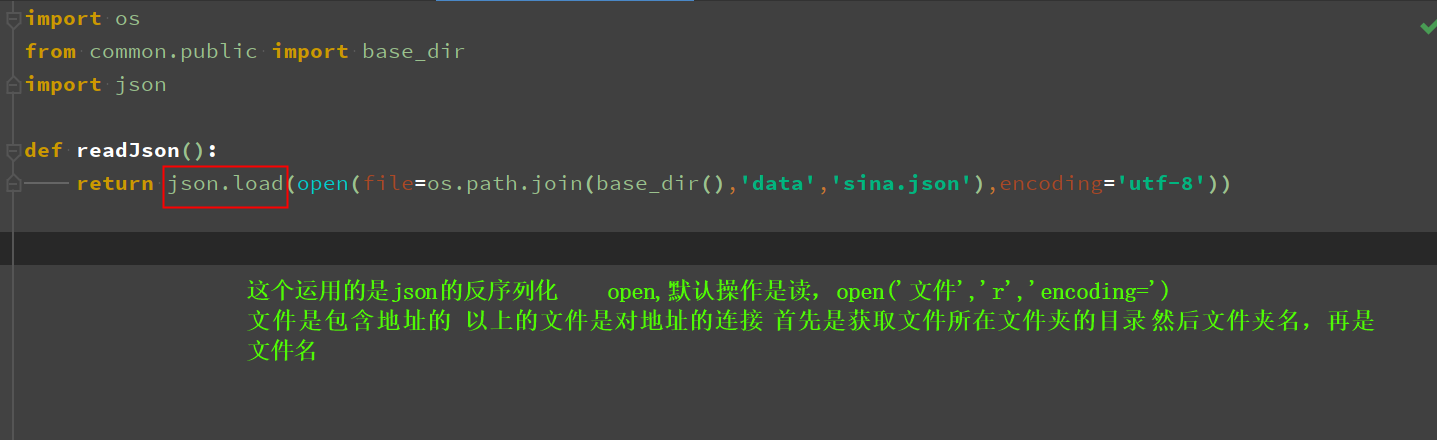
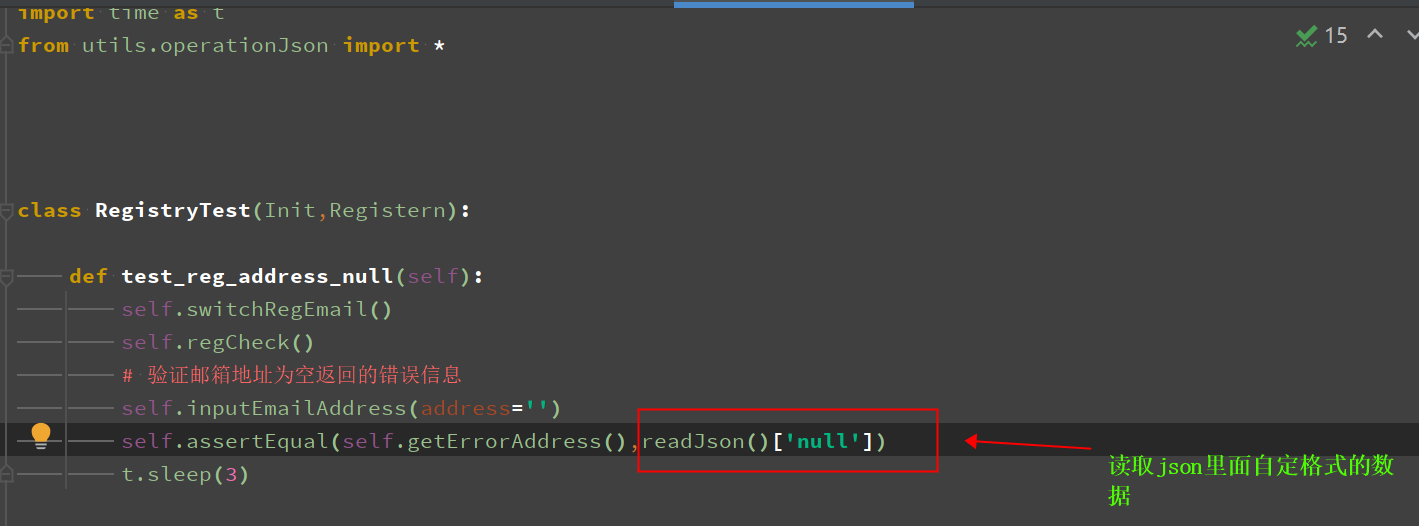
在测试中调用json文件中的数据(字典类型 根据key获取值)
测试数据放在YAML文件:
新建文件“xxxx.yaml”
注意事项:
(注意!yaml文件中的冒号后面必须要有一个空格,如果没有空格,颜色都是不对的)
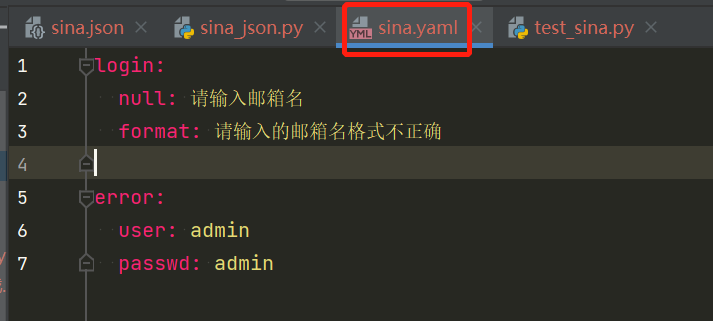
yaml.safe_load()读取文件
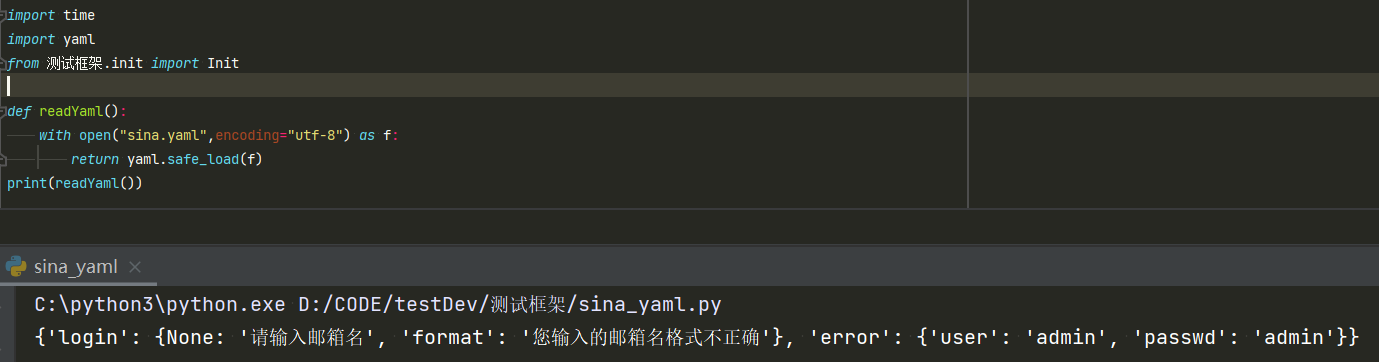
js java go 语言的: "null" "true" "false"
相当于python中的:"None" "True" "False"
有异常时 在python中CTRL+R 替换一下。
csv文件的读取:
通过列表的方式读取:
import csv # 通过列表的方式读取csv文件 def readCsvList(): lists=[] with open('data.csv','r',encoding='utf-8')as f: reader=csv.reader(f) # 第一行不读 从第二行开始(忽略第一行) next(reader) # 对reader进行循环 for item in reader: # 把它添加到列表中 lists.append(item) return lists print(readCsvList())
通过字典的方式读取:
import csv # 字典的方式读取csv文件 def readCsvDict(): lists=[] with open('data.csv','r',encoding='utf-8-sig')as f: reader=csv.DictReader(f) # 对reader进行循环 for item in reader: # 把它添加到列表中 lists.append(dict(item)) return lists print(readCsvDict())
excel文件的读取:
# 这个需要安装第三方库 pip install xlrd==1.2.0 import xlrd def readExcel(): lists=[] book=xlrd.open_workbook('data.xlsx') # 这个读那个sheet里的文件 sheet=book.sheet_by_index(0) # 通过行进行循环,range表达是范围 for item in range(1,sheet.nrows): # 把它的值添加到列表一个列表中 lists.append(sheet.row_values(item)) return lists print(readExcel())
