爬虫介绍
爬虫是什么?
-爬虫就是程序---》从互联网中,各个网站上,爬取数据[你能浏览的页面才能爬],做数据清晰
爬虫的本质
-模拟http请求,获取数据---》入库
-网站
-app:抓包
补充:百度其实就是一个大爬虫
-百度爬虫一刻不停的在互联网中爬取各个页面---》爬取完后---》保存到自己的数据库中
-你在百度搜索框中搜索---》百度自己的数据库查询关键字---》返回回来
-点击某个页面----》跳转到真正的地址上
-seo:
-sem:充钱的
我们所学习的
-模拟发送http请求
-requests模块
-selenium
-反爬:封ip,解决ip代理,封账号:解决cookie池
-爬虫框架:scrapy
requests模块介绍
使用python如何发送http请求
模块:requests模块,封装了python内置模块urllib
使用requests可以模拟浏览器的请求(http),比起之前用到的urllib,requests模块的api更加快捷(本质就是封装了urllib3)
安装:
pip3 install requests
request发送get请求
import requests
#
# res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html')
# print(res.text)
# 如果有的网站,发送请求,不返回数据,人家做了反扒---》拿不到数据,学习如何反扒
# res = requests.get('https://dig.chouti.com/')
# print(res.text)
requests携带参数
import requests
# 方式一:直接拼接到路径中
# res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html?name=lqz&age=19')
# 方式二:使用params参数
res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html',params={'name':"lqz",'age':19})
# print(res.text)
print(res.url)
url编码解码
import requests
from urllib.parse import quote,unquote
# res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html',params={'name':"彭于晏",'age':19})
# # print(res.text)
#
# # 如果是中文,在地址栏中会做url的编码:彭于晏:%E5%BD%AD%E4%BA%8E%E6%99%8F
# print(res.url)
# 'https://www.baidu.com/s?wd=%E5%B8%85%E5%93%A5'
# 编码:
# res=quote('彭于晏')
# print(res)
# 解码
res=unquote('%E5%BD%AD%E4%BA%8E%E6%99%8F')
print(res)
携带请求头
反爬措施之一就是请求头
http请求中,请求头中有一个很重要的参数User-Agent
-表明了客户端类型是什么:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36
-如果没有带这个请求头,后端就禁止
-requests发送请求,没有携带该参数,所以有的网站就禁止了
import requests
# http请求头:User-Agent,cookie,Connection
# http协议版本间的区别
# Connection: keep-alive
# http协议有版本:主流1.1 0.9 2.x
# http 基于TCP 如果建立一个http链接---》底层创建一个tcp链接
# 1.1比之前多了keep-alive
# 2.x比1.x多了 多路复用
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
res = requests.get('https://dig.chouti.com/',headers=headers)
print(res.text)
发送post请求,携带数据
import requests
# 携带登录信息,携带cookie
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'Cookie': ''
}
# post请求,携带参数
data = {
'linkId': '38063872'
}
res = requests.post('https://dig.chouti.com/link/vote', headers=headers, data=data)
print(res.text)
# 双token认证
自动登录,携带cookie的两种方式
# 登录功能,一般都是post
import requests
data = {
'username': '',
'password': '',
'captcha': '3456',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
res = requests.post('http://www.aa7a.cn/user.php',data=data)
print(res.text)
# 响应中会有登录成功的的cookie,
print(res.cookies) # RequestsCookieJar 跟字典一样
# 拿着这个cookie,发请求,就是登录状态
# 访问首页,get请求,携带cookie,首页返回的数据一定会有 我的账号
# 携带cookie的两种方式 方式一是字符串,方式二是字典或CookieJar对象
# 方式二:放到cookie参数中
res1=requests.get('http://www.aa7a.cn/',cookies=res.cookies)
print('616564099@qq.com' in res1.text)
requests.session的使用
为了保持cookie,以后不需要携带cookie
import requests
data = {
'username': '',
'password': '',
'captcha': '3456',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
session = requests.session()
res = session.post('http://www.aa7a.cn/user.php', data=data)
print(res.text)
res1 = session.get('http://www.aa7a.cn/') # 自动保持登录状态,自动携带cookie
print('616564099@qq.com' in res1.text)
补充post请求携带数据编码格式
import requests
# data对应字典,这样写,编码方式是urlencoded
requests.post(url='xxxxxxxx',data={'xxx':'yyy'})
# json对应字典,这样写,编码方式是json格式
requests.post(url='xxxxxxxx',json={'xxx':'yyy'})
# 终极方案,编码就是json格式
requests.post(url='',
data={'':1,},
headers={
'content-type':'application/json'
})
响应Response对象
# Response相应对象的属性和方法
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
respone=requests.get('http://www.jianshu.com',headers=headers)
# respone属性
print(respone.text) # 响应体转字符串
print(respone.content) # 响应体的二进制内容
print(respone.status_code) # 响应状态码
print(respone.headers) # 响应头
print(respone.cookies) # cookie是在响应头,cookie很重要,它单独做成了一个属性
print(respone.cookies.get_dict()) # cookieJar对象---》转字典
print(respone.cookies.items()) # 一次性取出cooike的键值对
print(respone.url) # 请求地址
print(respone.history) #
print(respone.encoding) # 响应编码格式
编码问题
# 有的网站,打印
res.text --->发现乱码---》请求回来的二进制---》转成了字符串---》默认用utf8转---》
response.encoding='gbk'
再打印res.text它就用gbk转码
下载图片,视频
import requests
# res=requests.get('http://pic.imeitou.com/uploads/allimg/230224/7-230224151210-50.jpg')
# # print(res.content)
# with open('美女.jpg','wb') as f:
# f.write(res.content)
#
res=requests.get('https://vd3.bdstatic.com/mda-pcdcan8afhy74yuq/sc/cae_h264/1678783682675497768/mda-pcdcan8afhy74yuq.mp4')
with open('致命诱惑.mp4','wb') as f:
for line in res.iter_content():
f.write(line)
requests高级用法
解析json
# 发送http请求,返回的数据会有xml格式,也有json格式
import requests
data = {
'cname': '',
'pid': '',
'keyword': '500',
'pageIndex': 1,
'pageSize': 10,
}
res = requests.post('http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword',data=data)
# print(res.text) # json 格式字符串---》json.cn
print(type(res.json())) # 转成对象 字典对象
ssl认证
http协议:明文传输
https:http+ssl/tls
HTTP+SSL/TLS 也就是在http上又加了一层处理加密信息的模块,比http安全,可防止组织在传输过程中被窃取,改变,确保数据的完整性
https://zhuanlan.zhihu.com/p/561907474
以后遇到整数提示错误问题,ssl xxx
1.不验证证书
import requests
response = requests.get('https://www.12306.cn',verify=False)
# 参数:verify就是表示是否验证证书,不验证证书,报警警告,返回200
print(response.status_code)
2.关闭警告
import requests
from requests.packages import urllib3
urllib3.disable_warnings() # 关闭警告
response = requests.get('https://www.12306.cn',verify=False)
# 这里就不会有警告了
print(response.status_code)
3 手动携带证书(了解)
import requests
respone=requests.get('https://www.12306.cn',
cert=('/path/server.crt',
'/path/key'))
print(respone.status_code)
使用代理
如果爬虫使用自身ip地址访问,很有可能被封ip地址,以后就访问不了了
解决办法:我们可以使用代理ip
代理:收费和免费(不稳,延迟高)
# res = requests.post('https://www.cnblogs.com',proxies={'http':'地址+端口'})
# res = requests.post('https://www.cnblogs.com',proxies={'http':'27.79.236.66:4001'})
res = requests.post('https://www.cnblogs.com',proxies={'http':'60.167.91.34:33080'})
print(res.status_code)
# 高匿代理和透明代理
-高匿:服务端拿不到真实客户端的ip地址
-透明:服务端能拿到真实客户端的ip地址
-后端如何拿到真实客户端ip地址
-http请求中有个:X-Forwarded-For: client1, proxy1, proxy2, proxy3
-x-forword-for
-获得HTTP请求端真实的IP
超时设置
import requests
respone=requests.get('https://www.baidu.com',timeout=0.0001)
异常处理
import requests
from requests.exceptions import * #可以查看requests.exceptions获取异常类型
try:
r=requests.get('http://www.baidu.com',timeout=0.00001)
except ReadTimeout:
print('===:')
# except ConnectionError: #网络不通
# print('-----')
# except Timeout:
# print('aaaaa')
except RequestException:
print('Error')
上传文件
import requests
files = {'file': open('美女.png', 'rb')}
respone = requests.post('http://httpbin.org/post', files=files)
print(respone.status_code)
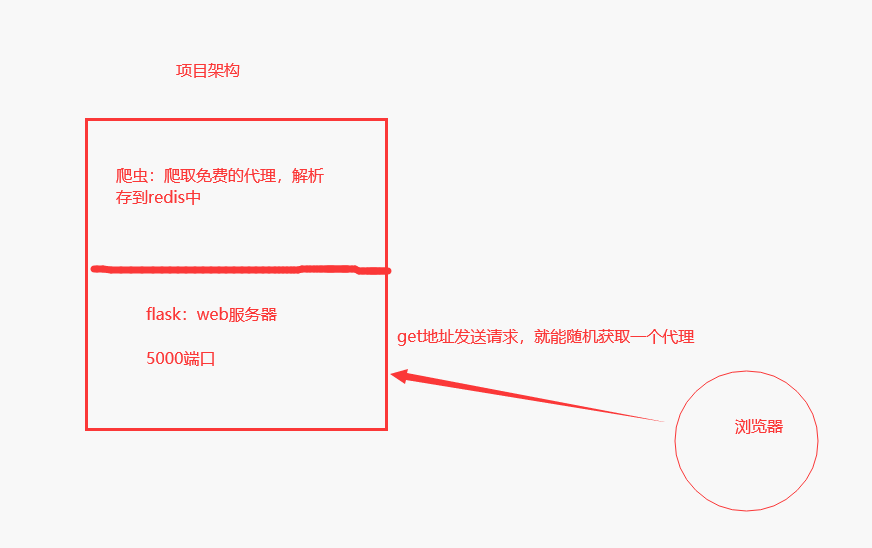
代理池搭建
requests发送请求使用代理
代理从哪来:
-公司花钱买
-搭建免费的代理池:https://github.com/jhao104/proxy_pool
-python:爬虫+flask写的
-架构:看下图
# 搭建步骤:
1 git clone https://github.com/jhao104/proxy_pool.git
2 使用pycharm打开
3 安装依赖:pip install -r requirements.txt
4 修改配置文件(redis地址即可)
HOST = "0.0.0.0"
PORT = 5010
DB_CONN = 'redis://127.0.0.1:6379/0'
PROXY_FETCHER #爬取哪些免费代理网站
5 启动爬虫程序
python proxyPool.py schedule
6 启动服务端
python proxyPool.py server
7 使用随机一个免费代理
地址栏中输入:http://127.0.0.1:5010/get/
# 使用随机代理发送请求
import requests
from requests.packages import urllib3
urllib3.disable_warnings() # 关闭警告
# 读取代理
res = requests.get('http://127.0.0.1:5010/get/').json()
# print(res)
# {'anonymous': '', 'check_count': 2, 'fail_count': 0, 'https': False, 'last_status': True,
# 'last_time': '2023-03-16 16:21:50',
# 'proxy': '121.33.160.52:1080', 'region': '中国 广东 广州 电信', 'source': 'freeProxy09'}
proxies = {}
if res['https']: # 判断代理是是https,还是http
proxies['https'] = res['proxy'] # 将代理池的代理放到我们的字典中
else:
proxies['http'] = res['proxy']
print(proxies) # 随机获取代理地址{'http': '58.17.78.91:8085'}
res = requests.post('https://www.cnblogs.com', proxies=proxies, verify=False)
print(res) # <Response [200]> 响应成功
django后端获取客户端的ip地址
# 建立django后端---》index地址---》访问就返回访问者的ip
# django代码---》不要忘记改配置文件
# 路由
path('', index),
# 视图函数
def index(request):
ip = request.META.get('REMOTE_ADDR')
print('ip地址是', ip)
return HttpResponse(ip)
# 测试端:
# import requests
# from requests.packages import urllib3
# urllib3.disable_warnings() #关闭警告
# # 获取代理
# res = requests.get('http://127.0.0.1:5010/get/').json()
# proxies = {}
# if res['https']:
# proxies['https'] = res['proxy']
# else:
# proxies['http'] = res['proxy']
#
# print(proxies)
# res=requests.get('http://101.43.19.239/', proxies=proxies,verify=False)
# print(res.text)
from threading import Thread
import requests
def task():
res = requests.get('http://101.43.19.239/')
print(res.text)
for i in range(10000000):
t = Thread(target=task)
t.start()
爬取某视频网站
import requests
import re
res = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0')
# print(res.text) # 拿到整体网页
video_list = re.findall('<a href="(.*?)" class="vervideo-lilink actplay">', res.text)
# print(video_list) # ['video_1346772', 'video_1433296', 'video_1420573', 'video_1397663']
for i in video_list:
# print(i) # video_1346772
video_id = i.split('_')[1]
# print(video_id) # 1346772
real_url = 'https://www.pearvideo.com/' + i
headers = {
'Referer': 'https://www.pearvideo.com/video_%s' % video_id
}
res1 = requests.get('https://www.pearvideo.com/videoStatus.jsp?contId=%s&mrd=0.29636538326105044' % video_id,
headers=headers).json()
# print(res1["videoInfo"]['videos']['srcUrl'])
mp4_url = res1["videoInfo"]['videos']['srcUrl']
mp4_url = mp4_url.replace(mp4_url.split('/')[-1].split('-')[0], 'cont-%s' % video_id)
print(mp4_url)
res2 = requests.get(mp4_url)
with open('./video/%s.mp4' % video_id, 'wb') as f:
for line in res2.iter_content():
f.write(line)
# headers={
# 'Referer': 'https://www.pearvideo.com/video_1212452'
# }
# res=requests.get('https://www.pearvideo.com/videoStatus.jsp?contId=1212452&mrd=0.29636538326105044',headers=headers)
#
# print(res.text)
# https://video.pearvideo.com/mp4/short/20171204/ 1678938313577 -11212458-hd.mp4
# https://video.pearvideo.com/mp4/short/20171204/ cont-1212452 -11212458-hd.mp4
mp4_url = 'https://video.pearvideo.com/mp4/short/20171204/ 1678938313577-11212458-hd.mp4'
爬取新闻
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.autohome.com.cn/all/1/#liststart')
# print(res.text)
# 第一个参数是要解析的文本str
# 第二个参数是:解析的解析器,html,parser:内置解析器
soup = BeautifulSoup(res.text, 'html.parser')
# 查找所有类型叫article的ul标签,find_all
ul_list = soup.find_all(name='ul', class_='article')
print(ul_list)
for ul in ul_list:
li_list = ul.find_all(name='li')
print(len(li_list))
for li in li_list:
h3 = li.find(name='h3')
# print(h3)
if h3:
title = h3.text
url = 'https' + li.find('a').attrs['href']
desc = li.find('p').text
img = li.find(name='img').attrs['src']
print('''
新闻标题:%s
新闻连接:%s
新闻摘要:%s
新闻图片:%s
''' % (title, url, desc, img))
bs4介绍,遍历文档树
beautifulsoup4从HTML或XML文件中提取数据的Python库
用它来解析爬取回来的xml
安装:pip install beautifulsoup4
pip install lxml # 这是下载解析库
soup=BeautifulSoup('要解析的内容str类型','html.parser/lxml'
bs4的遍历文档树
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title">
lqz
<b>The Dormouse's story</b>
</p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1" name='lqz'>Elsie</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
# 1.美化,不是标准xml,完成美化
# print(soup.prettify())
# 2.遍历文档树---》通过.来遍历
# print(soup.html.body.p) # html中body中第一个p标签,一层一层找,只会找一个
# print(soup.p) # 跨层找,也是只找第一个
# 3.获取标签的属性---》属性字典
# print(soup.a.attrs) # 获取a标签下的所有属性
# {'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1', 'name': 'lqz'}
# 拿到属性就可以索引或者get取值
# print(soup.a.attrs['href']) # 拿到属性href对应的链接
# 4.获取标签的内容
# text 获得该标签内部子子孙孙所有标签的文本内容
# print(soup.p.text) # 拿到第一个p标签文本内容包含他的子标签b标签的文本内容
# # string p下的文本只有一个时,取到,否则为None
# print(soup.p.string)
# # strings
# print(list(soup.p.strings)) # generator
# 5.嵌套选择
# print(soup.html.body)
# ---- 了解
#6、子节点、子孙节点
# print(soup.body.contents) #p下所有子节点,只取一层
# print(list(soup.p.children)) #list_iterator得到一个迭代器,包含p下所有子节点 只取一层
# print(list(soup.body.descendants) ) # generator 子子孙孙
#7、父节点、祖先节点
# print(soup.a.parent) #获取a标签的父节点 直接父亲
# print(list(soup.a.parents) )#找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲...
#8、兄弟节点
# print(soup.a.next_sibling) #下一个兄弟
# print(soup.a.previous_sibling) #上一个兄弟
#
# print(list(soup.a.next_siblings)) #下面的兄弟们=>生成器对象
print(list(soup.a.previous_siblings)) #上面的兄弟们=>生成器对象
bs4搜索文档树
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p id="my p" class="title"><b id="bbb" class="boldest">The Dormouse's story</b>
</p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
# 五种过滤器:字符串、正则表达式、列表、True、方法,这些都指的是查询条件
# 1.字符串
# res = soup.find_all(name='p') # 查询所有的p标签
# print(res)
# 类名交sister的所有标签
# res = soup.find_all(class_='sister')
# print(res)
# id叫link1的标签
# res = soup.find_all(id='link1')
# print(res)
# 文本内容叫Elsie的父标签
# res = soup.find(text='Elsie').parent
# print(res)
# 另一种方式
# res = soup.find_all(attrs={'class':'sister'})
# res = soup.find_all(attrs={'id':'link1'})
# 2.正则表达式
# import re
# # res=soup.find_all(id=re.compile('^l'))
# res=soup.find_all(class_=re.compile('^s'))
# print(res)
# 3.列表
# 查询id为link1的标签和id为link2的标签
# res = soup.find_all(id=['link1','link2'])
# print(res)
# print(soup.find_all(name=['a','b']))
# print(soup.find_all(['a','b']))
# 4 True
# res=soup.find_all(id=True) # 所有有id的标签
# res=soup.find_all(href=True)
# res=soup.find_all(class_=True)
# print(res)
# 5 方法
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
print(soup.find_all(name=has_class_but_no_id))
find的其他参数
find的参数有:
name
class_
id
text
attrs
-----
limit:限制条数,find_all用的,find的本质是find_all,limit=1
recursive:查找的时候,是只找第一层还是子子孙孙都找,默认是True,子子孙孙都找
# limit 参数
# res=soup.find_all(href=True,limit=2)
# print(res)
# recursive 查找的时候,是只找第一层还是子子孙孙都找
# res=soup.find_all(name='b',recursive=False)
# res=soup.find_all(name='b')
# 建议遍历和搜索一起用
res=soup.html.body.p.find_all(name='b',recursive=False)
print(res)
CSS选择器
之前学过的css选择器,可以很复杂
.类名
# id
p
学了bs4,以后可能见到别的解析器(lxml)----》他们都会支持css选择器,也会支持xpath
# bs4 支持css选择器
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title">
<b>The Dormouse's story</b>
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
<div class='panel-1'>
<ul class='list' id='list-1'>
<li class='element'>Foo</li>
<li class='element'>Bar</li>
<li class='element'>Jay</li>
</ul>
<ul class='list list-small' id='list-2'>
<li class='element'><h1 class='yyyy'>Foo</h1></li>
<li class='element xxx'>Bar</li>
<li class='element'>Jay</li>
</ul>
</div>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
# select内写css选择器
# 查到类名是sister的标签
# print(soup.select('.sister'))
# 查找id是link1的标签
# print(soup.select('#link1'))
# 查找id是link1里面的span标签
# print(soup.select('#link1 span'))
# 终极大招---》如果不会写css选择器,可以复制
import requests
res=requests.get('https://www.w3school.com.cn/css/css_selector_attribute.asp')
soup=BeautifulSoup(res.text,'lxml')
# print(soup.select('#intro > p:nth-child(1) > strong'))
print(soup.select('#intro > p:nth-child(1) > strong')[0].text)
selenium基本使用
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
使用步骤:
1.下载selenium
2.操作浏览器,分不同浏览器,需要下载不同浏览器的驱动
-用谷歌---》谷歌浏览器驱动:https://registry.npmmirror.com/binary.html?path=chromedriver/
-跟谷歌浏览器版本要对应 111.0.5563.65:
3 下载完的驱动,放在项目路径下
4 写代码,控制谷歌浏览器
from selenium import webdriver
import time
bro = webdriver.Chrome(executable_path='chromedriver.exe') # 打开一个谷歌浏览器
bro.get('https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3') # 在地址栏中输入地址
print(bro.page_source) # 当前页面的内容 (html格式)
with open('1.html','w',encoding='utf-8') as f:
f.write(bro.page_source)
time.sleep(5)
bro.close() # 关闭浏览器
无界面浏览器
from selenium import webdriver
import time
from selenium.webdriver.chrome.options import Options
# 隐藏浏览器的图形化界面,但是数据还拿到
chrome_options = Options()
chrome_options.add_argument('window-size=1920x3000') #指定浏览器分辨率
chrome_options.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 提升速度
chrome_options.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
# chrome_options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" #手动指定使用的浏览器位置
bro = webdriver.Chrome(executable_path='chromedriver.exe',chrome_options=chrome_options)
# 打开一个谷歌浏览器,隐藏浏览器的图形化界面,但是数据拿到了
bro.get('https://www.cnblogs.com/')
print(bro.page_source)
time.sleep(5)
bro.close() # 关闭浏览器
模拟登录百度
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
bro = webdriver.Chrome(executable_path='chromedriver.exe') # 打开一个谷歌浏览器
bro.get('https://www.baidu.com')
# 加入等待:找标签,如果找不到,就等待 x秒,如果还找不到就报错
bro.implicitly_wait(10) # 1 等待
# 从页面中找到登录 a标签,点击它
# By.LINK_TEXT 按a标签文本内容找
btn = bro.find_element(by=By.LINK_TEXT, value='登录')
# 点击它
btn.click()
# 找到按账号登录的点击按钮,有id,优先用id,因为唯一 TANGRAM__PSP_11__changePwdCodeItem
btn_2 = bro.find_element(by=By.ID, value='TANGRAM__PSP_11__changeSmsCodeItem')
btn_2.click()
time.sleep(1)
btn_2 = bro.find_element(by=By.ID, value='TANGRAM__PSP_11__changePwdCodeItem')
btn_2.click()
time.sleep(1)
name = bro.find_element(by=By.ID, value='TANGRAM__PSP_11__userName')
password = bro.find_element(by=By.ID, value='TANGRAM__PSP_11__password')
name.send_keys('306334678@qq.com')
password.send_keys('1234')
time.sleep(1)
submit=bro.find_element(by=By.ID,value='TANGRAM__PSP_11__submit')
submit.click()
time.sleep(2)
bro.close() # 关闭浏览器
selenium其它用法
查找标签
# 两个方法
bro.find_element 找一个
bro.find_elements 找所有
# 可以按id,标签名,name属性名,类名,a标签的文字,a标签的文字模糊匹配,css选择器,xpath【后面聊】
# input_1=bro.find_element(by=By.ID,value='wd') # 按id找
# input_1 = bro.find_element(by=By.NAME, value='wd') # name属性名
# input_1=bro.find_element(by=By.TAG_NAME,value='input') # 可以按标签名字找
# input_1=bro.find_element(by=By.CLASS_NAME,value='s_ipt') # 可以按类名
# input_1=bro.find_element(by=By.LINK_TEXT,value='登录') # 可以按a标签内容找
# input_1=bro.find_element(by=By.PARTIAL_LINK_TEXT,value='录') # 可以按a标签内容找
# input_1 = bro.find_element(by=By.CSS_SELECTOR, value='#su') # 可以按css选择器
获取位置属性大小,文本
print(tag.get_attribute('src')) # 用的最多
tag.text # 文本内容
#获取标签ID,位置,名称,大小(了解)
print(tag.id)
print(tag.location)
print(tag.tag_name)
print(tag.size)
等待元素被加载
# 代码执行很快,有的标签没来的及加载,直接查找就会报错,设置等待
# 隐士等待:所有标签,只要去找,找不到就遵循 等10s的规则
bro.implicitly_wait(10)
# 显示等待:需要给每个标签绑定一个等待,麻烦
元素操作
# 点击
tag.click()
# 输入内容
tag.send_keys()
# 清空内容
tag.clear()
# 浏览器对象 最大化
bro.maximize_window()
#浏览器对象 截全屏
bro.save_screenshot('main.png')
执行js代码
bro.execute_script('alert("美女")') # 引号内部的相当于 用script标签包裹了
# 可以干的事
-获取当前访问的地址 window.location
-打开新的标签
-滑动屏幕--》bro.execute_script('scrollTo(0,document.documentElement.scrollHeight)')
-获取cookie,获取定义的全局变量
切换选项卡
import time
from selenium import webdriver
browser=webdriver.Chrome(executable_path='chromedriver.exe')
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles) #获取所有的选项卡
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(2)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://www.sina.com.cn')
browser.close()
浏览器前进后退
import time
from selenium import webdriver
browser=webdriver.Chrome(executable_path='chromedriver.exe')
browser.get('https://www.baidu.com')
browser.get('https://www.taobao.com')
browser.get('http://www.sina.com.cn/')
browser.back()
time.sleep(2)
browser.forward()
browser.close()
异常处理
import time
from selenium import webdriver
browser=webdriver.Chrome(executable_path='chromedriver.exe')
try:
except Exception as e:
print(e)
finally:
browser.close()
0 selenium 登录cnblogs
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import json
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
try:
####1 获取cookie
# bro.get('https://www.cnblogs.com/')
# bro.implicitly_wait(10)
# login_btn = bro.find_element(by=By.LINK_TEXT, value='登录')
# login_btn.click()
# username = bro.find_element(By.ID, 'mat-input-0')
# password = bro.find_element(By.ID, 'mat-input-1')
# submit_btn = bro.find_element(By.CSS_SELECTOR,
# 'body > app-root > app-sign-in-layout > div > div > app-sign-in > app-content-container > div > div > div > form > div > button')
# username.send_keys('616564099@qq.com')
# # 手动输入密码,手动点击登录 搞好验证码,都成功,敲回车
# input()
#
# # 取出cookies
# cookie = bro.get_cookies()
# print(cookie)
# # 保存到本地文件
# with open('cnblogs.json', 'w', encoding='utf-8') as f:
# json.dump(cookie, f)
### 2 打开首页
bro.get('https://www.cnblogs.com/') # 没有登录状态
bro.implicitly_wait(10)
time.sleep(2)
# 打开本地的cookie的json文件
with open('cnblogs.json', 'r', encoding='utf-8') as f:
cookies = json.load(f)
for cookie in cookies:
bro.add_cookie(cookie)
bro.refresh() # 刷新
time.sleep(5)
except Exception as e:
print(e)
finally:
bro.close()
1 抽屉半自动点赞
# 1 使用selenium 半自动登录---》取到cookie
# 2 使用requests模块,解析出点赞的请求地址---》模拟发送请求---》携带cookie
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import json
import requests
# bro = webdriver.Chrome(executable_path='./chromedriver.exe')
try:
####1 先登录,获取cookie
# bro.get('https://dig.chouti.com/')
# bro.maximize_window()
# bro.implicitly_wait(10)
#
# login_btn = bro.find_element(By.LINK_TEXT, '登录')
# # login_btn.click() # 会报错,不能这么点击了
#
# # 使用js点击它,把传入的对象,点击一下
# bro.execute_script("arguments[0].click()", login_btn)
# time.sleep(3)
#
# username = bro.find_element(By.CSS_SELECTOR,
# 'body > div.login-dialog.dialog.animated2.scaleIn > div > div.login-body > div.form-item.login-item.clearfix.phone-item.mt24 > div.input-item.input-item-short.left.clearfix > input')
# password = bro.find_element(By.NAME, 'password')
#
# username.send_keys('18953675221')
# password.send_keys('lqz123')
# time.sleep(1)
# submit_btn = bro.find_element(By.CSS_SELECTOR,
# 'body > div.login-dialog.dialog.animated2.scaleIn > div > div.login-footer > div:nth-child(4) > button')
# submit_btn.click()
#
# input('') # 万一有验证码,手动操作一下
# with open('chouti.json', 'w', encoding='utf-8') as f:
# json.dump(bro.get_cookies(), f)
### 使用request模拟点赞,携带cookie
# 先把cookie打开
with open('chouti.json', 'r', encoding='utf-8') as f:
cookies = json.load(f)
# selenium 的cookie不能直接给requests模块使用,需要额外处理一下
request_cookies = {}
for cookie in cookies:
request_cookies[cookie['name']] = cookie['value']
print(request_cookies)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
res = requests.get('https://dig.chouti.com/top/24hr?_=1679277434856', headers=headers)
for item in res.json().get('data'):
id_link = item.get('id')
data = {
'linkId': id_link
}
res2 = requests.post('https://dig.chouti.com/link/vote', headers=headers, data=data, cookies=request_cookies)
print(res2.text)
except Exception as e:
print(e)
finally:
# bro.close()
pass
2 xpath的使用
# 每个解析器,都会有自己的查找方法
-bs4 find 和find_all
-selenium find_element和 find_elements
-lxml 也是个解析器,支持xpath和css
# 这些解析器,基本上都会支持两种统一的 css和xpath
-css咱们会了
-xpath需要学习
# xpath是什么?
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言
# 有终极大招,只需要记住几个用法就可以了
- / 从当前路径下开始找
- /div 从当前路径下开始找div
-// 递归查找,子子孙孙
-//div 递归查找div
-@ 取属性
- . 当成
- .. 上一层
3 selenium 动作链
# 人可以滑动某些标签
# 网站中有些按住鼠标,滑动的效果
-滑动验证码
# 两种形式
-形式一:
actions=ActionChains(bro) #拿到动作链对象
actions.drag_and_drop(sourse,target) #把动作放到动作链中,准备串行执行
actions.perform()
-方式二:
ActionChains(bro).click_and_hold(sourse).perform()
distance=target.location['x']-sourse.location['x']
track=0
while track < distance:
ActionChains(bro).move_by_offset(xoffset=2,yoffset=0).perform()
track+=2
3.1 动作链案例
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
try:
browser = webdriver.Chrome(executable_path='./chromedriver.exe')
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframeResult') # 切换到id为iframeResult的frame
target = browser.find_element(By.ID, 'droppable') # 目标
source = browser.find_element(By.ID, 'draggable') # 源
# 方案1
# actions = ActionChains(browser) # 拿到动作链对象
# actions.drag_and_drop(source, target) # 把动作放到动作链中,准备串行执行
# actions.perform()
# 方案2
# ActionChains(browser).click_and_hold(source).perform()
# distance = target.location['x'] - source.location['x']
# track = 0
# while track < distance:
# ActionChains(browser).move_by_offset(xoffset=2, yoffset=0).perform()
# track += 2
time.sleep(2)
finally:
browser.close()
4 自动登录12306
# selenium自动登录12306
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
from selenium.webdriver.chrome.options import Options
try:
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled") # 去掉自动化控制
browser = webdriver.Chrome(executable_path='./chromedriver.exe', chrome_options=options)
browser.get('https://kyfw.12306.cn/otn/resources/login.html')
browser.maximize_window()
username = browser.find_element(By.ID, 'J-userName')
password = browser.find_element(By.ID, 'J-password')
username.send_keys('')
password.send_keys('')
login_btn = browser.find_element(By.ID, 'J-login')
time.sleep(2)
login_btn.click()
time.sleep(5)
span = browser.find_element(By.ID, 'nc_1_n1z')
ActionChains(browser).click_and_hold(span).perform()
ActionChains(browser).move_by_offset(xoffset=300, yoffset=0).perform()
# 滑动完成了,但是进不去,原因是它检测到我们使用了selenium,屏蔽掉
time.sleep(3)
finally:
browser.close()
5 打码平台使用
# 登录网站,会有些验证码,可以借助于第三方的打码平台,破解验证码,只需要花钱解决
# 免费的:纯数字,纯字母的----》python有免费模块破解,失败率不高
# 云打码,超级鹰(以它为例)
# 云打码:https://zhuce.jfbym.com/price/
# 价格体系:破解什么验证码,需要多少钱
http://www.chaojiying.com/price.html
6 使用打码平台自动登录
# 使用selenium打开页面---》截取整个屏幕----》使用pillow---》根据验证码图片位置,截取出验证码图片---》使用第三方打码平台破解---》写入到验证码框中,点击登录
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from chaojiying import ChaojiyingClient
from PIL import Image
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
bro.get('http://www.chaojiying.com/apiuser/login/')
bro.implicitly_wait(10)
bro.maximize_window()
try:
username = bro.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input')
password = bro.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input')
code = bro.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input')
btn = bro.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input')
username.send_keys('306334678')
password.send_keys('lqz123')
# 获取验证码:
#1 整个页面截图
bro.save_screenshot('main.png')
# 2 使用pillow,从整个页面中截取出验证码图片 code.png
img = bro.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/div/img')
location = img.location
size = img.size
print(location)
print(size)
# 使用pillow扣除大图中的验证码
img_tu = (int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height']))
# # 抠出验证码
# #打开
img = Image.open('./main.png')
# 抠图
fram = img.crop(img_tu)
# 截出来的小图
fram.save('code.png')
# 3 使用超级鹰破解
chaojiying = ChaojiyingClient('306334678', 'lqz123', '937234') # 用户中心>>软件ID 生成一个替换 96001
im = open('code.png', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 1902)) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
res_code=chaojiying.PostPic(im, 1902)['pic_str']
code.send_keys(res_code)
time.sleep(5)
btn.click()
time.sleep(10)
except Exception as e:
print(e)
finally:
bro.close()
7 使用selenium爬取京东商品信息
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys # 键盘按键操作
def get_goods(bro):
# 找到所有类名叫gl-item 的li标签
li_list = bro.find_elements(By.CLASS_NAME, 'gl-item')
for li in li_list:
try:
img_url = li.find_element(By.CSS_SELECTOR, '.p-img img').get_attribute('src')
if not img_url:
img_url = 'https:' + li.find_element(By.CSS_SELECTOR, '.p-img img').get_attribute('data-lazy-img')
price = li.find_element(By.CSS_SELECTOR, '.p-price i').text
name = li.find_element(By.CSS_SELECTOR, '.p-name a').text
url = 'https:' + li.find_element(By.CSS_SELECTOR, '.p-img a').get_attribute('href')
commit = li.find_element(By.CSS_SELECTOR, '.p-commit a').text
print('''
商品图片地址:%s
商品地址:%s
商品名字:%s
商品价格:%s
商品评论数:%s
''' % (img_url, url, name, price, commit))
except Exception as e:
print(e)
continue
# 查找下一页,点击,在执行get_goods
next = bro.find_element(By.PARTIAL_LINK_TEXT, '下一页')
time.sleep(1)
next.click()
get_goods(bro)
try:
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
bro.get('http://www.jd.com')
bro.implicitly_wait(10)
input_key = bro.find_element(By.ID, 'key')
input_key.send_keys('茅台')
input_key.send_keys(Keys.ENTER) # 敲回车
# 滑动屏幕到最底部
bro.execute_script('scrollTo(0,5000)')
get_goods(bro)
except Exception as e:
print('sasdfsadfasdfa',e)
finally:
bro.close()
8 scrapy介绍
# requsets bs4 selenium 模块
# 框架 :django ,scrapy--->专门做爬虫的框架,爬虫界的django,大而全,爬虫有的东西,它都自带
# 安装 (win看人品,linux,mac一点问题没有)
-pip3.8 install scrapy
-装不上,基本上是因为twisted装不了,单独装
1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
3、pip3 install lxml
4、pip3 install pyopenssl
5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy
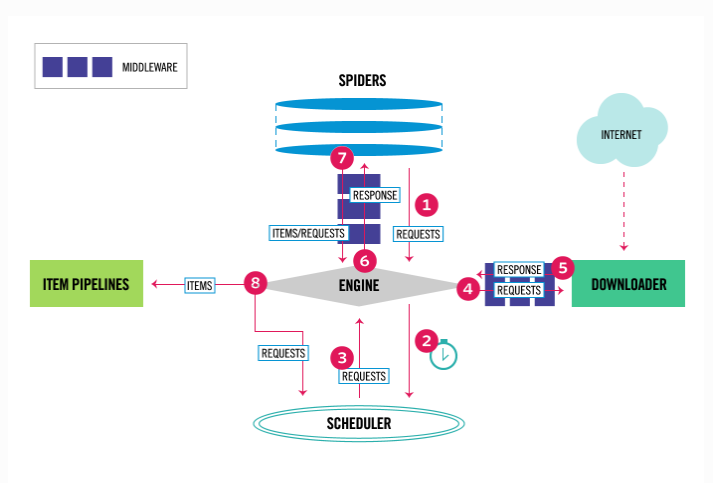
# 架构分析
-爬虫:spiders(自己定义的,可以有很多),定义爬取的地址,解析规则
-引擎:engine ---》控制整个框架数据的流动,大总管
-调度器:scheduler---》要爬取的 requests对象,放在里面,排队
-下载中间件:DownloaderMiddleware---》处理请求对象,处理响应对象
-下载器:Downloader ----》负责真正的下载,效率很高,基于twisted的高并发的模型之上
-爬虫中间件:spiderMiddleware----》处于engine和爬虫直接的(用的少)
-管道:piplines---》负责存储数据
# 创建出scrapy项目
scrapy startproject firstscrapy # 创建项目
scrapy genspider 名字 网址 # 创建爬虫 等同于 创建app
# pycharm打开
0 scrapy架构介绍

# 引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。
# 调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
# 下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
# 爬虫(SPIDERS)--->在这里写代码
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
# 项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
# 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,你可用该中间件做以下几件事:设置请求头,设置cookie,使用代理,集成selenium
# 爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
0.1 scrapy的一些命令
# 安装完成后,会有scrapy的可执行文件
# 创建项目
scrapy startproject 项目名字 # 跟创建django一样,pycharm能直接创建django
# 创建爬虫
scrapy genspider 名字 域名 # 创建爬虫 django的创建app
# pycharm打开scrapy的项目
# 运行爬虫
scrapy crawl 爬虫名字
# 想点击绿色箭头运行爬虫
新建一个run.py,写入,以后右键执行即可
from scrapy.cmdline import execute
execute(['scrapy','crawl','cnblogs','--nolog'])
# 补充:爬虫协议
http://www.cnblogs.com/robots.txt
0.2 scrapy项目目录结构
firstscrapy # 项目名
firstscrapy # 文件夹名字,核心代码,都在这里面
spiders # 爬虫的文件,里面有所有的爬虫
__init__.py
baidu.py # 百度爬虫
cnblogs.py #cnblogs爬虫
items.py # 有很多模型类---》以后存储的数据,都做成模型类的对象,等同于django的models.py
middlewares.py # 中间件:爬虫中间件,下载中间件都写在这里面
pipelines.py #项目管道---》以后写持久化,都在这里面写
run.py # 自己写的,运行爬虫
settings.py # 配置文件 django的配置文件
scrapy.cfg # 项目上线用的,不需要关注
1 scrapy解析数据
1 response对象有css方法和xpath方法
-css中写css选择器
-xpath中写xpath选择
2 重点1:
-xpath取文本内容
'.//a[contains(@class,"link-title")]/text()'
-xpath取属性
'.//a[contains(@class,"link-title")]/@href'
-css取文本
'a.link-title::text'
-css取属性
'img.image-scale::attr(src)'
3 重点2:
.extract_first() 取一个
.extract() 取所有
解析cnblosg
# def parse(self, response):
# # 解析数据 css解析
# article_list = response.css('article.post-item')
# for article in article_list:
# title = article.css('div.post-item-text>a::text').extract_first()
# author_img = article.css('div.post-item-text img::attr(src)').extract_first()
# author_name = article.css('footer span::text').extract_first()
# desc_old = article.css('p.post-item-summary::text').extract()
# desc = desc_old[0].replace('\n', '').replace(' ', '')
# if not desc:
# desc = desc_old[1].replace('\n', '').replace(' ', '')
# url=article.css('div.post-item-text>a::attr(href)').extract_first()
# # 文章真正的内容,没拿到,它不在这个页面中,它在下一个页面中
# print(title)
# print(author_img)
# print(author_name)
# print(desc)
# print(url)
def parse(self, response):
# 解析数据 css解析
article_list = response.xpath('//*[@id="post_list"]/article')
# article_list = response.xpath('//article[contains(@class,"post-item")]')
for article in article_list:
title = article.xpath('.//div/a/text()').extract_first()
author_img = article.xpath('.//div//img/@src').extract_first()
author_name = article.xpath('.//footer//span/text()').extract_first()
desc_old = article.xpath('.//p/text()').extract()
desc = desc_old[0].replace('\n', '').replace(' ', '')
if not desc:
desc = desc_old[1].replace('\n', '').replace(' ', '')
url = article.xpath('.//div/a/@href').extract_first()
# 文章真正的内容,没拿到,它不在这个页面中,它在下一个页面中
print(title)
print(author_img)
print(author_name)
print(desc)
print(url)
2 settings相关配置,提高爬取效率
# scrapy 项目有项目自己的配置文件,还有内置的
2.1 基础的一些
#1 了解
BOT_NAME = "firstscrapy" #项目名字,整个爬虫名字
#2 爬虫存放位置 了解
SPIDER_MODULES = ["firstscrapy.spiders"]
NEWSPIDER_MODULE = "firstscrapy.spiders"
#3 记住 是否遵循爬虫协议,一般都设为False
ROBOTSTXT_OBEY = False
# 4 记住
USER_AGENT = "firstscrapy (+http://www.yourdomain.com)"
#5 记住 日志级别
LOG_LEVEL='ERROR'
#6 记住 DEFAULT_REQUEST_HEADERS 默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
#7 记住 后面学 SPIDER_MIDDLEWARES 爬虫中间件
SPIDER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsSpiderMiddleware': 543,
}
#8 后面学 DOWNLOADER_MIDDLEWARES 下载中间件
DOWNLOADER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsDownloaderMiddleware': 543,
}
#9 后面学 ITEM_PIPELINES 持久化配置
ITEM_PIPELINES = {
'cnblogs.pipelines.CnblogsPipeline': 300,
}
2.2 增加爬虫的爬取效率
#1 增加并发:默认16
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改
CONCURRENT_REQUESTS = 100
值为100,并发设置成了为100。
#2 降低日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:
LOG_LEVEL = 'INFO'
# 3 禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:
COOKIES_ENABLED = False
# 4 禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:
RETRY_ENABLED = False
# 5 减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:
DOWNLOAD_TIMEOUT = 10 超时时间为10s
3 持久化方案
# 方式一:(parse必须有return值,必须是列表套字典形式--->使用命令,可以保存到json格式中,csv中。。。)
scrapy crawl cnblogs -o cnbogs.json
# 方式二:我们用的,使用pipline存储---》可以存到多个位置
-第一步:在item.py中写一个类
class FirstscrapyItem(scrapy.Item):
title = scrapy.Field()
author_img = scrapy.Field()
author_name = scrapy.Field()
desc = scrapy.Field()
url = scrapy.Field()
# 博客文章内容,但是暂时没有
content = scrapy.Field()
-第二步:在pipline.py中写代码,写一个类:open_spide,close_spider,process_item
-open_spide:开启爬虫会触发
-close_spider:爬完会触发
-process_ite:每次要保存一个对象会触发
class FirstscrapyFilePipeline:
def open_spider(self, spider):
print('我开了')
self.f=open('a.txt','w',encoding='utf-8')
def close_spider(self, spider):
print('我关了')
self.f.close()
# 这个很重要
def process_item(self, item, spider):
self.f.write(item['title']+'\n')
return item
-第三步:配置文件配置
ITEM_PIPELINES = {
"firstscrapy.pipelines.FirstscrapyFilePipeline": 300, # 数字越小,优先级越高
}
-第四步:在解析方法parse中yield item对象
4 全站爬取cnblogs文章
4.1 request和response对象传递参数
# Request创建:在parse中,for循环中,创建Request对象时,传入meta
yield Request(url=url, callback=self.detail_parse,meta={'item':item})
# Response对象:detail_parse中,通过response取出meta取出item,把文章详情写入
yield item
4.2 解析下一页并继续爬取
import scrapy
from bs4 import BeautifulSoup
from firstscrapy.items import FirstscrapyItem
from scrapy.http.request import Request
class CnblogsSpider(scrapy.Spider):
name = "cnblogs"
allowed_domains = ["www.cnblogs.com"]
start_urls = ["http://www.cnblogs.com/"]
# 解析出下一页地址,继续爬取
def parse(self, response):
article_list = response.xpath('//*[@id="post_list"]/article')
# article_list = response.xpath('//article[contains(@class,"post-item")]')
# l=[]
for article in article_list:
item = FirstscrapyItem()
title = article.xpath('.//div/a/text()').extract_first()
item['title'] = title
author_img = article.xpath('.//div//img/@src').extract_first()
item['author_img'] = author_img
author_name = article.xpath('.//footer//span/text()').extract_first()
item['author_name'] = author_name
desc_old = article.xpath('.//p/text()').extract()
desc = desc_old[0].replace('\n', '').replace(' ', '')
if not desc:
desc = desc_old[1].replace('\n', '').replace(' ', '')
item['desc'] = desc
url = article.xpath('.//div/a/@href').extract_first()
item['url'] = url
# print(title)
# yield item对象 不完整,缺文章的content,而文章的content在下一个页面中,而此处要yield一个Request对象
# yield item
yield Request(url=url,callback=self.parser_detail,meta={'item':item}) # 爬完后执行的解析方法
next='https://www.cnblogs.com'+response.css('div.pager>a:last-child::attr(href)').extract_first()
print(next) # 继续爬取
yield Request(url=next,callback=self.parse)
# 解析详情的方法
def parser_detail(self,response):
# print(response.status)
# 解析出文章内容
content=response.css('#cnblogs_post_body').extract_first()
# print(str(content))
# 如何放到item中
item=response.meta.get('item')
if content:
item['content']=content
else:
item['content'] = '没查到'
yield item
