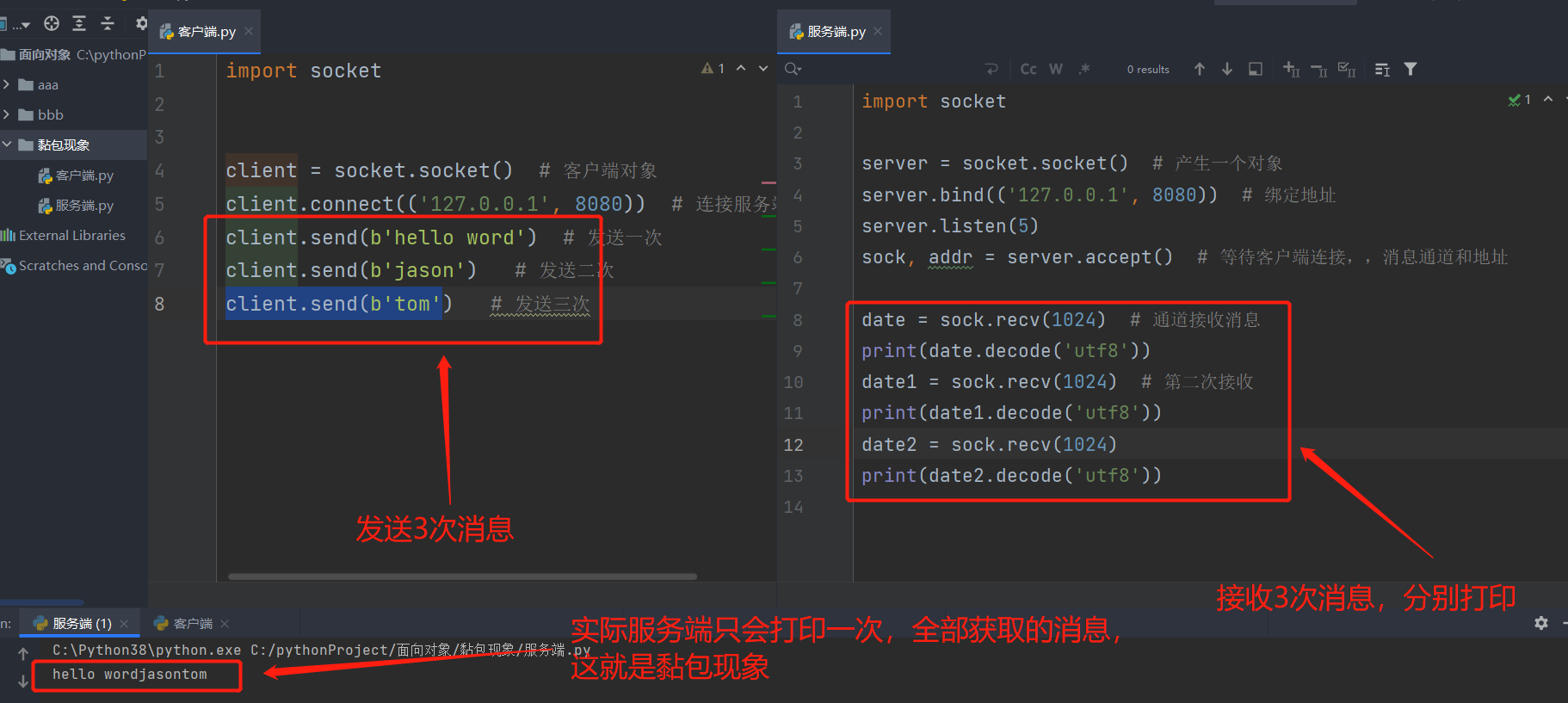
黏包现象及解决办法
黏包现象
1.服务端连续执行三次recv # 服务端收3次
2.客户端连续执行三次send # 客户端发3次
问题:服务端一次性接收到了客户端3次的消息,该现象称为'黏包现象'
黏包现象产生的原因:
1.不知道每次的数据到底多大
2.TCP也成为流式协议:数据像水流一样绵绵不绝没有间隔(TCP会针对数据量较小且发送间隔较短的多条数据一次性合并打包发送)
避免黏包现象的核心思路/关键点
如何明确即将接收的数据具体有多少
struct模块
import struct
info = b'hello bin baby'
print(len(info)) # 打印数据长度14
res = struct.pack('i', len(info)) # 调用struct包括在I模式下转换info的长度
print(len(res)) # 长度为4(bytes),报头
real_len = struct.unpack('i', res) # 根据固定长度的报头解析出真实数据的长度
print(real_len) # (14,)是元组的形式,所以要使用14,需要元组索引0
desc = b'hello my baby I will take you to play big ball'
print(len(desc)) # 真实长度46
res = struct.pack('i', len(desc))
print(len(res)) # 打宝之后长度为4
real_len = struct.unpack('i', res)
print(real_len) # (46,)
"""
解决黏包问题初次版本
客户端
1.将真实数据转换成bytes类型并计算长度
2.利用struct模块将真实长度制作一个固定长度的报头
3.将固定长度的报头先发送给服务端,服务端只需要在recv括号内填写固定长度的报头数字即可
4.然后再发送真实数据
服务端
1.服务端先接收固定长度的报头
2.利用struct模块反向解析出真实数据长度
3.recv接收真实数据长度即可
"""
"""问题1:structs模块无法打包数据量较大的数据,就算换更大的模式也不行"""
import struct
res = struct.pack('i',212341532134)
print(res) # 会直接报错
"""问题2:报头是否能传递更多的信息,比如电影大小,电影名称,电影评价,电影简介"""
"""终极解决方案:字典作为报头打包,效果更好,数字更小"""
data_dict = {
'file_name': 'xxx老师电影.avi',
'file_size': 123232313231233,
'file_info': '内容精彩,不容错过',
'file_desc': '私人珍藏'
}
import json
date_json = json.dumps(data_dict).encode('utf8') # 将字典转json字符串再转二进制
print(len(date_json)) # 真实长度190
res = struct.pack('i',len(date_json)) # 用struct模块打包字典数据长度
print(len(res)) # 打包后的长度4
"""
黏包问题终极解决方案:
客户端:
1.制作真实数据的信息字典(数据长度、数据简介、数据名称)
2.利用struct模块制作字典的报头
3.发送固定长度的报头(解析出来就是字典的长度)
4.发送字典数据
5.发送真实数据
服务端:
1.接收固定长度的字典报头
2.解析出字典的长度并接收
3.通过字典获取到真实数据的各项信息
4.接收真实数据长度
"""
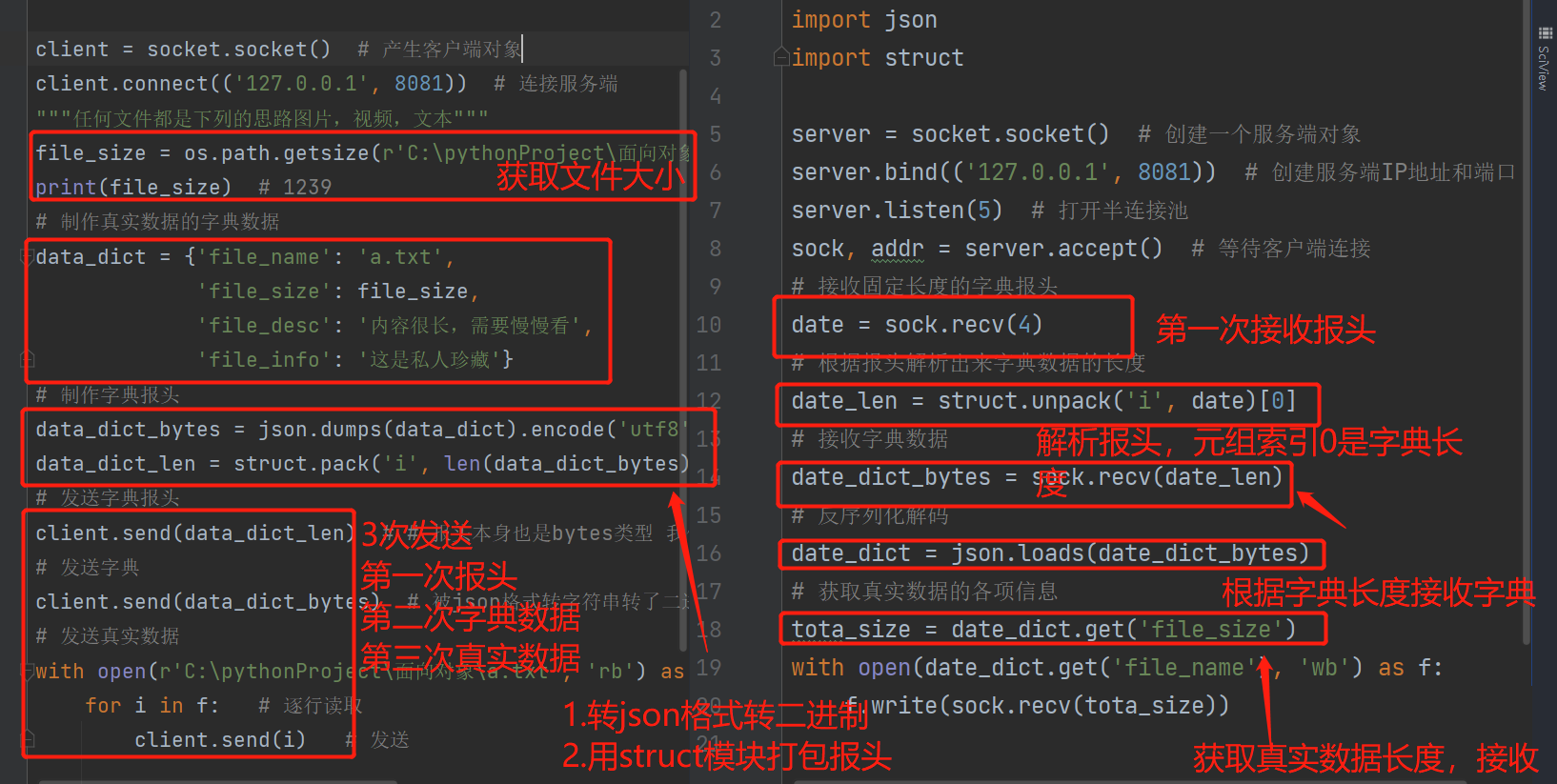
黏包代码实战
客户端:
import socket
import struct
import json
import os
client = socket.socket() # 产生客户端对象
client.connect(('127.0.0.1', 8081)) # 连接服务端
"""任何文件都是下列的思路图片,视频,文本"""
file_size = os.path.getsize(r'C:\pythonProject\面向对象\a.txt') # 用os模块判断文件的数据大小
print(file_size) # 1239
# 制作真实数据的字典数据
data_dict = {'file_name': 'a.txt',
'file_size': file_size,
'file_desc': '内容很长,需要慢慢看',
'file_info': '这是私人珍藏'}
# 制作字典报头
data_dict_bytes = json.dumps(data_dict).encode('utf8')
data_dict_len = struct.pack('i', len(data_dict_bytes))
# 发送字典报头
client.send(data_dict_len) # # 报头本身也是bytes类型 我们在看的时候用len长度是4
# 发送字典
client.send(data_dict_bytes) # 被json格式转字符串转了二进制以后的字典
# 发送真实数据
with open(r'C:\pythonProject\面向对象\a.txt', 'rb') as f: # 打开文件发送数据
for i in f: # 一行行发送 和直接一起发效果一样 因为TCP流式协议的特性
client.send(i) # 发送
服务端:
import socket
import json
import struct
server = socket.socket() # 创建一个服务端对象
server.bind(('127.0.0.1', 8081)) # 创建服务端IP地址和端口
server.listen(5) # 打开半连接池
sock, addr = server.accept() # 等待客户端连接
# 接收固定长度的字典报头
date = sock.recv(4)
# 根据报头解析出来字典数据的长度
date_len = struct.unpack('i', date)[0]
# 接收字典数据
date_dict_bytes = sock.recv(date_len)
# 反序列化解码
date_dict = json.loads(date_dict_bytes)
# 获取真实数据的各项信息
tota_size = date_dict.get('file_size')
with open(date_dict.get('file_name'), 'wb') as f:
f.write(sock.recv(tota_size))
'''接收真实数据的时候 如果数据量非常大 recv括号内直接填写该数据量 不太合适 我们可以每次接收一点点 反正知道总长度'''
# total_size = data_dict.get('file_size')
# recv_size = 0
# with open(data_dict.get('file_name'), 'wb') as f:
# while recv_size < total_size:
# data = sock.recv(1024)
# f.write(data)
# recv_size += len(data)
# print(recv_size)
UDP协议(了解)
1.UDP服务端和客户端'各自各玩各自的'
2.UDP不会出现多个消息发送合并


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律