

Kafka源码分析(三) - Server端 - 消息存储
系列文章目录
https://zhuanlan.zhihu.com/p/367683572
一. 业务模型
在上一篇文章中,我们分析了生产者的原理。下一步我们来分析下提交上来的消息在Server端时如何存储的。
1.1 概念梳理
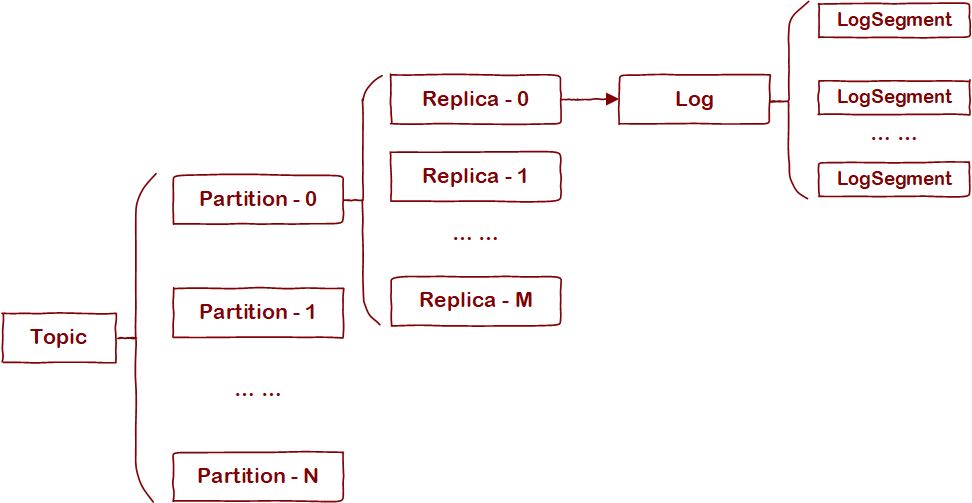
Kafka用Topic将数据划分成内聚性较强的子集,Topic内部又划分成多个Partition。不过这两个都是逻辑概念,真正存储文件的是Partition所对应的一个或多个Replica,即副本。在存储层有个概念和副本一一对应——Log。为了防止Log过大,增加消息过期和数据检索的成本,Log又会按一定大小划分成"段",即LogSegment。用一张图汇总这些概念间的关系:
1.2 文件分析
1.2.1 数据目录
Kafkap配置文件(server.properties)中有一个配置项——log.dir,其指定了kafka数据文件存放位置。为了研究数据目录的结构,我们先创建一个Topic(lao-zhang-tou-topic)
kafka-console-producer.sh --topic lao-zhang-tou-topic --bootstrap-server localhost:9092
然后向其中写几条消息
kafka-console-producer.sh --topic lao-zhang-tou-topic --bootstrap-server localhost:9092
{"message":"This is the first message"}
{"message":"This is the sencond message"}
接下来我们来看看log.dir指定目录下存放了那些文件

该目录下文件分3类:
-
数据文件夹
如截图中的lao-zhang-tou-topic-0
-
checkpoint文件
- cleaner-offset-checkpoint
- log-start-offset-checkpoint
- recovery-point-offset-checkpoint
- replication-offset-checkpoint
-
配置文件
meta.properties
第2、3类文件后续文章会详细分析,本文主要关注截图中lao-zhang-tou-topic-0目录。

实际上,该目录对应上文提到的Log概念,命名规则为 ${Topic}-${PartitionIndex}。该目录下,名称相同的.log文件、.index文件、.timeindex文件构成了一个LogSegment。例如图中的 00000000000000000000.log、00000000000000000000.index、00000000000000000000.timeindex 三个文件。其中.log是数据文件,用于存储消息数据;.index和.timeindex是在.log基础上建立起来的索引文件。
1.2.2 .log文件
log文件将消息数据依次排开进行存储

每个Message内部分为"数据头"(LOG_OVERHEAD)和"数据体"(Record)两部分
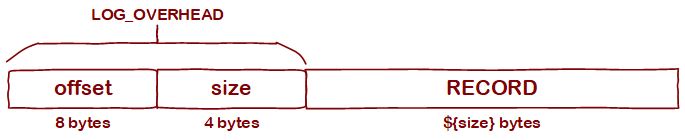
其中,LOG_OVERHEAD包含两个字段:
- offset:每条数据的逻辑偏移量,按插入顺序分别为0、1、2... ... N;每个消息的offset在Partition内部是唯一的;
- size:数据体(RECORD)部分的长度;
RECORD内部格式如下:

其中,
-
crc32:校验码,用于验证数据完整性;
-
magic:消息格式的版本号;v0=0,v1=1;本文讲v1格式;
-
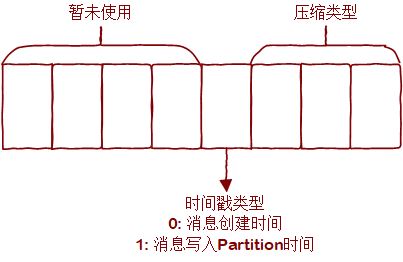
timestamp:时间戳,具体业务含义依attributes的值而定;
-
attributes:属性值;其 8bits 的含义如下
-
keyLength:key值的长度;
-
key:消息数据对应的key;
-
valueLength:value值的长度;
-
value:消息体,承载业务信息;
1.2.3 .index和.timeindex文件
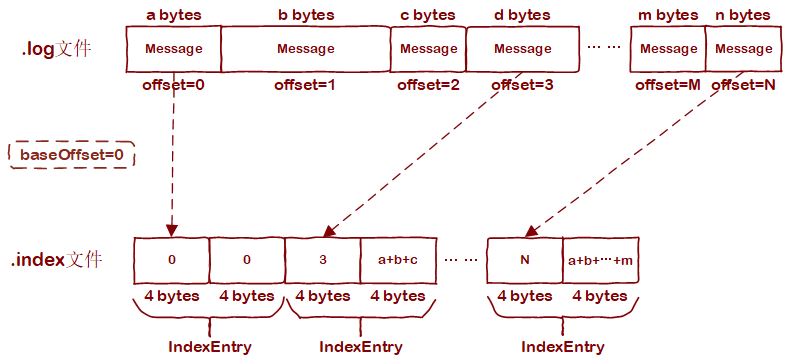
.index文件是依offset建立其的稀疏索引,可减少通过offset查找消息时的遍历数据量。.index文件的每个索引条目占8 bytes,有两个字段:relativeOffset 和 position(各占4 bytes)。也就是消息offset到其在文件中偏移量的一个映射。那有人要问了,索引项中保存的明明是一个叫relativeOffset的东西,为什么说是offset到偏移量的映射呢?其实,准确的来讲,relativeOffset指的的相对偏移量,是对LogSegment基准offset而言的。我们注意到,一个LogSegment内的.log文件、.index文件、和.index文件除后缀外的名称都是相同的。其实这个名称就是该LogSegment的基准offset,即LogSegment内保存的第一条消息对应的offset。baseOffset + relativeOffset即可得到offset,所以称索引项是offset到物理偏移量的映射。
不是所有的消息都对应.index文件内的一个条目。Kafka会每隔一定量的消息才会在.index建立索引条目,间隔大小由"log.index.interval.bytes"配置指定。.index文件布局示意图如下:
.timeindex文件和.index原理相同,只不过其IndexEntry的两个字段分别为timestamp(8 bytes)和relativeOffset(4 bytes)。用于减少以时间戳查找消息时遍历元素数量。
1.3 顺序IO
对于我们常用的机械硬盘,其读取数据分3步:
- 寻道;
- 寻找扇区;
- 读取数据;
前两个,即寻找数据位置的过程为机械运动。我们常说硬盘比内存慢,主要原因是这两个过程在拖后腿。不过,硬盘比内存慢是绝对的吗?其实不然,如果我们能通过顺序读写减少寻找数据位置时读写磁头的移动距离,硬盘的速度还是相当可观的。一般来讲,IO速度层面,内存顺序IO > 磁盘顺序IO > 内存随机IO > 磁盘随机IO。
Kafka在顺序IO上的设计分两方面看:
- LogSegment创建时,一口气申请LogSegment最大size的磁盘空间,这样一个文件内部尽可能分布在一个连续的磁盘空间内;
- .log文件也好,.index和.timeindex也罢,在设计上都是只追加写入,不做更新操作,这样避免了随机IO的场景;
Kafka是公认的高性能消息中间件,顺序IO在这里占了很大一部分因素。
不知道大家有没有听过这样一个说法:Kafka集群能承载的Partition数量有上限。很大一部分原因是Partition数量太多会抹杀掉Kafka顺序IO设计带来的优势,相当于自废武功。Why?因为不同Partition在磁盘上的存储位置可不保证连续,当以不同Partition为读写目标并发地向Kafka发送请求时,Server端近似于随机IO。
1.4 端到端压缩
一条压缩消息从生产者处发出后,其在消费者处才会被解压。Kafka Server端不会尝试解析消息体,直接原样存储,省掉了Server段压缩&解压缩的成本,这也是Kafka性能喜人的原因之一。
二. 源码结构
2.1 核心类
2.1.1 核心类之间的关系
Kafka消息存储涉及的核心类有:
- ReplicaManager
- Partition
- Replica
- Log
- LogSegment
- OffsetIndex
- TimeIndex
- MemoryRecords
- FileRecords
它们之间的关系如下图:
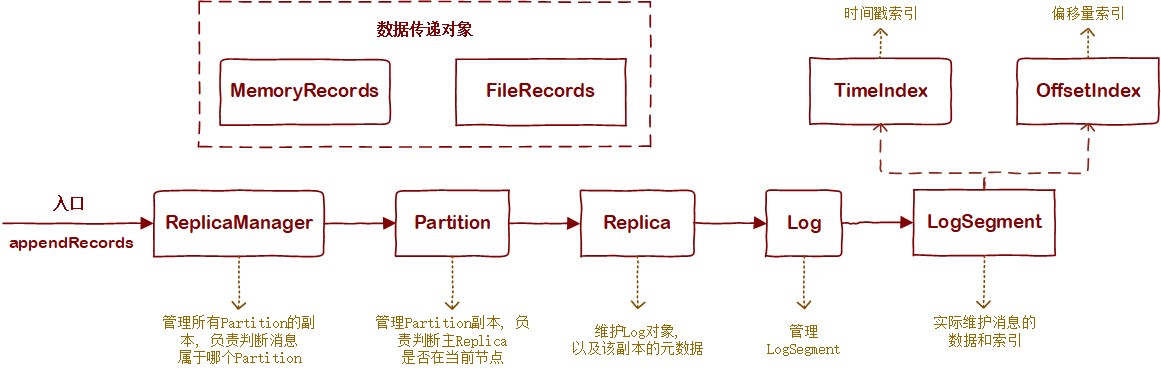
2.1.1 数据传递对象
Kafka消息存储的基本单位不是"一条消息",而是"一批消息"。在生产者文章中提到过,Producer针对每个Partition会攒一批消息,经过压缩后发到Server端。Server端会将对应Partition下的这一"批"消息作为一个整体进行管理。所以在Server端,一个"Record"表示"一批消息",而数据传递对象"XXXRecords"则可以表示一批或多批消息。
MemoryRecords所表示的消息数据存储于内存。比如Server端从接到生产者消息到将消息存入磁盘的过程就用MemoryRecords来传递数据,因为这期间消息需要暂存于内存,且没有磁盘数据与之对应。MemoryRecords核心属性有两个:
| 属性名 | 类型 | 说明 |
|---|---|---|
| buffer | ByteBuffer | 存储消息数据 |
| batches | Iterable<MutableRecordBatch> | 迭代器;用于以批为单位遍历buffer所存储的数据 |
FileRecords所表示的消息数据存储于磁盘文件。比如从磁盘读出消息返回给消费者的过程就用FileRecords来传递数据。其核心属性如下:
| 属性名 | 类型 | 说明 |
|---|---|---|
| file | File | 消息数据所存储的文件 |
| channel | FileChannel | 文件所对应的FileChannel |
| start | int | 本FileRecords所表示的数据在文件中的起始偏移量 |
| end | int | 本FileRecords所表示的数据在文件中的结束偏移量 |
| size | AtomicInteger | 本FileRecords所表示的数据的字节数 |
2.1.2 ReplicaManager
ReplicaManager负责管理本节点存储的所有副本。这个类的属性真的巨多。不过不要慌,对于消息存储原理这块,我们只需要关注下面这一个属性就可以,其他和请求处理以及副本复制相关的属性我们放到后边对应章节慢慢分析。
| 属性名 | 类型 | 说明 |
|---|---|---|
| allPartitions | Pool[TopicPartition, Partition] | 存储Partition对象,可根据TopicPartition类将其检索出来 |
2.1.3 Partition
Partition对象负责维护本分区下的所有副本,其核心属性如下:
| 属性名 | 类型 | 说明 |
|---|---|---|
| allReplicasMap | Pool[Int, Replica] | 本分区下的所有副本。其中,key为BrokerId,value为Replica对象 |
| leaderReplicaIdOpt | Option[Int] | Leader副本所在节点的BrokerId |
| localBrokerId | Int | 本节点对应的BrokerId |
2.1.4 Replica
Replica负责维护Log对象。Replica是业务模型层面"副本"的表示,Log是数据存储层面的"副本"。Replica核心属性如下:
| 属性名 | 类型 | 说明 |
|---|---|---|
| log | Option[Log] | Replica对应的Log对象 |
| topicPartition | TopicPartition | 标识该副本所属"分区" |
| brokerId | Int | 该副本所在的BrokerId |
| highWatermarkMetadata | LogOffsetMetadata | 高水位(后续章节会详细分析) |
| logEndOffsetMetadata | LogOffsetMetadata | 该副本中现存最大的Offset(后续章节会详细分析) |
2.1.5 Log
Log负责维护副本下的LogSegment,其核心属性如下:
| 属性名 | 类型 | 说明 |
|---|---|---|
| dir | File | Log对应的目录,即存储LogSegment的文件夹 |
| segments | ConcurrentSkipListMap[java.lang.Long, LogSegment] | LogSegment集合,其中key为对应LogSegment的起始offset |
2.1.6 LogSegment
LogSegment则实实在在维护消息数据,其核心属性如下:
| 属性名 | 类型 | 说明 |
|---|---|---|
| log | FileRecords | 本日志段的消息数据 |
| baseOffset | Long | 本日志段的起始offset |
| maxSegmentBytes | Int | 本日志段的最大字节数; 超过后就需要新建一个LogSegment; |
| maxSegmentMs | Long | 日志段也可以根据时间来滚动; 比如待插入消息和日志段第一个消息间隔超过一定时间后,需要开个新的日志段; maxSegmentMs便是所指定的间隔大小(segment.ms 配置项); |
| rollJitterMs | Long | 为避免当前节点上所有LogSegment同时滚动的情况,需要在maxSegmentMs基础上减去一个随机数值; rollJitterMs便是这个随机扰动(segment.jitter.ms 配置项指定该随机数的最大值) |
| offsetIndex | OffsetIndex | 偏移量索引,下文分析 |
| timeIndex | TimeIndex | 时间索引,下文分析 |
2.1.7 OffsetIndex和TimeIndex
首先两个索引都继承于AbstractIndex,那么他们就有一批共同的核心属性:
| 属性名 | 类型 | 说明 |
|---|---|---|
| file | File | 对应的索引文件 |
| mmap | MappedByteBuffer | 索引文件的内存映射 |
| maxIndexSize | Int | 索引文件的最大字节数, 由 segment.index.bytes 配置项指定 |
| baseOffset | Long | 所在日志段的起始offset |
实际上,这些属性已足够表达当前的索引逻辑,OffsetIndex和TimeIndex均未再额外自定义属性。
2.2 消息写入流程
消息写入流程时序图如下:
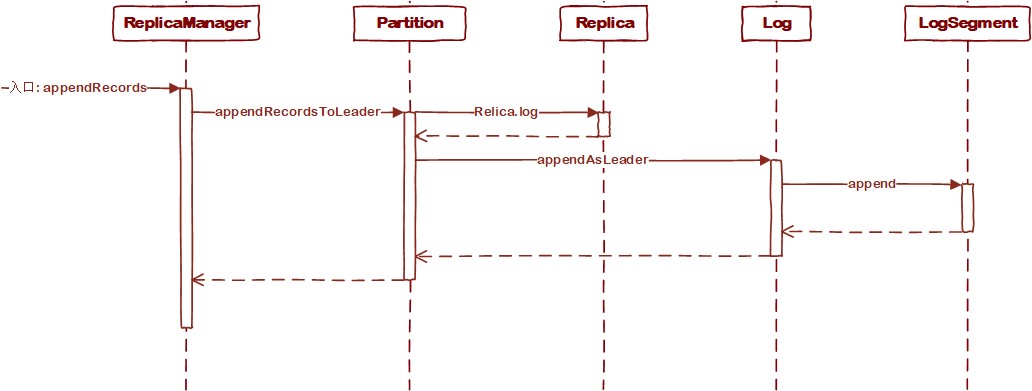
需要提一点,这里不是为了让诸君将这一串流程视为整体记入脑海。面向对象的代码仍然要从面向对象的角度去理解。所以这里重要的是各个类各自内部的逻辑,这有助于进一步明确类所扮演的角色。
2.2.1 ReplicaManager.appendRecords
def appendRecords(timeout: Long,
requiredAcks: Short,
internalTopicsAllowed: Boolean,
isFromClient: Boolean,
entriesPerPartition: Map[TopicPartition, MemoryRecords],// 各Partition上待插入的消息数据
responseCallback: Map[TopicPartition, PartitionResponse] => Unit,
delayedProduceLock: Option[Lock] = None,
recordConversionStatsCallback: Map[TopicPartition, RecordConversionStats] => Unit = _ => ()) {
... ...
val localProduceResults = appendToLocalLog(internalTopicsAllowed = internalTopicsAllowed,
isFromClient = isFromClient, entriesPerPartition, requiredAcks)
... ...
}
private def appendToLocalLog(internalTopicsAllowed: Boolean,
isFromClient: Boolean,
entriesPerPartition: Map[TopicPartition, MemoryRecords],
requiredAcks: Short): Map[TopicPartition, LogAppendResult] = {
... ...
// step1 reject appending to internal topics if it is not allowed
if (Topic.isInternal(topicPartition.topic) && !internalTopicsAllowed) {
(topicPartition, LogAppendResult(
LogAppendInfo.UnknownLogAppendInfo,
Some(new InvalidTopicException(s"Cannot append to internal topic ${topicPartition.topic}"))))
} else {
try {
//step2 若本Broker节点不承载对应partition的主副本, 这步会抛异常
val (partition, _) = getPartitionAndLeaderReplicaIfLocal(topicPartition)
//step3 将消息写入对应Partition主副本, 并唤醒相关的等待操作(比如, 消费等待)
val info = partition.appendRecordsToLeader(records, isFromClient, requiredAcks)
... ...
}
}
}
}
appendRecords直接调用appendToLocalLog,后者才是真正实行逻辑的方法。ReplicaManager的逻辑基本分三步走:
- 检查目标Topic是否为Kafka内部Topic,若是的话根据配置决定是否允许写入;
- 获取对应的Partition对象;
- 调用Partition.appendRecordsToLeader写入消息数据;
2.2.2 Partition.appendRecordsToLeader
接下来看看Partition内部的逻辑
def appendRecordsToLeader(records: MemoryRecords, isFromClient: Boolean, requiredAcks: Int = 0): LogAppendInfo = {
val (info, leaderHWIncremented) = inReadLock(leaderIsrUpdateLock) {
leaderReplicaIfLocal match {
//step1 判断Leader副本是否在当前节点
case Some(leaderReplica) =>
//step2 获取Log对象
val log = leaderReplica.log.get
... ...
//step3 调用Log对象方法写入数据
val info = log.appendAsLeader(records, leaderEpoch = this.leaderEpoch, isFromClient)
... ...
// 若本节点不是目标Partition的Leader副本, 抛异常
case None =>
throw new NotLeaderForPartitionException("Leader not local for partition %s on broker %d"
.format(topicPartition, localBrokerId))
}
}
... ...
}
这里的逻辑也分3步走:
- 判断Leader副本是否在当前节点;
- 获取Log对象;
- 调用Log对象的appendAsLeader方法写入数据;
这里我们额外看下第1步的原理。leaderReplicaIfLocal是个方法
def leaderReplicaIfLocal: Option[Replica] =
leaderReplicaIdOpt.filter(_ == localBrokerId).flatMap(getReplica)
def getReplica(replicaId: Int = localBrokerId): Option[Replica] = Option(allReplicasMap.get(replicaId))
其核心思想是那本节点BrokerId和Leader副本所在节点的BrokerId作比较,若相等,则返回对应的Replica对象。
2.2.3 Log.appendAsLeader
def appendAsLeader(records: MemoryRecords, leaderEpoch: Int, isFromClient: Boolean = true): LogAppendInfo = {
append(records, isFromClient, assignOffsets = true, leaderEpoch)
}
private def append(records: MemoryRecords, isFromClient: Boolean, assignOffsets: Boolean, leaderEpoch: Int): LogAppendInfo = {
... ...
// maybe roll the log if this segment is full
val segment = maybeRoll(validRecords.sizeInBytes, appendInfo)
... ...
// 将消息插入segment
segment.append(largestOffset = appendInfo.lastOffset,
largestTimestamp = appendInfo.maxTimestamp,
shallowOffsetOfMaxTimestamp = appendInfo.offsetOfMaxTimestamp,
records = validRecords)
... ...
}
appendAsLeader方法直接调用append方法,后者两步走:
- 判断是否需要创建一个新的LogSegment,并返回最新的LogSegment;
- 调用LogSegment.append方法写入数据;
这里我们再额外关注下第1步的判断标准。主要还是根据LogSegment.shouldRoll方法的返回值来作决策:
def shouldRoll(messagesSize: Int, maxTimestampInMessages: Long, maxOffsetInMessages: Long, now: Long): Boolean = {
val reachedRollMs = timeWaitedForRoll(now, maxTimestampInMessages) > maxSegmentMs - rollJitterMs
size > maxSegmentBytes - messagesSize ||
(size > 0 && reachedRollMs) ||
offsetIndex.isFull || timeIndex.isFull || !canConvertToRelativeOffset(maxOffsetInMessages)
}
Kafka的源码很清晰的,这方面值得点赞和学习。从shouldRoll的结果表达式我们可以看到,以下4类场景中,LogSegment需要向前滚动:
- 若接受新消息的写入,当前LogSegment将超过最大字节数限制;
- 若接受新消息的写入,当前LogSegment将超过最大时间跨度限制;
- 当前LogSegment对应的索引已无法写入新数据;
- 输入的offset不在当前LogSegment表示范围;
2.2.4 LogSegment.append
def append(largestOffset: Long,
largestTimestamp: Long,
shallowOffsetOfMaxTimestamp: Long,
records: MemoryRecords): Unit = {
// step1.1 判断输入消息大小
if (records.sizeInBytes > 0) {
trace(s"Inserting ${records.sizeInBytes} bytes at end offset $largestOffset at position ${log.sizeInBytes} " +
s"with largest timestamp $largestTimestamp at shallow offset $shallowOffsetOfMaxTimestamp")
// step1.2 校验offset
val physicalPosition = log.sizeInBytes()
if (physicalPosition == 0)
rollingBasedTimestamp = Some(largestTimestamp)
ensureOffsetInRange(largestOffset)
// step2 append the messages
val appendedBytes = log.append(records)
trace(s"Appended $appendedBytes to ${log.file} at end offset $largestOffset")
// step3 Update the in memory max timestamp and corresponding offset.
if (largestTimestamp > maxTimestampSoFar) {
maxTimestampSoFar = largestTimestamp
offsetOfMaxTimestamp = shallowOffsetOfMaxTimestamp
}
// step4 append an entry to the index (if needed)
if (bytesSinceLastIndexEntry > indexIntervalBytes) {
offsetIndex.append(largestOffset, physicalPosition)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestamp)
bytesSinceLastIndexEntry = 0
}
bytesSinceLastIndexEntry += records.sizeInBytes
}
}
LogSegment.append大体可以分为4步:
- 数据校验
- 校验输入消息大小;
- 校验offset;
- 写入数据(注意: 此步的log对象不是Log类的实例,而是FileRecords的实例);
- 更新统计数据;
- 处理索引;
三. 总结
本文从业务模型&源码角度分析了Kafka消息存储原理。才疏学浅,不一定很全面。
另外也可以在目录中找到同系列的其他文章:Kafka源码分析系列-目录(收藏关注不迷路)。
欢迎诸君随时来交流。
微信搜索“村口老张头”,不定期推送技术文章哦~

也可以知乎搜索“村口老张头”哦~

