



javascript正则用法
一、元字符
. 匹配除了换行符以外的字符。
\w 匹配字母或者数字或者下划线
\W 匹配不是字母、数字、下划线
\d 匹配数字,相当于[0-9]
\D 匹配不是数字的字符
\s 匹配任意不可见字符,如空格、制表符,换行符等
\S 匹配任意可见字符
^ 匹配字符串开始位置
$ 匹配字符串结束的位置
/[\W\w]/ 全集
/[\d\D]/ 全集
/[\s\S]/ 全集
举个栗子:
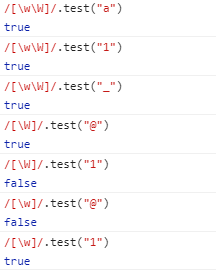
^和$
举个栗子:
二、量词
* 重复任意次 ,相当于{0,}
? 重复0次或者1次 ,相当于{0,1}
+ 重复一次或者更多次,相当于{1,}
{n} 重复n次
{n,} 重复n次或者大于n次
{n,m} 重复n到m次
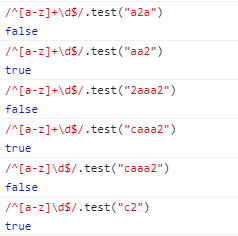
举个栗子:
三、分支与字符集
(a|b|c) 匹配a或者b或者c字符
[abc]==[a-c] 匹配abc字符
[^abc]==[^a-c] 匹配不是abc字符
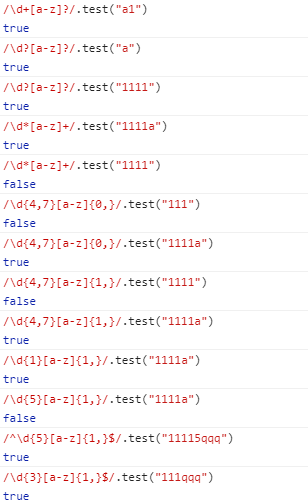
举个栗子:
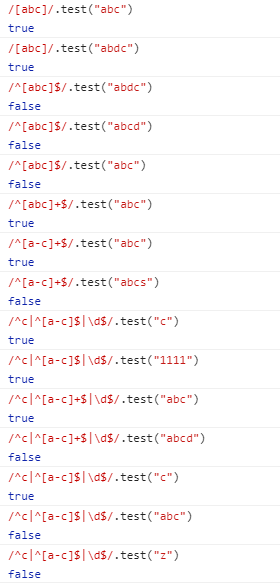
/[a-c]/==(a|b|c) (不加量词的情况)至少有一个字符匹配1次或者多次
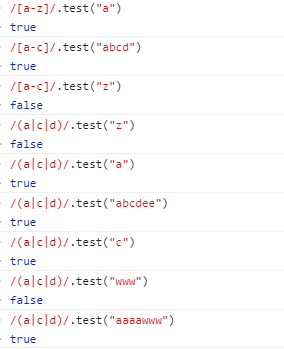
/[a-c]/ 加量词和不加量词对比的情况 开头和结尾必须是a开头,c结尾 这个不用多说
不加量词满足条件就是只能匹配a或者b或者c一次,加了量词就可以多匹配

/(a|c|d)/ 同 /[a-c]/ 一样的用法
解释:前提是以a或者c或者d开头 , 以a或者c或者d结尾 ,无量词只匹配a或者c或者d中的一个一次。有量词就可以多次匹配

四、分组和引用
分组:
/(\d{4})-(\d{2})-(\d{2})/

/(?:\d{4})-(\d{2})-(\d{2})/ 分组不捕获 内存占用小 也就是不用把年存起来啦

下面是es2018新增的,低版本浏览器可能不兼容:
命名分组:
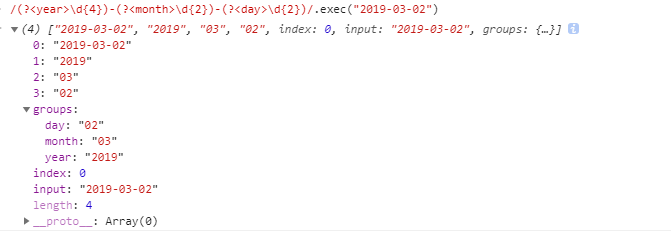

引用:引用就是引用谁就是和谁是一样的
\1 对前面的引用 因为下面的第一个加了?:意思就是第一个不存在了 所以第二个变成了第一个 多以\1就是对前面的引用

去掉?:

下面这个:$1代表的就是(\d{2}) $2代码(\1)

RegExp.$[_1-9]
这个和上面的\1,\2,\3一个意思,少见了
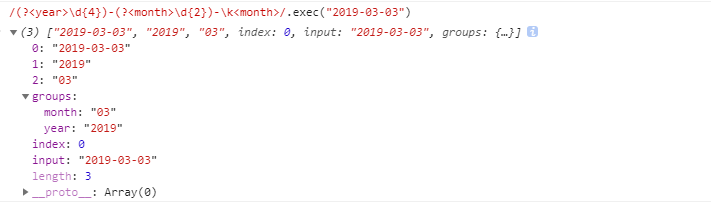
/(?<year>\d{4})-(?<month>\d{2})-\k<month>/ \k<month>对月份的引用
五,转义字符
\转义字符 有特殊含义的字符如 . ? + { } ( ) 等有特殊含义的 /\./匹配点 /\+/匹配加号等
六、零宽断言
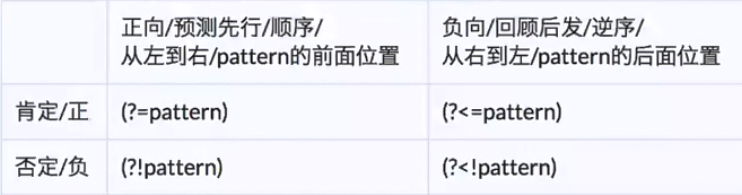
需要注意一下几点:
①ab↑cdefm 基于箭头处的位置向后匹配是负向,向前匹配是正向
②肯定是直接按照这pattern进行匹配,否定是按照pattern进行匹配然后取反
③零宽意思是(?=pattern)(?!pattern)(?<=pattern)(?<!pattern) 是不占位置的
④零宽对言意思是根据 (?=pattern)(?!pattern)(?<=pattern)(?<!pattern)里面的表达式对要匹配的字符串进行全局扫描,如果满足就进行匹配,不满足就不匹配,这样的好处是性能高。
举个栗子:

七、惰性和贪婪
贪婪模式:在匹配成功的前提下,尽可能多的去匹配
惰性模式:在匹配成功的前提下,尽可能少的去匹配
贪婪模式用于匹配优先量词修饰的子表达式 像:+,*,{n,m},{n,}
惰性模式用于匹配忽略优先量词修饰的子表达式 ,就是尽量少的。
贪婪模式:
举个栗子:

贪婪模式尽可能多的去匹配,.*把要匹配的都能匹配了,之后剩下bbb,那么久开始回溯,这样再回来匹配bbb,这种匹配方式特别损耗性能。
惰性模式:
举个栗子:

惰性模式尽可能少的去匹配,这样.*?,?就是0个或者1个,也就是可以匹配也可以不匹配,但是第一个是a,,所以.*可以匹配一个a,之后就可以匹配bbb了,这种方式相对于贪婪模式性能要好很多。
八,修饰符和标志
g 全局
i 忽略大小写
m 多行
es2018 新增:
y sticky
u unicode
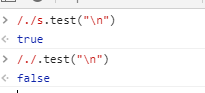
s dotAll 就是点 这点包含\n
举个栗子:
九、正则方法

介绍如下:
①pattern.test("字符串") 返回true|false
②pattern.exec("字符串") 返回数组|null
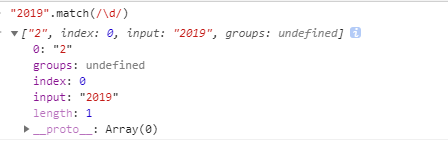
③string.match(pattern) 返回数组|null
④string.replace(pattern,string) 根据正则找到匹配,用第二个参数替换

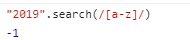
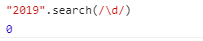
⑤string.search(pattern) 反回匹配到的字符的索引 没有匹配到反回-1
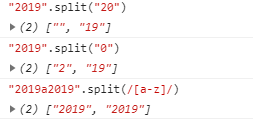
⑥string.split(pattern|string) 使用正则或者字符串分割一个字符串,将分割后的字符串存储到数组里面返回
加油!!O(∩_∩)O哈哈~

