


http缓存
http缓存对前端来说很重要,可以优化页面的性能,体验会更好,下面就来了解一下http缓存是怎么一回事呢
先来了解一下浏览器缓存:
浏览器缓存是把已经访问的过的页面(如 html js css 图片等)拷贝一份副本保存在浏览器中,当下一次访问该网站,url相同,缓存会根据缓存机制决定是直接使用副本响应访问请求,还是向源服务器再次发送请求。
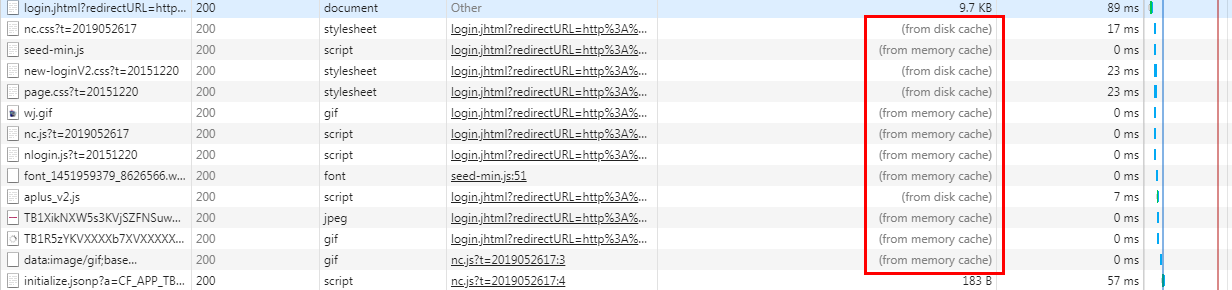
第一次访问就会出现多少k,第二次就会就读缓存了(from memory catch或者from disk catch)
Chrome的from memory catch(内存缓存) 和 from disk catch(硬盘缓存)过程?
先写入内存为from memory catch(内存读写更快,缓冲区作用),然后大概5分钟,在写入disk中变成from disk catch,这样做提高性能。
浏览器缓存的控制:
①web开发者可以在HTML页面的<head>节点中加入<meta>标签,代码如下
<meta http-equiv="Pragma" content="no-cache">
<!- Pragma是http1.0版本中给客户端设定缓存方式之一-->
上述代码的作用是告诉浏览器当前页面不被缓存,每次访问都需要去服务器拉取。
但是这种禁用缓存的形式用处很有限:
a. 仅有IE才能识别这段meta标签含义,其它主流浏览器仅识别“Cache-Control: no-store”的meta标签。
b. 在IE中识别到该meta标签含义,并不一定会在请求字段加上Pragma,但的确会让当前页面每次都发新请求(仅限页面,页面上的资源则不受影响)。
②使用缓存有关的HTTP消息报头
首先我这里用到两个概念:
强缓存:就是客户端第二次访问同一个网站的时候,会去查看是否有缓存或者是否失效,如果没有缓存或者已经失效,就会去服务器端发请求,请求新数据,新数据返回后然后在把数据根据某种规则缓存起来。
对比缓存:客户端第二次访问同一个网站的时候,会读取缓存中的缓存数据标识,然后向服务器端发送请求,请求服务器验证缓存标识所对应的数据是否有效,如果是有效的,返回304状态码,就返回客户端是有效的,通知客户端比较成功,可以使用缓存数据。客户端就读取缓存啦,如果是失效的,就直接返回新数据和缓存规则,客户端接收新数据并根据缓存规则进行缓存数据。
下面就来介绍正文,有关http缓存的内容:
强缓存(expire/catch-control)
expire 设置对象的有效期
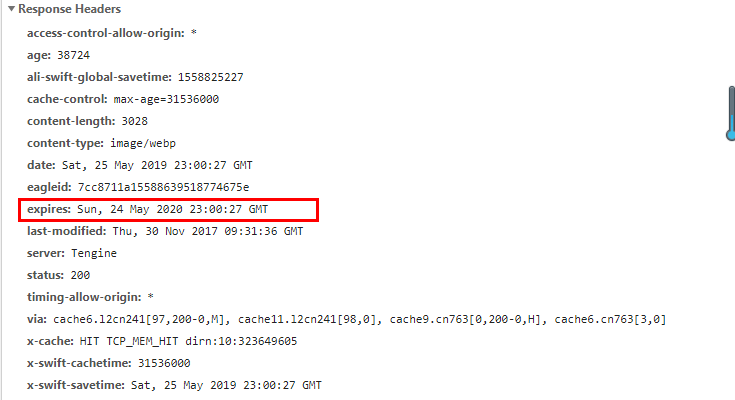
当客户端去再次请求服务器之前会查一下expires的时间,比较当前的时间是否在expires时间之内,在之前就直接读取缓存,否则就去服务器重新获得。
但是这有个问题,如果客户端的本地时间改了,那么这样去和expire时间去比较,这样会出现不准确。
不过expires是HTTP 1.0的东西,现在默认浏览器均默认使用HTTP 1.1,所以它的作用基本忽略。
到http1.1的时候就出现了catch-control。就可以避免上面本地时间和服务器时间不一致问题。
catch-control:
属性值有:
max-age=num (s) 设置最大缓存时间
private: 客户端可以缓存 ,不设置这个属性默认值就是pravite (pravite 中间层,cdn不能缓存,浏览器能换存的。设置成public 。中间层能缓存的,cdn等)
public: 客户端和代理服务器都可缓存(前端的同学,可以认为public和private是一样的)
no-catch 不会被缓存(可以通过对比缓存校验缓存数据)
no-store 所有内容都不会缓存,强缓存,对比缓存都不会触发(对于前端开发来说,缓存必不可少,这个几乎被忽略了)
cache-control 的优先级比 expire 高。
强缓存当然也存在问题,在这个期限时间内都用缓存数据了,那我服务器更新数据怎么办?下面介绍一下对比缓存。
对比缓存
Last-Modified / If-Modified-Since:
Last-Modified:设置对象的最后修改时间 (http1.0)
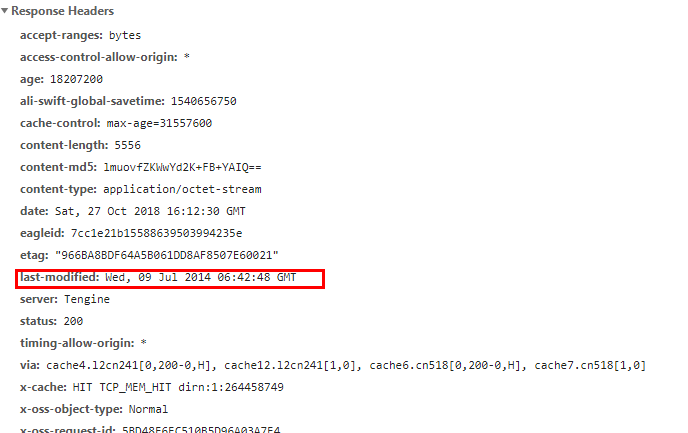
last-Modified 由服务器产生,指数据的最后修改时间,服务器将 Last-Modified 返回给客户端,下一次浏览器再次请求会携带这个最后修改时间,放在 If-Modified-Since 里,服务器拿到 If-Modified-Since 后,对比数据的最后修改时间:
比对成功,代表数据未修改过,返回状态码 304, 重定向到缓存数据库。
对比失败,代表数据距离上一次被请求时, 做过修改,就要重新响应数据, 返回 200。
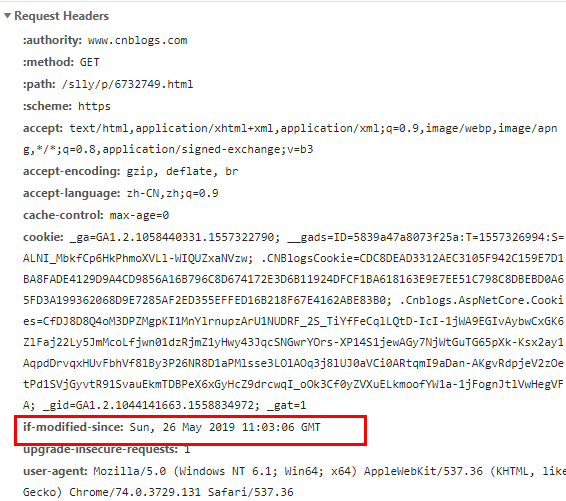
还是会存在问题:
①资源被修改,内容没变的话,但last-modifify却改变了,导致文件没法使用缓存,比如touch一下。
②last-modifify 是精确到1s的,本质上能在1s内修改文件两次。这样它将不能准确标注文件的新鲜度。
③有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形。
Etag / If-None-Match(优先级高于Last-Modified / If-Modified-Since)
etag:解决可能在同一秒保存两次,也可能服务器修改时间不一致
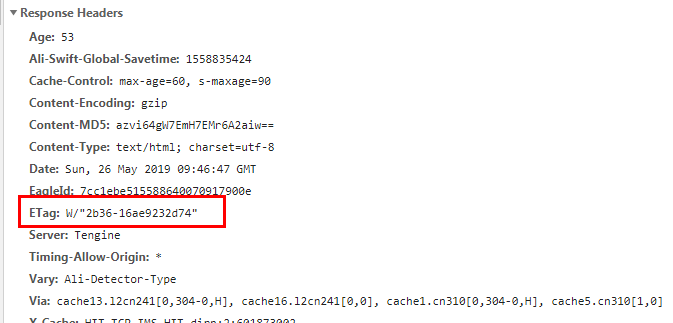
服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定)。
再次请求服务器时,通过此字段通知服务器客户段缓存数据的唯一标识。
服务器收到请求后发现有头If-None-Match 则与被请求资源的唯一标识进行比对,不同,说明资源又被改动过,则响应整片资源内容,返回状态码200;
相同,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。
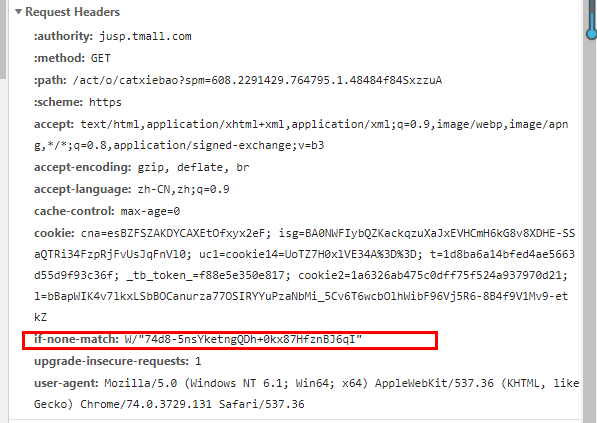
还有需要注意点:
etag 值开头是w/是弱计算,没有对内容真正计算hash。而一串字母数字混合的的是强的计算。
为什么要分强和弱呢?根据内容计算hash消耗内存较多,内容越长,计算越慢,计算hash 比较消耗cpu,所有会有个比较弱的,为了提高性能。
max-age+last-modified会怎样?
首先看max-age是否过期,然后在用last-modified 去请求服务器,看服务器的文件是否有变化。
max-age+last-modified+etag会怎样?
优先校验max-age ,再校验etag,最后last-modified
以上是http缓存知识,学无止境,一起加油。
喜欢就赞一个 ,支持一下哦,O(∩_∩)O哈哈~
