
Rasa: OpenSource Language Understanding and Dialogue Management 翻译
Rasa: OpenSource Language Understanding and Dialogue Management
摘要
这是一个用于构建会话系统的开源python库,主要由两个部分构成Rasa NLU(自然语言理解) 和Rasa Core(对话管理),这两个软件包都有大量文档,并附带一套全面的测试。该代码地址:https://github.com/RasaHQ/
1 简介
2 相关工作
Rasa的API使用了来自scikit-learn(专注于一致的API而不是严格的继承)和Keras(不同后端实现的一致API)的思想,实际上这两个库都是Rasa应用程序的(可选的)组件。
Rasa nlu的性能优于各种闭源解决方案,使用条件随机字段识别自定义实体。
Rasa的语言理解和对话管理完全脱钩。这允许Rasa NLU和Core彼此独立使用,并允许经过训练的对话模型跨语言重用。对于语言生成,我们鼓励开发人员通过为每个响应创作多个模板来生成各种响应。Rasa Core也没有考虑到语音转录和NLU的不确定性,正如通常使用部分可观察马尔可夫决策过程(POMDP)所实现的那样。
3 代码说明
Rasa的架构采用模块化设计。这样可以轻松与其他系统集成。例如,Rasa Core可以与Rasa NLU以外的NLU服务一起用作对话管理器。
3.1 架构
对话状态保存在tracker对象中。每一个对话会话都会有一个tracker对象,这是唯一一个有状态的组件。tracker存储槽,以及导致该状态和在对话中发生的所有事件的日志。可以通过重放所有事件来重建对话的状态。
当收到用户消息时,Rasa会采取一系列步骤,如图1所示。第1步由Rasa NLU执行,所有后续步骤均由Rasa Core处理。
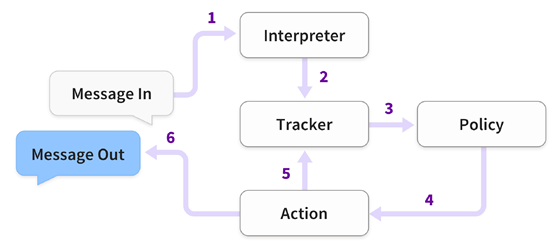
- 上图接受消息并将它传递给Interpreter(解释器)(例如:Rasa NLU)来提取意图(intent),实体(entity)和其他一些结构化信息。
- Tracker(追踪器)保持对话状态,他接收到新的消息的通知。
- Policy接收tracker的当前状态
- Policy选择下一个动作(action)
- Tracker记录选择的动作(action)
- 执行操作(这可以包括向用户发送消息)
- 如果预测的操作不是“监听(listen)”,请返回步骤3。
3.2 Action(动作)
我们将对话管理问题定为一个分类问题。在每次迭代中,Rasa Core预测都会从预定义列表中提取动作(action)。动作可以是简单的话语,即向用户发送消息,或者它可以是执行的任意函数。当一个动作(action)被执行时,它被传递到一个tracker实例中,因此可以利用在对话历史中收集的任何相关信息:插槽,先前的话语和先前动作的结果。
Actions(动作)不能直接改变tracker,但是在执行时可能会返回事件列表。tracker使用这些事件来更新它的状态。有许多不同的事件类型,例如SlotSet,AllSlotsReset,Restarted等。完整列表在文档中地址如下:https://core.rasa.ai
3.3 自然语言理解(NLU)
Rasa NLU是自然语言理解模块。它包含松耦合的模块,在consistent (一致的)API中结合了许多自然语言处理和机器学习的库。为此,预定义的管道(pipelines )具有合理的默认值,适用于大多数用例。例如,推荐的管道 spacy_sklearn,使用以下组件处理文本。首先,文本被标记化并且使用spaCy NLP库注释词性(POS)。然后spaCy featuriser 为每个注释查找一个GloVe向量,并将它们汇集起来以创建整个句子的表示。然后,scikit-learn分类器为数据训练一个估计器,默认情况下,使用五折交叉验证训练多类支持向量分类器。然后,ner_crf 组件使用标记和词性标签作为基本特征,训练条件随机字段以识别训练数据中的实体。由于这些组件中的每一个都实现了相同的API,因此很容易交换(比方说)GloVe向量,对于自定义,特定于域的字嵌入的,或者使用不同的机器学习库来训练分类器。还有其他组件用于处理词汇外单词和对于更高级用户的许多自定义选项。所有这些详细的文档说明都在:https://nlu.rasa.ai。
3.4 Policies(策略)
policy的作用是在给定tracker 对象的情况下选择要执行的下一个操作(action)。policy与featurizer被一起实例化,featurizer在给定tracker的情况下创建当前对话状态的矢量表示。
标准特征描述符合以下功能:
最后一个action是什么;
最近用户消息中的意图和实体;
目前定义了哪些插槽。
槽(slot)的特征可能会有所不同。在最简单的情况下,槽被单个二进制向量元素表示,显示它是否被填充。槽作为分类变量被编码为 1/k 个二进制向量,那些(向量)具有连续值的(向量)可以指定影响其特征的阈值,或者简单地作为浮点数传递给featurizer。
有一个超参数 max_history,它指定了包含在特征中的先前状态的数量。默认情况下,状态堆叠形成二维数组,可以通过递归神经网络或类似的序列模型进行处理。在实践中,我们发现对于大多数问题,max_history的值在3到6之间是很好的。
4 用法
4.1 训练数据格式
Rasa NLU 和 Core都使用人类可读的训练数据格式。Rasa NLU需要一个带有意图和实体标注的话语列表。这些列表可以指定为json格式或者是markdown格式。markdown格式非常的经凑且容易阅读,可以由许多文本编辑器和Web应用程序(如GitHub)呈现。
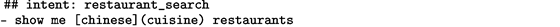
阅读json格式会有稍微的麻烦,但是(它)空格不敏感,更适合在应用程序和服务器之间传输训练数据。

Rasa Core使用markdown来指定训练对话(又名“故事(stories)”)


一个故事以一个名字开头,前面有两个“#”

名称地选择是任意的,但是它有助于调试。故事的主体是一系列事件,由换行符分割。一个事件如下:
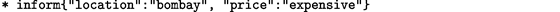
用户的表达注释为一种对话行为。一般格式:
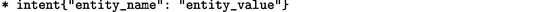
其中实体是由逗号分隔的键值对。系统操作也是事件,由以破折号开头的行指定。故事的结尾用换行符表示。
4.1 机器教学
除了监督学习之外,Rasa Core还支持机器教学方法,通过系统开发人员可以做出正确的操作(action)。我们发现用于生成训练数据这是一种实用的方法,并探索合理有效的对话空间。
以下是用户参与餐馆推荐系统的机器教学的示例(在第5节中描述)。向用户显示以下提示

如果用户输入2,表示操作错误,将向他们提供如下提示,其中列出了对话策略可能的操作和分配给他们的概率:

选择正确的操作会创建一个新的训练数据点。然后,Rasa Core训练部分对话政策,并将对话推进到下一步。完成后,训练的模型将保持不变,新生成的训练数据将保存到文件中。
4.3 对话图可视化
Rasa Core还具有可视化训练对话图表的功能。故事(story)图是将动作作为节点的有向图。边缘被标记为在两个操作执行之间发生的用户话语。如果两个连续动作之间没有用户交互,则省略边缘标签。每个图都有一个名为START的初始节点和一个名为END的终端节点。请注意,图表不会捕获完整的对话状态,并非沿着边缘的所有可能的行走(walk)必然发生在训练集中。为了简化可视化,使用启发式方法合并相似节点。如图2所示运行简化之前和之后生成的图形。在简化期间,将两个节点合并为一个节点,该节点继承所有传入和传出的边,删除流程中的重复项。这使得生成的图形更容易解释。
如果满足以下两个条件,则合并节点:
•它们代表相同的行为
•对于所有指向节点的对话,前面的max_history循环都是相同的。
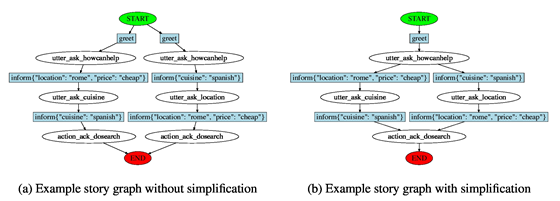
图2:说明故事图如何简化的最小示例。训练数据包含两个具有相同第一次交互的故事。因此,这些节点被认为是等效的并且被合并。
4.4 在生产环境中部署
Rasa NLU和Core的存储库都包含用于生成静态虚拟机(VM)映像的Docker文件。这有助于重现性和易于部署到各种服务器环境。运行HTTP API的Web服务器支持基于线程和基于进程的并行性,允许它们在生产环境中处理大量请求卷。
5 演示
为了演示Rasa Core的用法,我们使用BAbl对话数据集[2]。这是一个简单的槽填充练习,要求系统搜索餐馆,并且必须填写几个槽才能进行成功的搜索。系统可以询问用户他们对任何槽的偏好。可用的插槽是位置,人数,美食和价格范围。
由于问题的固有非线性,这是一个有趣的数据集 - 有多种方法可以获得相同的信息,因此在每种情况下都没有单一的“正确”操作。因此,准确性和精确度不是评估对话政策的最合适的指标。相反,我们会考虑系统如何根据已有的信息选择操作。它应该尝试填充空的插槽。
在图3中,我们可以看到Rasa Core在给定已知的插槽的情况下附加到每个操作的概率。我们看到Core遵循粗略的询问菜肴模式,其次是位置,然后是人数 - 就像在培训数据中一样。然而,它认识到它还可以通过将非零概率归因于每个未填充的时隙来询问其他未填充的时隙。填充的槽(“网格”的下对角线)给出的概率很小。这说明了Rasa Core如何使用上下文线索来学习非线性对话。
6 展望
Rasa NLU和Core都在积极开发中。它们可以作为非专业开发人员使用的会话AI应用研究的平台,因此永远不会“完成”。许多主题正在积极开发中,包括改进对强化学习的支持,使NLU对拼写错误和俚语具有强大的支持,并支持更多语言。我们还计划发布实际数据集,以比较不同模型的性能。作者欢迎对该项目的外部贡献,其中的具体内容可以在GitHub上的存储库中找到。
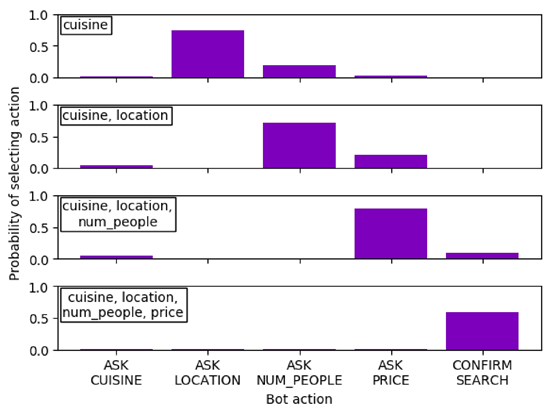
图3:这里我们绘制了为bAbl示例选择动作的概率(第5节)。我们按顺序通知系统正确(上下):美食,位置,人数和价格,系统根据已有的信息选择下一个操作(左上方框中列出)。系统倾向于询问尚未被告知的插槽,直到所有插槽都被填充并且它搜索餐馆。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号