

并发编程实战:用多线程、多进程、多协程加速程序运行
一、为什么要引入并发编程
场景一:一个网络爬虫,按顺序爬花了一个小时,采用并发下载减少到20分钟
场景二:一个APP应用,优化前每次打开页面需要3秒,采用异步编发提升到每次200毫秒
引入并发,就是为了提升程序运行速度
二、有哪些程序提速的方法
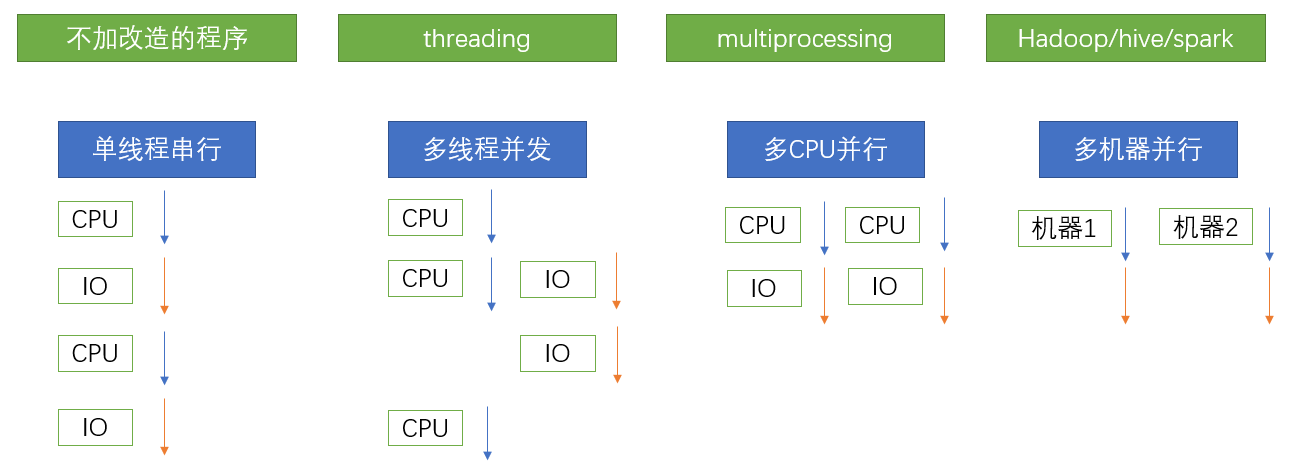
三、Python对并发编程的支持
①多线程:threading,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成
②多进程:multiprocessing,利用多核CPU的能力,真正的并行执行任务
③异步IO:asyncio,在单线程利用CPU和IO同时执行的原理,实现函数异步执行
④使用Lock对资源加锁,防止冲突访问
⑤使用Queue实现不同线程/进程之间的数据通信,实现生产者-消费者模式
⑥使用线程池Pool/进程池Pool,简化线程/进程的任务提交、等待结束、获取结果使用subprocess启动外部程序的进程,并进行输入输出交互
四、Python并发编程的三种方式
①多线程(Thread)
②多进程(Process)
③多协程(Coroutine)
五、CPU密集型计算、IO密集型计算
1、CPU密集型(CPU-bound)
CPU密集型也叫计算密集型,是指I/O在很短的时间就可以完成,CPU需要大量的极端和处理,特点是CPU占用率相当高。
例如:压缩解压缩、加密解密、正则表达式搜索。
2、IO密集型(I/O-bound)
IO密集型指的是系统运作大部分的状况是CPU在等I/O(硬盘/内存)的读/写操作,CPU占用率较低。
例如:文件处理程序、网络爬虫程序、读写数据程序。
六、多进程、多线程、多协程
一个进程中可以启动多个线程,一个线程中可以启动多个协程
1、多进程 Process(multiprocessing)
优点:可以利用多核CPU并行运算
缺点:点用资源最多、可启动数目比线程少
适用于:CPU密集型计算
2、多线程Thread(threading)
优点:相比进程,更轻量级、占用资源少缺点:
相比进程:多线程只能并发执行,不能利用多CPU(GIL)
相比协程:启动数目有限制,占用内存资源,有线程切换开销
适用于:IO密集型计算、同时运行的任务数目要求不多
3、多协程 Coroutine(asyncio)
优点:内存开销最少、启动协程数量最多
缺点:支持的库有限制(aiohttp vs requests)、代码实现复杂
适用于:IO密集型计算、需要超多任务运行、但有现成库支持的场景
七、如何根据任务选择对应技术
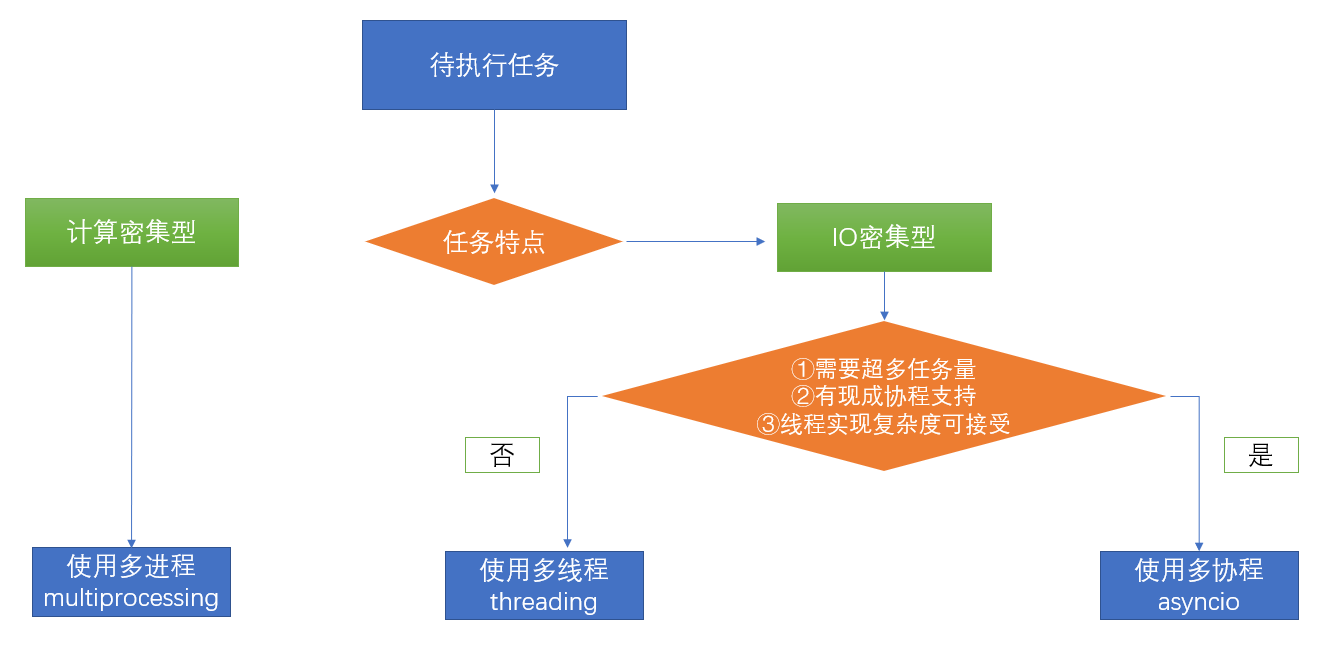
八、GIL
1、Python速度慢的两大原因
①动态类型语言,解释型语言,边解释边执行
②GIL,无法利用多核CPU并发执行
2、GIL是什么
GIL(Global Interpreter Lock):全局解释器锁
是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。
即便在多核心处理器上,使用 GIL 的解释器也只允许同一时间执行一个线程。
由于GIL的存在,即使电脑有多核CPU,但是时刻也只能使用1个,相比并发加速的C++/JAVA速度慢。
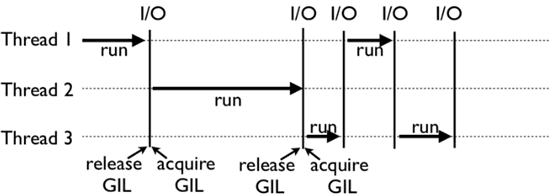
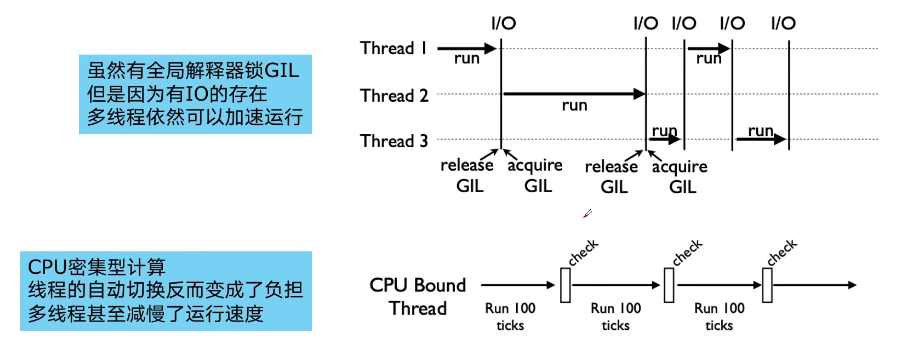
上面这张图,就是 GIL 在 Python 程序的工作示例。其中,Thread 1、2、3 轮流执行,每一个线程在开始执行时,都会锁住 GIL,以阻止别的线程执行;同样的,每一个线程执行完一段后,会释放 GIL,以允许别的线程开始利用资源。
读者可能会问,为什么 Python 线程会去主动释放 GIL 呢?毕竟,如果仅仅要求 Python 线程在开始执行时锁住 GIL,且永远不去释放 GIL,那别的线程就都没有运行的机会。其实,CPython 中还有另一个机制,叫做间隔式检查(check_interval),意思是 CPython 解释器会去轮询检查线程 GIL 的锁住情况,每隔一段时间,Python 解释器就会强制当前线程去释放 GIL,这样别的线程才能有执行的机会。
GIL 是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大
3、为什么会存在GIL
①简而言之:Python设计初期,为了规避并发问题引入了GIL,现在想去除却去不掉了。
②为了解决多线程之间数据完整性和状态同步问题
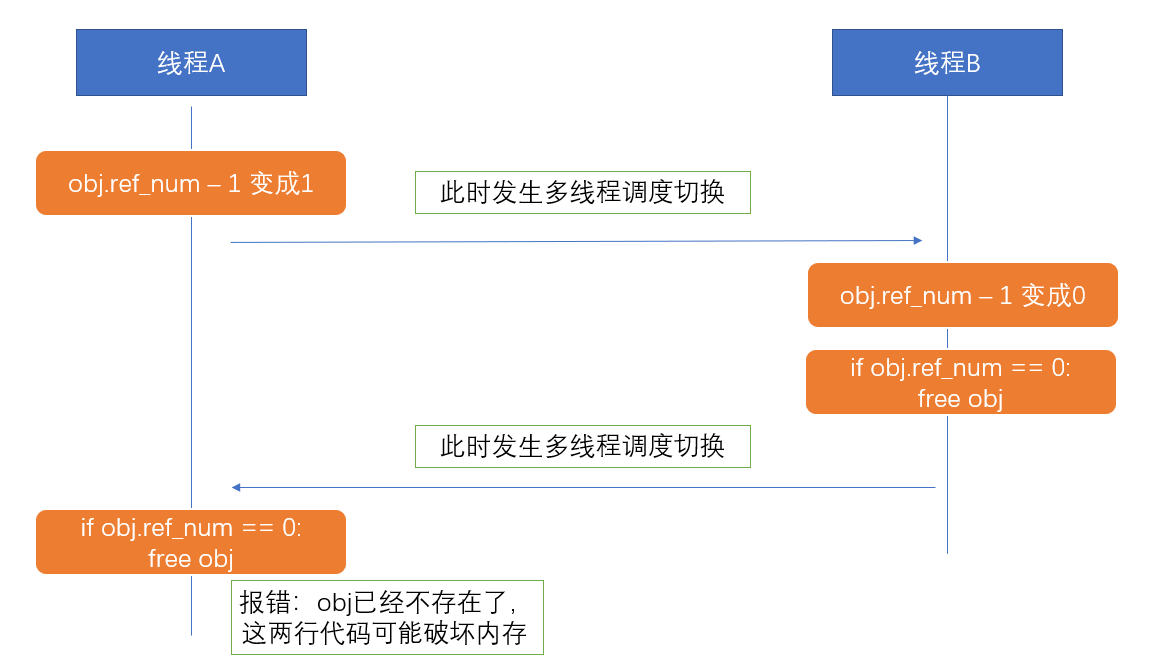
③Python中对象的管理,是使用引用计数器进行的,引用数为0则释放对象
例子:线程A和线程B都引用了对象obj,obj.ref_num=2, 线程A和B都想撤销对obj的引用,如下图片,如果没有GIL锁,则线程A以及线程B对同一个资源进行释放,有可能造成内存破坏
GIL确实有好处:简化了Python对共享资源的管理
4、怎样规避GIL带来的限制
①多线程 threading 机制依然是有用的,用于IO密集型计算
因为在 I/O(read、write、send、recv)期间,线程会释放GIL,实现CPU和IO的并行因此多线程用于IO密集型计算依然可以大幅提升速度
但是多线程用于CPU密集型计算时,只会更加拖慢速度。
②使用multiprocessing的多进程机制实现并行计算、利用多核CPU优势。为了应对GIL的问题,Python提供了multiprocessing。
九、使用多线程,python爬虫被加速10倍
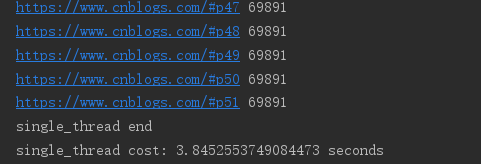
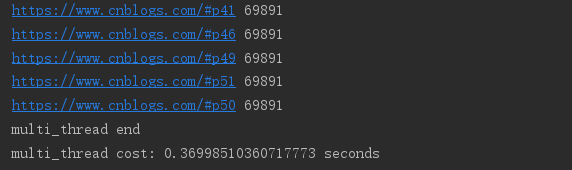
import requests import threading import time urls = [] for i in range(2, 52): urls.append('https://www.cnblogs.com/#p{0}'.format(i)) def craw(url): r = requests.get(url) print(url, len(r.text)) # 单线程:耗时:single_thread cost: 3.8452553749084473 seconds def single_thread(): print('single_thread start') for url in urls: craw(url) print('single_thread end') # 多线程:耗时:multi_thread cost: 0.36998510360717773 seconds def multi_thread(): print('multi_thread start') threads = [] for url in urls: threads.append(threading.Thread(target=craw, args=(url,))) for thread in threads: thread.start() for thread in threads: thread.join() print('multi_thread end') if __name__ == '__main__': start = time.time() single_thread() end = time.time() print('single_thread cost:', end - start, 'seconds') start = time.time() multi_thread() end = time.time() print('multi_thread cost:', end - start, 'seconds')
十、python实现生产者消费者爬虫
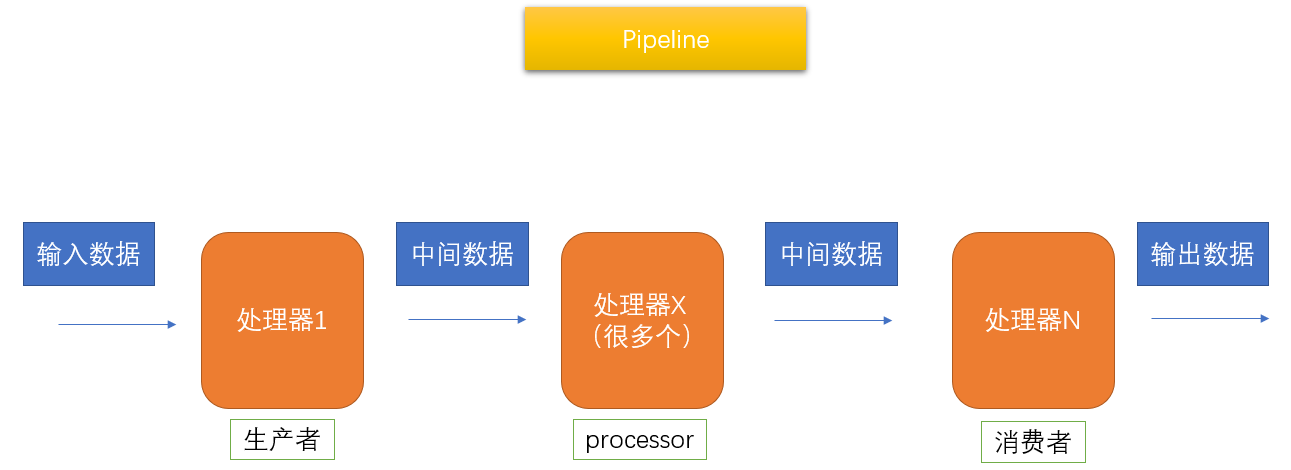
1、多组件的Pipeline技术结构
复杂的事情一般不会一下子做完,而是会分成很多中间步骤一步步完成。
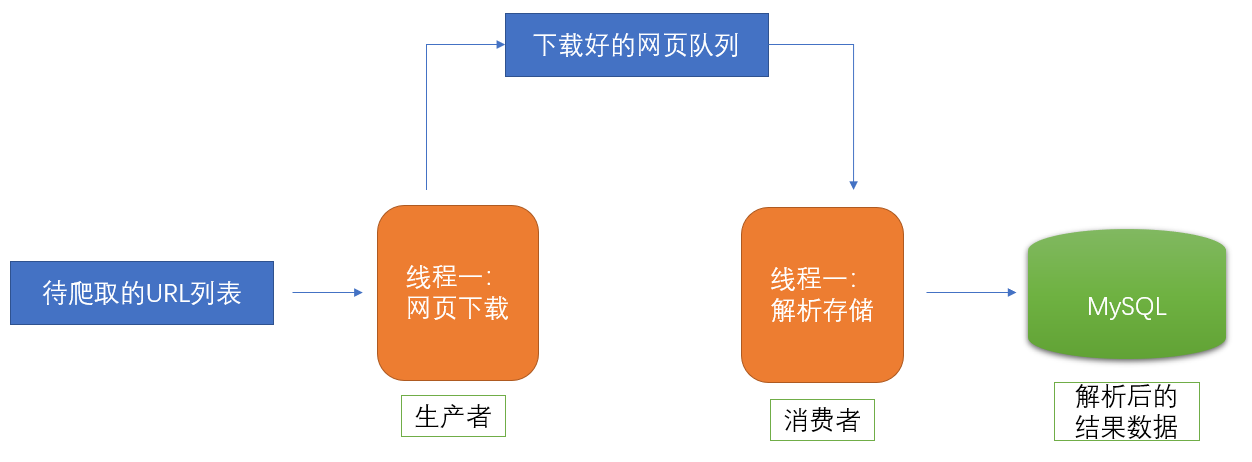
2、生产者消费者爬虫的架构
3、多线程数据通信的queue.Queue

4、单线程:获取第一页的所有文章的链接的标题
import requests from bs4 import BeautifulSoup urls = [] for i in range(2, 52): urls.append('https://www.cnblogs.com/#p{0}'.format(i)) def craw(url): r = requests.get(url) return r.text def parse(html): soup = BeautifulSoup(html, 'html.parser') links = soup.find_all('a', class_='post-item-title') return [(link['href'], link.get_text()) for link in links] if __name__ == '__main__': for result in parse(craw(urls[0])): print(result)
5、多线程实现生产者消费者模型
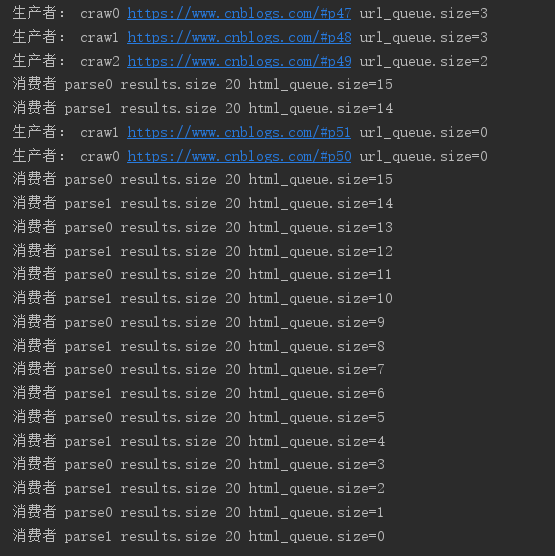
import requests import queue from bs4 import BeautifulSoup import time import threading urls = [] for i in range(2, 52): urls.append('https://www.cnblogs.com/#p{0}'.format(i)) def craw(url): r = requests.get(url) return r.text def parse(html): soup = BeautifulSoup(html, 'html.parser') links = soup.find_all('a', class_='post-item-title') # 返回页面中的每篇文章的链接和标题 return [(link['href'], link.get_text()) for link in links] # 生产者生产任务 def do_craw(url_queue: queue.Queue, html_queue: queue.Queue): while True: url = url_queue.get() html = craw(url) html_queue.put(html) print('生产者:', threading.current_thread().name, url, 'url_queue.size={0}'.format(url_queue.qsize())) time.sleep(2) # 消费者消费任务 def do_parse(html_queue: queue.Queue, fout): while True: html = html_queue.get() results = parse(html) for res in results: fout.write(str(res) + '\n') print('消费者', threading.current_thread().name, 'results.size', len(results), 'html_queue.size={0}'.format(html_queue.qsize())) time.sleep(2) if __name__ == '__main__': url_queue = queue.Queue() html_queue = queue.Queue() for url in urls: url_queue.put(url) # 生产者开启3个线程 for id in range(3): t = threading.Thread(target=do_craw, args=(url_queue, html_queue), name='craw{0}'.format(id)) t.start() # 消费者开启2个线程 # 把消费的任务写到文件中 fout = open('02.data.txt', 'w') for id in range(2): t = threading.Thread(target=do_parse, args=(html_queue, fout), name='parse{0}'.format(id)) t.start()
十一、python线程安全问题以及解决方法
①概念:线程安全指某个函数、函数库在多线程环境中被调用时,能够正确地处理多个线程之间的共享变量,使程序功能正确完成。
由于线程的执行随时会发生切换,就造成了不可预料的结果,出现线程不安全
问题的代码:
import threading import time class Account: def __init__(self, balance): self.balance = balance def draw(account, amount): if account.balance >= amount: time.sleep(1) print(threading.current_thread().name, '取钱成功') account.balance -= amount print(threading.current_thread().name, '余额', account.balance) else: print(threading.current_thread().name, '取钱失败,余额不足') if __name__ == '__main__': account = Account(1000) ta = threading.Thread(name='ta', target=draw, args=(account, 800)) tb = threading.Thread(name='tb', target=draw, args=(account, 800)) ta.start() tb.start()
打印结果:
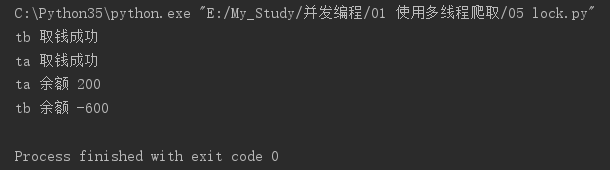
发现执行的是错误的结果。开启了两个线程,去取钱,第一个线程去取钱(1000-800)还剩200,第二个线程取钱应该执行的是else后面的代码,打印余额不足才对。但是因为多个线程去执行时会发生线程切换,当第一个线程在减去余额之前,切换了第二个线程去取钱,这个时候,账户还是1000元,这就是线程安全问题。
②Lock用于解决线程安全问题
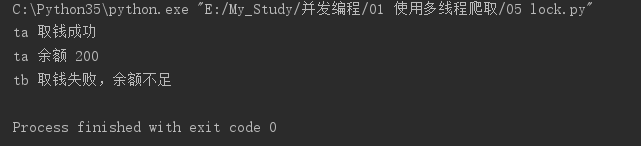
import threading import time lock = threading.Lock() class Account: def __init__(self, balance): self.balance = balance def draw(account, amount): with lock: if account.balance >= amount: time.sleep(1) print(threading.current_thread().name, '取钱成功') account.balance -= amount print(threading.current_thread().name, '余额', account.balance) else: print(threading.current_thread().name, '取钱失败,余额不足') if __name__ == '__main__': account = Account(1000) ta = threading.Thread(name='ta', target=draw, args=(account, 800)) tb = threading.Thread(name='tb', target=draw, args=(account, 800)) ta.start() tb.start()
十二、线程池
1、线程池的原理
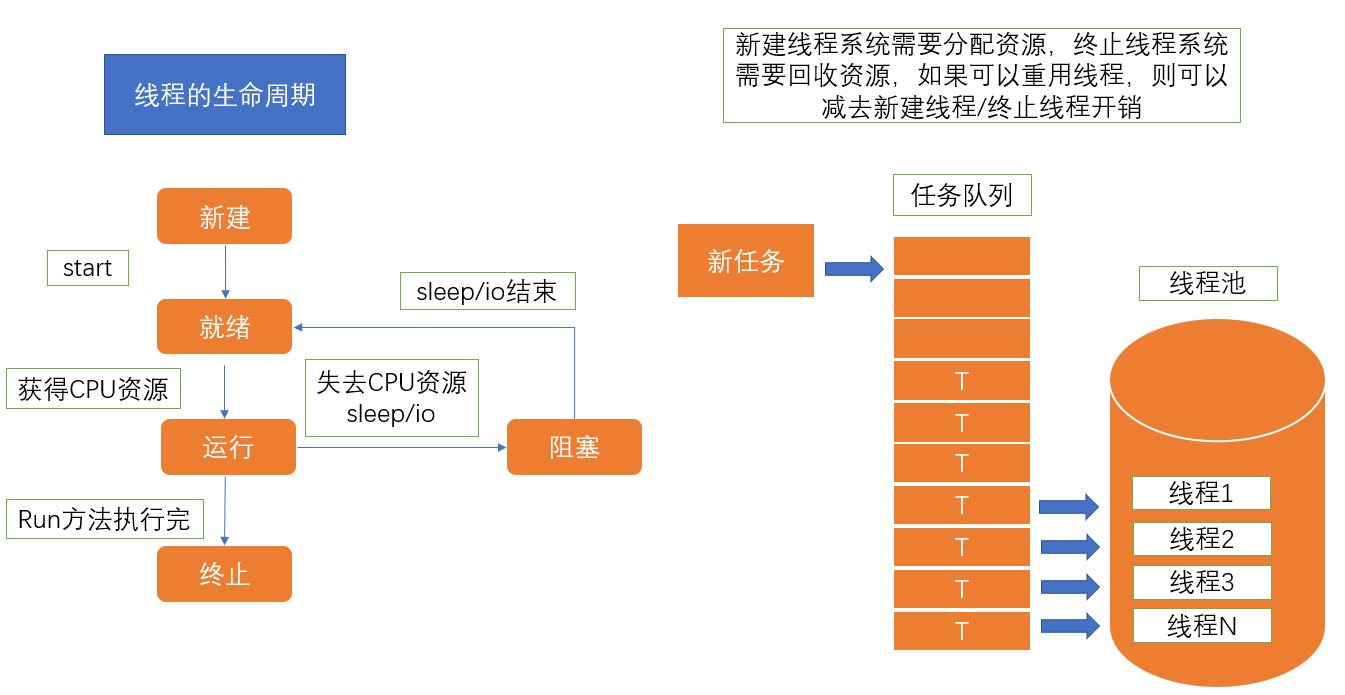
2、使用线程池的好处
①提升性能:因为减去了大量新建、终止线程的开销,重用了线程资源。
②适用场景:适合处理突发性大量请求或需要大量线程完成任务、但实际任务处理时间较短。
③防御功能:能有效避免系统因为创建线程过多,而导致系统负荷过大相应变慢等问题。
④代码优势:使用线程池的语法比自己新建线程执行线程更加简洁。
3、 ThreadPoolExecutor的使用语法

4、使用线程池改造爬虫程序
import concurrent.futures import requests from bs4 import BeautifulSoup urls = [] for i in range(2, 52): urls.append('https://www.cnblogs.com/#p{0}'.format(i)) def craw(url): r = requests.get(url) return r.text def parse(html): soup = BeautifulSoup(html, 'html.parser') links = soup.find_all('a', class_='post-item-title') return [(link['href'], link.get_text()) for link in links] with concurrent.futures.ThreadPoolExecutor() as pool: htmls = pool.map(craw, urls) htmls = list(zip(urls, htmls)) for url, html in htmls: pass print(url, len(html)) print('生产者:end') with concurrent.futures.ThreadPoolExecutor() as pool: futures = {} for url, html in htmls: future = pool.submit(parse, html) futures[future] = url for future, url in futures.items(): print(url, future.result()) print('消费者:end')
十三、Python使用线程池在web服务中实现加速
1、web服务的架构以及特点

web后台服务的特点:
①web服务对响应时间要求非常高,比如要求200ms返回
②web服务有大量的依赖IO操作的调用,比如磁盘文件、数据库、远程API
③web服务经常需要处理几万人、几百万人的同时请求
2、使用线程池ThreadPoolExecutor加速
使用线程池ThreadPoolExecutor的好处:
①方便的将磁盘文件、数据库、远程API的IO调用并发执行
②线程池的线程数目不会无限创建(导致系统挂掉),具有防御功能
import flask import json import time app = flask.Flask(__name__) def read_file(): time.sleep(0.1) return 'file_result' def read_db(): time.sleep(0.2) return 'db_result' def read_api(): time.sleep(0.3) return 'api_result' @app.route('/') def index(): result_file = read_file() result_db = read_db() result_api = read_api() return json.dumps({ 'result_file': result_file, 'result_db': result_db, 'result_api': result_api, }) if __name__ == '__main__': app.run()
运行程序,获取花费多长时间:

600多毫秒。windows可以下载postman软件来查看耗时。
然后下面我们采用此案城池来进行加速:
import flask import json import time from concurrent.futures import ThreadPoolExecutor app = flask.Flask(__name__) pool = ThreadPoolExecutor() def read_file(): time.sleep(0.1) return 'file_result' def read_db(): time.sleep(0.2) return 'db_result' def read_api(): time.sleep(0.3) return 'api_result' @app.route('/') def index(): result_file = pool.submit(read_file) result_db = pool.submit(read_db) result_api = pool.submit(read_api) return json.dumps({ 'result_file': result_file.result(), 'result_db': result_db.result(), 'result_api': result_api.result(), }) if __name__ == '__main__': app.run()
运行程序,获取花费多长时间:

300多毫秒,时间相比较加速了一倍。
十四、使用多进程multiprocessing加速
1、有了多线程threading,为什么还要用多进程multiprocessing
如果遇到了CPU密集型计算,多线程反而会降低执行速度。
mutilprocessing模块就是python为了解决GIL缺陷引入的一个模块,原理是用多进程在多CPU上并行执行。
2、多进程multiprocessing知识梳理(对比多线程threading)

3、代码实战:单线程、多线程、多进程对比CPU密集计算速度
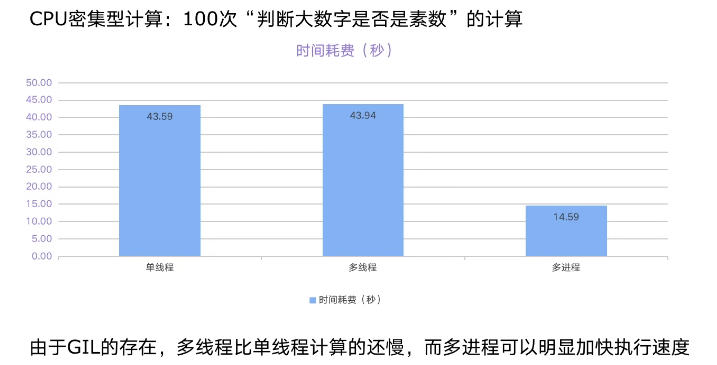
代码演示:计算一个cpu密集型任务,单线程、多线程、多进程三种方法执行的效率
import math import time from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor num_list = [112272535095293] * 100 # 判断一个数字是否为素数:cpu计算密集型任务 def is_prime(n): if n < 2: return False if n == 2: return True if n % 2 == 0: return False # 对此数字开根号 sqrt_n = int(math.floor(math.sqrt(n))) for i in range(3, sqrt_n + 1, 2): if n % i == 0: return False return True # 单线程 def single_thread(): for num in num_list: is_prime(num) # 多线程 def multi_thread(): with ThreadPoolExecutor() as pool: pool.map(is_prime, num_list) # 多进程 def multi_process(): with ProcessPoolExecutor() as pool: pool.map(is_prime, num_list) if __name__ == '__main__': start = time.time() single_thread() end = time.time() print('单线程:', end - start, '秒') start = time.time() multi_thread() end = time.time() print('多线程:', end - start, '秒') start = time.time() multi_process() end = time.time() print('多进程:', end - start, '秒')

运行程序,输出结果查看,多线程花费的时间比单进程花费的时间还多,多进程花费的时间相比就很快。
4、python在Flask项目中使用多进程池进行加速
import math import json import flask from concurrent.futures import ProcessPoolExecutor app = flask.Flask(__name__) # 判断一个数字是否为素数 def is_prime(n): if n < 2: return False if n == 2: return True if n % 2 == 0: return False # 对此数字开根号 sqrt_n = int(math.floor(math.sqrt(n))) for i in range(3, sqrt_n + 1, 2): if n % i == 0: return False return True @app.route('/is_prime/<num_list>') def api_is_prime(num_list): num_list = [int(x) for x in num_list.split(',')] result = pool.map(is_prime, num_list) return json.dumps(dict(zip(num_list, result))) if __name__ == '__main__': pool = ProcessPoolExecutor() app.run()
运行程序,访问:

十五、python异步IO实现并发爬虫
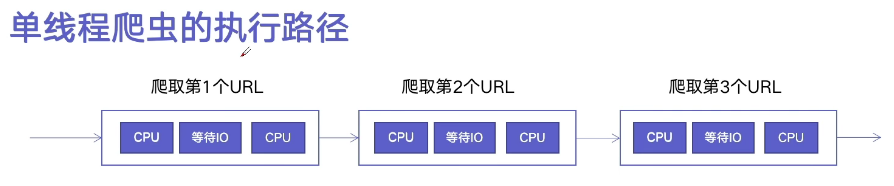
1、原理
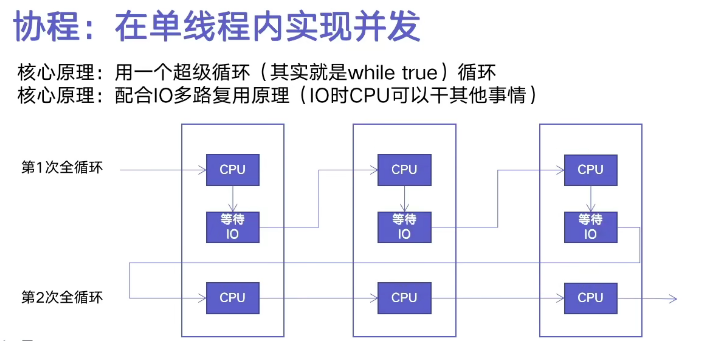
2、asyncio使用

代码演示:
import asyncio import aiohttp import time urls = [] for i in range(2, 52): urls.append('https://www.cnblogs.com/#p{0}'.format(i)) # 定义协程 async def async_craw(url): async with aiohttp.ClientSession() as session: async with session.get(url) as resp: result = await resp.text() print('craw url:', url, len(result)) loop = asyncio.get_event_loop() # 定义超级循环 tasks = [loop.create_task(async_craw(url)) for url in urls] start = time.time() loop.run_until_complete(asyncio.wait(tasks)) end = time.time() print('use time', end - start, '秒')
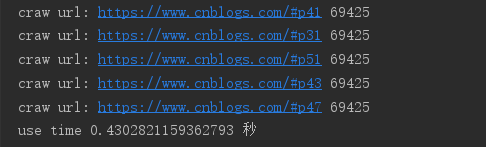
单线程异步爬虫花费的时间是0.4秒。之前我们演示的单线程爬虫耗时:8秒,和多线程爬虫耗时1秒(见章节九)
3、在异步IO中使用信号量控制爬虫并发度:信号量(Semaphore)
信号量(Semaphore):又称为信号量、旗语。是一个同步对象,用于保持在0至指定最大值之间的一个计数值。
当线程完成一次对该semaphore对象的等待(wait)时,该计数值减一。
当线程完成一次对semaphore对象的释放(release)时,计数值加一。
当计数值为0,则线程等待该semaphore对象不再能成功直至该semaphore对象变成signaled状态。
semaphore对象的计数值大于0,为signaled状态;计数值等于0,为nonsignaled状态。

代码演示:
import asyncio import aiohttp import time # 加入信号量,控制并发度 semaphore = asyncio.Semaphore(10) urls = [] for i in range(2, 52): urls.append('https://www.cnblogs.com/#p{0}'.format(i)) # 定义协程 async def async_craw(url): async with semaphore: async with aiohttp.ClientSession() as session: async with session.get(url) as resp: result = await resp.text() # 做演示,方便观察,睡3秒 await asyncio.sleep(3) print('craw url:', url, len(result)) loop = asyncio.get_event_loop() # 定义超级循环 tasks = [loop.create_task(async_craw(url)) for url in urls] start = time.time() loop.run_until_complete(asyncio.wait(tasks)) end = time.time() print('use time', end - start, '秒')
十六、python使用subprocess播放歌曲
1、介绍

2、使用

3、代码演示
播放歌曲:
import subprocess proc = subprocess.Popen( ['start', 'E:\My_Study\data\燕无歇-蒋雪儿.mp3'], shell=True ) proc.communicate()
运行程序,实现播放歌曲。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号