

爬虫小案例——爬取天猫
分析
天猫控制登录字段:
sort: 排序
s:起始第几个商品
如:http://list.tmall.com/search_product.htm?s=60&q=Ůװ&sort=s 跳转到登录页面
如果想正常访问,删除字段sort与s
http://list.tmall.com/search_product.htm?q=男装&totalPage=80&jumpto=3
q :控制搜索
totalPage: 总页数
jumpto : 跳转到第几页
获取商品信息分析
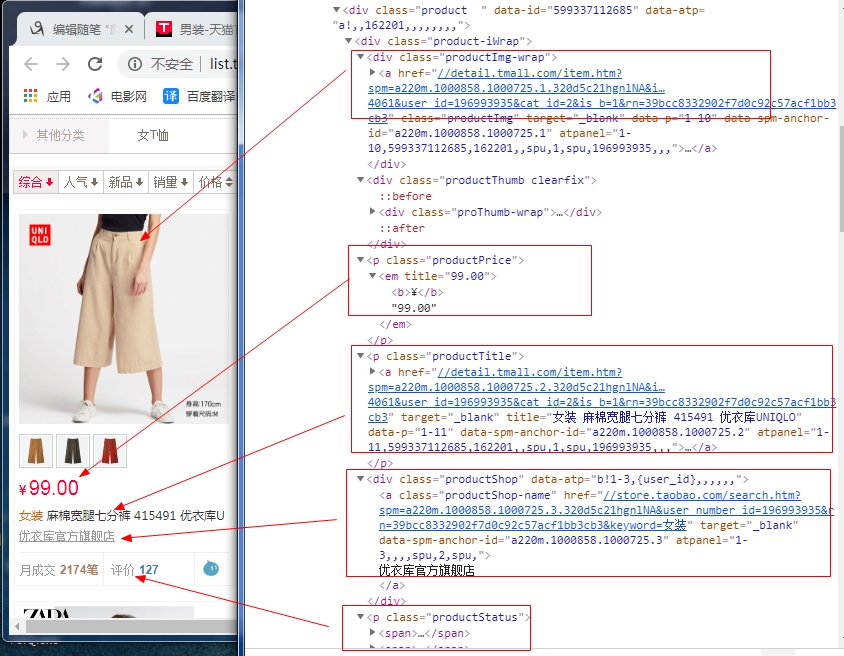
代码实现
keyword = input('请输入要爬取的商品:') params = { 'totalPage': 1, 'jumpto': 1, 'q': keyword } url = 'http://list.tmall.com/search_product.htm?' from requests_html import HTMLSession session = HTMLSession() # r = session.get(url=url, params=params) # # totalPage = int(r.html.find('[name="totalPage"]', first=True).attrs.get('value')) # 获取总页数 # params['totalPage'] = totalPage # 更新总页数 # # # 拼出所有的url # for i in range(1, totalPage+1): # params['jumpto'] = i # r = session.get(url=url, params=params) # print(r.url) def get_totalPage(params, url): r = session.get(url=url, params=params) totalPage = int(r.html.find('[name="totalPage"]', first=True).attrs.get('value')) # 获取总页数 params['totalPage'] = totalPage # 更新总页数 def get_params(params, totalPage): for i in range(1, totalPage + 1): params['jumpto'] = i yield params def get_product_info(params, url): r = session.get(url=url, params=params) # print(r.url) # 每一页的url product_element_list = r.html.find('.product') for product_element in product_element_list: product_img_url = product_element.find('img', first=True).attrs.get('src') product_detail_url = product_element.find('a', first=True).attrs.get('href') product_price = product_element.find('em', first=True).attrs.get('title') product_title = product_element.find('[class=productTitle] a', first=True).attrs.get('title') product_shopper = product_element.find('[class=productShop] a', first=True).text product_shopper_url = product_element.find('[class=productShop] a', first=True).attrs.get('href') product_sell = product_element.find('[class=productStatus] em', first=True).text product_comment_num = product_element.find('[class=productStatus] a', first=True).text product_comment_url = product_element.find('[class=productStatus] a', first=True).attrs.get('href') print(product_img_url) # 商品图片url print(product_detail_url) # 商品详情url print(product_price) # 商品价格 print(product_title) # 商品标题 print(product_shopper) # 商家 print(product_shopper_url) # 商家url print(product_sell) # 卖出数 print(product_comment_num) # 评论数 print(product_comment_url) # 评论数url get_totalPage(params, url) for params in get_params(params, params['totalPage']): try: get_product_info(params, url) except: pass
打印结果
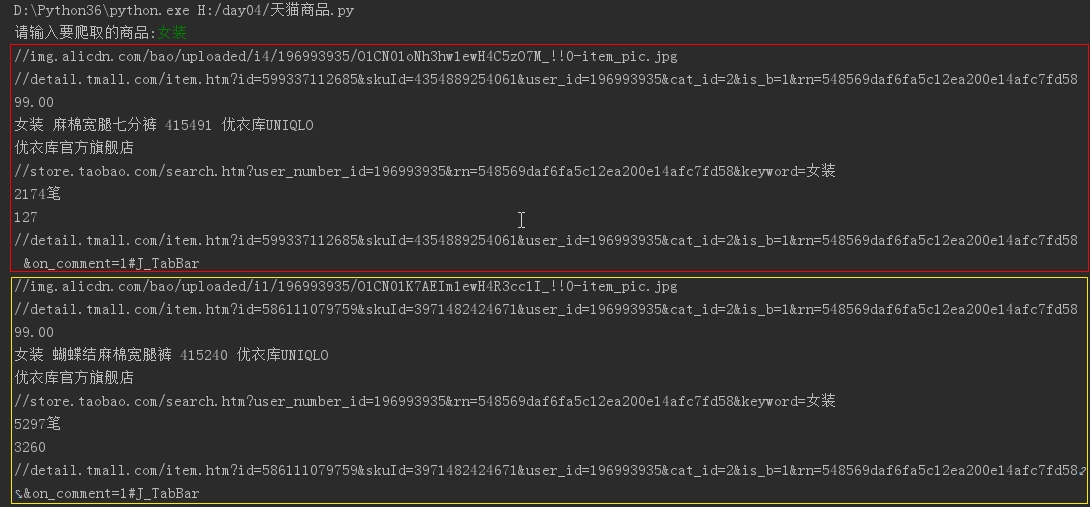

 浙公网安备 33010602011771号
浙公网安备 33010602011771号