

爬虫基础相关
一、什么是爬虫
互联网就像一张蜘蛛网,爬虫相当于蜘蛛,数据相当于猎物
2、爬虫的具体定义:
模拟浏览器向后端发送请求,获取数据,解析并且获得我想要的数据,然后存储
3、爬虫的价值:
数据的价值
发送请求(requests)——获取数据——解析数据(bs4,pyquery,re)——存储数据
二、
1、请求
url:指明了我要去哪里
method:
get:传递数据:?&拼在url后面
post:请求体:formdata,files,json
请求头:
Cookie:验证用户的登录
Referer:告诉服务器你从哪里来(例子:图片防盗链)
User-Agent:告诉服务器你的身份
2、响应
Status Code状态码:
2xx:成功
3xx:重定向
响应头:
location

响应对象 = requests.get(......) 参数: url headers = {} # headers里面的Cookie优先级高于cookies cookies = {} params = {} # 参数 proxies = {'http':‘http://端口:ip’} # 代理ip timeout = 0.5 # 超时时间 allow_redirects = False # 允许重定向,不写默认是True。设置成False,不允许重定向
代码
import requests from requests.exceptions import ConnectTimeout url = 'http://httpbin.org/get' # url = 'http://www.baidu.com' headers = { 'Referer': 'https://baike.baidu.com/item/%E8%8B%8D%E4%BA%95%E7%A9%BA%E6%95%88%E5%BA%94/6527087?fr=aladdin', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36', 'Cookie': 'egon' } cookies = { 'xxx': 'dsb', 'yyy': 'hahaha', } params = { 'name': 'mac', 'age': '16' } try: r = requests.get(url=url, headers=headers, cookies=cookies, params=params, timeout=5) print(r.text) # r = requests.get(url=url, headers=headers, cookies=cookies, params=params, allow_redirects=False) # print(r.url) except ConnectTimeout: print('进行其他操作')
打印结果
{ "args": { "age": "16", "name": "mac" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Cookie": "egon", "Host": "httpbin.org", "Referer": "https://baike.baidu.com/item/%E8%8B%8D%E4%BA%95%E7%A9%BA%E6%95%88%E5%BA%94/6527087?fr=aladdin", "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36" }, "origin": "223.167.30.218, 223.167.30.218", "url": "https://httpbin.org/get?name=mac&age=16" }
响应对象 = requests.post(......) 参数: url headers = {} cookies = {} data = {} json = {} files = {‘file’:open(...,‘rb’)} timeout = 0.5 allow_redirects = False
代码
import requests from requests.exceptions import ConnectTimeout url = 'http://httpbin.org/post' # url = 'http://www.baidu.com' headers = { 'Referer': 'https://baike.baidu.com/item/%E8%8B%8D%E4%BA%95%E7%A9%BA%E6%95%88%E5%BA%94/6527087?fr=aladdin', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36', 'Cookie': 'egon' } cookies = { 'xxx': 'dsb', 'yyy': 'hahaha', } data = { 'name': 'mac', 'password': 'abc123' } json = { 'xxx': 'xxx', 'yyy': 'yyy' } files = { 'file': open('1.txt', 'rb') } try: # r = requests.post(url=url, headers=headers, cookies=cookies, data=data, timeout=5) # data=data模拟form表单 # r = requests.post(url=url, headers=headers, cookies=cookies, json=json, timeout=5) # json=json发json数据 r = requests.post(url=url, headers=headers, cookies=cookies, data=data, files=files, timeout=5) # 模拟注册 print(r.text) # r = requests.get(url=url, headers=headers, cookies=cookies, data=data, allow_redirects=False) # print(r.url) except ConnectTimeout: print('进行其他操作')
打印结果
{ "args": {}, "data": "", "files": { "file": "abcdefghijklmn" }, "form": { "name": "mac", "password": "abc123" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "338", "Content-Type": "multipart/form-data; boundary=c7c8c676d7f232259827977daaa20412", "Cookie": "egon", "Host": "httpbin.org", "Referer": "https://baike.baidu.com/item/%E8%8B%8D%E4%BA%95%E7%A9%BA%E6%95%88%E5%BA%94/6527087?fr=aladdin", "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36" }, "json": null, "origin": "223.167.30.218, 223.167.30.218", "url": "https://httpbin.org/post" }
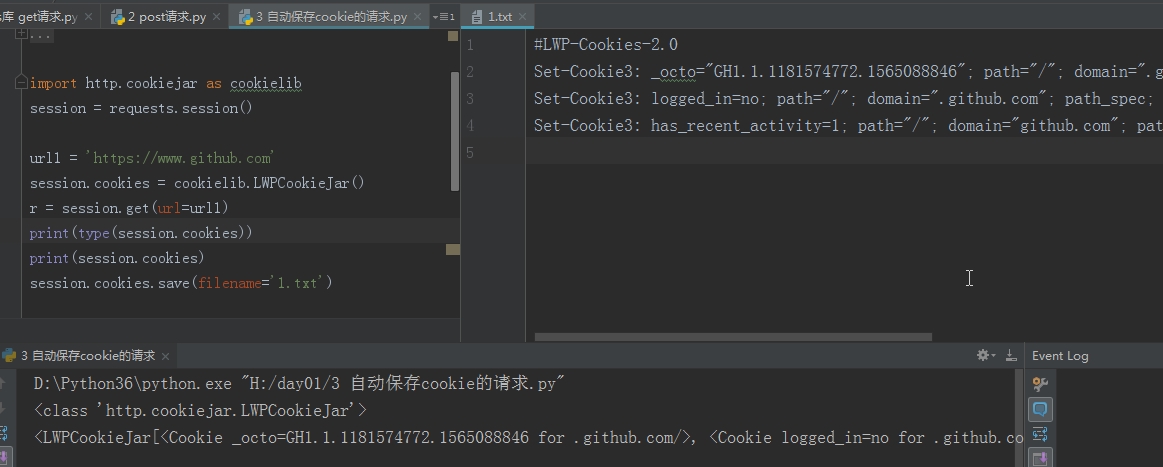
自动保存cookie的请求
import requests session = requests.session() # 记录每一次请求的cookie url1 = 'https://www.lagou.com' r = session.get(url=url1) print(session.cookies) url2 = 'https://www.github.com' r2 = session.get(url=url2) print(session.cookies) 结果为: # <RequestsCookieJar[<Cookie JSESSIONID=ABAAABAABEEAAJA52562AD095370A108C9943E2088FDB22 for www.lagou.com/>]> # <RequestsCookieJar[<Cookie _octo=GH1.1.1145368561.1565088576 for .github.com/>, <Cookie logged_in=no for .github.com/>, <Cookie _gh_sess=YXhBUXgrcFNyWUFJOWNJdmtzYk9yT1l6WUVzR0xlTFIxVGhPbzBma05NZkI0M056aHdickh2STY2VDA5Q09VdHN4WFlGNW1waVAzaEVVMXl0dElqVTN1SXowNnQ5TmNsMTg4QVBicTc3Sko1QXhyY01lVTd5Yk1ad0d2U01Bbm1saFJCZnFxY2ZzeitKNWo1Z09QQ1ZVZy9IYkpCenFZdE1hTndSZHl5alQvSFd2RGtUTkJ5a2RyTjhhdkgxbjdyR2JtTlpLdzI1bTBFR2c0WjZPUzJCdz09LS1ZdVNtbjJaR2l6TzVRNE1aRXkvR0lBPT0%3D--5b92d0e4c31fe84e0a2acddc3c0529d863867c1c for github.com/>, <Cookie has_recent_activity=1 for github.com/>, <Cookie JSESSIONID=ABAAABAABEEAAJA52562AD095370A108C9943E2088FDB22 for www.lagou.com/>]>
补充:保存cookie到本地
r.url r.text r.encoding = 'UTF-8' r.content r.json() r.status_code r.headers r.cookies r.history
代码
import requests session = requests.session() r = session.get('https://www.baidu.com') r.encoding = 'UTF-8' # 指定编码格式,不指定会乱码 print(r.text) r = session.get(url='https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=20') print(r.text) print(r.json()) # 转成python格式 print(r.status_code) r = session.get('http://www.tmall.com') print(r.url) # https://www.tmall.com/ print(r.status_code) # 200 print(r.history[0].status_code) # 302
1、类选择器 2、id选择器 3、标签选择器 4、后代选择器 5、子选择器 6、属性选择器 7、群组选择器 8、多条件选择器
from requests_html import HTMLSession session = HTMLSession() r = session.get('https://www.baidu.com') r = session.post('https://www.baidu.com') r = session.request(url='https://www.baidu.com', method='get')
from requests_html import HTMLSession session = HTMLSession() # r = session.get('http://www.xiaohuar.com/p-1-2077.html') # print(r.html.absolute_links) # 绝对链接 # print(r.html.links) # 原样链接 # print(r.html.base_url) # 基础链接 r = session.get('http://www.xiaohuar.com/p-3-230.html') r.html.encoding = 'GBK' # 不指定会乱码 # print(r.html.html) # print(r.html.text) # 文本内容 # print(r.html.raw_html) # 二进制流 # print(r.html.pq) # pyquery
html对象方法
r.html.find('css选择器') # [element对象,element对象,element对象] r.html.find('css选择器',first = True) # element对象 r.html.search(‘模板’) # result对象 r.html.search_all('模板') # [result对象,result对象,result对象]
from requests_html import HTMLSession session = HTMLSession() url = 'https://www.183xsw.com/6_6116/' r = session.request(method='get', url=url) # print(r.html.html) # print(r.html.find('dd')) # print(r.html.find('dd', first=True)) # print(r.html.find('dd a')) # dd下所有的a标签 # for a_element in r.html.find('dd a'): # print(dir(a_element)) # print(a_element.absolute_links) # 拿到所有a标签的超链接 # 提示:已启用缓存技术,最新章节可能会延时显示,登录书架即可实时查看。 # print(r.html.search('提示:{},最新章节可能会{},登录书架即可实时查看')[0]) # 已启用缓存技术 # print(r.html.search('提示:{},最新章节可能会{},登录书架即可实时查看')[1]) # 延时显示 # print(r.html.search('提示:{name},最新章节可能会{pwd},登录书架即可实时查看')['name']) # 已启用缓存技术
render用法
调用render,启用浏览器内核,需要下载chromium
参数: scripy:'''( ) => { js代码 js代码 } ''' scrolldow:n # 翻页 sleep:n # 渲染完成停n秒 keep_page:True/False # 允许和浏览器进行交互
代码
from requests_html import HTMLSession session = HTMLSession( browser_args=[ # 设置浏览器的启动参数 '--no-sand', '--user-agent=Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36' ], headless=False ) # url = 'https://www.baidu.com' # url = 'https://www.httpbin.org/get' url = 'https://www.csdn.net/' r = session.request(method='get', url=url) scripts = """ ()=>{ # 反扒设置 Object.defineProperties(navigator,{ navigator.webdriver webdriver:{ get: () => undefined } }) } """ # r.html.render() # 调用render,启用浏览器内核,对浏览器进行渲染 print(r.html.html) # print(r.html.render(script=scripts, scrolldown=10, sleep=1)) # scrolldown翻页 print(r.html.render(script=scripts, sleep=30)) # 渲染完停10秒
.screenshot({'path':路径})
.evaluate('''() =>{js代码}'''}) # js注入
.cookies()
.type('css选择器',’内容‘,{’delay‘:100}) # input框里注入内容
click('css选择器') # 点击
.focus('css选择器') # 聚焦
.hover('css选择器') # 悬浮
.waitForSelector('css选择器') # 等待元素被加载
.waitFor(1000) # 等待1秒
代码
from requests_html import HTMLSession session = HTMLSession( browser_args=[ # 设置浏览器的启动参数 '--no-sand', '--user-agent=Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36' ], headless=False ) # url = 'https://www.baidu.com' # url = 'https://www.httpbin.org/get' # url = 'https://www.csdn.net/' # url = 'https://www.183xsw.com/6_6116/' # url = 'https://www.zhihu.com/signin?next=%2F' url = 'https://www.mi.com/' r = session.request(method='get', url=url) scripts = """ ()=>{ Object.defineProperties(navigator,{ webdriver:{ get: () => undefined } }) } """ try: r.html.render(script=scripts, sleep=3, keep_page=True) async def main(): # 定义一个协程函数 # await r.html.page.screenshot({'path': '1.png'}) # await r.html.page.screenshot({'path': '2.png', 'clip': {'x': 200, 'y': 200, 'width': 400, 'height': 400}}) # # # evaluate: js注入, 获取坐标 # res = await r.html.page.evaluate(''' # ()=>{ # var a = document.querySelector("#list") # return {'x':a.offsetLeft} # } # ''') # print(res) # # # 拿到当前的cookie # print(await r.html.page.cookies()) # input框里注入内容 # await r.html.page.type('#kw', '泷泽萝拉', {'delay': 500}) # await r.html.page.waitForSelector('[name="tj_trnews"]') # 等待元素被加载 # # 点击 # await r.html.page.click('[name="tj_trnews"]') # # 聚焦 # await r.html.page.focus('[type="number"]') # # 键盘输入 # await r.html.page.keyboard.type('111111', {'delay': 200}) # 悬浮 # await r.html.page.hover('[data-stat-id="6f5c93b4d1baf5e9"]') await r.html.page.waitFor(10000) # 等待5秒 session.loop.run_until_complete(main()) finally: session.close()
键盘事件 r.html.page.keyboard.XXX
.down('Shift') .up('Shift') .press('ArrowLeft') .type('喜欢你啊',{‘delay’:100})
代码
from requests_html import HTMLSession session = HTMLSession( browser_args=[ # 设置浏览器的启动参数 '--no-sand', '--user-agent=Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36' ], headless=False ) url = 'https://www.baidu.com' r = session.request(method='get', url=url) scripts = """ ()=>{ Object.defineProperties(navigator,{ webdriver:{ get: () => undefined } }) } """ try: r.html.render(script=scripts, sleep=3, keep_page=True) async def main(): # 定义一个协程函数 # input框录入 await r.html.page.keyboard.type('喜欢你啊啊啊', {'delay': 200}) # 按住 await r.html.page.keyboard.down('Shift') for i in range(3): await r.html.page.keyboard.press('ArrowLeft', {'delay': 1000}) # 抬起来 await r.html.page.keyboard.up('Shift') # 删除 await r.html.page.keyboard.press('Backspace') await r.html.page.waitFor(10000) # 等待5秒 session.loop.run_until_complete(main()) finally: session.close()
鼠标事件 r.html.page.mouse.XXX
.click(x,y,{ 'button':'left', 'click':1 'delay':0 }) .down({'button':'left'}) .up({'button':'left'}) .move(x,y,{'steps':1})
代码
from requests_html import HTMLSession session = HTMLSession( browser_args=[ # 设置浏览器的启动参数 '--no-sand', '--user-agent=Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36' ], headless=False ) url = 'https://www.bilibili.com/' r = session.request(method='get', url=url) scripts = """ ()=>{ Object.defineProperties(navigator,{ webdriver:{ get: () => undefined } }) } """ try: r.html.render(script=scripts, sleep=3, keep_page=True) async def main(): # 定义一个协程函数 res = await r.html.page.evaluate(''' ()=>{ var a = document.querySelector('[alt="【服装配布】伪·2nd Season Spring 初音-Cute Medley Idol Sounds"]') return { 'x':a.x+a.width/2, 'y':a.y+a.height/2 } } ''') print(res) # await r.html.page.mouse.move(res['x'], res['y'], {'steps': 200}) # await r.html.page.mouse.down({'button': 'right'}) # 用左键还是右键打开, 默认左键left # await r.html.page.mouse.up({'button': 'right'}) await r.html.page.mouse.click(res['x'], res['y']) # 点击事件 await r.html.page.waitFor(10000) # 等待5秒 session.loop.run_until_complete(main()) finally: session.close()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现