

SQL查询操作
语法执行顺序:

书写顺序
select distinct * from '表名' where '限制条件' group by '分组依据' having '过滤条件' order by limit;
执行顺序
from
where
group by
having
order by
limit
distinct
select
一、单表查询
先建立表格
create table emp(
id int not null unique auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int,
depart_id int
);
插入数据,三个部门:教学,销售,运营
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values
('jason','male',18,'20170301','张江第一帅形象代言',7300.33,401,1), # 以下是教学部
('egon','male',78,'20150302','teacher',1000000.31,401,1),
('kevin','male',81,'20130305','teacher',8300,401,1),
('tank','male',73,'20140701','teacher',3500,401,1),
('owen','male',28,'20121101','teacher',2100,401,1),
('jerry','female',18,'20110211','teacher',9000,401,1),
('nick','male',18,'19000301','teacher',30000,401,1),
('sean','male',48,'20101111','teacher',10000,401,1),
('歪歪','female',48,'20150311','sale',3000.13,402,2), # 以下是销售部门
('丫丫','female',38,'20101101','sale',2000.35,402,2),
('丁丁','female',18,'20110312','sale',1000.37,402,2),
('星星','female',18,'20160513','sale',3000.29,402,2),
('格格','female',28,'20170127','sale',4000.33,402,2),
('张野','male',28,'20160311','operation',10000.13,403,3), # 以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3)
;
1、where:查询
①查询id大于等于3小于等于6的数据
select * from emp where id between 3 and 6;
②查询薪资是20000或者18000或者17000的数据
select * from emp where salary in (20000,18000,17000);
③查询员工姓名中包含o字母的员工姓名和薪资
select name,salary from emp where name like '%o%';
补充:like模糊查询 %:匹配任意数量的任意字符
_:匹配单个数量的任意字符
查询名字为四个字符的员工信息
select * from emp where name like '____';
select * from emp where char_length(name) = 4; ④查询id小于3或者大于6的数据 select * from emp where id not between 3 and 6; ⑤查询薪资不在20000,18000,17000范围的数据 select * from emp where salary not in (20000,18000,17000); ⑥查询岗位描述为空的员工名与岗位名:针对null不能用等号,只能用is select name,post from emp where post_comment is null;
2、group by:分组
应用场景:每个部门的平均薪资,男女比例等
①按部门分组
select * from emp group by post; # 报错
强调:只要分组了,就不能够再“直接”查找到单个数据信息了,只能获取到组名
select post from emp group by post;
②获取每个部门的最高工资
select post,max(salary) from emp group by post;
每个部门的最低工资
select post,min(salary) from emp group by post;
每个部门的平均工资
select post,avg(salary) from emp group by post;
每个部门的工资总和
select post,sum(salary) from emp group by post;
每个部门的人数
select post,count(id) from emp group by post;
③查询分组之后的部门名称和每个部门下所有的学生姓名
group_concat(分组之后用)不仅可以用来显示除分组外字段还有拼接字符串的作用
select post,group_concat(name) from emp group by post;
select post,group_concat(name,'sb') from emp group by post;
④补充concat(不分组时用)拼接字符串达到更好的显示效果 as语法使用
select concat(name,':',age,':',sex,':',post) from emp;
select concat(name,':',age) as info from emp;
select concat(':',name,age,post) from emp;
select concat('name:',name) as NAME,concat('age:',age) as AGE from emp;
补充as语法 即可以给字段起别名也可以给表起
select t1.id,t1.name from emp as t1;
⑤查询每个人的年薪
select name,salary*12 as annual_salary from emp;
⑥查询公司内男员工和女员工的个数
select sex,count(id) from emp group by sex;
⑦查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
select sex,avg(salary) from emp group by sex;
⑧关键字where group by同时出现的情况下,group by必须在where之后
where先对整张表进行一次筛选,如何group by再对筛选过后的表进行分组
⑨统计各部门年龄在30岁以上的员工平均工资
select post,avg(salary) from emp where age>30 group by post;
3、having:限制条件,用在group by后
having的语法格式与where一致,只不过having是在分组之后进行的过滤, 即where虽然不能用聚合函数,但是having可以!
统计各部门年龄在30岁以上的员工平均工资,并且保留平均工资大于10000的部门
select post,avg(salary) from emp where age>30 group by post having avg(salary)>10000 ;
4、distinct:去重
对有重复的展示数据进行去重操作
select distinct post from emp;
5、order by:排序
①工资升序
select * from emp order by salary asc;
②工资降序
select * from emp order by salary desc;
③升序,年龄一样,按薪资排
select * from emp order by age,salary asc;
④统计各部门年龄在10岁以上的员工平均工资,并且保留平均工资大于1000的部门,然后对平均工资进行排序
select post,avg(salary) from emp where age>10 group by post having avg(salary)>1000 order by avg(salary) asc;
6、limit:限制查询条件
①限制展示条数
select * from emp limit 5;
②分页显示
如果写了俩参数,第一个参数表示起始位置,第二个参数表示的从第一个参数的位置开始往后获取的数据个数
select * from emp limit 5,5; (起始位置,显示个数)
③查询工资最高的人的详细信息
select * from emp order by salary desc limit 1;
7、regexp:正则
贪婪匹配与非贪婪匹配:.* .*?
查询以j开头,以n或y结尾,尽可能多的匹配
select * from emp where name regexp '^j.*(n|y)$';
二、多表查询
先创建表格:
create table dep(
id int,
name varchar(16)
);
create table emp_1(
id int primary key auto_increment,
name varchar(16),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
再插入数据:
insert into dep values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营');
insert into emp_1(name,sex,age,dep_id) values
('jason','male',18,200),
('egon','female',48,201),
('keven','male',38,201),
('owen','male',15,202),
('jerry','male',25,204);
了解:
笛卡尔积:
左表的一条记录与右表所有记录都对应一遍
select * from emp_1,dep;
1、内连接:只取两张表有对应关系的记录 inner join
select * from emp_1 inner join dep on emp_1.dep_id=dep.id;
2、左连接:在内连接的基础上保留左表没有对应关系的记录 left join
select * from emp_1 left join dep on emp_1.dep_id=dep.id;
3、右连接:在内连接的基础上保留右表没有对应关系的记录 right join
select * from emp_1 right join dep on emp_1.dep_id=dep.id;
4、全连接:在内连接的基础上保留左、右面表没有对应关系的的记录 union
select * from emp_1 left join dep on emp_1.dep_id=dep.id;
union
select * from emp_1 right join dep on emp_1.dep_id=dep.id;
5、子查询
就是将一个查询语句的结果用括号括起来当作另外一个查询语句的条件去用
记住一个规律,表的查询结果可以作为其他表的查询条件,也可以通过其别名的方式把它作为一张虚拟表去跟其他表做关联查询
1、查询部门是技术或者人力资源的员工信息
先获取技术部和人力资源部的id号,再去员工表里面根据前面的id筛选出符合要求的员工信息
select * from emp where dep_id in (select id from dep where name = "技术" or name = "人力资源");
2、每个部门最新入职的员工 思路:先查每个部门最新入职的员工,再按部门对应上联表查询
select t1.id,t1.name,t1.hire_date,t1.post,t2.* from emp as t1
inner join
(select post,max(hire_date) as max_date from emp group by post) as t2
on t1.post = t2.post
where t1.hire_date = t2.max_date
查询部门是技术或者人力资源的员工信息
select * from emp_1 where dep_id in (select id from dep where name in ('技术','人力资源'));
6、exist(了解)
exist关字键字表示存在。在使用exist关键字时,内层查询语句不返回查询的记录,
而是返回一个真假值,True或False。
当返回True时,外层查询语句将进行查询
当返回值为False时,外层查询语句不进行查询。
select * from emp where exists (select * from dep where 1=2);
select * from emp where exists (select * from dep where id >1);
三、函数
1、常用函数



2、聚合函数
计数:count()
求和:sum()
平均值:avg()
最大值:max()
最小值:min()
获取每个部门的最高工资
select post,max(salary) from emp group by post;
每个部门的最低工资
select post,min(salary) from emp group by post;
每个部门的平均工资
select post,avg(salary) from emp group by post;
每个部门的工资总和
select post,sum(salary) from emp group by post;
每个部门的人数
select post,count(id) from emp group by post;
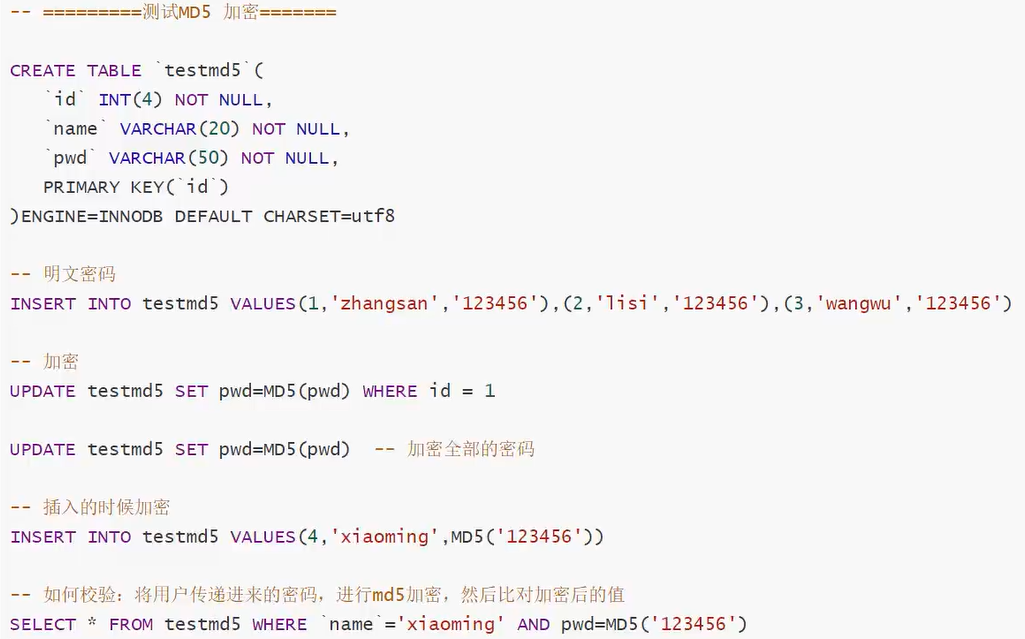
四、数据库级别的MD5加密


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现