

线程
一、线程理论
线程:是计算机中可以被cpu调度的最小单元。
进程:是计算机资源分配的最小单元,进程为线程提供资源。
一个进程汇总可以有多个线程,同一个进程中的线程可以共享此进程中的资源。
在python中,如果执行一个程序,默认情况下会创建一个进程,在一个进程中又会创建一个线程,线程是真正工作的单位,进程是为线程提供资源的单位。

类比:
一个工厂,至少有一个车间,一个车间中至少有一个工人,最终是工人在工作。
一个程序,至少有一个进程,一个进程中至少有一个线程,最终是线程在工作。
result = 0
for i in range(10000):
result += i
print(result)
上述串行的代码示例就是一个程序,在使用python xx.py运行时,内部就创建一个进程(主进程),在进程中创建一个线程(主线程),由线程运行代码。
以前我们开发的程序中所有的行为都只能通过串行的形式运行,排队逐一执行,前面未完成,后面也无法执行。
通过进程和线程都可以将串行的程序变为并发。
1、什么是线程
进程:资源单位
线程:执行单位
注意:每一个进程中都会自带一个线程
拿一个工厂中车间里的流水线作比喻
进程比喻为车间
线程比喻为流水线
操作系统比喻为工厂
2、为什么要有线程
开一个进程: 申请内存空间 --->>> 耗时 将代码拷贝到申请的内存空间中 --->>> 耗时 开线程:不需要申请内存空间 不需要拷贝代码
3、进程vs线程
①同一进程内的多个线程共享该进程内的资源,不同进程内的线程资源是隔离的
②创建线程的开销比创建进程小
二、创建线程的两种方式
1、方式一
from threading import Thread import time def task(name): print('%s is running' % name) time.sleep(1) if __name__ == '__main__': t = Thread(target=task, args=('egon',)) t.start() # 开启线程的速度非常快,几乎代码执行完线程就已经开启 print('主') # 结果为 egon is running 主
2、方式二
from threading import Thread import time class MyThread(Thread): def __init__(self, name): super().__init__() self.name = name def run(self): print('%s is running' % self.name) time.sleep(1)if __name__ == '__main__': t = MyThread('jason') t.start() print('主') # 结果为 jason is running 主
三、线程之间数据共享
from threading import Thread x = 100 def task(): global x x = 20if __name__ == '__main__': t = Thread(target=task) # 实例化一个对象 t.start() t.join() print(x) # 结果为 20
四、线程对象其他方法
from threading import Thread, current_thread, active_count import os import time def task(name): print('%s is running' %name, os.getpid(), current_thread().name) time.sleep(2) print('%s is over' % name) def info(name): print('%s is running' % name, os.getpid(), current_thread().name) time.sleep(2) print('%s is over' % name) if __name__ == '__main__': t1 = Thread(target=task, args=('jerry',)) t2 = Thread(target=info, args=('tom',)) t1.start() t2.start() t1.join() print(active_count()) # 当前存活的线程数 print(os.getpid()) # id号 print(current_thread().name) # 线程名字 # 结果为 jerry is running 7448 Thread-1 tom is running 7448 Thread-2 jerry is over 2 7448 MainThread tom is over
五、守护线程
主线程必须等待所有非守护线程的结束才能结束
from threading import Thread import time def task(name): print('%s is running' % name) time.sleep(1) if __name__ == '__main__': t = Thread(target=task, args=('jerry',)) t.daemon = True # t.daemon = True: 主线程运行完不会检查子线程程的状态(是否执行完),直接结束进程; t.start() print('主线程') # 结果为 jerry is running 主线程
六、python线程安全问题以及解决方法(加锁Lock)
如果你学过操作系统,那么对于锁应该不陌生。锁的含义是线程锁,可以用来指定某一个逻辑或者是资源同一时刻只能有一个线程访问。这个很好理解,就好像是有一个房间被一把锁锁住了,只有拿到钥匙的人才能进入。每一个人从房间门口拿到钥匙进入房间,出房间的时候会把钥匙再放回到门口。这样下一个到门口的人就可以拿到钥匙了。这里的房间就是某一个资源或者是一段逻辑,而拿取钥匙的人其实指的是一个线程。
加锁的原因以及应用场景
举一个非常简单的例子,就是淘宝买东西。我们都知道商家的库存都是有限的,卖掉一个少一个。假如说当前某个商品库存只剩下一个,但当下却有两个人同时购买。两个人同时购买也就是有两个请求同时发起购买请求,
如果我们不加锁的话,两个线程同时查询到商品的库存是1,大于0,进行购买逻辑之后,同时减一。由于两个线程同时执行,所以最后商品的库存会变成-1。显然商品的库存不应该是一个负数,所以我们需要避免这种情况发生。
通过加锁可以完美解决这个问题。我们规定一次只能有一个线程发起购买的请求,那么这样当一个线程将库存减到0的时候,第二个请求就无法修改了,就保证了数据的准确性。
错误的代码
import threading import time class Account: def __init__(self, balance): self.balance = balance def draw(account, amount): if account.balance >= amount: time.sleep(1) print(threading.current_thread().name, '取钱成功') account.balance -= amount print(threading.current_thread().name, '余额', account.balance) else: print(threading.current_thread().name, '取钱失败,余额不足') if __name__ == '__main__': account = Account(1000) ta = threading.Thread(name='ta', target=draw, args=(account, 800)) tb = threading.Thread(name='tb', target=draw, args=(account, 800)) ta.start() tb.start()
打印结果:
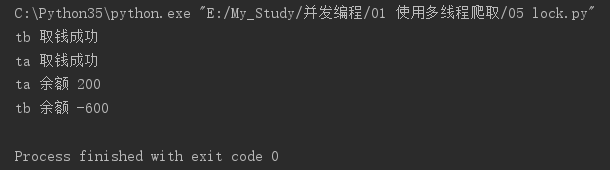
发现执行的是错误的结果。开启了两个线程,去取钱,第一个线程去取钱(1000-800)还剩200,第二个线程取钱应该执行的是else后面的代码,打印余额不足才对。但是因为多个线程去执行时会发生线程切换,当第一个线程在减去余额之前,切换了第二个线程去取钱,这个时候,账户还是1000元,这就是线程安全问题。
加锁代码实现(Lock用于解决线程安全问题)
其实很简单,threading库当中已经为我们提供了线程的工具,我们直接拿过来用就可以了。我们通过使用threading当中的Lock对象, 可以很轻易的实现方法加锁的功能。
import threading import time lock = threading.Lock() # 涉及到多个线程或者进程操作同一份数据的时候,通常都需要将并行、并发变成串行,虽然牺牲了效率,但是提升了数据的安全性 class Account: def __init__(self, balance): self.balance = balance def draw(account, amount): lock.acquire() if account.balance >= amount: time.sleep(1) print(threading.current_thread().name, '取钱成功') account.balance -= amount print(threading.current_thread().name, '余额', account.balance) else: print(threading.current_thread().name, '取钱失败,余额不足') lock.release() if __name__ == '__main__': account = Account(1000) ta = threading.Thread(name='ta', target=draw, args=(account, 800)) tb = threading.Thread(name='tb', target=draw, args=(account, 800)) ta.start() tb.start()
我们从代码当中就可以很轻易的看出Lock这个对象的使用方法,我们在进入加锁区(资源抢占区)之前,我们需要先使用lock.acquire()方法获取锁。Lock对象可以保证同一时刻只能有一个线程获取锁,只有获取了锁之后才会继续往下执行。当我们执行完成之后,我们需要把锁“放回门口”,所以需要再调用一下release方法,表示锁的释放。
这里有一个小问题是很多程序员在编程的时候总是会忘记release,导致不必要的bug,而且这种分布式场景当中的bug很难通过测试发现。因为测试的时候往往很难测试并发场景,code review的时候也很容易忽略,因此一旦泄露了还是挺难发现的。
为了解决这个问题,Lock还提供了一种改进的用法,就是使用with语句。with语句我们之前在使用文件的时候用到过,使用with可以替我们完成try catch以及资源回收等工作,我们只管用就完事了。这里也是一样,使用with之后我们就可以不用管锁的申请和释放了,直接写代码就行,所以上面的代码可以改写成这样:
import threading import time lock = threading.Lock() # 涉及到多个线程或者进程操作同一份数据的时候,通常都需要将并行、并发变成串行,虽然牺牲了效率,但是提升了数据的安全性 class Account: def __init__(self, balance): self.balance = balance def draw(account, amount): with lock: if account.balance >= amount: time.sleep(1) print(threading.current_thread().name, '取钱成功') account.balance -= amount print(threading.current_thread().name, '余额', account.balance) else: print(threading.current_thread().name, '取钱失败,余额不足') if __name__ == '__main__': account = Account(1000) ta = threading.Thread(name='ta', target=draw, args=(account, 800)) tb = threading.Thread(name='tb', target=draw, args=(account, 800)) ta.start() tb.start()
执行结果:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现