protobuf 协议浅析
Protobuf 协议浅析
导语:本文首先介绍了 protobuf 的基本概念和语法,然后重点介绍了 protobuf 编解码的原理,最后结合前面的知识给出了 protobuf 的一些使用建议并利用思维导图对这篇文章的内容做了总结。
1. Protobuf 介绍
1.1 Protobuf 基本概念
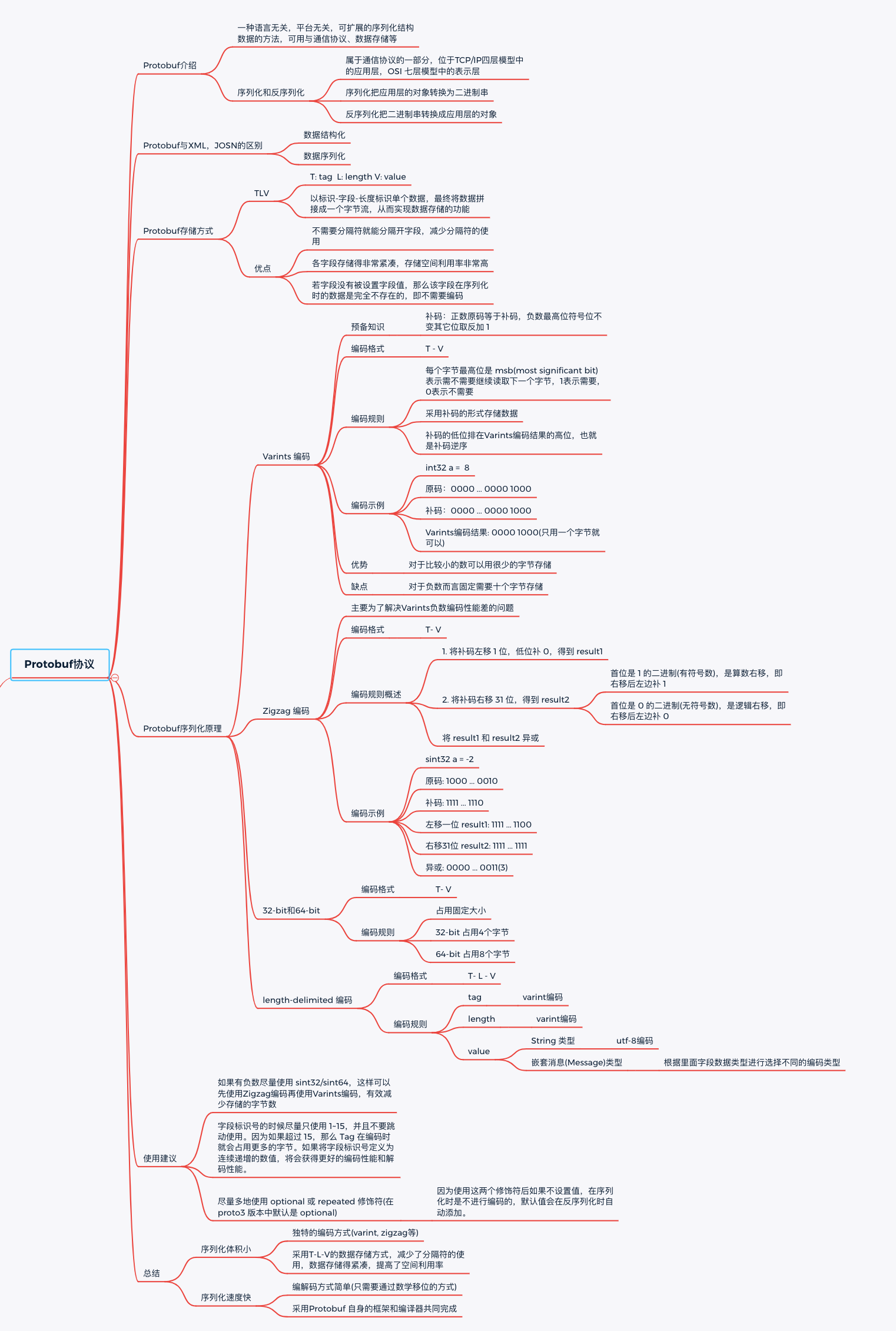
Protobuf 是由 Google 开发的一种语言无关,平台无关,可扩展的序列化结构数据的方法,可用于通信和数据存储。
提到 Protobuf 就不得不提到序列化和反序列化的概念。
序列化和反序列化属于通信协议的一部分,它们位于 TCP/IP 四层模型中的应用层和 OSI 七层模型中的表示层。
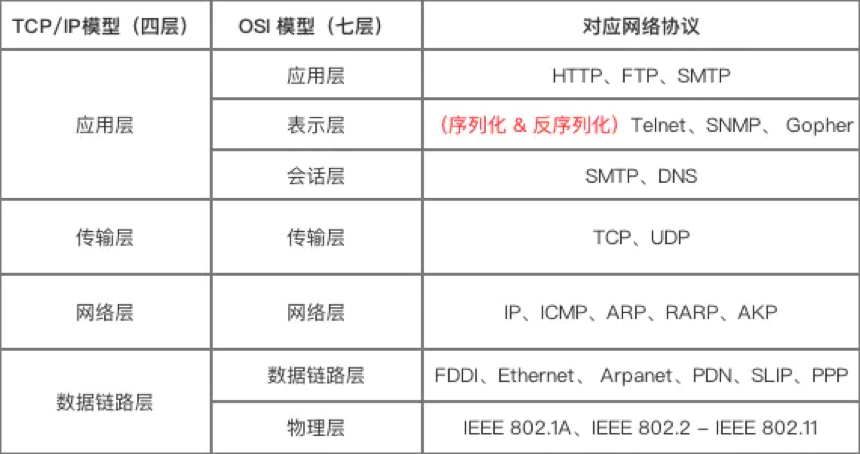
序列化是把应用层的对象转换为二进制串,反序列化是把二进制串转化成应用层的对象。
1.2 Protobuf 的优点
1)跨语言,跨平台
Protobuf 和语言,平台无关,定义好 pb 文件之后,对于不同的语言使用不同的语言的编译器对 pb 文件进行编译即可,编译完成之后就会提供对应语言能够使用的接口,通过这些接口就可以访问在 pb 文件中定义好的内容了。
2)性能优越
Protobuf 十分高效,无论是在数据存储还是通信性能都非常好,序列化的体积很小,序列化的速度也很快,关于这一点会在后面第 3 节序列化原理章节中做详细的介绍。
3)兼容性好
Protobuf 的兼容性特别好,当我们更新数据的时候不会影响原有的程序,例如 int32 和 int64 是两种不同的类型,存储的数据占用的字节数也不同,但是如果现在需要存储一个负数,采用 Varints 编码时,它们都会占用固定的十个字节,这是为了防止用户在将 int64 改为 int32 时会影响原有的程序。关于这方面的内容,在第3节也会做详细的介绍。
1.3 Protobuf, JSON, XML 的区别
Protobuf 和 JSON,XML 既有相似点又有不同点,从数据结构化和数据序列化两个维度去进行比较可能会更直观一些。
数据结构化主要面向开发和业务层面,数据序列化主要面向通信和存储层面。当然数据序列化也需要结构和格式,所以这两者的区别主要在于应用领域和场景不同,因此要求和侧重点也会有所不同。
数据结构化更加侧重于人类的可读性,强调语义表达能力,而数据序列化侧重效率和压缩。
接下来从这两个维度出发,我们进行一些简单的分析。
XML 作为一种可扩展标记语言,JSON 作为源于 JS 的数据格式,都具有数据结构化的能力。
例如 XML 可以衍生出 HTML(虽然 HTNL 早于 XML,但从概念上讲,HTML 只是预定义标签的 XML),HTML 的作用是标记和表达万维网中资源的结构,以便浏览器更好地展示万维网资源,同时也要尽可能保证其人类可读以便开发人员进行开发,这是面向业务或开发层面的数据结构化。
再如 XML 还可衍生出 RDF/RDFS,进一步表达语义网中资源的关系和语义,同样它强调数据结构化的能力和人类可读。
JSON 也是同理,在很多场景下更多的是体现了数据结构化的能力,例如作为交互接口的数据结构的表达。
当然,JSON 和 XML 同样也可以直接被用来数据序列化,实际上很多时候它们也是被这么使用的,例如直接采用 JSON,XML 进行网络通信传输,此时 XML 和 JSON 就成了一种序列化格式,发挥了数据序列化的能力。
但是我们平时开发的时候经常会这么用并不代表就是合理的,或者说是最好的。实际上,将 JSON 和 XML 直接数据序列化进行网络传输通常并不是最优的选择。因为它们在速度、效率,占用空间上都并不是最优的。换句话说它们更适合数据结构化而不是数据序列化。但是如果从这两方面综合考虑或许我们平时的选择又是合理的。
Protobuf 在数据结构化方面可能没有那么突出,但是在数据序列化方面,你会发现 Protobuf 具有明显的优势,效率,速度,空间几乎全面占优,这一部分将会在第 3 节编解码部分做出详细的阐述。
稍微做一个小的总结:
1)XML、JSON、Protobuf 都具有数据结构化和序列化的能力;
2)XML、JSON 更注重数据结构化,关注人类可读性和语义表达能力,Protobuf 更注重数据序列化,关注效率,空间,速度。
3)Protobuf 的应用场景更为明确,一般是在传输数据量较大,RPC 服务数据数据传输,XML、JSON 的应用场景更为丰富,传输数据量较小,在 MongoDB 中采用 JSON 作为查询语句,也是在发挥其数据结构化的能力。
2. Protobuf 基本语法
2.1 pb 文件的构成
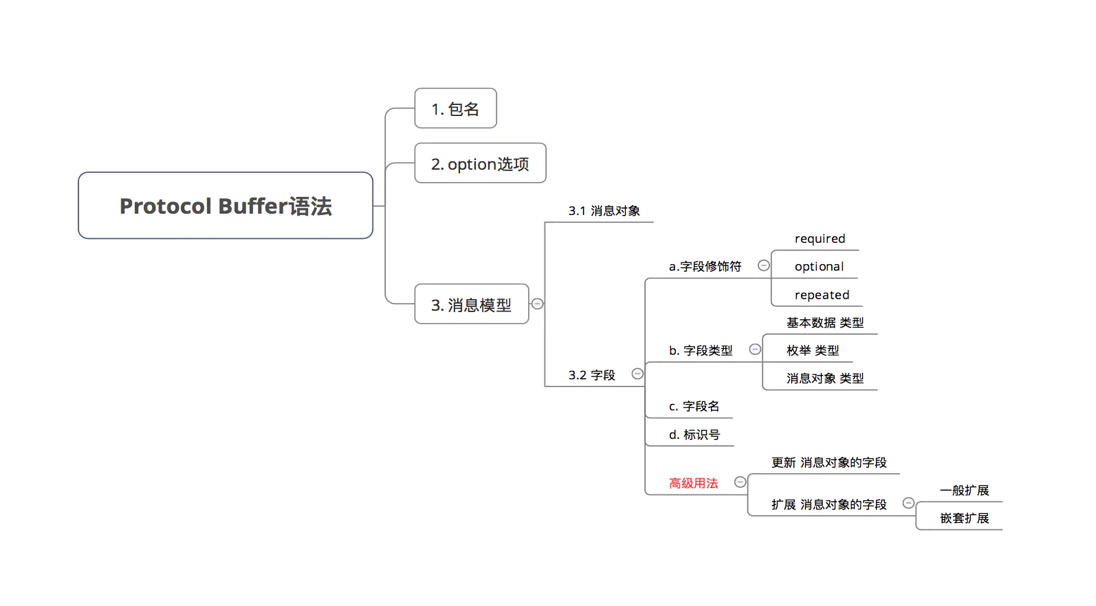
1)包名
作用:防止不同的 .proto 项目间命名发生冲突。
Protobuf 包的解析过程如下:
- protobuf 的类型名称解析与 C++ 一致:从最内部开始查找,依次向外进行,每个包会被看作是父类包的内部类
- Protobuf 编译器会解析
.proto文件中定义的所有类型名 - 生成器会根据不同语言生成对应语言的代码文件
2)option 选项
作用:影响特定环境下的处理方式
常用的 option 选项如下:
// 定义: Java 包名 // 作用: 指定生成的类应该放在什么 Java 包名下 // 注意: 如果不显示指定,默认包名为: 按照应用名称倒序方式进行排序 option java_package="com.tencent.trpcprotocol.tde.provider.provider"; option java_outer_classname = "Demo"; // 定义:类名 // 作用:生成对应.java 文件的类名(不能跟下面message的类名相同) // 注:如不显式指定,则默认为把.proto文件名转换为首字母大写来生成 // 如.proto文件名="my_proto.proto",默认情况下,将使用 "MyProto" 做为类名 option optimize_for = ***; // 作用:影响 C++ & java 代码的生成 // ***参数如下: // 1. SPEED (默认)::protocol buffer编译器将通过在消息类型上执行序列化、语法分析及其他通用的操作。(最优方式) // 2. CODE_SIZE::编译器将会产生最少量的类,通过共享或基于反射的代码来实现序列化、语法分析及各种其它操作。 // 特点:采用该方式产生的代码将比SPEED要少很多, 但是效率较低; // 使用场景:常用在 包含大量.proto文件 但 不追求效率 的应用中。 //3. LITE_RUNTIME::编译器依赖于运行时 核心类库 来生成代码(即采用libprotobuf-lite 替代libprotobuf)。 // 特点:这种核心类库要比全类库小得多(忽略了 一些描述符及反射 );编译器采用该模式产生的方法实现与SPEED模式不相上下,产生的类通过实现 MessageLite接口,但它仅仅是Messager接口的一个子集。 // 应用场景:移动手机平台应用 option cc_generic_services = false; option java_generic_services = false; option py_generic_services = false; // 作用:定义在C++、java、python中,protocol buffer编译器是否应该 基于服务定义 产生 抽象服务代码(2.3.0版本前该值默认 = true) // 自2.3.0版本以来,官方认为通过提供 代码生成器插件 来对 RPC实现 更可取,而不是依赖于“抽象”服务 optional repeated int32 samples = 4 [packed=true]; // 如果该选项在一个整型基本类型上被设置为真,则采用更紧凑的编码方式(不会对数值造成损失) // 在2.3.0版本前,解析器将会忽略 非期望的包装值。因此,它不可能在 不破坏现有框架的兼容性上 而 改变压缩格式。 // 在2.3.0之后,这种改变将是安全的,解析器能够接受上述两种格式。 optional int32 old_field = 6 [deprecated=true]; // 作用:判断该字段是否已经被弃用 // 作用同 在java中的注解@Deprecated
3)消息对象
作用:用于描述数据结构
一个消息对象(Message)可以看作一个结构化数据,消息对象(Message)里的字段可以看作结构化数据里的成员变量。
消息对象GetProxyEnvReq:
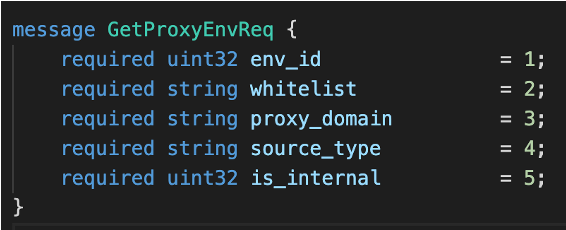
对应 JS 中的一个对象 getProxyEnvReq:
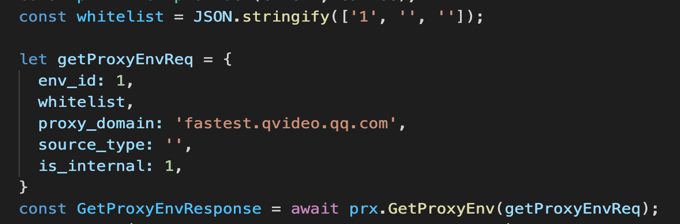
下面将详细介绍一下消息对象。
2.2 消息对象
在 Protobuf 中,消息对象用 message 修饰,一个消息对象由多个字段构成。
消息对象中字段的构成格式:
字段修饰符 字段类型 字段名 = 字段标识号;
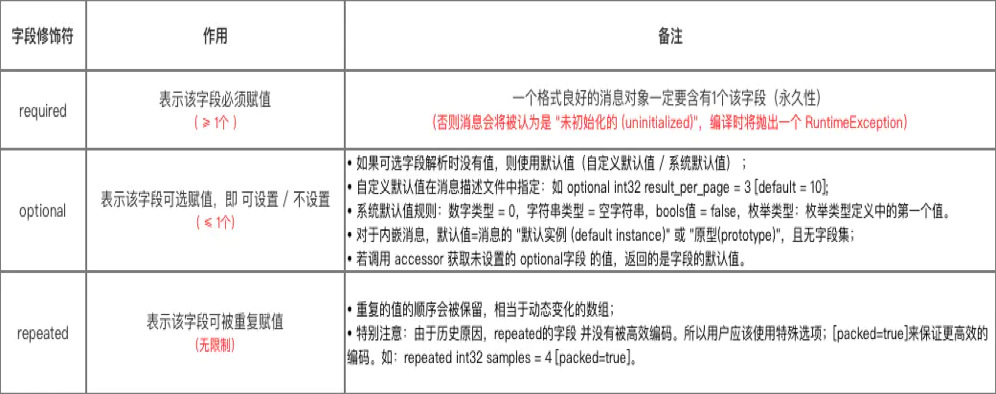
2.2.1 字段修饰符
作用:设置该字段解析时的规则。
注:Protobuf 现在主要有两个版本,proto2 和 proto3。在 proto3 中如果不写字段修饰符默认就是 optional。
2.2.2 字段类型
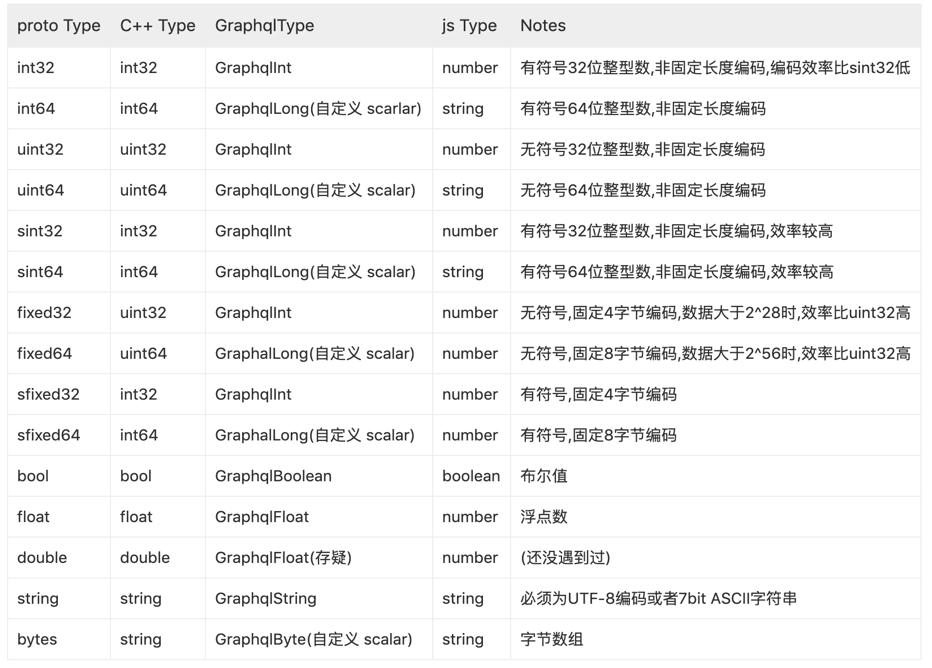
1)基本数据类型
Protobuf 中的基本数据类型可以转换为其它编程语言中对应的数据类型。
下图来自 bff-service 项目
2)枚举类型
作用:为字段指定一个可能取值的字段集合。
注意 Protobuf 中默认值的设置方式。
枚举类型的定义可在一个消息对象的内部或外部,当枚举类型是在一消息内部定义,希望在另一个消息中使用时,需要采用 MessageType.EnumType 的格式。
enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; } // 使用枚举类型 message PhoneNumber { PhoneType type = 1 [default = HOME] // 设置PhoneType的默认值为HOME }
当对一个使用了枚举类型的 .proto 文件使用 Protobuf 编译器编译时,生成的代码文件中,对于 Java 或 C++ 来说,将有一个对应的 enum 文件,对于 Python 来说,会有一个特殊的 EnumDescriptor 类。
3)消息对象类型
一个消息对象可以作为其它消息对象模型中的字段的类型来使用的,一个消息消息对象本身也是一种类型。
消息对象类型的使用非常灵活
- 使用内部的消息对象
message Person { string name = 1; int32 id = 2; string email = 3; message PhoneNumber { required string number = 1; } repeated PhoneNumber phone = 4; }
- 使用外部的消息对象
message People { string name = 1; uint32 id = 2; string email = 3; } message AddressBook { repeated Person person = 1; }
- 使用外部消息对象的内部消息对象类型
message Person { string name = 1; uint32 id = 2; string email = 3; message PhoneNumber { string number = 1; PhoneType type = 2 [default = HOME]; } } message OtherMessage { Person.PhoneNumber phonenumber = 1; }
- 使用不同 pb 文件里的消息类型
目的:需要在 A.proto 中使用 B.proto 文件里的消息类型。
解决方案:在 A.proto 文件中通过导入 B.proto 文件来使用 B.proto 文件里的消息类型。
import 'myproject/other_protos_proto'; // 在A.proto 文件中添加 B.proto文件路径的导入声明 // ProtocolBuffer编译器 会在 该目录中 查找需要被导入的 .proto文件 // 如果不提供参数,编译器就在 其调用的目录下 查找
2.2.3 标识号
作用:通过数字唯一标识一个字段
标识号的作用范围是 [1, 2^29 - 1],不可以使用 [19000 - 19999] 的标识号,因为 Protobuf 协议实现中对这些标识号进行了预留。
每个字段在进行编码时都会占用内存,而占用内存大小取决于标识号:
范围 [1,15] 标识号的字段在编码时占用1个字节,范围在 [16, 2047] 标识号的字段在编码时占用 2 个字节。
使用建议:
-
为频繁出现的消息字段使用[1, 15]标识号
-
为将来可能添加、频繁出现的消息字段预留[1, 15]标识号
2.3 使用 protobuf 编译器编译 pb 文件
根据上面介绍的语法,pb 文件我们已经写好了,现在假设想要进行编程就需要通过 protobuf 编译器将 .proto 文件编译成对应平台的代码文件。
如果现在是在用 trpc-node 进行开发,可以使用 trpc-tools-codec 这个编译工具进行编译,生成的代码文件如下:
. ├── proto │ ├── helloworld-dispatcher.ts ---- 协议文件生成的 server 端桥接代码 │ ├── helloworld-imp.ts ---- 协议文件生成的 server 端脚手架代码 │ ├── helloworld-proxy.ts ---- 协议文件生成的 client 端代理代码 │ ├── helloworld.d.ts ---- 协议文件生成的 codec 代码 for ts │ ├── helloworld.js ---- 协议文件生成的 codec 代码 │ └── helloworld.proto ---- 协议文件
利用这些生成的代码文件我们就可以进行编写 trpc 服务了。
3. Protobuf 序列化原理
3.1 Protobuf 编码结构
protobuf 数据存储采用 Tag-Length-Value 即标识 - 长度 - 字段值存储方式,以标识 - 长度 - 字段值表示单个字段,最终将数据拼接成一个字节流,从而实现数据存储的功能。
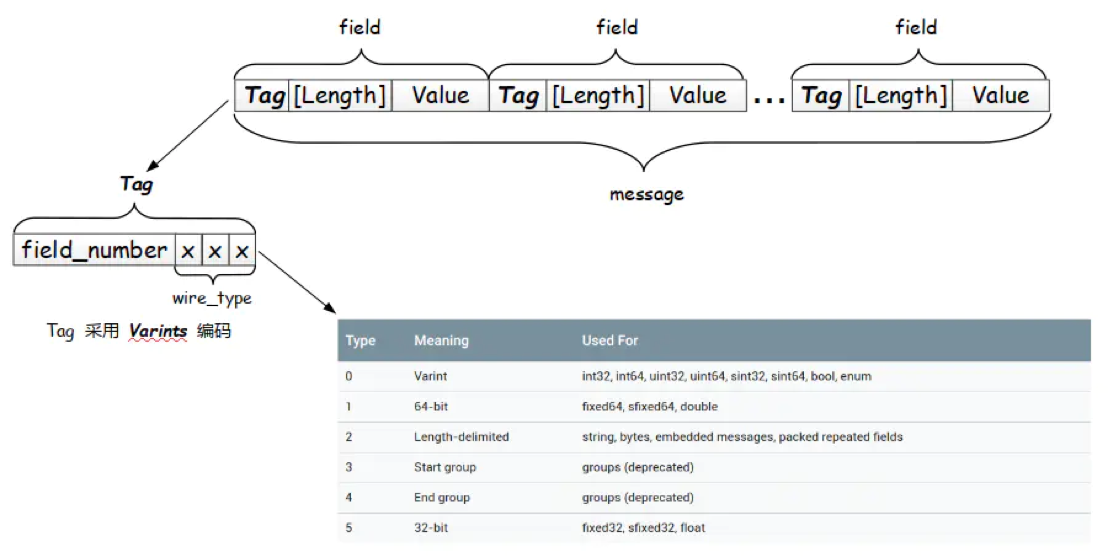
可以看到当采用 T - L - V 的存储结构时不需要分隔符就能分隔开字段,各字段存储地非常紧凑,存储空间利用率非常高。
此外如果某字段没有被设置字段值,那么该字段在序列化时是完全不存在的,即不需要编码,这个字段在解码时才会被设置默认值。
接下来重点介绍一下每个字段中都存在的 Tag。
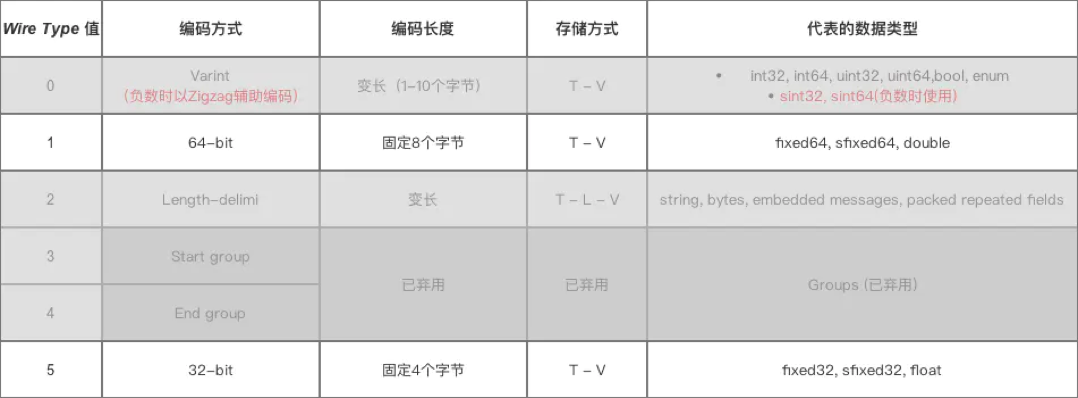
Tag 由 field_number 和 wire_type 两部分组成,其中 field_number 是字段的标识号,wire_type 是一个数值,根据它的数值可以确定该字段的字段值需要采用的编码类型。
// Tag 的具体表达式如下 Tag = (field_number << 3) | wire_type; // 参数说明: // field_number:对应于 .proto文件中消息字段的标识号,表示这是消息里的第几个字段 // 原来的field_number需要左移三位再拼接上wire_type就会得出Tag,所以真正的field_number是将Tag右移三位后的值 // field_number << 3:表示 field_number = 将 Tag的二进制表示右移三位后的值 // field_num左移3位不会导致数据丢失,因为表示范围还是足够大地去表示消息里的字段数目 // wire_type:表示 字段 的数据类型 // wire_type = Tag的二进制表示 的最低三位值 // wire_type 的取值 enum WireType { WIRETYPE_Varint = 0, WIRETYPE_FIXED64 = 1, WIRETYPE_LENGTH_DELIMITED = 2, WIRETYPE_START_GROUP = 3, WIRETYPE_END_GROUP = 4, WIRETYPE_FIXED32 = 5 }; // 从上面可以看出,`wire_type` 最多占用 3 位的内存空间(因为3位足以表示 0-5 的二进制)
wire_type 占 3 bit,最多可以表达 8 种编码类型,目前 Protobuf 已经定义了 6 种(Start group 和 End group 已经被废弃掉了),如下图所示。
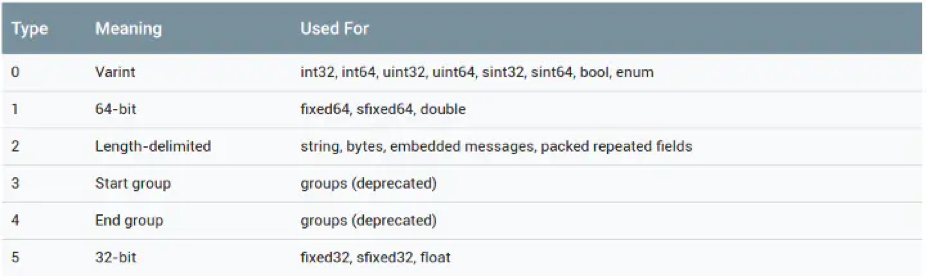
每个字段根据不同的编码类型会有下面两种编码格式:
- Tag - Length - Value: 编码类型表中 Type = 2,即 Length - delimited 编码类型将使用这种结构
- Tag - Value: 编码类型表中 Varint,64-bit,32-bit 将使用这种结构
接下来就来详细地介绍一下各种编码类型。
3.2 Varint 编码
Varint 编码是一种变长的编码方式,用字节表示数字,值越小的数字,使用越少的字节数表示。它通过减少表示数字的字节数从而进行数据压缩。
3.2.1 Varint 编码规则
部分源码:
private void writeVarint32(int n) { int idx = 0; while (true) { if ((n & ~0x7F) == 0) { i32buf[idx++] = (byte)n; break; } else { i32buf[idx++] = (byte)((n & 0x7F) | 0x80); // 步骤1:取出字节串末7位 // 对于上述取出的7位:在最高位添加1构成一个字节 // 如果是最后一次取出,则在最高位添加0构成1个字节 n >>>= 7; // 步骤2:通过将字节串整体往右移7位,继续从字节串的末尾选取7位,直到取完为止。 } } trans_.write(i32buf, 0, idx); // 步骤3: 将上述形成的每个字节 按序拼接 成一个字节串 // 即该字节串就是经过Varint编码后的字节 }
从步骤 1 中可以看出,Varint 编码中每个字节的最高位都有特殊的含义:
- 如果是 1,表示后续的字节也是该数字的一部分,需要继续读取
- 如果是 0,表示这是最后一个字节,且剩余 7 位都用来表示数字
所以,当使用 Varint 编码时,只要读取到最高位为 0 的字节时,就表示已经是 Varint 的最后一个字节了。
可以简单地将 Varint 的编码规则归结为以下三点:
1)在每个字节开头的 bit 设置了 msb(most significant bit),标识是否需要继续读取下一个字节
2)存储数字对应的二进制补码
3)补码的低位排在前面
补码的计算方法:
对于正数,原码和补码相同
对于负数,最高位符号位不变,其它位按位取反然后加 1
3.2.2 Varint 编码示例
接下来通过一个示例来说明一下 Varint 编码的过程
示例 1
int32 a = 8;
- 原码:0000 ... 0000 1000
- 补码:0000 ... 0000 1000
- 根据 Varint 编码规则,从低位开始取 7 bit,000 1000
- 当取出前 7 bit 后,前面所有的位就都是 0 了,不需要继续读取了,因此设置 msb 位为 0 即可
- 所以最终 Varint 编码为 0000 1000
可以看到在使用 Varint 编码后只使用一个字节就可以了,而正常的 int32 编码一般需要 4 个字节。
仔细体会上述的 Varint 编码,我们可以发现 Varint 编码本质实际上是每个字节都牺牲了一个 bit 位,来表示是否已经结束(是否需要继续读取下一个字节),msb 实际上就起到了 length 的作用,正因为有了这个 msb 位,所以我们可以摆脱原来那种无论数字大小都必须分配四个字节的窘境。
通过 Varint 编码对于比较小的数字可以用很少的字节进行表示,从而减小了序列化后的体积。
但是由于 Varint 编码每个字节都要拿出一位作为 msb 位,因此每个字节就少了一位来表示字段值。那这就意味着四个字节能表达的最大数字是为 2^28 而不是 2^32 了。
所以如果当数字大于 2^28 时,采用 Varint 编码将导致分配 5 个字节,原先明明只需要 4 个字节。此时 Varint 编码的效率不仅没有提高反而是下降了。
但是这并不影响 Varint 编码在实际应用时的高效,因为事实证明,在大多数情况下,数字在 2^28 ~ 2^32 出现的概率要远远小于 0 ~ 2^28 出现的概率。
示例 2
这样看来 Varint 编码似乎很完美,但是有一种情况下,Varint 编码的效率很低。上面的例子中只给出了正数的情况,思考如果是负数的情况呢。
我们知道负数的二进制表示中最高位是符号位 1,这一点意味着负数都必须占用所有字节。
我们还是通过一个示例来体会一下。
int32 a = -1
- 原码:1000 ... 0000 0001
- 补码:1111 ... 1111 1111
- 根据 Varints 编码规则,从低位开始取 7 bit,111 1111,由于前面还有 1 需要读取,因此需要设置 msb 位为 1,然后将这个字节放在 Varint 编码的高位。
- 依次类推,有 9 组(字节)都是 1,这 9 组的 msb 均为 1,最后一组只有 1 位是 1,由于已经是最后一组了不需要再继续读取了,因此这组的 msb 位应该是 0.
- 因此最终的 Varint 编码是 1111 1111 ... 0000 0001(FF FF FF FF FF FF FF FF FF 01 )
可能大家会有疑问为什么会占用 10 个字节呢?
这是 Protobuf 基于兼容性考虑,例如当开发者将 int64 改为 int32 后应该不影响旧程序,所以将 int32 扩展为 int64 的八个字节。
可能大家还会有疑问为什么对于正数的时候不需要进行类似的兼容处理呢?
实际上当要编码的是正数时,int32 和 int64 是天然兼容的,他们两个的编码过程是完全一样的,利用 msb 位去控制最终的 Varint 编码长度即可。
所以目前的情况是我们定义了一个 int32 类型的变量,如果将变量的值设置为 负数,如果直接采用 Varint 编码的话,其编码结果将总是占用十个字节,这显然不是我们希望得到的结果。那么我们应该如何去解决呢?
答案就是下面的 Zigzag 编码。
3.3 Zigzag 编码
在 Protobuf 中 Zigzag 编码的出现主要是为了解决 Varint 编码负数效率低的问题。
基本原理就是将有符号正数映射成无符号整数,然后再使用 Varint 编码,这里所说的映射是通过移位的方式实现的并不是通过存储映射表。
3.3.1 Zigzag 编码规则
部分源码:
public int int_to_Zigzag(int n) { // 传入的参数n = 传入字段值的二进制表示(此处以负数为例) // 负数的二进制 = 符号位为1,剩余的位数为该数绝对值的原码按位取反;然后整个二进制数+1 return (n <<1) ^ (n >>31); } // 解码 public int Zigzag_to_int(int n) { return (n >>> 1) ^ -(n & 1); }
根据上面的源码我们可以得出 Zigzag 的编码过程如下:
- 将补码左移 1 位,低位补 0,得到 result1
- 将补码右移 31 位,得到 result2
- 首位是 1 的补码(有符号数)是算数右移,即右移后左边补 1
- 首位是 0 的补码(无符号数)是逻辑右移,即右移后左边补 0
- 将 result1 和 result2 异或
3.3.2 Zigzag 编码示例
下面通过一个示例来演示一个 Zigzag 的编码过程
sint32 a = -2
- 原码:1000 ... 0010
- 补码:1111 ... 1110
- 左移一位(算数右移)result1:1111 ... 1100
- 右移31位result2:1111 ... 1111
- 异或: 0000 ... 0011(3)
编码过程示意图如下:
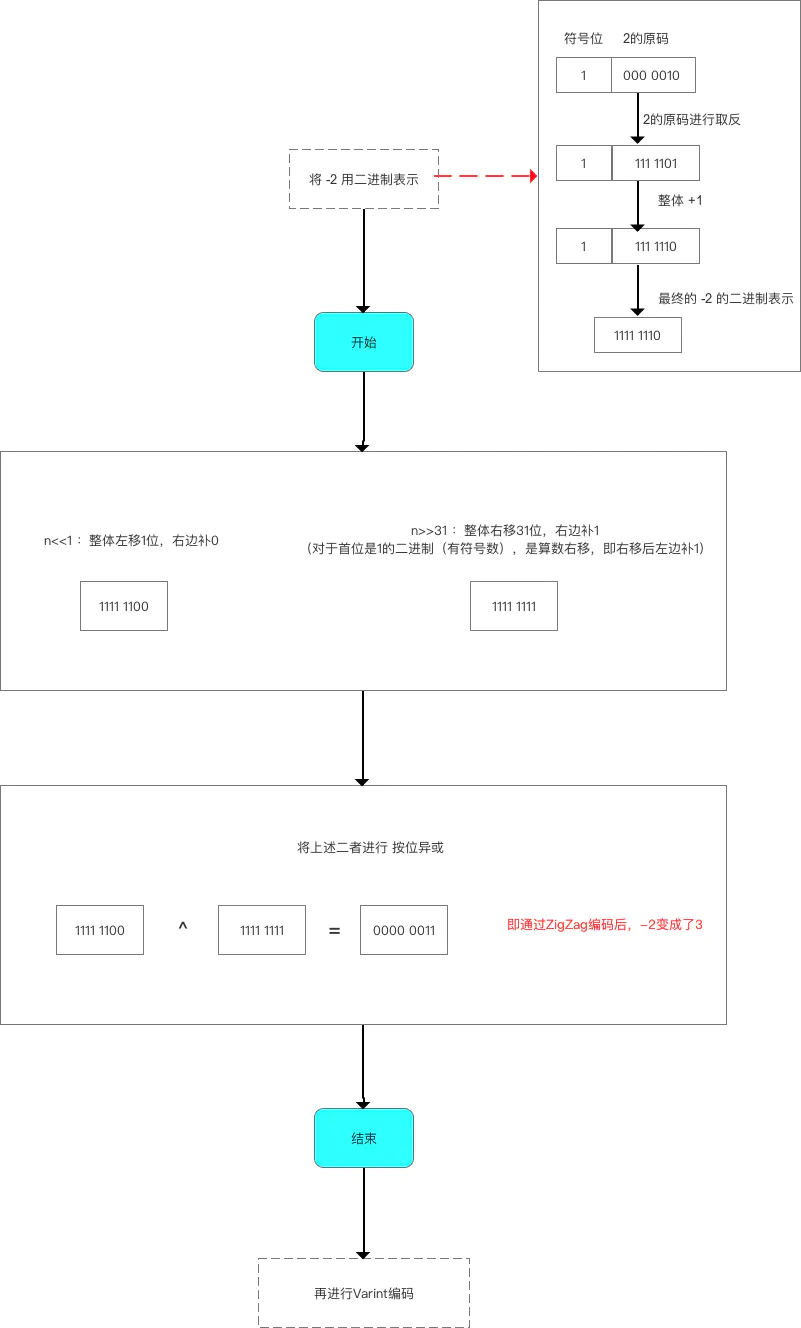
可以看到 -2 经过 Zigzag 编码之后变成了正数 3,这时再通过 Varint 编码就很高效了,在接收端先通过 Varint 解码得到数字 3,然后再通过 Zigzag 解码就可以得到原始发送的数据 -2 了。
因此在定义字段时如果知道该字段的值有可能是负数的话,那么建议使用 sint32/sint64 这两种数据类型。
3.4 64-bit(32-bit)编码
64-bit 和 32-bit 的编码方式比较简单,64-bit 编码后是固定的 8 个字节,32 bit 编码后是固定的 4 个字节。当数据类型是 fixed64,sfixed64,double 时将采用 64-bit 编码方式,当数据类型是 fixd32,sfixed64,float 时将采用 32-bit 编码方式。
注意这两种编码方式都是补码的高位放到编码后的低位。
它们都采用的是 T - V 的存储方式。
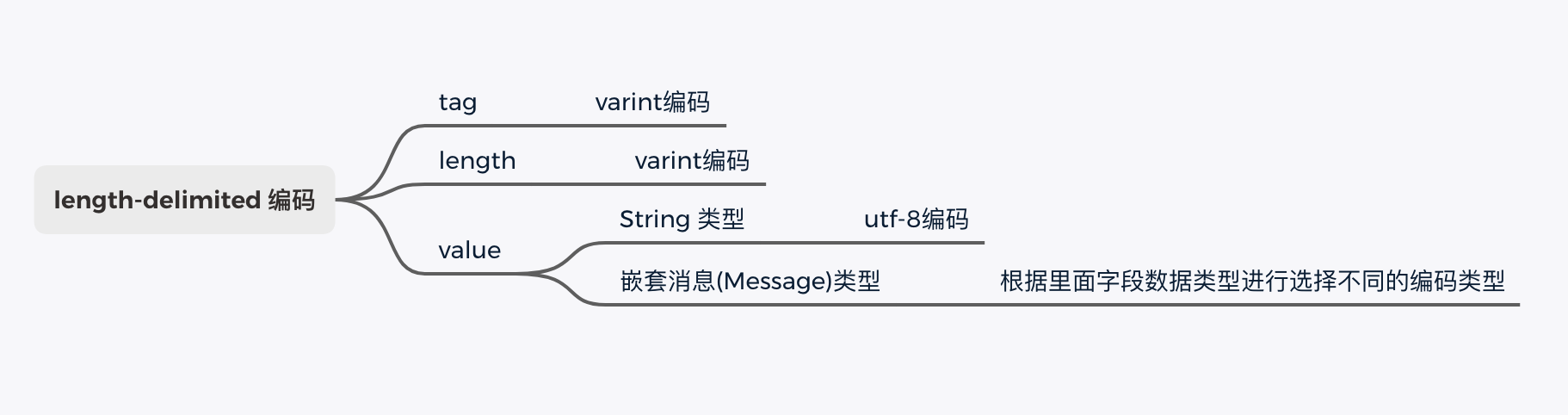
3.5 length-delimited
这是 Protobuf 中唯一一个采用 T - L - V 的存储方式。如下图所示,Tag 和 Length 仍然采用 Varint 编码,对于字段值根据不同的数据类型采用不同的编码方式。
例如,对于 string 类型字段值采用的是 utf-8 编码,而对于嵌套消息数据类型会根据里面字段的类型选择不同的编码方式。
接下来重点说一下嵌套消息数据类型是如何进行编码的。
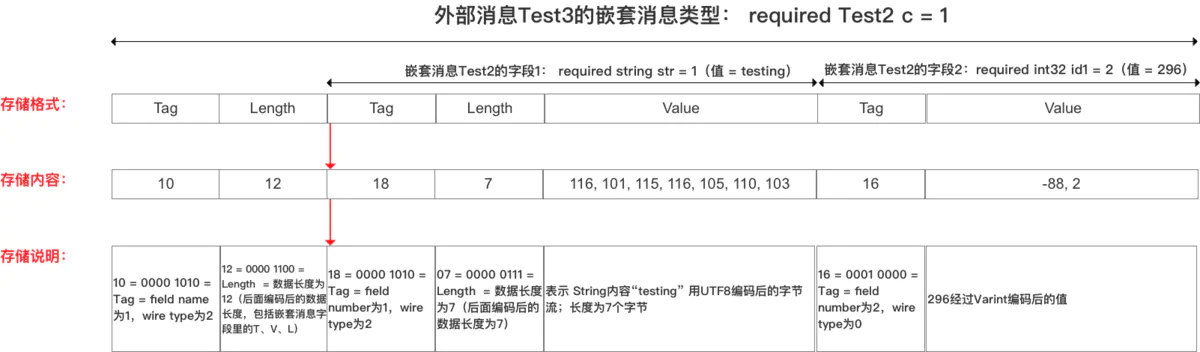
通过下面的示例来说明,在 Test3 这个 Message 对象中的 c 字段的类型是一个消息对象 Test2,并且将 Test2 中字段 str 的值设置为 testing,将字段 id1 的值设置为 296.
message Test2 { required string str = 1; required int32 id1 = 2; } message Test3 { required Test2 c = 1 } // 将Test2中的字段str设置为:testing // 将Test2中的字段id1设置为:296 // 编码后的字节为:10 ,12 ,18,7,116, 101, 115, 116, 105, 110, 103,16,-88,2
那么编码后的存储方式如下:
3.6 序列化过程
Protobuf 的性能非常优越主要体现在两点,其中一点就是序列化后的体积非常小,这一点在前面编解码的介绍中已经体现出来了。还有另外一点就是序列化速度非常快,接下来就简单地介绍一下为什么序列化的速度非常快。
Protobuf 序列化的过程简单来说主要有下面两步
- 判断每个字段是否有设置值,有值才进行编码,
- 根据 tag 中的 wire_type 确定该字段采用什么类型的编码方案进行编码即可。
Protobuf 反序列化过程简单来说也主要有下面两步:
- 调用消息类的 parseFrom(input) 解析从输入流读入的二进制字节数据流
- 将解析出来的数据按照指定的格式读取到相应语言的结构类型中
Protobuf 的序列化过程中由于编码方式简单,只需要简单的数学运算位移即可,而且采用的是 Protobuf 框架代码和编译器共同完成,因此序列化的速度非常快。
可能这样并不能很直观地展现出 Protobuf 序列化过程非常快,接下来我们简单介绍一下 XML 的反序列化过程,通过对比我们就能清晰地认识到 Protobuf 序列化的速度是非常快的。
XML 反序列化的过程大致如下:
- 从文件中读取出字符串
- 从字符串转换为 XML 文档对象模型
- 从 XML 文档对象结构模型中读取指定节点的字符串
- 将该字符串转换成指定类型的变量
从上述过程中,我们可以看到 XML 反序列化的过程比较繁琐,而且在第二步,将 XML 文件转换为文档对象模型的过程是需要词法分析的,这个过程是比较耗费时间的,因此通过对比我们就可以感受到 Protobuf 的序列化的速度是非常快的。
4. 使用建议
接下来结合上面所提到的一些知识,简单给出一些在使用 Protobuf 时的一些小建议。
1)如果有负数,那么尽量使用 sint32/sint64 ,不要使用 int32/int64,因为采用 sin32/sin64 数据类型表示负数时,根据前面的介绍可以知道会先采用 Zigzag 将负数通过移位的方式映射为正数, 然后再使用 Varint 编码,这样就可以有效减少存储的字节数。
2)字段标识号的时候尽量只使用 1~15,并且不要跳动使用。因为如果超过 15,那么 Tag 在编码时就会占用更多的字节。如果将字段标识号定义为连续递增的数值,将会获得更好的编码性能和解码性能。
3)尽量多地使用 optional 或 repeated 修饰符(在 proto3 版本中默认是 optional),因为使用这两个修饰符后如果不设置值,在序列化时是不进行编码的,默认值会在反序列化时自动添加。
5. 总结
-------------------------------------------
个性签名:梦想不只是梦与想
如果您觉得这篇文章哪个地方不恰当甚至有错误的话,麻烦告诉一下博主哦,感激不尽。
如果您觉得这篇文章对你有一点小小的帮助的话,希望能在右下角点个“推荐”哦。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人