使用Spark开发应用程序,并将作业提交到服务器
1、pycharm编写spark应用程序#
由于一些原因在windows上配置未成功(应该是可以配置成功的)、我是在linux上直接使用pycharm,在linux的好处是,环境可能导致的一切问题不复存在
111 新建一个普通python工程
编程环境使用spark使用的python环境
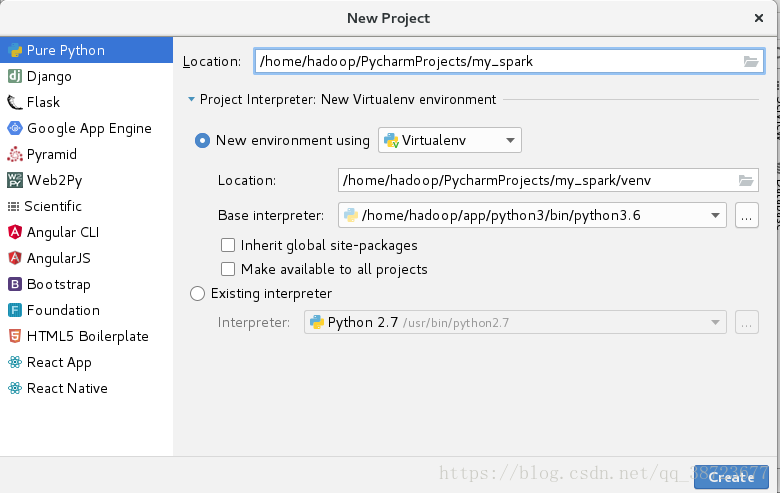
222 配置spark环境
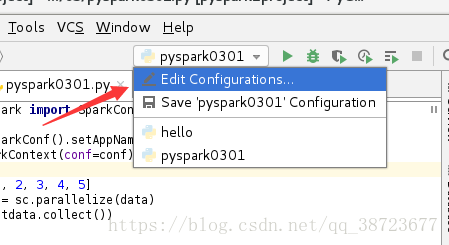
进入下图
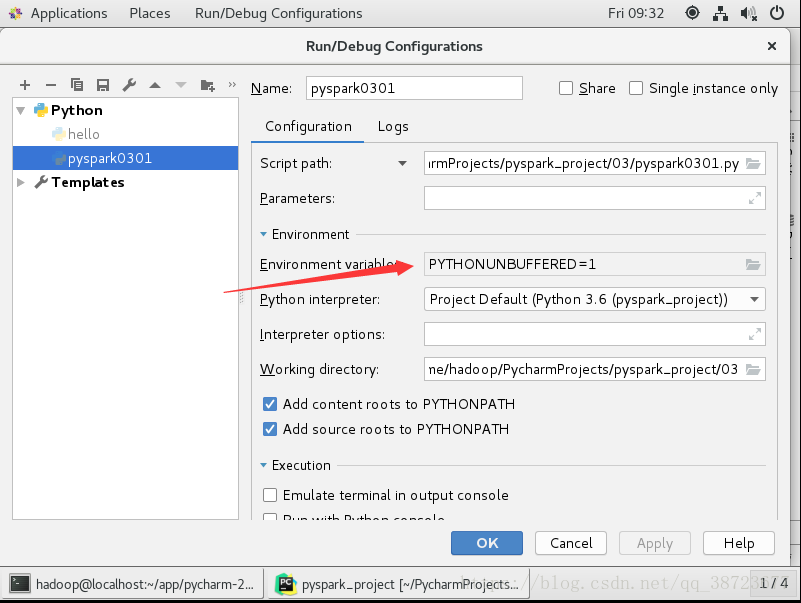
添加2个相应属性
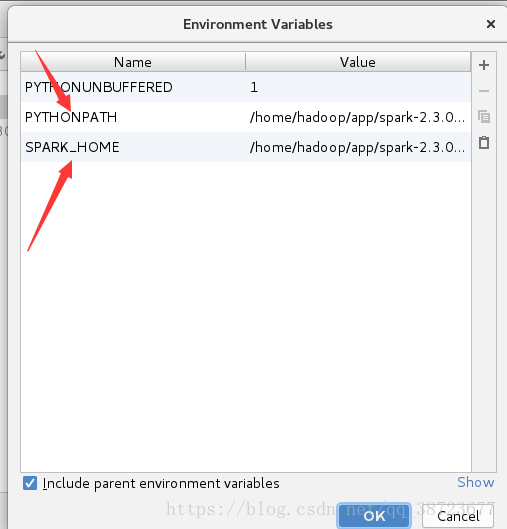
PYTHON_PATH为spark安装目录下的python的路径
我的:/home/hadoop/app/spark-2.3.0-bin-2.6.0-cdh5.7.0/python
SPARK_HOMR为spark安装目录
我的:/home/hadoop/app/spark-2.3.0-bin-2.6.0-cdh5.7.0
完成后
导入两个包进入setting

包位置为spark安装目录下python目录下lib里

2、正式编写#
创建一个python文件
from pyspark import SparkConf, SparkContext
# 创建SparkConf:设置的是spark的相关信息
conf = SparkConf().setAppName("spark0301").setMaster("local[2]")
# 创建SparkContext
sc = SparkContext(conf=conf)
# 业务逻辑
data = [1, 2, 3, 4, 5]
# 转成RDD
distdata = sc.parallelize(data)
print(distdata.collect())
# 好的习惯
sc.stop()在linux系统用户家根目录创建一个script

将代码放入spark0301.py中
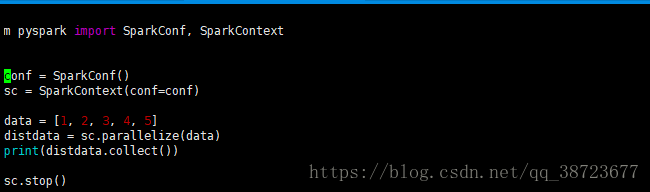
将appname和master去掉,官网说不要硬编码,会被自动赋值
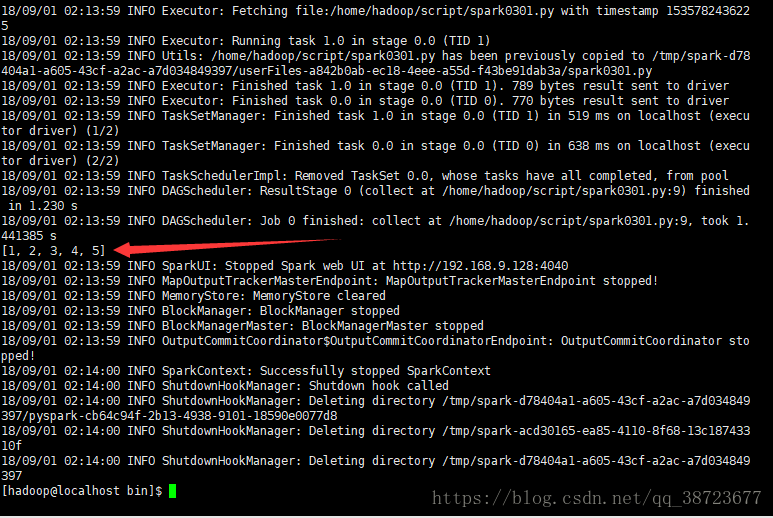
然后进入spark安装目录下bin目录运行
./spark-submit --master local[2] --name spark0301 /home/hadoop/script/spark0301.py
因为速度太快结束网站是看不到的



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY