用MR生成HFile文件格式后,数据批量导入HBase
环境hadoop cdh5.4.7 hbase1.0.0
测试数据:
topsid uid roler_num typ
10 111111 255 0
在Hbase 创建t2数据库: create 't2','info'。创建数据库t2, columnFamily:info
import java.io.IOException; import java.net.URI; import java.text.SimpleDateFormat; import java.util.Date; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.KeyValue; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class HFileCreate { static class HFileImportMapper2 extends Mapper<LongWritable, Text, ImmutableBytesWritable, KeyValue> { protected SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd"); protected final String CF_KQ = "info"; protected final int ONE = 1; @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); System.out.println("line : " + line); String[] datas = line.split("\\s+"); // row格式为:yyyyMMdd-sid-uid-role_num-timestamp-typ String row = datas[0] + "-" + datas[1] + "-" + datas[2] + "-" + "-" + datas[3]; ImmutableBytesWritable rowkey = new ImmutableBytesWritable( Bytes.toBytes(row)); KeyValue kv = new KeyValue(Bytes.toBytes(row), this.CF_KQ.getBytes(), datas[3].getBytes(), Bytes.toBytes(this.ONE)); context.write(rowkey, kv); } } public static void main(String[] args) { Configuration conf = new Configuration(); conf.addResource("hbase-site.xml"); String tableName = "t2"; String input = "hdfs://node11:9000/datas/t3"; String output = "hdfs://node11:9000/datas/out12"; System.out.println("table : " + tableName); HTable table; try { // 运行前,删除已存在的中间输出目录 try { FileSystem fs = FileSystem.get(URI.create(output), conf); fs.delete(new Path(output), true); fs.close(); } catch (IOException e1) { e1.printStackTrace(); } table = new HTable(conf, tableName.getBytes()); Job job = new Job(conf); job.setJobName("Generate HFile"); job.setJarByClass(HFileCreate.class); job.setInputFormatClass(TextInputFormat.class); job.setMapperClass(HFileImportMapper2.class); FileInputFormat.setInputPaths(job, input); job.getConfiguration().set("mapred.mapoutput.key.class", "org.apache.hadoop.hbase.io.ImmutableBytesWritable"); job.getConfiguration().set("mapred.mapoutput.value.class", "org.apache.hadoop.hbase.KeyValue"); FileOutputFormat.setOutputPath(job, new Path(output)); HFileOutputFormat2.configureIncrementalLoad(job, table); try { job.waitForCompletion(true); } catch (InterruptedException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } } catch (IOException e) { e.printStackTrace(); } } }
输出目录要有带columnFamily的文件HFile才生成成功:

4、需要先配置自己HBase_HOME 在配置文件中自己查看。
echo $HBase_HOME
5、我的配置:export HBASE_HOME=/home/hbase-1.0.0-cdh5.4.7
输入:
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` hadoop jar ${HBASE_HOME}/lib/hbase-server-1.0.0-cdh5.4.7.jar
例如我的:HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` hadoop jar /home/hbase-1.0.0-cdh5.4.7/lib/hbase-server-1.0.0-cdh5.4.7.jar completebulkload /datas/out12 t2
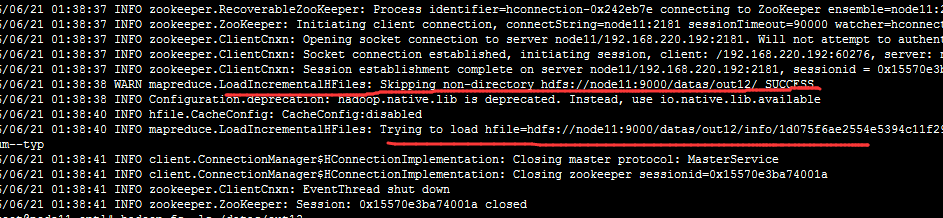
一般执行到这步就 成功导入。
6、查询HBase
7、HBase-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- /** * * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ --> <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://node11:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node11</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property> <property> <name>hbase.region.server.rpc.scheduler.factory.class</name> <value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value> <description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description> </property> <property> <name>hbase.rpc.controllerfactory.class</name> <value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value> <description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description> </property> <property> <name>hbase.coprocessor.regionserver.classes</name> <value>org.apache.hadoop.hbase.regionserver.LocalIndexMerger</value> </property> <property> <name>hbase.master.loadbalancer.class</name> <value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value> </property> <property> <name>hbase.coprocessor.master.classes</name> <value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value> </property> </configuration>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号