solr添加IK分词和自己定义词库
下载IK分词IK Analyzer 2012FF_hf1.zip
下载地址:http://yunpan.cn/cdvATy8899Lrw (提取码:c10d)
1、将IKAnalyzer2012FF_u1.jar包上传到服务器,复制到solr-4.10.4/example/solr-webapp/webapp/WEB-INF/lib目录下
2、在solr-4.10.4/example/solr-webapp/webapp/WEB-INF目录下创建目录classes,然后把IKAnalyzer.cfg.xml和stopword.dic拷贝到新创建的classes目录下即可
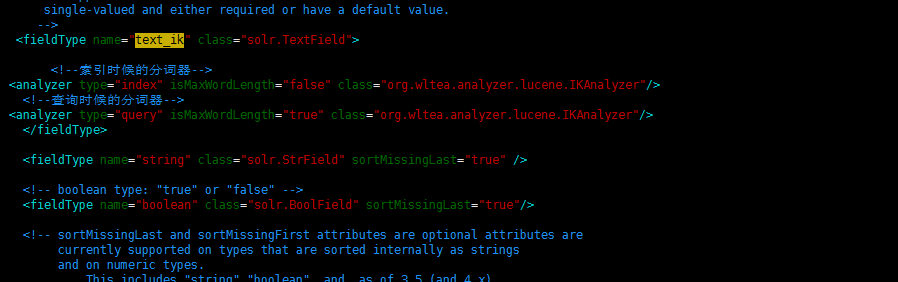
3:修改solr core的schema文件,默认是solr-4.10.4/example/solr/collection1/conf/schema.xml,添加如下配置
<fieldType name="text_ik" class="solr.TextField">
<!--索引时候的分词器-->
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<!--查询时候的分词器-->
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
4、启动solr集群

自定义词库
到sougou 下载对应的词库:http://pinyin.sogou.com/dict/
由于sougou 下载后的文件是scel 格式不能直接用,需要用工具转化下格式,推荐使用深蓝工具,下载地址
http://yunpan.cn/cmuyuQhCasFMR (提取码:6432)

然后将文件格式转化为dic结尾的。词库的文件格式必需是:无BOM的UTF-8格式,分词库可以为多个,以分号隔开即可。
将下载的词库复制到/home/hadoop/cloudsolr/solr-4.10.4/example/solr-webapp/webapp/WEB-INF/classes目录下

修改配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典
<entry key="ext_dict">ext.dic;</entry>
-->
<entry jey = "mingxing">mingxing.scel</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
重启solr集群
测试结果:
这样分词有一个问题:分词方式是按照maxword 的方式
集群启动的时候主节点不会报错。从节点会报错

配置文件信息如下:
IK的lib文件已经上传

改配置的都配置了,启动还是报错:
{msg=SolrCore 'collection1' is not available due to init failure: Could not load conf for core collection1: Plugin init failure for [schema.xml] fieldType "text_ik": Cannot load analyzer: org.wltea.analyzer.lucene.IKAnalyzer. Schema file is /configs/myconf/schema.xml,trace=org.apache.solr.common.SolrException: SolrCore 'collection1' is not available due to init failure: Could not load conf for core collection1: Plugin init failure for [schema.xml] fieldType "text_ik": Cannot load analyzer: org.wltea.analyzer.lucene.IKAnalyzer. Schema file is /configs/myconf/schema.xml
at org.apache.solr.core.CoreContainer.getCore(CoreContainer.java:745)
at org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:347)
问题原因:
配置了IK分词后,没有同步到zk,删掉zkdata 里面的数据重新启动zk即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号