【学习笔记】分类算法-k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类。
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
使用数据范围:数值型和标称型
用例子来理解k-近邻算法
电影可以按照题材分类,每个题材又是如何定义的呢?那么假如两种类型的电影,动作片和爱情片。动作片有哪些公共的特征?那么爱情片又存在哪些明显的差别呢?我们发现动作片中打斗镜头的次数较多,而爱情片中接吻镜头相对更多。当然动作片中也有一些接吻镜头,爱情片中也会有一些打斗镜头。所以不能单纯通过是否存在打斗镜头或者接吻镜头来判断影片的类别。那么现在我们有6部影片已经明确了类别,也有打斗镜头和接吻镜头的次数,还有一部电影类型未知。
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|---|---|---|
| California Man | 3 | 104 | 爱情片 |
| He's not Really into dues | 2 | 100 | 爱情片 |
| Beautiful Woman | 1 | 81 | 爱情片 |
| Kevin Longblade | 101 | 10 | 动作片 |
| Robo Slayer 3000 | 99 | 5 | 动作片 |
| Amped II | 98 | 2 | 动作片 |
| ? | 18 | 90 | 未知 |
那么我们使用K-近邻算法来分类爱情片和动作片:存在一个样本数据集合,也叫训练样本集,样本个数M个,知道每一个数据特征与类别对应关系,然后存在未知类型数据集合1个,那么我们要选择一个测试样本数据中与训练样本中M个的距离,排序过后选出最近的K个,这个取值一般不大于20个。选择K个最相近数据中次数最多的分类。那么我们根据这个原则去判断未知电影的分类。
| 电影名称 | 与未知电影的距离 |
|---|---|
| California Man | 20.5 |
| He's not Really into dues | 18.7 |
| Beautiful Woman | 19.2 |
| Kevin Longblade | 115.3 |
| Robo Slayer 3000 | 117.4 |
| Amped II | 118.9 |
我们假设K为3,那么排名前三个电影的类型都是爱情片,所以我们判定这个未知电影也是一个爱情片。那么计算距离是怎样计算的呢?
定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
欧氏距离 那么对于两个向量点a1和a2之间的距离,可以通过该公式表示:
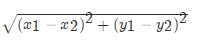
如果说输入变量有四个特征,例如(1,3,5,2)和(7,6,9,4)之间的距离计算为:
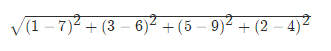
sklearn k-近邻算法API
sklearn.neighbors提供监督的基于邻居的学习方法的功能,sklearn.neighbors.KNeighborsClassifier是一个最近邻居分类器。
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
预测入住位置
kaggle地址:https://www.kaggle.com/c/facebook-v-predicting-check-ins
from sklearn.model_selection import train_test_split
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 读取数据
data = pd.read_csv("data/facebook/train.csv")
# 处理数据
# 缩小数据的范围
data.query("x > 1.0 & x < 1.2 & y > 2.5 & y < 3", inplace=True)
# 处理日期数据
time_value = pd.to_datetime(data["time"], unit="s")
time_value = pd.DatetimeIndex(time_value)
# print(time_value)
# 构造一些特征
data["day"] = time_value.day
data["hour"] = time_value.hour
data["minute"] = time_value.minute
data["weekday"] = time_value.weekday
# 去掉时间戳特征
data.drop(["time"], axis=1, inplace=True)
# 把签到数量少于n的目标位置去掉
place_count = data.groupby("place_id").count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data["place_id"].isin(tf.place_id)]
# 取出特征值和目标值
y = data["place_id"]
x = data.drop(["place_id"], axis=1)
# 将数据分隔成训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 特征工程(标准化)
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# knn
knn = KNeighborsClassifier()
knn.fit(x_train, y_train.astype("int"))
# 得出预测结果
y_predict = knn.predict(x_test)
print("预测结果为:", y_predict)
# 得出准确率
print("预测的准确率为:", knn.score(x_test, y_test.astype("int")))
运行结果:
预测结果为: [-2147483648 -2147483648 -2147483648 ... -2147483648 1176369387
1176369387]
预测的准确率为: 0.8290876777251185
流程:
- 对数据集进行处理:为了减少程序的运行时间,缩小了数据集的范围。提取出时间戳中的day、hour、minute、weekday,并去掉时间戳。并把签到数据小于3的目标位置去掉。
- 分隔数据集:按照75:25的比例去分隔数据集
- 对数据进行标注化
- estimator流程进行分类预测
问题:
-
k值取很小:容易受异常点影响
-
k值取很大:容易受最近数据太多导致比例变化
k-近邻算法优缺点:
优点:
- 简单,易于理解,易于实现,无需估计参数,无需训练
缺点:
- 懒惰算法,对测试样本分类时的计算量大,内存开销大
- 必须指定K值,K值选择不当则分类精度不能保证
使用场景:小数据场景,几千~几万样本,具体场景具体业务去测试
本文来自博客园,作者:coder-qi,转载请注明原文链接:https://www.cnblogs.com/coder-qi/p/10548635.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号