第一次个人编程作业
Part one 作业github链接

Part two PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 50 |
| Development | 开发 | 480 | 480 |
| · Analysis | · 需求分析 (包括学习新技术) | 480 | 600 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 30 | 40 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| · Design | · 具体设计 | 60 | 80 |
| · Coding | · 具体编码 | 120 | 150 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 40 |
| Reporting | 报告 | 60 | 80 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1550 | 1715 |
Part three 计算模块接口的设计与实现过程
- 整体程序流程图
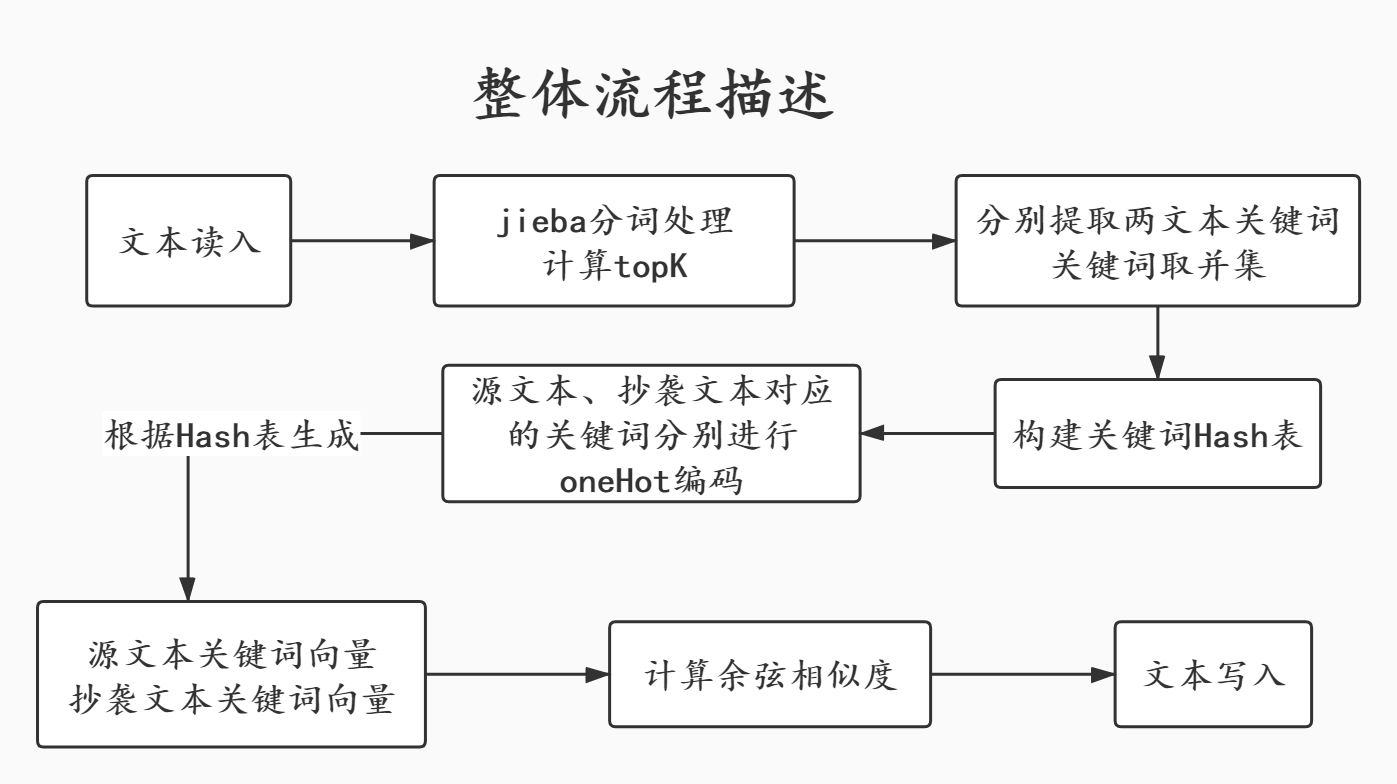
-
模块介绍
- 算法思想:基于余弦相似度算法进行文本查重
余弦相似度,是通过计算两个向量的夹角余弦值来评估他们的相似度。本次作业要求计算两篇文本之间的相似度,我的思路是通过提取文本的关键词,通过关键词集编码后的向量进行余弦值计算,即文本相似度。
-
python库:
- jieba 进行分词
- jieba.analyse 提取关键词
- sklearn.metrics.pairwise中的cosine_similarity可直接进行余弦相似度计算
- sys 用于读取命令行参数
-
extractKeyword 用于关键词的提取,按照权重提取前k个关键词。
def extractKeyword(text): cut = [i for i in jieba.cut(text, cut_all=True) if i != ''] keywords = jieba.analyse.extract_tags(",".join(cut), topK=topK, withWeight=False) return keywords解释一下这个方法用到的参数
jieba.analyse.extract_tags(sentence, topK=5, withWeight=True)sentence: 需要提取的字符串,必须是str类型,不能是list
topK: 提取前多少个关键词
withWeight: 是否返回每个关键词的权重
-
constructHash 哈希表构造
def constructHash(keywords): dictionaries = {} hash_value = 0 for keyword in keywords: dictionaries[keyword] = hash_value hash_value += 1 return dictionaries- oneHotCode 进行onehot编码
def oneHotCode(dictionaries, keywords): vector = [0] * len(dictionaries) for keyword in keywords: vector[dictionaries[keyword]] += 1 return vector- calculate 计算余弦相似度
def calculate(s1_code, s2_code): sim = cosine_similarity([s1_code, s2_code]) return sim[0][1]- 整体思路:读入源文本与抄袭文本,利用extractKeyword对两文本分别进行分词处理(用到jieba库),并提取其中权重排行前k个词,得到keywords1 keywords2,构造关键词HashTable,利用HashTable进行onehot编码生成两文本对应的关键词向量,最后对向量进行余弦值计算,这边直接用到sklearn中的cosine_similarity 可直接计算余弦相似度。
Part four 计算模块接口部分的性能改进
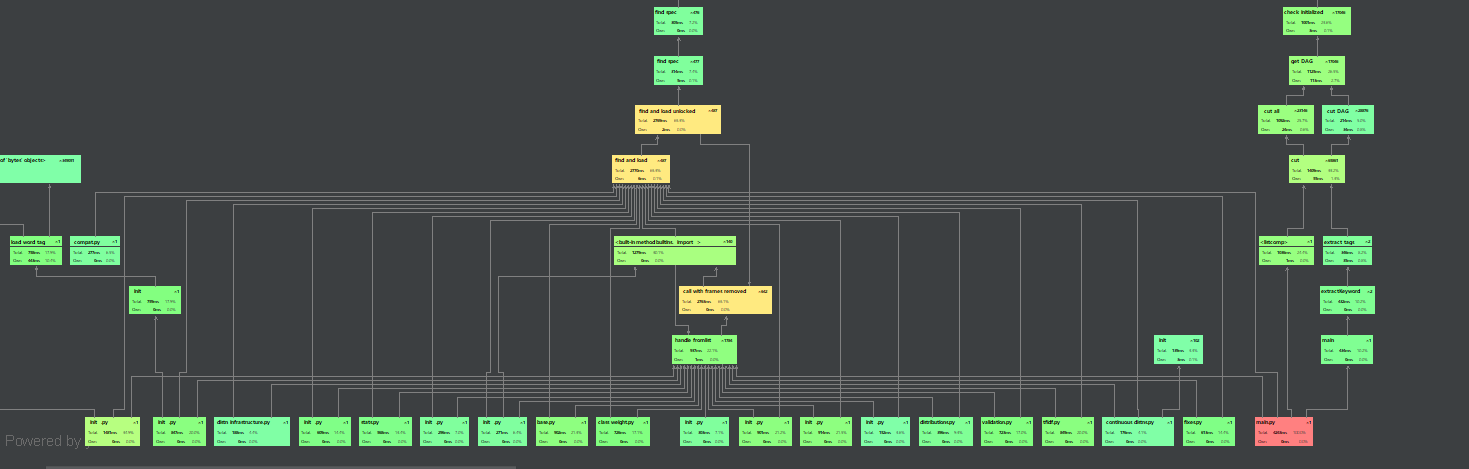
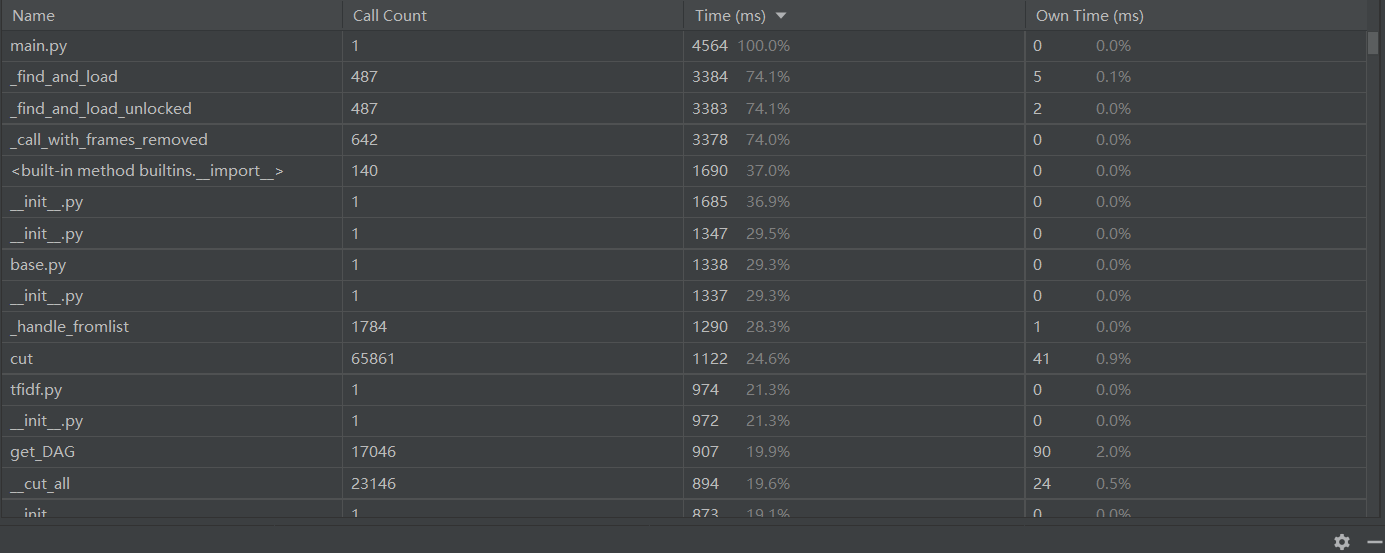
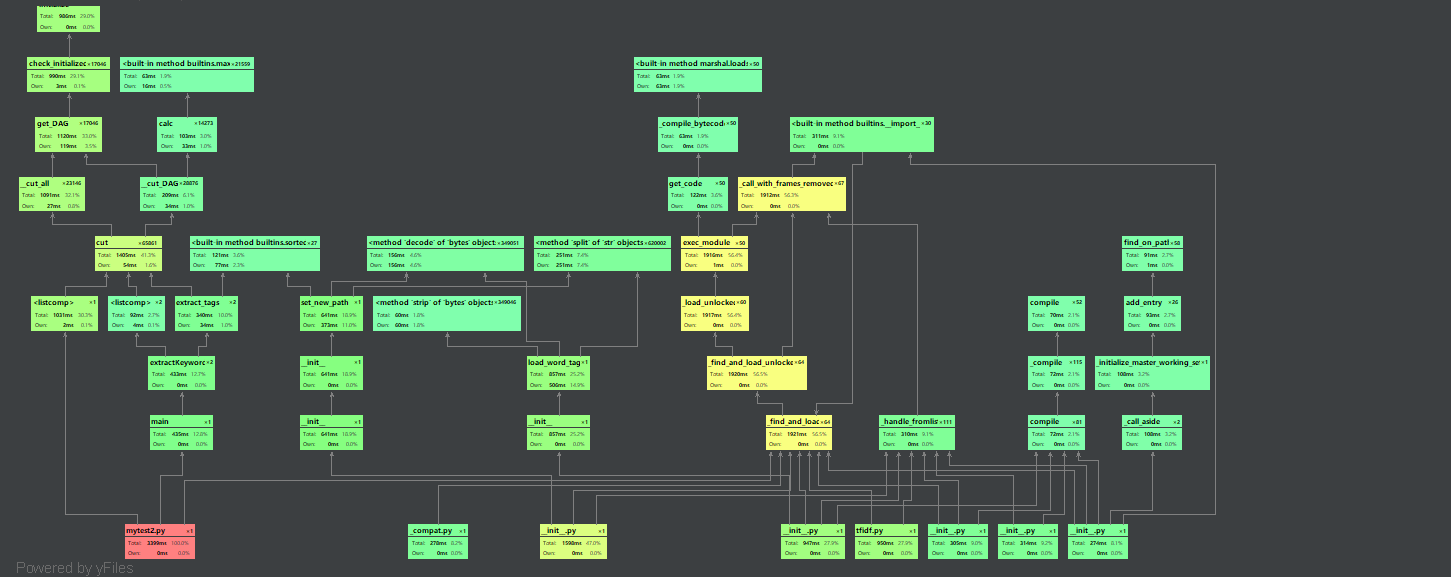
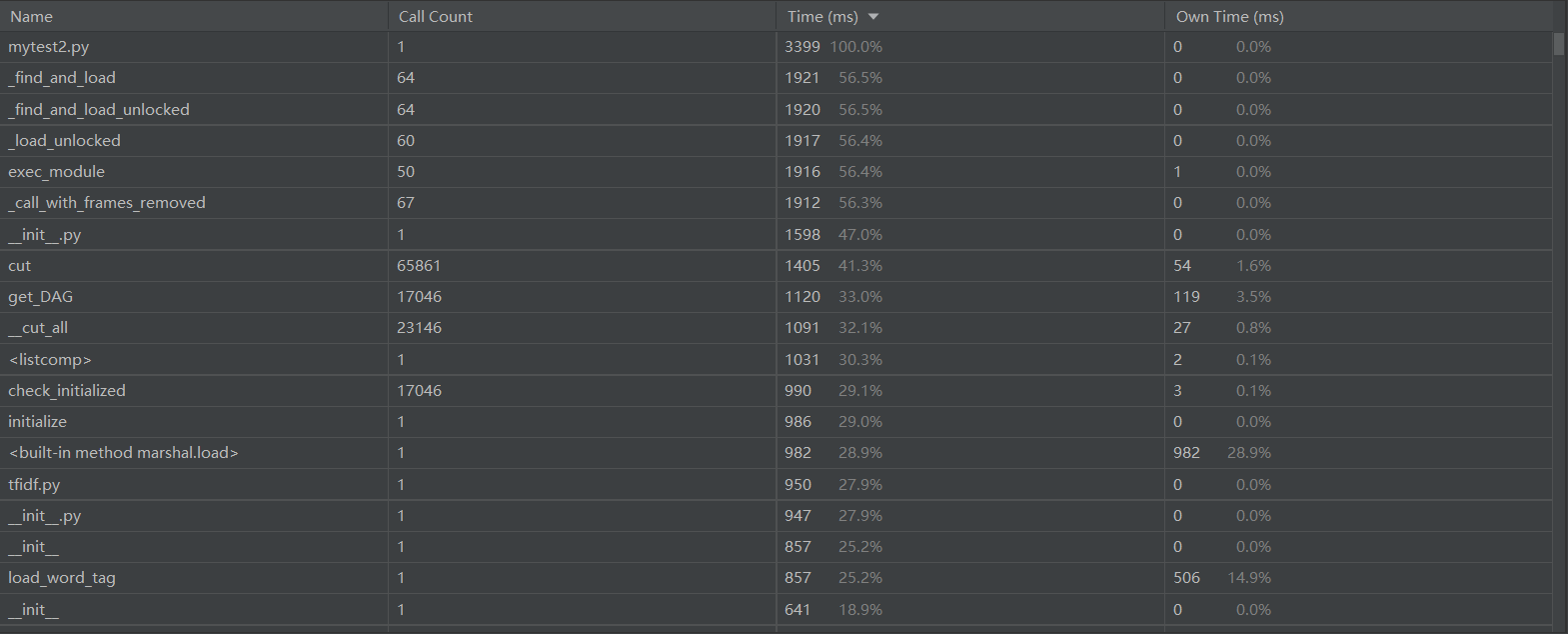
- 整个程序的用时
我发现调用sklearn.metrics.pairwise的cosine_similarity来计算余弦值会占用一大部分时间,之前偷懒不想写公式,本着优化程序的态度,就尝试了一下,不调用cosine_similarity直接计算,通过余弦公式进行计算,然后以下是改进后的性能分析,可以看出整个程序的用时缩短了二秒多。
Part five 计算模块部分单元测试展示
- 参考别人的博客自己写了个测试程序 对于助教提供的样例文本进行测试 以下是测试的输出数据 精确到小数点后两位
- 得出的数据还是蛮符合我的预期的,毕竟肯定做不到每一篇的相似度都在80%左右,稍微有点偏差还是可接受的。
orig_0.8_add.txt 相似度
0.84
test over!
.orig_0.8_del.txt 相似度
0.73
test over!
.orig_0.8_dis_1.txt 相似度
0.89
test over!
.orig_0.8_dis_10.txt 相似度
0.75
test over!
.orig_0.8_dis_15.txt 相似度
0.63
test over!
.orig_0.8_dis_3.txt 相似度
0.87
test over!
.orig_0.8_dis_7.txt 相似度
0.84
test over!
.orig_0.8_mix.txt 相似度
0.8
test over!
.orig_0.8_rep.txt 相似度
0.74
test over!
- 测试程序
import testfunc
import unittest
class MyTest(unittest.TestCase):
def tearDown(self) -> None:
print("test over!")
def test_add(self):
print("orig_0.8_add.txt 相似度")
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("sim_0.8/orig_0.8_add.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = testfunc.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.main(), 2)
print(similarity)
def test_del(self):
print("orig_0.8_del.txt 相似度")
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("sim_0.8/orig_0.8_del.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = testfunc.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.main(), 2)
print(similarity)
def test_dis_1(self):
print("orig_0.8_dis_1.txt 相似度")
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("sim_0.8/orig_0.8_dis_1.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = testfunc.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.main(), 2)
print(similarity)
def test_dis_3(self):
print("orig_0.8_dis_3.txt 相似度")
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("sim_0.8/orig_0.8_dis_3.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = testfunc.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.main(), 2)
print(similarity)
def test_dis_7(self):
print("orig_0.8_dis_7.txt 相似度")
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("sim_0.8/orig_0.8_dis_7.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = testfunc.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.main(), 2)
print(similarity)
def test_dis_10(self):
print("orig_0.8_dis_10.txt 相似度")
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("sim_0.8/orig_0.8_dis_10.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = testfunc.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.main(), 2)
print(similarity)
def test_dis_15(self):
print("orig_0.8_dis_15.txt 相似度")
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("sim_0.8/orig_0.8_dis_15.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = testfunc.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.main(), 2)
print(similarity)
def test_mix(self):
print("orig_0.8_mix.txt 相似度")
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("sim_0.8/orig_0.8_mix.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = testfunc.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.main(), 2)
print(similarity)
def test_rep(self):
print("orig_0.8_rep.txt 相似度")
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("sim_0.8/orig_0.8_rep.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = testfunc.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.main(), 2)
print(similarity)
if __name__ == '__main__':
unittest.main()
- 异常情况的输出数据
- 对于两个文本都是空文本的情况 看一下测试结果
- 对于两个内容一模一样的文本测试相似度是否为1?
E:\python file>python abnormalTest.py
源文本和抄袭文本均为空的情况
0.0
test over!
源文本和抄袭文本内容完全相同的情况
1.0
test over!
- 异常测试程序
import testfunc
import unittest
class MyTest(unittest.TestCase):
def tearDown(self) -> None:
print("test over!")
def test_blank(self):
print("源文本和抄袭文本均为空的情况")
with open("abnormalTest/orig1.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("abnormalTest/test1.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = testfunc.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.main(), 2)
print(similarity)
def test_same(self):
print("源文本和抄袭文本内容完全相同的情况")
with open("abnormalTest/orig2.txt", "r", encoding='UTF-8') as fp:
orig_text = fp.read()
with open("abnormalTest/test2.txt", "r", encoding='UTF-8') as fp:
copy_text = fp.read()
similarity = testfunc.CosineSimilarity(orig_text, copy_text)
similarity = round(similarity.main(), 2)
print(similarity)
if __name__ == '__main__':
unittest.main()
Part six 计算模块部分异常处理说明
- 对输入两篇空文本或者说两篇文本生成的余弦向量是零向量,那么直接对两零向量求余弦值会出问题的(余弦公式分母为0)!需要进行异常处理
try:
# 余弦值求解
# 如果无异常 返回所求的余弦值
except Exception as e:
print(e) # 让我们康康是什么异常
return 0.0 # 对于零向量 余弦值为0
Part seven 本次作业总结
- 一开始看到作业需求时是懵的,然后再看到各种各样的要求,是有点裂开。
- 拥抱开源万岁!这次确实是面向百度、Google、知乎、csdn、Github...编程,说实话看到这个论文查重,一开始我也不知道从哪入手,然后就用搜索引擎各种看,但其实网上查到的算法就普遍的那几种,每个博客虽然实现算法都差不多,但实际上写出来查出的相似度还是有区别的(细节上处理的差别吧),然后就各个博客参考融合,把代码整出来,测了下数据发现还行,没有太大的偏差。
- 之前一直以为软件工程,就是单纯写代码,然后这次作业让我认识到了写代码之前还要各种需求分析,写完代码还要测试性能啥的。
- github之前用过,但也很久没用了,因为这次作业又重新倒腾了一下。另外我感觉写博客也蛮累的,但是写博客的过程,确实能让自己对整个项目再回顾一遍,记录自己完成整个项目的过程,对于后续的学习想必是会有帮助的!

