

【论文阅读】TabTransformer Tabular Data Modeling Using Contextual Embeddings
原始题目:TabTransformer: Tabular Data Modeling Using Contextual Embeddings
中文翻译:TabTransformer:使用上下文嵌入的表格数据建模
发表时间:2020-12-11
平台:arXiv
文章链接:http://arxiv.org/abs/2012.06678
开源代码:https://github.com/lucidrains/tab-transformer-pytorch
摘要
我们提出了TabTransformer,这是一种用于监督和半监督学习的新型深度表格数据建模架构。TabTransformer建立在基于自我关注的Transformers之上。Transformer层将分类特征的嵌入转换为鲁棒的上下文嵌入,以实现更高的预测精度。通过在15个公开可用的数据集上进行广泛的实验,我们表明,对于表格数据,TabTransformer的平均AUC至少比最先进的深度学习方法高出1.0%,并且与基于树的集成模型的性能相匹配。此外,我们证明了从TabTransformer学习的上下文嵌入对缺失和噪声数据特征都具有高度鲁棒性,并提供了更好的可解释性。最后,对于半监督设置,我们开发了一个无监督的预训练程序来学习数据驱动的上下文嵌入,与最先进的方法相比,平均AUC提高了2.1%。
1. 引言
表格数据是许多现实世界应用程序中最常见的数据类型,如推荐系统(Cheng等人,2016)、在线广告(Song等人,2019)和投资组合优化(Ban,El Karoui和Lim,2018)。许多机器学习比赛,如Kaggle和KDD Cup,主要是为了解决表格领域的问题。
最先进的表格数据建模方法是基于树的集成方法,如梯度增强决策树(GBDT)(Chen和Guestrin 2016;Prokhorenkova等人2018)。这与所有现有竞争模型都基于深度学习的图像和文本数据建模形成对比(Sandler等人,2018;Devlin等人2019)。基于树的集成模型可以实现有竞争力的预测精度,训练速度快,易于解释。这些好处使它们在机器学习从业者中非常有利。然而,与深度学习模型相比,基于树的模型有几个局限性。(a) 它们不适合从流数据进行连续训练,并且不允许在存在多模态和表格数据的情况下对图像/文本编码器进行有效的端到端学习。(b) 在它们的基本形式中,它们不适合最先进的半监督学习方法。这是因为基本决策树学习器不能对其预测产生可靠的概率估计(Tanha,Someren,and Afsarmanesh 2017)。(c) 处理缺失和噪声数据特征的最先进的深度学习方法(Devlin等人,2019)并不适用于它们。此外,基于树的模型的鲁棒性在文献中也没有得到太多研究。
多层感知器(MLP)是一种经典且流行的模型,该模型使用梯度下降进行训练,因此允许图像/文本编码器的端到端学习。MLP通常学习参数嵌入来编码分类数据特征。但由于其肤浅的架构和上下文无关的嵌入,它们有以下局限性:(a)模型和学习的嵌入都不可解释;(b) 它对丢失和有噪声的数据不具有鲁棒性(第3.2节);(c) 对于半监督学习,他们没有取得有竞争力的表现(第3.4节)。最重要的是,MLP在大多数数据集上与基于树的模型(如GBDT)的性能不匹配(Arik和Pfister 2019)。为了弥补MLP和GBDT之间的这种性能差距,研究人员提出了各种深度学习模型(Song等人,2019;Cheng等人2016;Arik和Pfister 2019;郭等人2018)。尽管这些深度学习模型实现了可比的预测精度,但它们并没有解决GBDT和MLP的所有局限性。此外,它们的比较是在少数数据集的有限环境中进行的。特别是,在第3.3节中,我们展示了在大量数据集上与标准GBDT相比,GBDT的性能明显优于这些最近的模型。
在本文中,我们提出了TabTransformer来解决MLP和现有深度学习模型的局限性,同时弥合MLP和GBDT之间的性能差距。我们通过在15个公开可用的数据集上进行广泛的实验,建立了TabTransformer的性能增益。
TabTransformer建立在Transformers之上(Vaswani等人,2017),用于学习分类特征的有效上下文嵌入。与表格域不同,嵌入在NLP中的应用已经得到了广泛的研究。使用嵌入在密集的低维空间中对单词进行编码在自然语言处理中很普遍。从Word2Verc(Rong 2014)的上下文无关单词嵌入到BERT(Devlin et al.2019)的上下文单词标记嵌入,嵌入在NLP中得到了广泛的研究和应用。与无上下文嵌入相比,基于上下文嵌入的模型(Mikolov et al.2011;Huang,Xu,and Yu 2015;Devlin et al.2019)取得了巨大成功。特别是,基于自我关注的变压器(Vaswani等人,2017)已成为NLP模型的标准组件,以实现最先进的性能。Transformers生成的上下文嵌入的有效性和可解释性也得到了很好的研究(Coenen等人,2019;Brunner等人2019)。
受变压器在NLP中成功应用的启发,我们将其应用于表格领域。特别是,TabTransformer在参数嵌入上应用了一系列基于多头注意力的Transformer层,将其转换为上下文嵌入,弥合了基线MLP和GBDT模型之间的性能差距。我们研究了Transformers生成的上下文嵌入的有效性和可解释性。我们发现,高度相关的特征(包括同一列和交叉列中的特征对)导致嵌入向量在欧几里得距离上接近,而在基线MLP模型中学习的上下文无关嵌入中不存在这种模式。我们还研究了TabTransformer对随机丢失和噪声数据的鲁棒性。与MLP相比,上下文嵌入使它们具有高度的鲁棒性。
此外,许多现有的表格数据深度学习模型是为监督学习场景设计的,但很少有用于半监督学习(SSL)。不幸的是,在计算机视觉中开发的最先进的SSL模型(Voulodimos等人,2018;Kendall和Gal 2017)和NLP(Vaswani等人,2017;Devlin等人2019)无法轻易扩展到表格域。受这些挑战的启发,我们利用语言模型中的预训练方法,并提出了一种半监督学习方法,用于使用未标记数据预训练我们的TabTransformer模型的Transformer。
我们提出的半监督学习方法的主要优点之一是两个独立的训练阶段:对未标记数据的昂贵预训练阶段和对标记数据的轻量级微调阶段。这与许多最先进的半监督方法不同(Chapelle、Scholkopf和Zien 2009;Oliver等人2018;Stretcu等人2019),这些方法需要一项培训工作,包括标记和未标记的数据。分离的训练过程有利于对模型进行一次预训练,但需要对多个目标变量进行多次微调。事实上,这种情况在工业环境中很常见,因为公司往往有一个大型数据集(例如描述客户/产品),并有兴趣对这些数据进行多重分析。总之,我们提供了以下贡献:
- 我们提出了TabTransformer,这是一种提供并利用类别特征的上下文嵌入的架构。我们提供了大量的经验证据,表明TabTransformer在表格数据方面优于基线MLP和最近的深度网络,同时与基于树的集成模型(GBDT)的性能相匹配。
- 与现有技术实现的参数上下文无关嵌入相比,我们研究了由此产生的上下文嵌入,并强调了它们的可解释性。
- 我们展示了TabTransformer对噪声和丢失数据的鲁棒性。
- 我们提供并广泛研究了一种针对表格数据的两阶段预训练然后微调程序,击败了半监督学习方法的最先进性能。
2. TabTransformer
TabTransformer架构包括列嵌入层、N个Transformer层的堆栈和多层感知器。每个Transformer层(Vaswani等人,2017)由一个多头自注意层和一个位置前馈层组成。TabTransformer的体系结构如下图1所示。
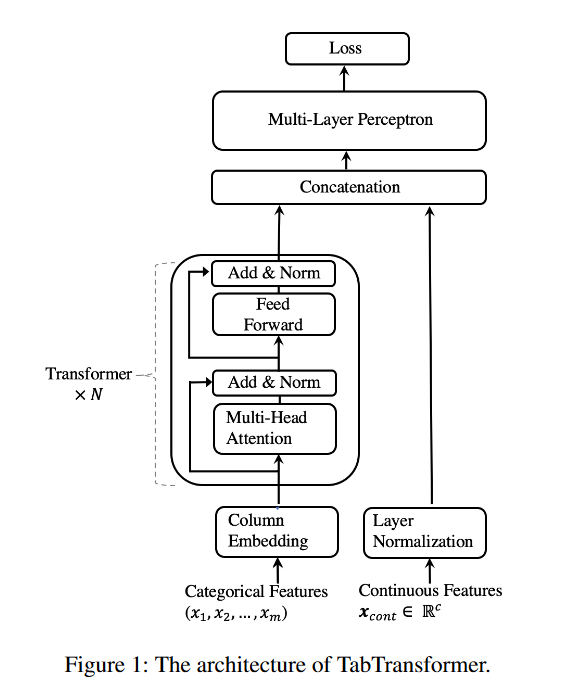
设(x,y)表示特征-目标对,其中\(x\equiv \{x_{\mathrm{cat}},x_{\mathrm{cont}}\}\) 。\(x_{\mathrm{cat}}\)表示所有的范畴特征,\(x_{\mathrm{cont}}\in\mathbb{R}^c\)表示所有的c个连续特征。设\(x_{\mathrm{cat}}\equiv\{x_{1},x_{2},\cdots,x_{m}\}\),其中每个xi是范畴特征,对于\(i\in\{1,\cdots,m\}\)。
我们使用列嵌入将每个xi分类特征嵌入到维度d的参数嵌入中,下面将对此进行详细解释。设\(e_{\phi_i}(x_i)\in\mathbb{R}^d\)对\(i\in\{1,\cdots,m\}\)是xi特征的嵌入,\(E_{\phi}(x_{\mathrm{cal}})=\{e_{\phi_{1}}(x_{1}),\cdots,e_{\phi_{m}}(x_{m})\}\)是所有范畴特征的嵌入集。
接下来,这些参数嵌入\(E_\phi(x_{\mathrm{cat}})\)被输入到第一Transformer层。第一变压器层的输出被输入到第二变压器层,以此类推。当从顶层Transformer输出时,通过来自其他嵌入的上下文的连续聚合,每个参数嵌入都被转换为上下文嵌入。我们将Transformer层的序列表示为函数\({f}_{\theta}\)。函数\({f}_{\theta}\)对参数嵌入\(\{e_{\phi_1}(x_1),\cdots,e_{\phi_m}(x_m)\}\)进行运算,并返回相应的上下文嵌入\(\{h_{1},\cdots,h_{m}\}\),其中\(h_i\in\mathbb{R}^d\)对于\(i\in\{1,\cdots,m\}\)。
上下文嵌入\(\{h_{1},\cdots,h_{m}\}\)与连续特征\(x_{\mathrm{cont}}\)连接,形成维度为(d×m+c)的向量。该向量被输入到MLP,用\(g_{\psi}\)表示,以预测目标y。设\(H\)为分类任务的交叉熵,为回归任务的均方误差。我们最小化以下损失函数\({\mathcal{L}}(x,y)\),以通过一阶梯度方法在端到端学习中学习所有TabTransformer参数。TabTransformer参数包括列嵌入的φ、Transformer层的θ和顶部MLP层的ψ。
下面,我们将解释Transformer层和列嵌入。
**Transformer **Transformer(Vaswani等人,2017)由一个多头自注意层和一个位置前馈层组成,每个层之后进行元素添加和层归一化。自注意层包括三个参数矩阵Key、Query和Value。每个输入嵌入都被投影到这些矩阵上,以生成它们的键、查询和值向量。形式上,设\({K}\in\mathbb{R}^{m\times k}\),\(Q\in\mathbb{R}^{m\times k}\)和\(V\in\mathbb{R}^{m\times v}\)分别是包含所有嵌入的键向量、查询向量和值向量的矩阵,m是输入到Transformer的嵌入数,K和V分别是键向量和值矢量的维数。每个输入嵌入都通过注意力头来关注所有其他嵌入,其计算如下:
其中\(A=\mathrm{softmax}((QK^{T})/\sqrt{k})\)。对于每个嵌入,注意力矩阵\({A}\in\mathbb{R}^{{m}\times m}\)计算它对其他嵌入的关注程度,从而将嵌入转换为上下文嵌入。维度v的注意力头的输出通过完全连接层被投影回维度d的嵌入,该完全连接层又通过两个位置前馈层。第一层将嵌入扩展到其大小的四倍,第二层将嵌入投影回其原始大小。
列嵌入。对于每个分类特征(列)i,我们有一个嵌入查找表\(e_{\phi_{i}}(.)\),对于\(i\in\{1,\cdots,m\}\)。对于具有\(d_{i}\)类的第i个特征,嵌入表\(e_{\phi_{i}}(.)\)具有\((d_{i}+1)\)个嵌入,其中附加嵌入对应于缺失值。编码值\(x_{i}=j\in[0,1,2,..,d_{i}]\)的嵌入是\(e_{\phi_{k}}(j)=[c_{\phi_{i}},w_{\phi_{ij}}]\),其中\(c_{\phi_i}\in\mathbb{R}^\ell,w_{\phi_{i,j}}\in\mathbb{R}^{d-t}\)。\(c_{\phi}\)的维数\(l\)是一个超参数。唯一标识符\(c_{\phi_{i}}\in\mathbb{R}^{\ell}\)将列i中的类与其他列中的类区分开来。
唯一标识符的使用是新的,特别是为表格数据而设计的。相反,在语言建模中,嵌入是与单词在句子中的位置编码一起明智地添加的。由于在表格数据中,并没有对特征进行排序,所以我们不使用位置编码。附录A中给出了对不同嵌入策略的消融研究。这些策略包括对\(l\)、d和元素的不同选择,添加唯一标识符和特征值特定嵌入,而不是将它们连接起来。
预训练嵌入。上面解释的上下文嵌入是在使用标记示例的端到端监督训练中学习的。对于一个场景,当有几个标记的示例和大量未标记的示例时,我们引入了一个预训练过程,以使用未标记的数据来训练Transformer层。然后使用标记的数据对预训练的Transformer层以及顶部MLP层进行微调。对于微调,我们使用方程(1)中定义的监督损失。
我们探索了两种不同类型的预训练过程,掩蔽语言建模(MLM)(Devlin等人,2019)和替换标记检测(RTD)(Clark等人,2020)。给定输入\(x_{\mathrm{cat}}=\{x_{1},x_{2},...,x_{m}\}\),MLM从索引1到m随机选择k+个特征,并将它们屏蔽为缺失。Transformer层和列嵌入是通过最小化多类分类器的交叉熵损失来训练的,该多类分类器试图根据从顶层Transformer输出的上下文嵌入来预测掩蔽特征的原始特征。
RTD不屏蔽特征,而是用该特征的随机值替换原始特征。这里,对于试图预测特征是否已被替换的二进制分类器,损失被最小化。(Clark等人,2020)中提出的RTD程序使用辅助生成器对应替换特征的特征子集进行采样。他们使用辅助编码器网络作为生成器的原因是,语言数据中有数以万计的令牌,而统一随机的令牌太容易检测。相反,(a)每个分类特征内的类的数量通常是有限的;(b) 每个列都定义了不同的二进制分类器,而不是共享的,因为每个列都有自己的嵌入查找表。我们将两种预训练方法命名为TabTransformer MLM和TabTransformer RTD。在我们的实验中,替换值k被设置为30。关于k的消融研究见附录A。
3. Experiments
数据。 我们在来自UCI知识库(Dua和Graff 2017)、AutoML挑战(Guyon et al.2019)和Kaggle(Kaggle,股份有限公司2017)的15个公开可用的二进制分类数据集上评估了TabTransformer和基线模型,用于监督和半监督学习。每个数据集分为五个交叉验证部分。每次拆分的数据的训练/验证/测试比例为65/15/20%。整个数据集的分类特征的数量在2到136之间。在半监督实验中,对于每个数据集和分割,训练数据中的前p个观测值被标记为标记数据,剩余的训练数据被标记为未标记集。p的值被选择为50、200和500,对应于3个不同的场景。在监督实验中,每个训练数据集都被完全标记。所有数据集的汇总统计数据见附录C表8、9。
设置。对于TabTransformer,隐藏(嵌入)维度、层数和注意力头的数量分别固定为32、6和8。MLP层大小设置为{4×l,2×l},其中l是其输入的大小。对于超参数优化(HPO),为每个交叉验证划分给每个模型20轮HPO。对于评估指标,我们使用曲线下面积(AUC)(Bradley 1997)。请注意,预训练仅适用于半监督场景。当整个数据都被标记时,我们没有发现使用它有多大好处。当存在大量未标记的实例和少数标记的实例时,其益处是显而易见的。由于在这种情况下,预训练提供了数据的表示,而这些数据不能仅基于标记的示例来学习。
实验部分组织如下。在第3.1节中,我们首先通过将我们的模型与没有变压器的模型(相当于MLP模型)进行比较来证明基于注意力的变压器的有效性。在第3.2节中,我们说明了TabTransformer对噪声和丢失数据的鲁棒性。最后,第3.3节针对监督学习和第3.4节针对半监督学习对各种方法进行了广泛评估。
3.1 Transformer层的有效性
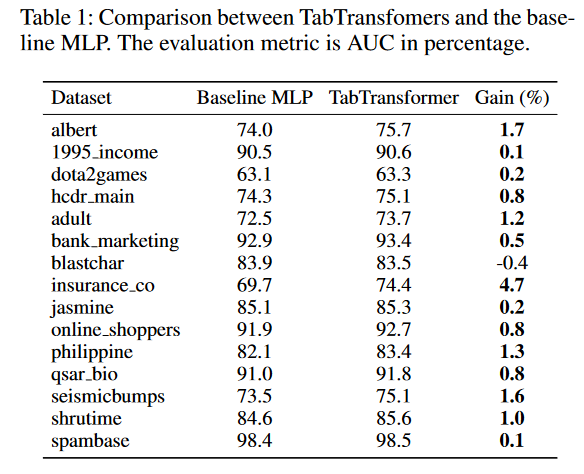
首先,在监督学习场景中对TabTransformers和基线MLP进行比较。我们从架构中移除Transformer层\({f}_{\theta}\),固定其余组件,并将其与原始TabTransformer进行比较。没有基于注意力的Transformer层的模型等效为MLP。对于两个模型,分类特征的嵌入的维数d都设置为32。15个数据集的比较结果如表1所示。具有Transformer层的TabTransformer在15个数据集中的14个数据集上优于基线MLP,AUC平均增益为1.0%。
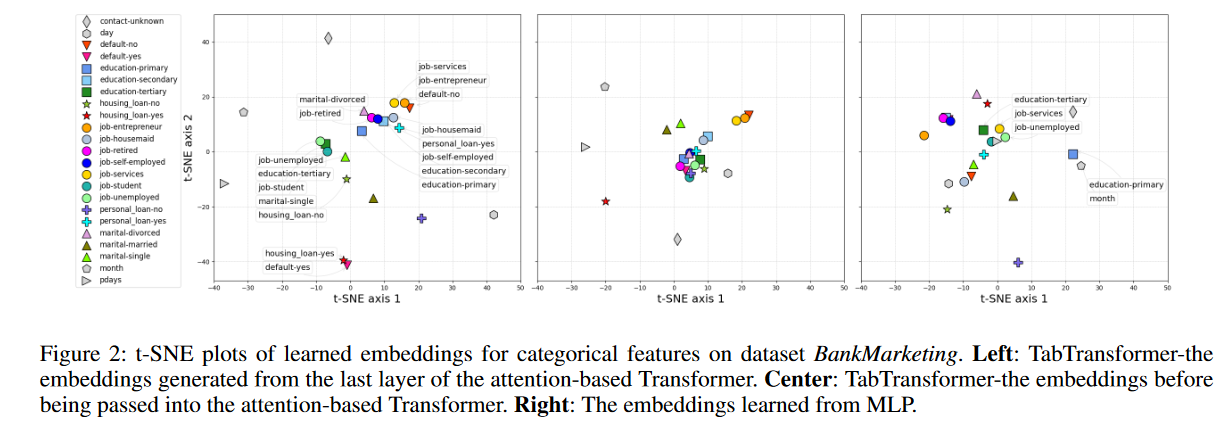
接下来,我们从Transformer的不同层获取上下文嵌入,并计算t-SNE图(Maaten和Hinton 2008),以可视化它们在函数空间中的相似性。更准确地说,对于每个数据集,我们获取其测试数据,将其分类特征传递到经过训练的TabTransformer中,并从Transformer的某一层提取所有上下文嵌入(跨所有列)。然后使用t-SNE算法将每个嵌入减少到t-SNE图中的2D点。图2(左)显示了用于数据集银行营销的Transformer最后一层嵌入的2D可视化。图中的每个标记表示特定类别的测试数据点上的2D点的平均值。我们可以看到,语义相似的类彼此接近,并在嵌入空间中形成簇。每个集群都由一组标签进行注释。例如,我们发现所有基于客户的特征(颜色标记),如工作、教育水平和军事状态,都位于中心区域,而非基于客户的特性(灰色标记),例如月(一年中最后一个接触月)、日(一周中最后一次接触日)位于中心区域之外;在底部聚类中,拥有住房贷款的嵌入与违约的嵌入保持接近;在左聚类上,学生身份、单身身份、无住房贷款和高等教育水平的嵌入聚在一起;在正确的集群中,教育水平与职业类型密切相关(Torpey和Watson,2014)。在图2中,中间和右边的图分别是通过Transformer之前的嵌入的t-SNE图和来自MLP的无上下文嵌入。对于传递到Transformer之前的嵌入,它开始区分非基于客户端的特征(灰色标记)和基于客户端的功能(颜色标记)。对于来自MLP的嵌入,我们没有观察到这样的模式,并且许多语义上不相似的分类特征被分组在一起,如图中的注释所示。
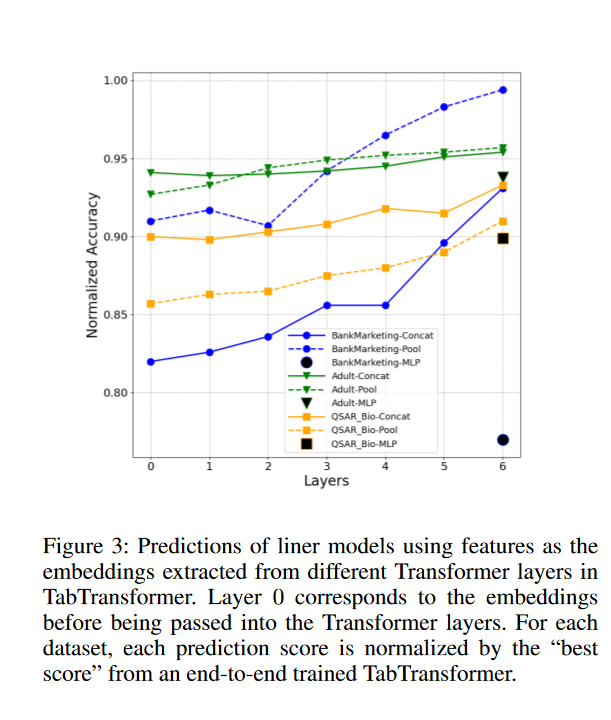
除了证明Transformer层的有效性外,在测试数据上,我们从经过训练的TabTransformer的每个Transformer层获取所有上下文嵌入,使用每个层的嵌入以及连续变量作为特征,并分别拟合具有目标y的线性模型。由于所有实验数据集都用于二元分类,因此线性模型是逻辑回归。这种评估的动机是将简单线性模型的成功定义为学习嵌入的质量度量
对于每个数据集和每个层,计算测试数据上AUC的CV得分的平均值。对数据点数量超过9000的整个测试数据进行评估。图3显示了BankMarketing、Adult和QSAR Bio数据集的结果。对于每一行,每个预测分数都通过相应数据集的端到端训练的TabTransformer的“最佳分数”进行归一化。我们还提出了平均和最大池策略(Howard和Ruder 2018),而不是将嵌入的级联作为线性模型的特征。向上的模式清楚地表明,随着Transformer层的进展,嵌入变得更加有效。相反,来自MLP(单个黑色标记)的嵌入在线性模型中表现更差。此外,每行中接近1.0的最后一个值表明,以最后一层嵌入为特征的线性模型可以实现可靠的精度,这证实了我们的假设。
3.2 TabTransformer的稳健性
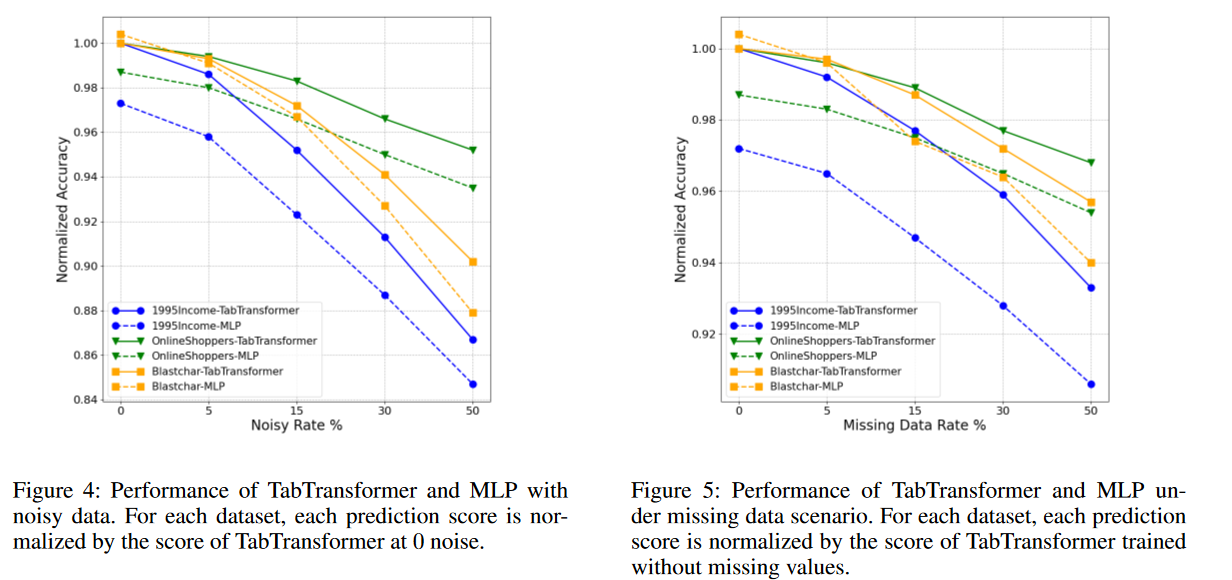
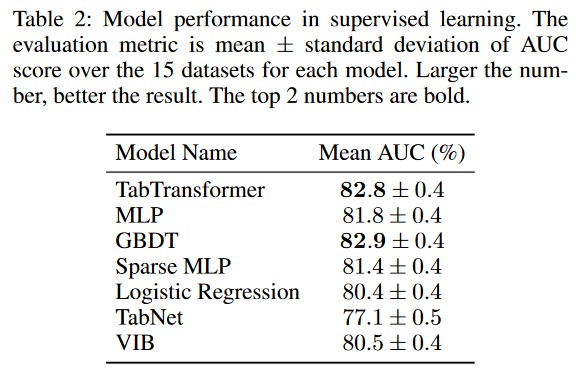
我们进一步证明了TabTransformer在有噪声数据和具有缺失值的数据上相对于基线MLP的稳健性。我们仅在分类特征上考虑这两种场景,以具体证明来自Transformer层的上下文嵌入的稳健性。
噪声数据。在测试示例中,我们首先通过用相应列(特征)中随机生成的值替换一定数量的值来污染数据。接下来,将噪声数据传递到经过训练的TabTransformer中,以计算预测AUC得分。一组3个不同数据集的结果如图4所示。随着噪声率的增加,TabTransformer在预测精度方面表现得更好,因此比MLP更稳健。特别要注意的是,Blastchar数据集的性能几乎相同,没有噪声,但随着噪声的增加,与基线相比,TabTransformer的性能显著提高。我们推测鲁棒性来自嵌入的上下文属性。尽管特征是有噪声的,但它从正确的特征中提取信息,允许进行一定量的校正。
缺少值的数据。类似地,在测试数据上,我们人为地选择一些缺失的值,并将具有缺失值的数据发送到经过训练的TabTransformer以计算预测得分。有两种选项可以处理缺失值的嵌入:(1)在相应列中的所有类上使用平均学习嵌入;(2) 缺失值类的嵌入,第2节中提到的每列的附加嵌入。由于基准数据集没有包含足够的缺失值来有效地训练选项(2)中的嵌入,我们使用(1)中的平均嵌入进行插补。相同3个数据集的结果如图5所示。我们可以看到噪声数据情况的相同模式,即TabTransformer在处理缺失值方面比MLP表现出更好的稳定性。
3.3 监督学习
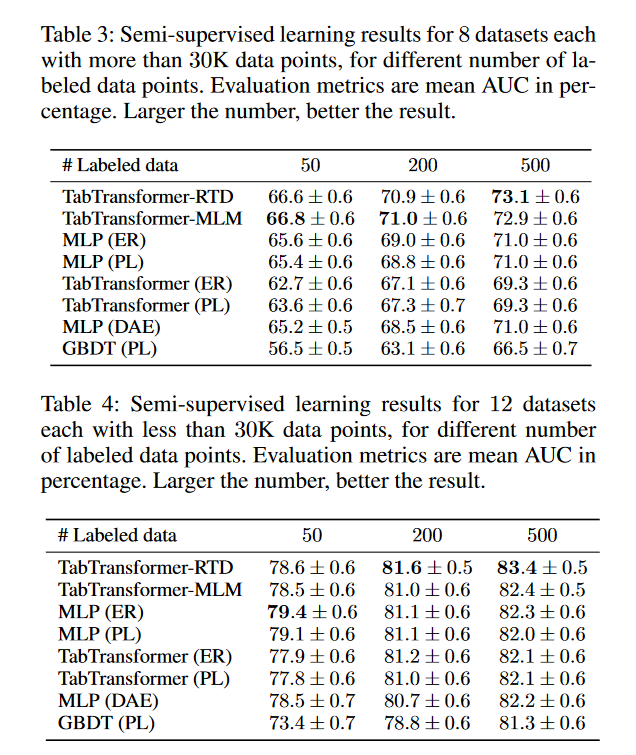
在这里,我们将TabTransformer的性能与以下四类方法进行了比较:(a)逻辑回归和GBDT(b)MLP和稀疏MLP(Morcos等人,2019)(c)Arik和Pfister的TabNet模型(2019)(d)以及Alemi等人的变分信息瓶颈模型(VIB)。(2017)。
结果汇总在表2中。TabTransformer、MLP和GBDT是表现最好的三个。TabTransformer的平均增益为1.0%,优于基线MLP,性能与GBDT相当。此外,TabTransformer明显优于最近用于表格数据的深度网络TabNet和VIB。有关实验和模型的详细信息,请参阅附录B。每个单独数据集上的模型性能如附录C中的表16和表17所示。
3.4 半监督学习
最后,我们在半监督学习场景下评估TabTransformer,其中很少有标记的训练示例和大量的未标记样本可用。具体而言,我们将我们预训练然后微调的TabTransformer RTD/MLM与以下半监督模型进行了比较:(a)熵正则化(ER)(Grandvalent和Bengio 2006)与MLP相结合,以及TabTransformer(b)伪标记(PL)(Lee 2013)与MLP、TabTransformer和GBDT相结合(Jain 2017)(c)MLP(DAE):一种为表格数据上的深度模型设计的无监督预训练方法:交换噪声去噪自动编码器(Jahrer 2018)。
预训练模型TabTransformer MLM、TabTransformer RTD和MLP(DAE)首先在整个未标记的训练数据上进行预训练,然后在标记的数据上进行微调。半监督学习方法,伪标记和熵正则化,是在标记和未标记的训练数据的混合上训练的。为了更好地呈现结果,我们将15个数据集划分为两个子集。第一组包括6个数据点超过30K的数据集,第二组包括其余9个数据集。
结果如表3和表4所示。当未标记数据的数量很大时,表3显示我们的TabTransformer RTD和TabTransformer MLM显著优于所有其他竞争对手。特别是,在50、200和500个标记数据点的情况下,TabTransformer RTD/MLM的平均AUC分别比所有其他竞争对手提高了至少1.2%、2.0%和2.1%。基于Transformer的半监督学习方法TabTransformer(ER)和TabTransformer。当未标记数据的数量变少时,如表4所示,TabTransformer RTD仍然优于大多数竞争对手,但略有改进。
此外,我们观察到,如表4所示,当未标记数据的数量较少时,TabTransformerRTD比TabTransformer MLM表现更好,这要归功于其比MLM(多类分类)更容易的预训练任务(二进制分类)。这与ELECTRA论文的发现一致(Clark等人,2020)。在表4中,只有50个标记的数据点,MLP(ER)和MLP(PL)击败了我们的TabTransformer RTD/MLM。这可以归因于我们的微调程序还有改进的空间。特别地,我们的方法允许获得信息嵌入,但不允许用未标记的数据训练分类器本身的权重。由于ER和PL不会出现这种问题,因此它们在极小的标记集中获得优势。然而,我们指出,这只意味着这些方法是互补的,并提到可能的后续行动可以结合所有方法中最好的方法。
表3和表4的评估结果都表明,我们的TabTransformer RTD和Transformers MLM模型在从未标记数据中提取有用信息以帮助监督训练方面很有前景,并且在未标记数据的大小较大时尤其有用。关于每个单独数据集的模型性能,请参见附录C中的表10、11、12、13、14、15。
4. 相关工作
监督学习。多年来,标准MLP已应用于表格数据(De Bŕebisson等人,2015)。对于专门为表格数据设计的深度模型,有深度版本的因子分解机(Guo et al.2018;肖等人2017)、基于Transformers的方法(Song et al.2019;李等人2020;孙等人2019)和深度版本的基于决策树的算法(Ke et al.2019,Yang、Morillo和Hospedales 2018)。特别是,(Song等人,2019)在嵌入上应用一层多头注意力来学习更高阶的特征。将高阶特征串接并输入到完全连接的层以进行最终预测。(Li et al.2020)使用自注意力层并跟踪注意力得分来获得特征重要性得分。(Sun等人,2019)将因子分解机模型与变压器机制相结合。这三篇论文都集中在推荐系统上,很难与本文进行明确的比较。其他模型是围绕表格数据的所谓特性设计的,如低阶和稀疏特征交互。其中包括深度和交叉网络(Wang et al.2017)、广域和深度网络(Cheng et al.2016)、TabNets(Arik和Pfister 2019)和AdaNet(Cortes et al.202016)。
半监督学习。(Izmailov等人2019)给出了一种基于密度估计的半监督方法,并在表格数据上评估了他们的方法。伪标记(Lee,2013)是一种简单、高效且流行的基线方法。伪标记使用当前网络,通过选择最有信心的类来推断未标记示例的伪标记。在交叉熵损失中,这些伪标签被视为人类提供的标签。标签传播(Zhu和Ghahramani,2002),(Iscen等人,2019)是一种类似的方法,其中节点的标签根据其接近度传播到所有节点,并被训练模型使用,就好像它们是真正的标签一样。半监督学习中的另一种标准方法是熵正则化(Grandvalent和Bengio 2005;Sajjadi、Javanmardi和Tasdizen 2016)。它将未标记示例的平均每样本熵添加到标记示例的原始损失函数中。半监督学习的另一种经典方法是联合训练(Nigam和Ghani,2000年)。然而,最近的方法——熵正则化和伪标记——通常更好、更受欢迎。对一般半监督学习方法的简要回顾可以在(Oliver等人,2019;Chappelle、Schöolkopf和Zien,2010年)中找到。
5. 结论
我们提出了TabTransformer,这是一种新的用于监督和半监督学习的深度表格数据建模架构。我们提供了大量的经验证据,表明TabTransformer在表格数据方面显著优于MLP和最近的深度网络,同时与基于树的集成模型(GBDT)的性能相匹配。我们提供并广泛研究了表格数据的两阶段预训练-然后微调过程,击败了半监督学习方法的最新性能。TabTransformer在对抗噪声和丢失数据的鲁棒性以及上下文嵌入的可解释性方面显示了有希望的结果。对于未来的工作,详细调查它们将是一件有趣的事情。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 推荐几款开源且免费的 .NET MAUI 组件库
· 易语言 —— 开山篇
· 实操Deepseek接入个人知识库
· Trae初体验