

Word2vec模型:CBOW
本文word2vec原理参考:NLP扎实基础2:Word2vec模型CBOW Pytorch复现
看过之后,基本上是能够理解的,在自己的电脑上运行时,对一些地方有困惑,经过查阅相关资料后才搞懂,另外,原博客中的代码还有一些bug一并解决。
1. CBOW是如何实现的
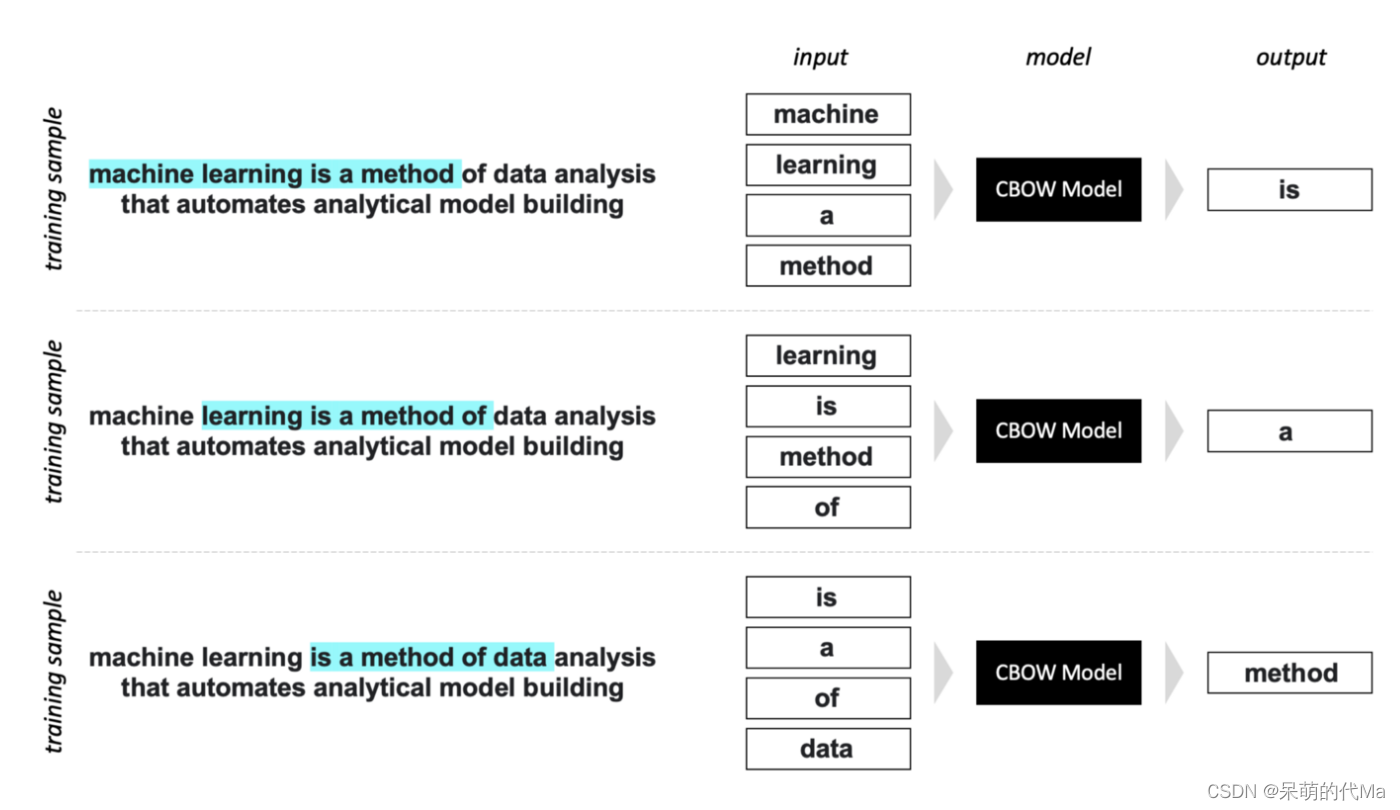
结合上述原理图,可以知道CBOW训练的主要思路是用背景词预测中心词。在没有看代码之前,对于损失计算,我的想法是:使用背景词的预测结果与当前中心词的词嵌入向量计算损失。实际上训练词嵌入的网络的最后一层的形状是(隐藏层个数,单词表个数),所以在最后一层前应该要做softmax,这种做法应该是更合适的,使用当前中心词的词嵌入向量是一种以当前最优值替代理想最优的想法,应该也能行得通,不过可能训练的时间要更久(没有实验验证)。
2. 交叉熵损失
在看到使用交叉熵损失代码的时候,一看到会觉得不太对劲,损失计算的前后两个对象并不一致,这个就属于代码经验不足了。
一个运行错误
# loss = criterion(model_out, center_token)
loss = criterion(model_out, center_token.long())
原代码是python2版本的,直接运行会报错误“RuntimeError: expected scalar type Long but found Int”,修改一下即可。
