python3读写csv文件
python读取CSV文件
python中有一个读写csv文件的包,直接import csv即可。利用这个python包可以很方便对csv文件进行操作,一些简单的用法如下。
1. 读文件
csv_reader = csv.reader(open('data.file', encoding='utf-8'))
for row in csv_reader:
print(row)
例如有如下的文件
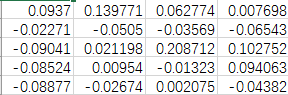
输出结果如下
['0.093700','0.139771','0.062774','0.007698']
['-0.022711','-0.050504','-0.035691','-0.065434']
['-0.090407','0.021198','0.208712','0.102752']
['-0.085235','0.009540','-0.013228','0.094063']
可见csv_reader把每一行数据转化成了一个list,list中每个元素是一个字符串。
2. 写文件
读文件时,我们把csv文件读入列表中,写文件时会把列表中的元素写入到csv文件中。
list = ['1', '2','3','4']
out = open(outfile, 'w') csv_writer = csv.writer(out) csv_writer.writerow(list)
可能遇到的问题:直接使用这种写法会导致文件每一行后面会多一个空行。
解决办法如下:
out = open(outfile, 'w', newline='') csv_writer = csv.writer(out, dialect='excel') csv_writer.writerow(list)
参考如下:
在stackoverflow上找到了比较经典的解释,原来 python3里面对 str和bytes类型做了严格的区分,不像python2里面某些函数里可以混用。所以用python3来写wirterow时,打开文件不要用wb模式,只需要使用w模式,然后带上newline=''。
|
In Python 2.X, it was required to open the csvfile with 'b' because the csv module does its own line termination handling. In Python 3.X, the csv module still does its own line termination handling, but still needs to know an encoding for Unicode strings. The correct way to open a csv file for writing is:
|


1 class writer(): 2 def __init__(self): 3 self.dict={ 4 "标题":"标题", 5 "链接":"链接", 6 "服务":"服务", 7 "dsr":"dsr", 8 "店铺名":"店铺名", 9 "价格":"店铺名", 10 "付款人数":"付款人数", 11 "发货地":"发货地" 12 } 13 out = open("outfile.csv", 'w', newline='') 14 self.csv_writer = csv.writer(out, dialect='excel') 15 self.csv_writer.writerow(self.dict) 16 17 def writer_to(self,key_value): 18 self.csv_writer.writerow(key_value) 19 20 21 if __name__ == '__main__': 22 a=writer() 23 new={"链接":"http://www.baidu.com",'标题':'我是标题',} 24 a.dict.update(new) 25 print(a.dict) 26 a.writer_to(a.dict.values())
import csv from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException, NoSuchElementException from selenium.webdriver.common.action_chains import ActionChains driver=['1','2'] colspan=['1','2'] try: out = open('类目.csv', 'w', newline='') except PermissionError: print('文件被其他程序占用') input('') csv_writer = csv.writer(out, dialect='excel') csv_writer.writerow(['宝贝ID','类目']) def open_chrome(): driver[0]=webdriver.Chrome() driver[0].get('https://www.dianchacha.com') input('请登陆后按回车:') def EC_located(one_group,value): ''' 目的:简化代码长度,参数1选择one或者group切换选中模式 :param value:要找的值【CSS选择器】 :return:选择到的对象 ''' wait = WebDriverWait(driver[0], 10) if one_group=="one": try: ecl=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,value))) return ecl except TimeoutException: print(value,'1元素未加载成功,等待超时') else: try: ecl=wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,value))) return ecl except TimeoutException: print(value,'1元素---组---未加载成功,等待超时') def operating(ID): #先获取ID输入框 driver[0].get('https://www.dianchacha.com/item/info/index/iid/'+ID) html=driver[0].page_source if '未能找到亲的宝贝' not in html: colspans=EC_located('group','.colspan-1') colspan[0]=str(colspans[1].text).replace('宝贝类目: ','') else: return operating(ID) print(colspan) def writer_txt(): csv_writer.writerow([url[0],colspan[0]]) print('保存',url[0],colspan[0],'成功') url=['0','1'] def main(): open_chrome() file = '宝贝ID.txt' with open(file) as f: for line in f.readlines(): url[0] = line print(line) operating(url[0]) writer_txt() out.close() print('已完成') if __name__ == '__main__': main()

