

pytorch学习笔记4
pytorch学习笔记4

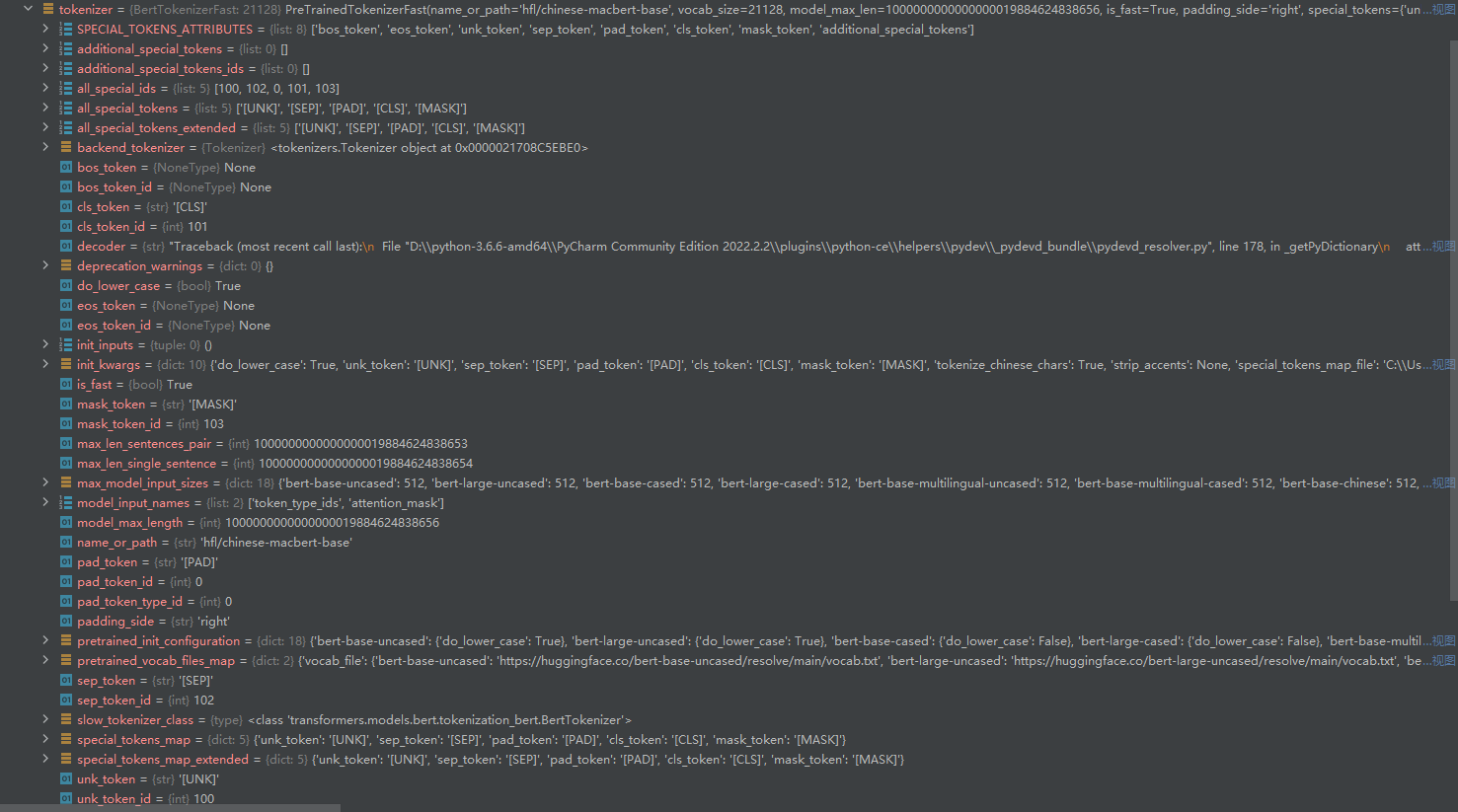
tokenizer【分词器】类的结构和数据
主要内容是用于分词的字符,包含一个字典,字典中包含一些特殊字符;
['[UNK]', '[SEP]', '[PAD]', '[CLS]', '[MASK]']常用的特殊字符一般是这5个,分表表示[未知字符],[分隔符],[填充符],[分类符],[掩码符];
Bert模型系列 vocab_file和tokenizer_file及其下载地址
vocab_file bert-base-uncased:https://huggingface.co/bert-base-uncased/resolve/main/vocab.txt bert-large-uncased:https://huggingface.co/bert-large-uncased/resolve/main/vocab.txt bert-base-cased:https://huggingface.co/bert-base-cased/resolve/main/vocab.txt bert-large-cased:https://huggingface.co/bert-large-cased/resolve/main/vocab.txt bert-base-multilingual-uncased:https://huggingface.co/bert-base-multilingual-uncased/resolve/main/vocab.txt bert-base-multilingual-cased:https://huggingface.co/bert-base-multilingual-cased/resolve/main/vocab.txt bert-base-chinese:https://huggingface.co/bert-base-chinese/resolve/main/vocab.txt bert-base-german-cased:https://int-deepset-models-bert.s3.eu-central-1.amazonaws.com/pytorch/bert-base-german-cased-vocab.txt bert-large-uncased-whole-word-masking:https://huggingface.co/bert-large-uncased-whole-word-masking/resolve/main/vocab.txt bert-large-cased-whole-word-masking:https://huggingface.co/bert-large-cased-whole-word-masking/resolve/main/vocab.txt bert-large-uncased-whole-word-masking-finetuned-squad:https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad/resolve/main/vocab.txt bert-large-cased-whole-word-masking-finetuned-squad:https://huggingface.co/bert-large-cased-whole-word-masking-finetuned-squad/resolve/main/vocab.txt bert-base-cased-finetuned-mrpc:https://huggingface.co/bert-base-cased-finetuned-mrpc/resolve/main/vocab.txt bert-base-german-dbmdz-cased:https://huggingface.co/bert-base-german-dbmdz-cased/resolve/main/vocab.txt bert-base-german-dbmdz-uncased:https://huggingface.co/bert-base-german-dbmdz-uncased/resolve/main/vocab.txt TurkuNLP/bert-base-finnish-cased-v1:https://huggingface.co/TurkuNLP/bert-base-finnish-cased-v1/resolve/main/vocab.txt TurkuNLP/bert-base-finnish-uncased-v1:https://huggingface.co/TurkuNLP/bert-base-finnish-uncased-v1/resolve/main/vocab.txt wietsedv/bert-base-dutch-cased:https://huggingface.co/wietsedv/bert-base-dutch-cased/resolve/main/vocab.txt tokenizer_file bert-base-uncased:https://huggingface.co/bert-base-uncased/resolve/main/tokenizer.json bert-large-uncased:https://huggingface.co/bert-large-uncased/resolve/main/tokenizer.json bert-base-cased:https://huggingface.co/bert-base-cased/resolve/main/tokenizer.json bert-large-cased:https://huggingface.co/bert-large-cased/resolve/main/tokenizer.json bert-base-multilingual-uncased:https://huggingface.co/bert-base-multilingual-uncased/resolve/main/tokenizer.json bert-base-multilingual-cased:https://huggingface.co/bert-base-multilingual-cased/resolve/main/tokenizer.json bert-base-chinese:https://huggingface.co/bert-base-chinese/resolve/main/tokenizer.json bert-base-german-cased:https://int-deepset-models-bert.s3.eu-central-1.amazonaws.com/pytorch/bert-base-german-cased-tokenizer.json bert-large-uncased-whole-word-masking:https://huggingface.co/bert-large-uncased-whole-word-masking/resolve/main/tokenizer.json bert-large-cased-whole-word-masking:https://huggingface.co/bert-large-cased-whole-word-masking/resolve/main/tokenizer.json bert-large-uncased-whole-word-masking-finetuned-squad:https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad/resolve/main/tokenizer.json bert-large-cased-whole-word-masking-finetuned-squad:https://huggingface.co/bert-large-cased-whole-word-masking-finetuned-squad/resolve/main/tokenizer.json bert-base-cased-finetuned-mrpc:https://huggingface.co/bert-base-cased-finetuned-mrpc/resolve/main/tokenizer.json bert-base-german-dbmdz-cased:https://huggingface.co/bert-base-german-dbmdz-cased/resolve/main/tokenizer.json bert-base-german-dbmdz-uncased:https://huggingface.co/bert-base-german-dbmdz-uncased/resolve/main/tokenizer.json TurkuNLP/bert-base-finnish-cased-v1:https://huggingface.co/TurkuNLP/bert-base-finnish-cased-v1/resolve/main/tokenizer.json TurkuNLP/bert-base-finnish-uncased-v1:https://huggingface.co/TurkuNLP/bert-base-finnish-uncased-v1/resolve/main/tokenizer.json wietsedv/bert-base-dutch-cased:https://huggingface.co/wietsedv/bert-base-dutch-cased/resolve/main/tokenizer.json
#end


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律