
pytorch学习笔记1
pytorch学习笔记1
模型与参数的关系:
- 深度学习中的模型可以抽象成一堆参数按照固定的运算规则所组成等的公式。
- 模型中的每个参数都是具体的数字,运算规则就是模型的网络结构。
- 在训练过程中,模型通过反复将公式的计算结果与目标值比较,并利用二者的差距对每个参数进行调整。
- 经过多次调整后的参数,可以使公式最终的输出结果高度的接近目标值,得到可用的模型。
pytorch中的乘法
|
* |
*在pytorch中是按位置相乘,存在广播机制。 但是需要注意的一点是虽然众多地方提到向量默认是列向量,但是在pytorch中一维的张量没有这种说法。 就算你用3×4的张量乘4×1的张量,得出的结果本应该是3×1的张量,但是因为是一维张量,也会变成默认的3(也不是1×3)。 可以执行的状态下print(mtx*vec)和print(vec*mtx)的结果是完全一样的。 但是上面的例子中如果执行print(mtx*vec)或者print(vec*mtx)会报错。因为默认情况下,一维的张量和矩阵执行*操作的时候,一维张量中元素的个数必须和二维矩阵列数相同,否则广播功能失效。 当然也可以使用reshap()为其增加一个维度。但是增加维度之后要遵守一些维度规则。 |
|
@ |
黑科技@,也是严格按照第一个参数的列数要等于第二个参数的行数。 对一维张量执行@操作就是dot 对一维和二维张量执行操作就是mv 对二维张量执行@操作就是mm |
|
mul |
数乘torch.mul torch.mul(input, value, out=None) 复制代码 用标量值value乘以输入input的每个元素,并返回一个新的结果张量。 就是张量的数乘运算。 |
|
mv |
矩阵向量相乘torch.mv torch.mv(mat, vec, out=None) → Tensor 复制代码 对矩阵mat和向量vec进行相乘。 如果mat 是一个n×m张量,vec 是一个m元 1维张量,将会输出一个n 元 1维张量。 必须前边是矩阵后边是向量,维度要符合矩阵乘法。出来的是一维张量。 |
|
mm |
矩阵乘法torch.mm torch.mm(mat1, mat2, out=None) → Tensor 复制代码 对矩阵mat1和mat2进行相乘。 如果mat1 是一个n×m张量,mat2 是一个 m×p张量,将会输出一个 n×p张量out。 就是我们线代中学的矩阵乘法,维度必须对应正确。 |
|
dot |
点乘积torch.dot torch.dot(tensor1, tensor2) → float 复制代码 计算两个张量的点乘积(内积),两个张量都为一维向量。 |
类结构
|
_tensor.py |
class Tensor(torch._C._TensorBase): 方法: def backward(self, gradient=None, retain_graph=None, create_graph=False, inputs=None): def register_hook(self, hook): def reinforce(self, reward): def is_shared(self): def share_memory_(self): def norm(self, p="fro", dim=None, keepdim=False, dtype=None): def lu(self, pivot=True, get_infos=False): def stft(self, n_fft: int, hop_length: Optional[int] = None, def istft(self, n_fft: int, hop_length: Optional[int] = None, def resize(self, *sizes): def resize_as(self, tensor): def split(self, split_size, dim=0): def unique(self, sorted=True, return_inverse=False, return_counts=False, dim=None): def unique_consecutive(self, return_inverse=False, return_counts=False, dim=None): def refine_names(self, *names): def align_to(self, *names): def unflatten(self, dim, sizes): def rename_(self, *names, **rename_map): def to_sparse_csr(self): def grad(self): 字段: self.data detach = _C._add_docstr(_C._TensorBase.detach, r""" self.requires_grad, _, self._backward_hooks = state
|
|
_TensorBase.py |
class _TensorBase(object): _TensorBase(object) abs(self) absolute(self) absolute_(self) abs_(self) acos(self) acosh(self) acosh_(self) acos_(self) add(self, other, *args, **kwargs) addbmm(self, batch1, batch2, *args, **kwargs) addbmm_(self, batch1, batch2, *args, **kwargs) addcdiv(self, tensor1, tensor2, *args, **kwargs) addcdiv_(self, tensor1, tensor2, *args, **kwargs) addcmul(self, tensor1, tensor2, *args, **kwargs) addcmul_(self, tensor1, tensor2, *args, **kwargs) addmm(self, mat1, mat2, *args, **kwargs) addmm_(self, mat1, mat2, *args, **kwargs) addmv(self, mat, vec, *args, **kwargs) addmv_(self, mat, vec, *args, **kwargs) addr(self, vec1, vec2, *args, **kwargs) addr_(self, vec1, vec2, *args, **kwargs) add_(self, other, *args, **kwargs) align_as(self, other) align_to(self, *args, **kwargs) all(self, dim=None, keepdim=False) allclose(self, other, rtol=1, *args, **kwargs) amax(self, dim=None, keepdim=False) amin(self, dim=None, keepdim=False) aminmax(self, *args, **kwargs) angle(self) any(self, dim=None, keepdim=False) apply_(self, callable) arccos(self) arccosh(self, *args, **kwargs) arccosh_(self, *args, **kwargs) arccos_(self) arcsin(self) arcsinh(self) arcsinh_(self) arcsin_(self) arctan(self) arctanh(self) arctanh_(self, other) arctan_(self) argmax(self, dim=None, keepdim=False) argmin(self, dim=None, keepdim=False) argsort(self, dim=-1, descending=False) asin(self) asinh(self) asinh_(self) asin_(self) as_strided(self, size, stride, storage_offset=0) as_strided_(self, *args, **kwargs) as_subclass(self, cls) atan(self) atan2(self, other) atan2_(self, other) atanh(self) atanh_(self, other) atan_(self) baddbmm(self, batch1, batch2, *args, **kwargs) baddbmm_(self, batch1, batch2, *args, **kwargs) bernoulli(self, *args, **kwargs) bernoulli_(self, p=0.5, *args, **kwargs) bfloat16(self, memory_format=None) bincount(self, weights=None, minlength=0) bitwise_and(self) bitwise_and_(self) bitwise_left_shift(self, other) bitwise_left_shift_(self, other) bitwise_not(self) bitwise_not_(self) bitwise_or(self) bitwise_or_(self) bitwise_right_shift(self, other) bitwise_right_shift_(self, other) bitwise_xor(self) bitwise_xor_(self) bmm(self, batch2) bool(self, memory_format=None) broadcast_to(self, shape) byte(self, memory_format=None) cauchy_(self, median=0, sigma=1, *args, **kwargs) cdouble(self, memory_format=None) ceil(self) ceil_(self) cfloat(self, memory_format=None) char(self, memory_format=None) cholesky(self, upper=False) cholesky_inverse(self, upper=False) cholesky_solve(self, input2, upper=False) chunk(self, chunks, dim=0) clamp(self, min=None, max=None) clamp_(self, min=None, max=None) clamp_max(self, *args, **kwargs) clamp_max_(self, *args, **kwargs) clamp_min(self, *args, **kwargs) clamp_min_(self, *args, **kwargs) clip(self, min=None, max=None) clip_(self, min=None, max=None) clone(self, *args, **kwargs) coalesce(self) col_indices(self) conj(self) conj_physical(self) conj_physical_(self) contiguous(self, memory_format=None) copysign(self, other) copysign_(self, other) copy_(self, src, non_blocking=False) corrcoef(self) cos(self) cosh(self) cosh_(self) cos_(self) count_nonzero(self, dim=None) cov(self, *args, **kwargs) cpu(self, memory_format=None) cross(self, other, dim=-1) crow_indices(self) cuda(self, device=None, non_blocking=False, memory_format=None) cummax(self, dim) cummin(self, dim) cumprod(self, dim, dtype=None) cumprod_(self, dim, dtype=None) cumsum(self, dim, dtype=None) cumsum_(self, dim, dtype=None) data_ptr(self) deg2rad(self) deg2rad_(self) dense_dim(self) dequantize(self) det(self) detach(self, *args, **kwargs) detach_(self, *args, **kwargs) diag(self, diagonal=0) diagflat(self, offset=0) diagonal(self, offset=0, dim1=0, dim2=1) diag_embed(self, offset=0, dim1=-2, dim2=-1) diff(self, n=1, dim=-1, prepend=None, append=None) digamma(self) digamma_(self) dim(self) dist(self, other, p=2) div(self, value, *args, **kwargs) divide(self, value, *args, **kwargs) divide_(self, value, *args, **kwargs) div_(self, value, *args, **kwargs) dot(self, other) double(self, memory_format=None) dsplit(self, split_size_or_sections) eig(self, eigenvectors=False) element_size(self) eq(self, other) equal(self, other) eq_(self, other) erf(self) erfc(self) erfc_(self) erfinv(self) erfinv_(self) erf_(self) exp(self) exp2(self) exp2_(self) expand(self, *sizes) expand_as(self, other) expm1(self) expm1_(self) exponential_(self, lambd=1, *args, **kwargs) exp_(self) fill_(self, value) fill_diagonal_(self, fill_value, wrap=False) fix(self) fix_(self) flatten(self, start_dim=0, end_dim=-1) flip(self, dims) fliplr(self) flipud(self) float(self, memory_format=None) float_power(self, exponent) float_power_(self, exponent) floor(self) floor_(self) floor_divide(self, value) floor_divide_(self, value) fmax(self, other) fmin(self, other) fmod(self, divisor) fmod_(self, divisor) frac(self) frac_(self) frexp(self, input) gather(self, dim, index) gcd(self, other) gcd_(self, other) ge(self, other) geometric_(self, p, *args, **kwargs) geqrf(self) ger(self, vec2) get_device(self) ge_(self, other) greater(self, other) greater_(self, other) greater_equal(self, other) greater_equal_(self, other) gt(self, other) gt_(self, other) half(self, memory_format=None) hardshrink(self, lambd=0.5) has_names(self, *args, **kwargs) heaviside(self, values) heaviside_(self, values) histc(self, bins=100, min=0, max=0) histogram(self, input, bins, *args, **kwargs) hsplit(self, split_size_or_sections) hypot(self, other) hypot_(self, other) i0(self) i0_(self) igamma(self, other) igammac(self, other) igammac_(self, other) igamma_(self, other) index_add(self, dim, index, tensor2) index_add_(self, dim, index, tensor, *args, **kwargs) index_copy(self, dim, index, tensor2) index_copy_(self, dim, index, tensor) index_fill(self, dim, index, value) index_fill_(self, dim, index, value) index_put(self, indices, values, accumulate=False) index_put_(self, indices, values, accumulate=False) index_select(self, dim, index) indices(self) inner(self, other) int(self, memory_format=None) int_repr(self) inverse(self) isclose(self, other, rtol=1, *args, **kwargs) isfinite(self) isinf(self) isnan(self) isneginf(self) isposinf(self) isreal(self) istft(self, n_fft, hop_length=None, win_length=None, window=None, center=True, normalized=False, onesided=True, length=None) is_coalesced(self) is_complex(self) is_conj(self) is_contiguous(self, memory_format=None) is_distributed(self, *args, **kwargs) is_floating_point(self) is_inference(self) is_neg(self) is_nonzero(self, *args, **kwargs) is_pinned(self, *args, **kwargs) is_same_size(self, *args, **kwargs) is_set_to(self, tensor) is_signed(self) item(self) kron(self, other) kthvalue(self, k, dim=None, keepdim=False) lcm(self, other) lcm_(self, other) ldexp(self, other) ldexp_(self, other) le(self, other) lerp(self, end, weight) lerp_(self, end, weight) less(self, *args, **kwargs) less_(self, other) less_equal(self, other) less_equal_(self, other) le_(self, other) lgamma(self) lgamma_(self) log(self) log10(self) log10_(self) log1p(self) log1p_(self) log2(self) log2_(self) logaddexp(self, other) logaddexp2(self, other) logcumsumexp(self, dim) logdet(self) logical_and(self) logical_and_(self) logical_not(self) logical_not_(self) logical_or(self) logical_or_(self) logical_xor(self) logical_xor_(self) logit(self) logit_(self) logsumexp(self, dim, keepdim=False) log_(self) log_normal_(self, mean=1, std=2, *args, **kwargs) log_softmax(self, *args, **kwargs) long(self, memory_format=None) lstsq(self, A) lt(self, other) lt_(self, other) lu_solve(self, LU_data, LU_pivots) map2_(self, *args, **kwargs) map_(self, tensor, callable) masked_fill(self, mask, value) masked_fill_(self, mask, value) masked_scatter(self, mask, tensor) masked_scatter_(self, mask, source) masked_select(self, mask) matmul(self, tensor2) matrix_exp(self) matrix_power(self, n) max(self, dim=None, keepdim=False) maximum(self, other) mean(self, dim=None, keepdim=False, *args, **kwargs) median(self, dim=None, keepdim=False) min(self, dim=None, keepdim=False) minimum(self, other) mm(self, mat2) mode(self, dim=None, keepdim=False) moveaxis(self, source, destination) movedim(self, source, destination) msort(self) mul(self, value) multinomial(self, num_samples, replacement=False, *args, **kwargs) multiply(self, value) multiply_(self, value) mul_(self, value) mv(self, vec) mvlgamma(self, p) mvlgamma_(self, p) nanmean(self, dim=None, keepdim=False, *args, **kwargs) nanmedian(self, dim=None, keepdim=False) nanquantile(self, q, dim=None, keepdim=False) nansum(self, dim=None, keepdim=False, dtype=None) nan_to_num(self, nan=0.0, posinf=None, neginf=None) nan_to_num_(self, nan=0.0, posinf=None, neginf=None) narrow(self, dimension, start, length) narrow_copy(self, dimension, start, length) ndimension(self) ne(self, other) neg(self) negative(self) negative_(self) neg_(self) nelement(self) new(self, *args, **kwargs) new_empty(self, size, dtype=None, device=None, requires_grad=False) new_empty_strided(self, size, stride, dtype=None, device=None, requires_grad=False) new_full(self, size, fill_value, dtype=None, device=None, requires_grad=False) new_ones(self, size, dtype=None, device=None, requires_grad=False) new_tensor(self, data, dtype=None, device=None, requires_grad=False) new_zeros(self, size, dtype=None, device=None, requires_grad=False) nextafter(self, other) nextafter_(self, other) ne_(self, other) nonzero(self) norm(self, p=2, dim=None, keepdim=False) normal_(self, mean=0, std=1, *args, **kwargs) not_equal(self, other) not_equal_(self, other) numel(self) numpy(self) orgqr(self, input2) ormqr(self, input2, input3, left=True, transpose=False) outer(self, vec2) permute(self, *dims) pinverse(self) pin_memory(self) polygamma(self, n) polygamma_(self, n) positive(self) pow(self, exponent) pow_(self, exponent) prelu(self, *args, **kwargs) prod(self, dim=None, keepdim=False, dtype=None) put(self, input, index, source, accumulate=False) put_(self, index, source, accumulate=False) qr(self, some=True) qscheme(self) quantile(self, q, dim=None, keepdim=False) q_per_channel_axis(self) q_per_channel_scales(self) q_per_channel_zero_points(self) q_scale(self) q_zero_point(self) rad2deg(self) rad2deg_(self) random_(self, to=None, *args, **kwargs) ravel(self, input) reciprocal(self) reciprocal_(self) record_stream(self, stream) refine_names(self, *args, **kwargs) relu(self, *args, **kwargs) relu_(self, *args, **kwargs) remainder(self, divisor) remainder_(self, divisor) rename(self, *args, **kwargs) rename_(self, *args, **kwargs) renorm(self, p, dim, maxnorm) renorm_(self, p, dim, maxnorm) repeat(self, *sizes) repeat_interleave(self, repeats, dim=None, *args, **kwargs) requires_grad_(self, requires_grad=True) reshape(self, *shape) reshape_as(self, other) resize_(self, *sizes, memory_format=None) resize_as_(self, tensor, memory_format=None) resolve_conj(self) resolve_neg(self) retain_grad(self) roll(self, shifts, dims) rot90(self, k, dims) round(self) round_(self) rsqrt(self) rsqrt_(self) scatter(self, dim, index, src) scatter_(self, dim, index, src, reduce=None) scatter_add(self, dim, index, src) scatter_add_(self, dim, index, src) select(self, dim, index) set_(self, source=None, storage_offset=0, size=None, stride=None) sgn(self) sgn_(self) short(self, memory_format=None) sigmoid(self) sigmoid_(self) sign(self) signbit(self) sign_(self) sin(self) sinc(self) sinc_(self) sinh(self) sinh_(self) sin_(self) size(self, dim=None) slogdet(self) smm(self, mat) softmax(self, *args, **kwargs) solve(self, A) sort(self, dim=-1, descending=False) sparse_dim(self) sparse_mask(self, mask) sparse_resize_(self, size, sparse_dim, dense_dim) sparse_resize_and_clear_(self, size, sparse_dim, dense_dim) split(self, *args, **kwargs) split_with_sizes(self, *args, **kwargs) sqrt(self) sqrt_(self) square(self) square_(self) squeeze(self, dim=None) squeeze_(self, dim=None) sspaddmm(self, mat1, mat2, *args, **kwargs) std(self, dim, unbiased=True, keepdim=False) stft(self, frame_length, hop, fft_size=None, return_onesided=True, window=None, pad_end=0) storage(self) storage_offset(self) storage_type(self) stride(self, dim) sub(self, other, *args, **kwargs) subtract(self, other, *args, **kwargs) subtract_(self, other, *args, **kwargs) sub_(self, other, *args, **kwargs) sum(self, dim=None, keepdim=False, dtype=None) sum_to_size(self, *size) svd(self, some=True, compute_uv=True) swapaxes(self, axis0, axis1) swapaxes_(self, axis0, axis1) swapdims(self, dim0, dim1) swapdims_(self, dim0, dim1) symeig(self, eigenvectors=False, upper=True) t(self) take(self, indices) take_along_dim(self, indices, dim) tan(self) tanh(self) tanh_(self) tan_(self) tensor_split(self, indices_or_sections, dim=0) tile(self, *reps) to(self, *args, **kwargs) tolist(self) topk(self, k, dim=None, largest=True, sorted=True) to_dense(self) to_mkldnn(self) to_sparse(self, sparseDims) trace(self) transpose(self, dim0, dim1) transpose_(self, dim0, dim1) triangular_solve(self, A, upper=True, transpose=False, unitriangular=False) tril(self, k=0) tril_(self, k=0) triu(self, k=0) triu_(self, k=0) true_divide(self, value) true_divide_(self, value) trunc(self) trunc_(self) type(self, dtype=None, non_blocking=False, **kwargs) type_as(self, tensor) t_(self) unbind(self, dim=0) unflatten(self, *args, **kwargs) unfold(self, dimension, size, step) uniform_(self, to=1) unsafe_chunk(self, chunks, dim=0) unsafe_split(self, split_size, dim=0) unsafe_split_with_sizes(self, *args, **kwargs) unsqueeze(self, dim) unsqueeze_(self, dim) values(self) var(self, dim, unbiased=True, keepdim=False) vdot(self, other) view(self, *shape) view_as(self, other) vsplit(self, split_size_or_sections) where(self, condition, y) xlogy(self, other) xlogy_(self, other) xpu(self, device=None, non_blocking=False, memory_format=None) zero_(self) _coalesced_(self, *args, **kwargs) _conj(self, *args, **kwargs) _conj_physical(self, *args, **kwargs) _dimI(self, *args, **kwargs) _dimV(self, *args, **kwargs) _fix_weakref(self, *args, **kwargs) _indices(self, *args, **kwargs) _is_view(self, *args, **kwargs) _make_subclass(self, *args, **kwargs) _neg_view(self, *args, **kwargs) _nnz(self, *args, **kwargs) _values(self, *args, **kwargs) __add__(self, *args, **kwargs) __and__(self, *args, **kwargs) __bool__(self, *args, **kwargs) __complex__(self, *args, **kwargs) __delitem__(self, *args, **kwargs) __div__(self, *args, **kwargs) __eq__(self, *args, **kwargs) __float__(self, *args, **kwargs) __floordiv__(self, *args, **kwargs) __getitem__(self, *args, **kwargs) __ge__(self, *args, **kwargs) __gt__(self, *args, **kwargs) __iadd__(self, *args, **kwargs) __iand__(self, *args, **kwargs) __idiv__(self, *args, **kwargs) __ifloordiv__(self, *args, **kwargs) __ilshift__(self, *args, **kwargs) __imod__(self, *args, **kwargs) __imul__(self, *args, **kwargs) __index__(self, *args, **kwargs) __init__(self, *args, **kwargs) __int__(self, *args, **kwargs) __invert__(self, *args, **kwargs) __ior__(self, *args, **kwargs) __irshift__(self, *args, **kwargs) __isub__(self, *args, **kwargs) __ixor__(self, *args, **kwargs) __len__(self, *args, **kwargs) __le__(self, *args, **kwargs) __long__(self, *args, **kwargs) __lshift__(self, *args, **kwargs) __lt__(self, *args, **kwargs) __matmul__(self, *args, **kwargs) __mod__(self, *args, **kwargs) __mul__(self, *args, **kwargs) __new__(*args, **kwargs) __ne__(self, *args, **kwargs) __nonzero__(self, *args, **kwargs) __or__(self, *args, **kwargs) __radd__(self, *args, **kwargs) __rand__(self, *args, **kwargs) __rmul__(self, *args, **kwargs) __ror__(self, *args, **kwargs) __rshift__(self, *args, **kwargs) __rxor__(self, *args, **kwargs) __setitem__(self, *args, **kwargs) __sub__(self, *args, **kwargs) __truediv__(self, *args, **kwargs) __xor__(self, *args, **kwargs) T __hash__ _backward_hooks _base _cdata _grad _grad_fn _python_dispatch _version data device dtype grad grad_fn imag is_cuda is_leaf is_meta is_mkldnn is_mlc is_ort is_quantized is_sparse is_sparse_csr is_vulkan is_xpu layout name names ndim output_nr real requires_grad retains_grad shape volatile
|
|
_VariableFunctions.pyi |
__all__ = ['__and__', '__lshift__', '__or__', '__rshift__', '__xor__', '_adaptive_avg_pool2d', '_adaptive_avg_pool3d', '_add_batch_dim', '_add_relu', '_add_relu_', '_aminmax', '_amp_foreach_non_finite_check_and_unscale_', '_amp_update_scale_', '_assert_async', '_baddbmm_mkl_', '_batch_norm_impl_index', '_cast_Byte', '_cast_Char', '_cast_Double', '_cast_Float', '_cast_Half', '_cast_Int', '_cast_Long', '_cast_Short', '_cat', '_choose_qparams_per_tensor', '_coalesce', '_compute_linear_combination', '_conj', '_conj_physical', '_convert_indices_from_coo_to_csr', '_convolution', '_convolution_mode', '_convolution_nogroup', '_copy_from', '_copy_from_and_resize', '_ctc_loss', '_cudnn_ctc_loss', '_cudnn_init_dropout_state', '_cudnn_rnn', '_cudnn_rnn_flatten_weight', '_cufft_clear_plan_cache', '_cufft_get_plan_cache_max_size', '_cufft_get_plan_cache_size', '_cufft_set_plan_cache_max_size', '_cummax_helper', '_cummin_helper', '_debug_has_internal_overlap', '_det_lu_based_helper', '_det_lu_based_helper_backward_helper', '_dim_arange', '_dirichlet_grad', '_embedding_bag', '_embedding_bag_forward_only', '_empty_affine_quantized', '_empty_per_channel_affine_quantized', '_euclidean_dist', '_fake_quantize_learnable_per_channel_affine', '_fake_quantize_learnable_per_tensor_affine', '_fake_quantize_per_tensor_affine_cachemask_tensor_qparams', '_fft_c2c', '_fft_c2r', '_fft_r2c', '_foreach_abs', '_foreach_abs_', '_foreach_acos', '_foreach_acos_', '_foreach_add', '_foreach_add_', '_foreach_addcdiv', '_foreach_addcdiv_', '_foreach_addcmul', '_foreach_addcmul_', '_foreach_asin', '_foreach_asin_', '_foreach_atan', '_foreach_atan_', '_foreach_ceil', '_foreach_ceil_', '_foreach_cos', '_foreach_cos_', '_foreach_cosh', '_foreach_cosh_', '_foreach_div', '_foreach_div_', '_foreach_erf', '_foreach_erf_', '_foreach_erfc', '_foreach_erfc_', '_foreach_exp', '_foreach_exp_', '_foreach_expm1', '_foreach_expm1_', '_foreach_floor', '_foreach_floor_', '_foreach_frac', '_foreach_frac_', '_foreach_lgamma', '_foreach_lgamma_', '_foreach_log', '_foreach_log10', '_foreach_log10_', '_foreach_log1p', '_foreach_log1p_', '_foreach_log2', '_foreach_log2_', '_foreach_log_', '_foreach_maximum', '_foreach_minimum', '_foreach_mul', '_foreach_mul_', '_foreach_neg', '_foreach_neg_', '_foreach_reciprocal', '_foreach_reciprocal_', '_foreach_round', '_foreach_round_', '_foreach_sigmoid', '_foreach_sigmoid_', '_foreach_sin', '_foreach_sin_', '_foreach_sinh', '_foreach_sinh_', '_foreach_sqrt', '_foreach_sqrt_', '_foreach_sub', '_foreach_sub_', '_foreach_tan', '_foreach_tan_', '_foreach_tanh', '_foreach_tanh_', '_foreach_trunc', '_foreach_trunc_', '_foreach_zero_', '_fused_dropout', '_fused_moving_avg_obs_fq_helper', '_grid_sampler_2d_cpu_fallback', '_has_compatible_shallow_copy_type', '_index_copy_', '_index_put_impl_', '_linalg_inv_out_helper_', '_linalg_qr_helper', '_log_softmax', '_log_softmax_backward_data', '_logcumsumexp', '_lu_with_info', '_make_dual', '_make_per_channel_quantized_tensor', '_make_per_tensor_quantized_tensor', '_masked_scale', '_mkldnn_reshape', '_mkldnn_transpose', '_mkldnn_transpose_', '_neg_view', '_nnpack_available', '_nnpack_spatial_convolution', '_pack_padded_sequence', '_pad_packed_sequence', '_pin_memory', '_remove_batch_dim', '_reshape_from_tensor', '_rowwise_prune', '_s_where', '_sample_dirichlet', '_saturate_weight_to_fp16', '_shape_as_tensor', '_sobol_engine_draw', '_sobol_engine_ff_', '_sobol_engine_initialize_state_', '_sobol_engine_scramble_', '_softmax', '_softmax_backward_data', '_sparse_addmm', '_sparse_coo_tensor_unsafe', '_sparse_csr_tensor_unsafe', '_sparse_log_softmax', '_sparse_log_softmax_backward_data', '_sparse_mask_helper', '_sparse_mm', '_sparse_softmax', '_sparse_softmax_backward_data', '_sparse_sparse_matmul', '_sparse_sum', '_stack', '_standard_gamma', '_standard_gamma_grad', '_test_serialization_subcmul', '_to_cpu', '_trilinear', '_unique', '_unique2', '_unpack_dual', '_use_cudnn_ctc_loss', '_use_cudnn_rnn_flatten_weight', '_validate_sparse_coo_tensor_args', '_validate_sparse_csr_tensor_args', '_weight_norm', '_weight_norm_cuda_interface', 'abs', 'abs_', 'absolute', 'acos', 'acos_', 'acosh', 'acosh_', 'adaptive_avg_pool1d', 'adaptive_max_pool1d', 'add', 'addbmm', 'addcdiv', 'addcmul', 'addmm', 'addmv', 'addmv_', 'addr', 'affine_grid_generator', 'all', 'allclose', 'alpha_dropout', 'alpha_dropout_', 'amax', 'amin', 'aminmax', 'angle', 'any', 'arange', 'arccos', 'arccos_', 'arccosh', 'arccosh_', 'arcsin', 'arcsin_', 'arcsinh', 'arcsinh_', 'arctan', 'arctan_', 'arctanh', 'arctanh_', 'argmax', 'argmin', 'argsort', 'as_strided', 'as_strided_', 'as_tensor', 'asin', 'asin_', 'asinh', 'asinh_', 'atan', 'atan2', 'atan_', 'atanh', 'atanh_', 'avg_pool1d', 'baddbmm', 'bartlett_window', 'batch_norm', 'batch_norm_backward_elemt', 'batch_norm_backward_reduce', 'batch_norm_elemt', 'batch_norm_gather_stats', 'batch_norm_gather_stats_with_counts', 'batch_norm_stats', 'batch_norm_update_stats', 'bernoulli', 'bilinear', 'binary_cross_entropy_with_logits', 'bincount', 'binomial', 'bitwise_and', 'bitwise_left_shift', 'bitwise_not', 'bitwise_or', 'bitwise_right_shift', 'bitwise_xor', 'blackman_window', 'bmm', 'broadcast_to', 'bucketize', 'can_cast', 'cat', 'ceil', 'ceil_', 'celu', 'celu_', 'channel_shuffle', 'cholesky', 'cholesky_inverse', 'cholesky_solve', 'choose_qparams_optimized', 'chunk', 'clamp', 'clamp_', 'clamp_max', 'clamp_max_', 'clamp_min', 'clamp_min_', 'clip', 'clip_', 'clone', 'column_stack', 'combinations', 'complex', 'concat', 'conj', 'conj_physical', 'conj_physical_', 'constant_pad_nd', 'conv1d', 'conv2d', 'conv3d', 'conv_tbc', 'conv_transpose1d', 'conv_transpose2d', 'conv_transpose3d', 'convolution', 'copysign', 'corrcoef', 'cos', 'cos_', 'cosh', 'cosh_', 'cosine_embedding_loss', 'cosine_similarity', 'count_nonzero', 'cov', 'cross', 'ctc_loss', 'cudnn_affine_grid_generator', 'cudnn_batch_norm', 'cudnn_convolution', 'cudnn_convolution_add_relu', 'cudnn_convolution_relu', 'cudnn_convolution_transpose', 'cudnn_grid_sampler', 'cudnn_is_acceptable', 'cummax', 'cummin', 'cumprod', 'cumsum', 'cumulative_trapezoid', 'deg2rad', 'deg2rad_', 'dequantize', 'det', 'detach', 'detach_', 'diag', 'diag_embed', 'diagflat', 'diagonal', 'diff', 'digamma', 'dist', 'div', 'divide', 'dot', 'dropout', 'dropout_', 'dsmm', 'dsplit', 'dstack', 'eig', 'embedding', 'embedding_bag', 'embedding_renorm_', 'empty', 'empty_like', 'empty_quantized', 'empty_strided', 'eq', 'equal', 'erf', 'erf_', 'erfc', 'erfc_', 'erfinv', 'exp', 'exp2', 'exp2_', 'exp_', 'expm1', 'expm1_', 'eye', 'fake_quantize_per_channel_affine', 'fake_quantize_per_tensor_affine', 'fbgemm_linear_fp16_weight', 'fbgemm_linear_fp16_weight_fp32_activation', 'fbgemm_linear_int8_weight', 'fbgemm_linear_int8_weight_fp32_activation', 'fbgemm_linear_quantize_weight', 'fbgemm_pack_gemm_matrix_fp16', 'fbgemm_pack_quantized_matrix', 'feature_alpha_dropout', 'feature_alpha_dropout_', 'feature_dropout', 'feature_dropout_', 'fill_', 'fix', 'fix_', 'flatten', 'flip', 'fliplr', 'flipud', 'float_power', 'floor', 'floor_', 'floor_divide', 'fmax', 'fmin', 'fmod', 'frac', 'frac_', 'frexp', 'frobenius_norm', 'from_file', 'from_numpy', 'frombuffer', 'full', 'full_like', 'fused_moving_avg_obs_fake_quant', 'gather', 'gcd', 'gcd_', 'ge', 'geqrf', 'ger', 'get_default_dtype', 'get_num_interop_threads', 'get_num_threads', 'gradient', 'greater', 'greater_equal', 'grid_sampler', 'grid_sampler_2d', 'grid_sampler_3d', 'group_norm', 'gru', 'gru_cell', 'gt', 'hamming_window', 'hann_window', 'hardshrink', 'heaviside', 'hinge_embedding_loss', 'histc', 'histogram', 'hsmm', 'hsplit', 'hspmm', 'hstack', 'hypot', 'i0', 'i0_', 'igamma', 'igammac', 'imag', 'index_add', 'index_copy', 'index_fill', 'index_put', 'index_put_', 'index_select', 'init_num_threads', 'inner', 'instance_norm', 'int_repr', 'inverse', 'is_complex', 'is_conj', 'is_distributed', 'is_floating_point', 'is_grad_enabled', 'is_inference', 'is_inference_mode_enabled', 'is_neg', 'is_nonzero', 'is_same_size', 'is_signed', 'is_vulkan_available', 'isclose', 'isfinite', 'isin', 'isinf', 'isnan', 'isneginf', 'isposinf', 'isreal', 'kaiser_window', 'kl_div', 'kron', 'kthvalue', 'layer_norm', 'lcm', 'lcm_', 'ldexp', 'ldexp_', 'le', 'lerp', 'less', 'less_equal', 'lgamma', 'linspace', 'log', 'log10', 'log10_', 'log1p', 'log1p_', 'log2', 'log2_', 'log_', 'log_softmax', 'logaddexp', 'logaddexp2', 'logcumsumexp', 'logdet', 'logical_and', 'logical_not', 'logical_or', 'logical_xor', 'logit', 'logit_', 'logspace', 'logsumexp', 'lstm', 'lstm_cell', 'lstsq', 'lt', 'lu_solve', 'lu_unpack', 'margin_ranking_loss', 'masked_fill', 'masked_scatter', 'masked_select', 'matmul', 'matrix_exp', 'matrix_power', 'matrix_rank', 'max', 'max_pool1d', 'max_pool1d_with_indices', 'max_pool2d', 'max_pool3d', 'maximum', 'mean', 'median', 'min', 'minimum', 'miopen_batch_norm', 'miopen_convolution', 'miopen_convolution_transpose', 'miopen_depthwise_convolution', 'miopen_rnn', 'mkldnn_adaptive_avg_pool2d', 'mkldnn_convolution', 'mkldnn_convolution_backward_weights', 'mkldnn_linear_backward_weights', 'mkldnn_max_pool2d', 'mkldnn_max_pool3d', 'mm', 'mode', 'moveaxis', 'movedim', 'msort', 'mul', 'multinomial', 'multiply', 'mv', 'mvlgamma', 'namedtuple_LU_pivots_info', 'namedtuple_P_L_U', 'namedtuple_Q_R', 'namedtuple_U_S_V', 'namedtuple_a_tau', 'namedtuple_det_lu_pivs', 'namedtuple_eigenvalues_eigenvectors', 'namedtuple_hist_bin_edges', 'namedtuple_mantissa_exponent', 'namedtuple_min_max', 'namedtuple_output_mask', 'namedtuple_primal_tangent', 'namedtuple_sign_logabsdet', 'namedtuple_solution_LU', 'namedtuple_solution_QR', 'namedtuple_solution_cloned_coefficient', 'namedtuple_values_indices', 'nan_to_num', 'nan_to_num_', 'nanmean', 'nanmedian', 'nanquantile', 'nansum', 'narrow', 'narrow_copy', 'native_batch_norm', 'native_group_norm', 'native_layer_norm', 'native_norm', 'ne', 'neg', 'neg_', 'negative', 'negative_', 'nextafter', 'nonzero', 'norm_except_dim', 'normal', 'not_equal', 'nuclear_norm', 'numel', 'ones', 'ones_like', 'orgqr', 'ormqr', 'outer', 'pairwise_distance', 'pdist', 'permute', 'pinverse', 'pixel_shuffle', 'pixel_unshuffle', 'poisson', 'poisson_nll_loss', 'polar', 'polygamma', 'positive', 'pow', 'prelu', 'prod', 'promote_types', 'put', 'q_per_channel_axis', 'q_per_channel_scales', 'q_per_channel_zero_points', 'q_scale', 'q_zero_point', 'qr', 'quantile', 'quantize_per_channel', 'quantize_per_tensor', 'quantized_batch_norm', 'quantized_gru_cell', 'quantized_lstm_cell', 'quantized_max_pool1d', 'quantized_max_pool2d', 'quantized_rnn_relu_cell', 'quantized_rnn_tanh_cell', 'rad2deg', 'rad2deg_', 'rand', 'rand_like', 'randint', 'randint_like', 'randn', 'randn_like', 'randperm', 'range', 'ravel', 'real', 'reciprocal', 'reciprocal_', 'relu', 'relu_', 'remainder', 'renorm', 'repeat_interleave', 'reshape', 'resize_as_', 'resize_as_sparse_', 'resolve_conj', 'resolve_neg', 'result_type', 'rnn_relu', 'rnn_relu_cell', 'rnn_tanh', 'rnn_tanh_cell', 'roll', 'rot90', 'round', 'round_', 'row_stack', 'rrelu', 'rrelu_', 'rsqrt', 'rsqrt_', 'rsub', 'saddmm', 'scalar_tensor', 'scatter', 'scatter_add', 'searchsorted', 'segment_reduce', 'select', 'selu', 'selu_', 'set_flush_denormal', 'set_num_interop_threads', 'set_num_threads', 'sgn', 'sigmoid', 'sigmoid_', 'sign', 'signbit', 'sin', 'sin_', 'sinc', 'sinc_', 'sinh', 'sinh_', 'slogdet', 'smm', 'softmax', 'solve', 'sort', 'sparse_coo_tensor', 'sparse_csr_tensor', 'split_with_sizes', 'spmm', 'sqrt', 'sqrt_', 'square', 'square_', 'squeeze', 'sspaddmm', 'stack', 'std', 'std_mean', 'sub', 'subtract', 'sum', 'svd', 'swapaxes', 'swapdims', 'symeig', 't', 'take', 'take_along_dim', 'tan', 'tan_', 'tanh', 'tanh_', 'tensor', 'tensor_split', 'threshold', 'threshold_', 'tile', 'topk', 'trace', 'transpose', 'trapezoid', 'trapz', 'triangular_solve', 'tril', 'tril_indices', 'triplet_margin_loss', 'triu', 'triu_indices', 'true_divide', 'trunc', 'trunc_', 'unbind', 'unique_dim', 'unsafe_chunk', 'unsafe_split', 'unsafe_split_with_sizes', 'unsqueeze', 'vander', 'var', 'var_mean', 'vdot', 'view_as_complex', 'view_as_real', 'vsplit', 'vstack', 'where', 'xlogy', 'xlogy_', 'zero_', 'zeros', 'zeros_like'] |
|
parameter.py |
class Parameter(torch.Tensor): data |
|
variable.py |
class Variable(with_metaclass(VariableMeta, torch._C._LegacyVariableBase)): # type: ignore[misc]
|
pytorch结构
|
torch 文件夹 |
文件夹: autograd、backends、contrib、cpu、cuda、futures、multiprocessing、 nn、onnx、optim、package、profiler、quantization、share、、、、 py文件: autocast_mode.py、functional.py、hub.py、overrides.py、quasirandom.py、 random.py、serialization.py、storage.py、torch_version.py、types.py、version.py、、 class类: DoubleStorage、FloatStorage、HalfStorage、LongStorage、IntStorage、ShortStorage、CharStorage、ByteStorage、BoolStorage、BFloat16Storage、ComplexDoubleStorage、ComplexFloatStorage、QUInt8Storage、QInt8Storage、QInt32Storage、QUInt4x2Storage、、 方法: def typename(o): def is_tensor(obj): def is_storage(obj): def set_default_tensor_type(t): def set_default_dtype(d): def use_deterministic_algorithms(mode): def are_deterministic_algorithms_enabled(): def set_warn_always(b): def is_warn_always_enabled(): def manager_path(): def compiled_with_cxx11_abi():
__all__ = [ 'typename', 'is_tensor', 'is_storage', 'set_default_tensor_type', 'set_rng_state', 'get_rng_state', 'manual_seed', 'initial_seed', 'seed', 'save', 'load', 'set_printoptions', 'chunk', 'split', 'stack', 'matmul', 'no_grad', 'enable_grad', 'rand', 'randn', 'inference_mode', 'DoubleStorage', 'FloatStorage', 'LongStorage', 'IntStorage', 'ShortStorage', 'CharStorage', 'ByteStorage', 'BoolStorage', 'DoubleTensor', 'FloatTensor', 'LongTensor', 'IntTensor', 'ShortTensor', 'CharTensor', 'ByteTensor', 'BoolTensor', 'Tensor', 'lobpcg', 'use_deterministic_algorithms', 'are_deterministic_algorithms_enabled', 'set_warn_always', 'is_warn_always_enabled', ] _storage_classes = { DoubleStorage, FloatStorage, LongStorage, IntStorage, ShortStorage, CharStorage, ByteStorage, HalfStorage, BoolStorage, QUInt8Storage, QInt8Storage, QInt32Storage, BFloat16Storage, ComplexFloatStorage, ComplexDoubleStorage, QUInt4x2Storage }
|
|
nn 文件夹 |
文件夹: backends、intrinsic、modules、parallel、quantizable、quantized、utils、、、、、、 py文件: common_types.py、cpp.py、functional.py、grad.py、init.py、parameter.py、、
|
|
modules 文件夹 |
py文件: activation.py、adaptive.py、batchnorm.py、channelshuffle.py、container.py、conv.py、distance.py、dropout.py、flatten.py、fold.py、instancenorm.py、lazy.py、linear.py、loss.py、module.py、normalization.py、padding.py、pixelshuffle.py、pooling.py、rnn.py、sparse.py、transformer.py、upsampling.py、utils.py
|
|
module.py |
def register_module_forward_pre_hook(hook: Callable[..., None]) -> RemovableHandle: def register_module_forward_hook(hook: Callable[..., None]) -> RemovableHandle: def register_module_backward_hook( hook: Callable[['Module', _grad_t, _grad_t], Union[None, Tensor]] ) -> RemovableHandle: def register_module_full_backward_hook( hook: Callable[['Module', _grad_t, _grad_t], Union[None, Tensor]] ) -> RemovableHandle: class Module: r"""Base class for all neural network modules. |
|
class Module |
函数: def register_buffer(self, name: str, tensor: Optional[Tensor], persistent: bool = True) -> None: def register_parameter(self, name: str, param: Optional[Parameter]) -> None: def add_module(self, name: str, module: Optional['Module']) -> None: def get_submodule(self, target: str) -> "Module": def get_parameter(self, target: str) -> "Parameter": def get_buffer(self, target: str) -> "Tensor": def get_extra_state(self) -> Any: def set_extra_state(self, state: Any): def apply(self: T, fn: Callable[['Module'], None]) -> T: def cuda(self: T, device: Optional[Union[int, device]] = None) -> T: def xpu(self: T, device: Optional[Union[int, device]] = None) -> T: def cpu(self: T) -> T: def type(self: T, dst_type: Union[dtype, str]) -> T: def float(self: T) -> T: def double(self: T) -> T: def half(self: T) -> T: def bfloat16(self: T) -> T: def to_empty(self: T, *, device: Union[str, device]) -> T: def to(self: T, device: Optional[Union[int, device]] = ..., dtype: Optional[Union[dtype, str]] = ..., def to(self: T, dtype: Union[dtype, str], non_blocking: bool = ...) -> T: def to(self: T, tensor: Tensor, non_blocking: bool = ...) -> T: def to(self, *args, **kwargs): def register_backward_hook( self, hook: Callable[['Module', _grad_t, _grad_t], Union[None, Tensor]] ) -> RemovableHandle: def register_full_backward_hook( self, hook: Callable[['Module', _grad_t, _grad_t], Union[None, Tensor]] ) -> RemovableHandle: def register_forward_pre_hook(self, hook: Callable[..., None]) -> RemovableHandle: def register_forward_hook(self, hook: Callable[..., None]) -> RemovableHandle: def state_dict(self, destination: T_destination, prefix: str = ..., keep_vars: bool = ...) -> T_destination: def state_dict(self, prefix: str = ..., keep_vars: bool = ...) -> 'OrderedDict[str, Tensor]': def state_dict(self, destination=None, prefix='', keep_vars=False): def load_state_dict(self, state_dict: 'OrderedDict[str, Tensor]', def parameters(self, recurse: bool = True) -> Iterator[Parameter]: def named_parameters(self, prefix: str = '', recurse: bool = True) -> Iterator[Tuple[str, Parameter]]: def buffers(self, recurse: bool = True) -> Iterator[Tensor]: def named_buffers(self, prefix: str = '', recurse: bool = True) -> Iterator[Tuple[str, Tensor]]: def children(self) -> Iterator['Module']: def named_children(self) -> Iterator[Tuple[str, 'Module']]: def modules(self) -> Iterator['Module']: def named_modules(self, memo: Optional[Set['Module']] = None, prefix: str = '', remove_duplicate: bool = True): def train(self: T, mode: bool = True) -> T: def eval(self: T) -> T: def requires_grad_(self: T, requires_grad: bool = True) -> T: def zero_grad(self, set_to_none: bool = False) -> None: def share_memory(self: T) -> T: def extra_repr(self) -> str:
|
|
functional.py 所有函数 |
Tensor、conv1d、conv2d、conv3d、conv_transpose1d、conv_transpose2d、conv_transpose3d、conv_tbc、
avg_pool1d、avg_pool2d、avg_pool3d、fractional_max_pool2d_with_indices、fractional_max_pool2d、fractional_max_pool3d_with_indices、fractional_max_pool3d、max_pool1d_with_indices、max_pool1d、max_pool2d_with_indices、max_pool2d、max_pool3d_with_indices、max_pool3d、max_unpool1d、max_unpool2d、max_unpool3d、lp_pool2d、lp_pool1d、adaptive_max_pool1d_with_indices、adaptive_max_pool1d、adaptive_max_pool2d_with_indices、adaptive_max_pool2d、adaptive_max_pool3d_with_indices、adaptive_max_pool3d、adaptive_avg_pool1d、adaptive_avg_pool2d、adaptive_avg_pool3d、
dropout、alpha_dropout、dropout2d、dropout3d、feature_alpha_dropout、threshold、relu、glu、hardtanh、relu6、elu、selu、celu、leaky_relu、prelu、rrelu、logsigmoid、gelu、hardshrink、tanhshrink、softsign、softplus、softmin、softmax、gumbel_softmax、log_softmax、softshrink、tanh、sigmoid、hardsigmoid、
linear、bilinear、silu、mish、hardswish、embedding、embedding_bag、batch_norm、instance_norm、layer_norm、group_norm、local_response_norm、
ctc_loss、nll_loss、poisson_nll_loss、gaussian_nll_loss、kl_div、cross_entropy、binary_cross_entropy、binary_cross_entropy_with_logits、smooth_l1_loss、huber_loss、l1_loss、mse_loss、margin_ranking_loss、hinge_embedding_loss、multilabel_margin_loss、soft_margin_loss、multilabel_soft_margin_loss、cosine_embedding_loss、multi_margin_loss、
pixel_shuffle、pixel_unshuffle、channel_shuffle、upsample、interpolate、upsample_nearest、upsample_bilinear、grid_sample、affine_grid、pad、pairwise_distance、pdist、cosine_similarity、one_hot、triplet_margin_loss、triplet_margin_with_distance_loss、normalize、assert_int_or_pair、unfold、fold、multi_head_attention_forward、、、、、、、、、、、、、、、 |
所有的函数
|
全连接函数linear |
Identity, Linear, Bilinear, LazyLinear |
|
卷积函数conv |
Conv1d, Conv2d, Conv3d, \ ConvTranspose1d, ConvTranspose2d, ConvTranspose3d, \ LazyConv1d, LazyConv2d, LazyConv3d, LazyConvTranspose1d, LazyConvTranspose2d, LazyConvTranspose3d |
|
激活函数activation |
Threshold, ReLU, Hardtanh, ReLU6, Sigmoid, Tanh, \ Softmax, Softmax2d, LogSoftmax, ELU, SELU, CELU, GELU, Hardshrink, LeakyReLU, LogSigmoid, \ Softplus, Softshrink, MultiheadAttention, PReLU, Softsign, Softmin, Tanhshrink, RReLU, GLU, \ Hardsigmoid, Hardswish, SiLU, Mish |
|
损失函数loss |
L1Loss, NLLLoss, KLDivLoss, MSELoss, BCELoss, BCEWithLogitsLoss, NLLLoss2d, \ CosineEmbeddingLoss, CTCLoss, HingeEmbeddingLoss, MarginRankingLoss, \ MultiLabelMarginLoss, MultiLabelSoftMarginLoss, MultiMarginLoss, SmoothL1Loss, HuberLoss, \ SoftMarginLoss, CrossEntropyLoss, TripletMarginLoss, TripletMarginWithDistanceLoss |
|
函数容器container |
Container, Sequential, ModuleList, ModuleDict, ParameterList, ParameterDict |
|
池化函数pooling |
AvgPool1d, AvgPool2d, AvgPool3d, MaxPool1d, MaxPool2d, MaxPool3d, \ MaxUnpool1d, MaxUnpool2d, MaxUnpool3d, FractionalMaxPool2d, FractionalMaxPool3d, LPPool1d, LPPool2d,AdaptiveMaxPool1d, AdaptiveMaxPool2d, AdaptiveMaxPool3d, AdaptiveAvgPool1d, AdaptiveAvgPool2d, AdaptiveAvgPool3d
|
|
批量标准化函数batchnorm |
BatchNorm1d, BatchNorm2d, BatchNorm3d, SyncBatchNorm, \ LazyBatchNorm1d, LazyBatchNorm2d, LazyBatchNorm3d
|
|
实例标准化函数instancenorm |
InstanceNorm1d, InstanceNorm2d, InstanceNorm3d, \ LazyInstanceNorm1d, LazyInstanceNorm2d, LazyInstanceNorm3d
|
|
normalization 标准化函数 |
LocalResponseNorm, CrossMapLRN2d, LayerNorm, GroupNorm
|
|
丢弃函数dropout |
import Dropout, Dropout2d, Dropout3d, AlphaDropout, FeatureAlphaDropout |
|
填补函数padding |
ReflectionPad1d, ReflectionPad2d, ReflectionPad3d, ReplicationPad1d, ReplicationPad2d, \ ReplicationPad3d, ZeroPad2d, ConstantPad1d, ConstantPad2d, ConstantPad3d
|
|
稀疏函数sparse |
Embedding, EmbeddingBag |
|
循环函数rnn |
RNNBase, RNN, LSTM, GRU, \ RNNCellBase, RNNCell, LSTMCell, GRUCell
|
|
打乱函数pixelshuffle |
PixelShuffle, PixelUnshuffle |
|
上采样函数upsampling |
UpsamplingNearest2d, UpsamplingBilinear2d, Upsample |
|
距离函数distance |
PairwiseDistance, CosineSimilarity |
|
fold |
Fold, Unfold
|
|
adaptive |
AdaptiveLogSoftmaxWithLoss |
|
transformer |
TransformerEncoder, TransformerDecoder, \ TransformerEncoderLayer, TransformerDecoderLayer, Transformer |
|
平坦flatten |
Flatten, Unflatten |
|
channelshuffle |
ChannelShuffle |
modules文件夹 __init__.py
|
from .module import Module from .linear import Identity, Linear, Bilinear, LazyLinear from .conv import Conv1d, Conv2d, Conv3d, \ ConvTranspose1d, ConvTranspose2d, ConvTranspose3d, \ LazyConv1d, LazyConv2d, LazyConv3d, LazyConvTranspose1d, LazyConvTranspose2d, LazyConvTranspose3d from .activation import Threshold, ReLU, Hardtanh, ReLU6, Sigmoid, Tanh, \ Softmax, Softmax2d, LogSoftmax, ELU, SELU, CELU, GELU, Hardshrink, LeakyReLU, LogSigmoid, \ Softplus, Softshrink, MultiheadAttention, PReLU, Softsign, Softmin, Tanhshrink, RReLU, GLU, \ Hardsigmoid, Hardswish, SiLU, Mish from .loss import L1Loss, NLLLoss, KLDivLoss, MSELoss, BCELoss, BCEWithLogitsLoss, NLLLoss2d, \ CosineEmbeddingLoss, CTCLoss, HingeEmbeddingLoss, MarginRankingLoss, \ MultiLabelMarginLoss, MultiLabelSoftMarginLoss, MultiMarginLoss, SmoothL1Loss, HuberLoss, \ SoftMarginLoss, CrossEntropyLoss, TripletMarginLoss, TripletMarginWithDistanceLoss, PoissonNLLLoss, GaussianNLLLoss from .container import Container, Sequential, ModuleList, ModuleDict, ParameterList, ParameterDict from .pooling import AvgPool1d, AvgPool2d, AvgPool3d, MaxPool1d, MaxPool2d, MaxPool3d, \ MaxUnpool1d, MaxUnpool2d, MaxUnpool3d, FractionalMaxPool2d, FractionalMaxPool3d, LPPool1d, LPPool2d, \ AdaptiveMaxPool1d, AdaptiveMaxPool2d, AdaptiveMaxPool3d, AdaptiveAvgPool1d, AdaptiveAvgPool2d, AdaptiveAvgPool3d from .batchnorm import BatchNorm1d, BatchNorm2d, BatchNorm3d, SyncBatchNorm, \ LazyBatchNorm1d, LazyBatchNorm2d, LazyBatchNorm3d from .instancenorm import InstanceNorm1d, InstanceNorm2d, InstanceNorm3d, \ LazyInstanceNorm1d, LazyInstanceNorm2d, LazyInstanceNorm3d from .normalization import LocalResponseNorm, CrossMapLRN2d, LayerNorm, GroupNorm from .dropout import Dropout, Dropout2d, Dropout3d, AlphaDropout, FeatureAlphaDropout from .padding import ReflectionPad1d, ReflectionPad2d, ReflectionPad3d, ReplicationPad1d, ReplicationPad2d, \ ReplicationPad3d, ZeroPad2d, ConstantPad1d, ConstantPad2d, ConstantPad3d from .sparse import Embedding, EmbeddingBag from .rnn import RNNBase, RNN, LSTM, GRU, \ RNNCellBase, RNNCell, LSTMCell, GRUCell from .pixelshuffle import PixelShuffle, PixelUnshuffle from .upsampling import UpsamplingNearest2d, UpsamplingBilinear2d, Upsample from .distance import PairwiseDistance, CosineSimilarity from .fold import Fold, Unfold from .adaptive import AdaptiveLogSoftmaxWithLoss from .transformer import TransformerEncoder, TransformerDecoder, \ TransformerEncoderLayer, TransformerDecoderLayer, Transformer from .flatten import Flatten, Unflatten from .channelshuffle import ChannelShuffle
|
|
__all__ = [ 'Module', 'Identity', 'Linear', 'Conv1d', 'Conv2d', 'Conv3d', 'ConvTranspose1d', 'ConvTranspose2d', 'ConvTranspose3d', 'Threshold', 'ReLU', 'Hardtanh', 'ReLU6', 'Sigmoid', 'Tanh', 'Softmax', 'Softmax2d', 'LogSoftmax', 'ELU', 'SELU', 'CELU', 'GLU', 'GELU', 'Hardshrink', 'LeakyReLU', 'LogSigmoid', 'Softplus', 'Softshrink', 'MultiheadAttention', 'PReLU', 'Softsign', 'Softmin', 'Tanhshrink', 'RReLU', 'L1Loss', 'NLLLoss', 'KLDivLoss', 'MSELoss', 'BCELoss', 'BCEWithLogitsLoss', 'NLLLoss2d', 'PoissonNLLLoss', 'CosineEmbeddingLoss', 'CTCLoss', 'HingeEmbeddingLoss', 'MarginRankingLoss', 'MultiLabelMarginLoss', 'MultiLabelSoftMarginLoss', 'MultiMarginLoss', 'SmoothL1Loss', 'GaussianNLLLoss', 'HuberLoss', 'SoftMarginLoss', 'CrossEntropyLoss', 'Container', 'Sequential', 'ModuleList', 'ModuleDict', 'ParameterList', 'ParameterDict', 'AvgPool1d', 'AvgPool2d', 'AvgPool3d', 'MaxPool1d', 'MaxPool2d', 'MaxPool3d', 'MaxUnpool1d', 'MaxUnpool2d', 'MaxUnpool3d', 'FractionalMaxPool2d', "FractionalMaxPool3d", 'LPPool1d', 'LPPool2d', 'LocalResponseNorm', 'BatchNorm1d', 'BatchNorm2d', 'BatchNorm3d', 'InstanceNorm1d', 'InstanceNorm2d', 'InstanceNorm3d', 'LayerNorm', 'GroupNorm', 'SyncBatchNorm', 'Dropout', 'Dropout2d', 'Dropout3d', 'AlphaDropout', 'FeatureAlphaDropout', 'ReflectionPad1d', 'ReflectionPad2d', 'ReflectionPad3d', 'ReplicationPad2d', 'ReplicationPad1d', 'ReplicationPad3d', 'CrossMapLRN2d', 'Embedding', 'EmbeddingBag', 'RNNBase', 'RNN', 'LSTM', 'GRU', 'RNNCellBase', 'RNNCell', 'LSTMCell', 'GRUCell', 'PixelShuffle', 'PixelUnshuffle', 'Upsample', 'UpsamplingNearest2d', 'UpsamplingBilinear2d', 'PairwiseDistance', 'AdaptiveMaxPool1d', 'AdaptiveMaxPool2d', 'AdaptiveMaxPool3d', 'AdaptiveAvgPool1d', 'AdaptiveAvgPool2d', 'AdaptiveAvgPool3d', 'TripletMarginLoss', 'ZeroPad2d', 'ConstantPad1d', 'ConstantPad2d', 'ConstantPad3d', 'Bilinear', 'CosineSimilarity', 'Unfold', 'Fold', 'AdaptiveLogSoftmaxWithLoss', 'TransformerEncoder', 'TransformerDecoder', 'TransformerEncoderLayer', 'TransformerDecoderLayer', 'Transformer', 'LazyLinear', 'LazyConv1d', 'LazyConv2d', 'LazyConv3d', 'LazyConvTranspose1d', 'LazyConvTranspose2d', 'LazyConvTranspose3d', 'LazyBatchNorm1d', 'LazyBatchNorm2d', 'LazyBatchNorm3d', 'LazyInstanceNorm1d', 'LazyInstanceNorm2d', 'LazyInstanceNorm3d', 'Flatten', 'Unflatten', 'Hardsigmoid', 'Hardswish', 'SiLU', 'Mish', 'TripletMarginWithDistanceLoss', 'ChannelShuffle' ] |
张量创建函数总结(表格)
|
填充张量 |
ones/ones_like |
全1张量 |
|
zeros/zeros_like |
全零张量 |
|
|
full/full_like |
全部元素为指定fill_value的张量 |
|
|
empty/empty_like |
没有初始化的tensor |
|
|
|
|
|
|
随机张量 |
rand/rand_like |
均匀分布 |
|
randint/randint_like |
均匀分布-整数 |
|
|
randn/randn_like |
正态分布 |
|
|
|
|
|
|
分布张量 |
range |
一维张量,线性分布 |
|
linspace |
线性分布的张量 |
|
|
logspace |
对数分布的张量 |
|
|
|
|
|
|
一般张量 |
tensor |
函数,张量 |
|
Tensor |
类,是torch.FloatTensor的别名 |
|
|
FloatTensor |
类,32位浮点类型数据 |
|
|
LongTensor |
类,是64位整型 |
|
|
|
|
|
|
|
parse_coo_tensor |
稀疏张量 |
|
|
eye |
对角矩阵 |
|
|
|
torch.Tensor(data)是将输入的data转化torch.FloatTensor
torch.tensor(data):(当你未指定dype的类型时)将data转化为torch.FloatTensor、torch.LongTensor、torch.DoubleTensor等类型,转化类型依据于data的类型或者dtype的值
当你想要创建一个空的tensor时候,可以使用如下的方法:
tensor_without_data = torch.Tensor() # tensor([])
tensor_without_data = torch.tensor(()) # tensor([])
tensor_without_data = torch.empty([]) # tensor(0.)
张量测试
|
# a=t.LongTensor(2,3) # a=t.full((2,3),fill_value=666)
# print(t.get_default_dtype())#torch.float32 # a=1 # print(t.is_tensor(a))#False # a=t.Tensor(2,3) # # tensor([[0., 0., 0.], # # [0., 0., 0.]]) # print(a) # print('is tensor:',t.is_tensor(a))#True # print('is storage:',t.is_storage(a))#is storage: False # print('is storage:',t.is_storage(a.storage()))#is storage: True # # a=t.LongTensor(2,3) # print(a) # # tensor([[ 0, 15, 0], # # [ 0, 0, 0]]) # print('is tensor:',t.is_tensor(a))#is tensor True # # print('number of elements=',t.numel(a))#number of elements= 6 # # import numpy as np # a=t.tensor(range(10)) # print(a)#tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) # a=t.tensor(np.ndarray([2,3])) # print(a) # # tensor([[ 0.0000e+00, 7.4110e-323, 0.0000e+00], # # [3.2033e+160, 2.4712e-312, 0.0000e+00]], dtype=torch.float64) # # a=t.from_numpy(np.ones([2,3],dtype='float64')) # print(a) # a=t.from_numpy(np.ones([2,3],dtype='float32')) # print(a) # # tensor([[1., 1., 1.], # # [1., 1., 1.]], dtype=torch.float64) # # tensor([[1., 1., 1.], # # [1., 1., 1.]]) # # print('cuda available? ', t.cuda.is_available())#cuda available? False # a=t.rand(2,3,dtype=t.float64) # print(a) # # tensor([[0.8559, 0.9666, 0.9605], # # [0.5527, 0.4796, 0.9490]], dtype=torch.float64) # out = None # a = t.empty(2, 3, out=out) # print(a, type(a)) # print(str(a.size())) # torch.Size([2, 3]) # print(str(a.shape)) # torch.Size([2, 3]) # print(a.size()) # torch.Size([2, 3]) # print(a.shape) # torch.Size([2, 3]) # print(a.size(0)) # 2 # print(a.shape[0]) # 2 # # size要用小括号,小括号内可以指定维度,也可以不指定参数 # # shape不能用小括号,可以用用方括号(内写指定维度),也可以不用方括号 # # tensor([[0., 0., 0.], # # [0., 0., 0.]]) # # print(a.shape()) # # TypeError: 'torch.Size' object is not callable??? # # print(out,out.shape()) # # AttributeError: 'NoneType' object has no attribute 'shape' # # # a=t.tensor([[1,2,3]],dtype=t.float64,device='cuda:0') # # print(a)#AssertionError: Torch not compiled with CUDA enabled # a = t.tensor([]) # print(a, a.shape) # tensor([]) torch.Size([0]) # a = t.tensor(3.1415926) # print(a, a.shape) # tensor(3.1416) torch.Size([]) |
#判断是否安装了cuda
import torch
print(torch.cuda.is_available()) #返回True则说明已经安装了cuda
#判断是否安装了cuDNN
from torch.backends import cudnn
print(cudnn.is_available()) #返回True则说明已经安装了cuDNN
generative英 [ˈdʒenərətɪv] 美 [ˈdʒenərətɪv]adj. 有生产力的,有生殖力的;(语言学)生成的
adversarial英 [ˌædvəˈseəriəl] 美 [ˌædvərˈseriəl]adj. 对抗的;对手的,敌手的
GAN=Generative Adversarial Net=生成对抗网络
ResNet模型的实现
|
import torch as t import torch.nn.functional from torch import nn import torch.nn.functional as f class ResidualBlock(nn.Module):#实现子模块,残差模块 def __init__(self,inchannel,outchannel,stride=1,shortcut=None): super(ResidualBlock, self).__init__() self.left=nn.Sequential( nn.Conv2d(inchannel,outchannel,kernel_size=3,stride=stride,padding=1,bias=False) ,nn.BatchNorm2d(outchannel), nn.ReLU(inplace=True), nn.Conv2d(outchannel,outchannel,kernel_size=3,stride=1,padding=1,bias=False) ,nn.BatchNorm2d(outchannel) ) self.right=shortcut
def forward(self,x): out=self.left(x) residual=x if self.right is None else self.right(x) out+=residual return f.relu(out)
class ResNet(nn.Module):#主要模块 def __init__(self,num_classes=1000): super(ResNet, self).__init__() self.pre=nn.Sequential( nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3,bias=False), nn.BatchNorm2d(64), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3,stride=2,padding=1), ) #重复模块,分别有3-4-6-3个残差模块 self.layer1=self.make_layer(inchannel=64,outchannel=128,block_num=3) self.layer2=self.make_layer(inchannel=128,outchannel=256,block_num=4,stride=2) self.layer3=self.make_layer(inchannel=256,outchannel=512,block_num=6,stride=2) self.layer4=self.make_layer(inchannel=512,outchannel=512,block_num=3,stride=2) self.fc=nn.Linear(in_features=512,out_features=num_classes) def make_layer(self,inchannel,outchannel,block_num,stride=1): shortcut=nn.Sequential( nn.Conv2d(in_channels=inchannel,out_channels=outchannel,kernel_size=1,stride=stride,bias=False), nn.BatchNorm2d(num_features= outchannel) ) layers=[] layers.append(ResidualBlock(inchannel=inchannel,outchannel=outchannel,stride=stride,shortcut=shortcut)) for i in range(1,block_num): layers.append(ResidualBlock(inchannel=outchannel,outchannel=outchannel)) return nn.Sequential(*layers)
def forward(self,x):#前向传播网络 x=self.pre(x) x=self.layer1(x) x=self.layer2(x) x=self.layer3(x) x=self.layer4(x) x=f.avg_pool2d(x,7) x=x.view(x.size(0),-1) return self.fc(x) #测试模型能否运行 model=ResNet() input=t.autograd.Variable(t.randn(1,3,224,224)) output=model(input) print(output.size())#torch.Size([1, 1000]) |
nn.Module实现了自定义的__setattr函数,当执行module.name=value时,会在__setter__总判断,value是否是Parameter对象或者Module对象;
- 如果是Parameter对象,则添加都_parameters字典中;
- 如果是Module对象,则添加到_modules字典中;
- 如果是其他对象,则保存到__dict__字典中;
其他对象,诸如Variable、list、dict等,会调用默认操作;
nn.Module设置参数、读取参数setattr/__setattr__/getattr/__getattr__
|
import torch as t from torch import nn module=nn.Module() module.param=nn.Parameter(t.ones(2,3)) module.param2=nn.Parameter(t.zeros(2,3)) module.what=nn.Parameter(t.randn(2,3)) print('params=', module._parameters) submodule1=nn.Linear(2,3) submodule2=nn.Linear(3,2) module_list=[submodule1,submodule2]
module.submodules=module_list print('modules=', module._modules) print('dict=',module.__dict__) # params= OrderedDict([('param', Parameter containing: # tensor([[1., 1., 1.], # [1., 1., 1.]], requires_grad=True)), ('param2', Parameter containing: # tensor([[0., 0., 0.], # [0., 0., 0.]], requires_grad=True)), ('what', Parameter containing: # tensor([[ 1.7606, -0.2944, -0.1285], # [ 2.0030, -0.0090, -0.8874]], requires_grad=True))]) # modules= OrderedDict() # dict= {'training': True, '_parameters': OrderedDict([('param', Parameter containing: # tensor([[1., 1., 1.], # [1., 1., 1.]], requires_grad=True)), ('param2', Parameter containing: # tensor([[0., 0., 0.], # [0., 0., 0.]], requires_grad=True)), ('what', Parameter containing: # tensor([[ 1.7606, -0.2944, -0.1285], # [ 2.0030, -0.0090, -0.8874]], requires_grad=True))]), '_buffers': OrderedDict(), '_non_persistent_buffers_set': set(), '_backward_hooks': OrderedDict(), '_is_full_backward_hook': None, '_forward_hooks': OrderedDict(), '_forward_pre_hooks': OrderedDict(), '_state_dict_hooks': OrderedDict(), '_load_state_dict_pre_hooks': OrderedDict(), '_modules': OrderedDict(), 'submodules': [Linear(in_features=2, out_features=3, bias=True), Linear(in_features=3, out_features=2, bias=True)]} |
rand、randn、randint、randperm的区别
|
rand/rand_like 均匀分布 浮点数 |
生成均匀分布的伪随机数。分布在(0~1)之间 主要语法:rand(m,n)生成m行n列的均匀分布的伪随机数,rand(m,n,'double')生成指定精度的均匀分布的伪随机数,参数还可以是'single', rand(RandStream,m,n)利用指定的RandStream(我理解为随机种子)生成伪随机数。 |
|
randn/randn_like 正态分布 浮点数 |
生成标准正态分布的伪随机数(均值为0,方差为1) 主要语法:和上面一样 |
|
randint/randint_like 均匀分布 整数 |
生成均匀分布的伪随机整数 主要语法:randi(iMax)在开区间(0,iMax)生成均匀分布的伪随机整数,randi(iMax,m,n)在开区间(0,iMax)生成mXn型随机矩阵, r = randi([iMin,iMax],m,n)在开区间(iMin,iMax)生成mXn型随机矩阵 print(t.randint(low=2, high=22, size=(2, 3))) # tensor([[11, 14, 14], # [20, 14, 4]]) |
|
randperm 整数序列 随机打乱 |
将0~n-1(包括0和n-1)随机打乱后获得的数字序列,函数名是random permutation缩写 torch.randperm(10) ===> tensor([2, 3, 6, 7, 8, 9, 1, 5, 0, 4]) |
|
normal 正态分布 浮点数 |
指定标准值和方差的正态分布 t.normal(mean=2,std=0.5,size=(2,3)) # tensor([[2.3745, 2.8523, 2.2585], # [1.9185, 2.0552, 2.5832]]) |
Linear英 /ˈlɪniə(r)/ 美 /ˈlɪniər/
adj. (linear)线形的;线条构成的;一维的;直线的;连续的;长度的;
Regression英 /rɪˈɡreʃn/ 美 /rɪˈɡreʃn/
- 后退,倒退;(思想或行为的)退化,退行;(疾病或症状的)消退;(统计)回归
线性回归Linear Regression
y=2x+3
|
import torch as t
t.manual_seed(666)
def get_fake_data(batch_size=8): x = t.rand(batch_size, 1) * 20 y = x * 2 + 3 * (1 + t.randn(batch_size, 1)) return x, y
# a=t.randn(8,1) # print(a)#一个8行1列的随机浮点数张量, # print(a+1)#得到一个同样shape的张量,原张量中的每个元素+1 # print(a*20)#得到一个同样shape的张量,原张量中的每个元素*20 w = t.rand(1, 1) # w = {Tensor: (1, 1)} tensor([[0.3119]]) b = t.zeros(1, 1) # b = {Tensor: (1, 1)} tensor([[0.]]) print(w, b) # tensor([[-2.1188]]) tensor([[0.]]) lr = 0.0001 for i in range(100000): x, y = get_fake_data() # x = {Tensor: (8, 1)} tensor([[ 5.4027],\n [ 2.2356],\n [ 2.0238],\n [ 3.7534],\n [ 0.3614],\n [ 6.6332],\n [ 1.6924],\n [11.4647]]) # y = {Tensor: (8, 1)} tensor([[16.6664],\n [ 8.6711],\n [ 7.9312],\n [16.1143],\n [ 3.9674],\n [16.0883],\n [ 8.6416],\n [25.1568]]) yy = x.mm(w) + b.expand_as(y) # yy = {Tensor: (8, 1)} # tensor([[1.6851],\n[0.6973],\n[0.6312],\n[1.1707],\n[0.1127],\n[2.0689],\n[0.5279],\n[3.5759]]) loss = 0.5 * (yy - y) ** 2 #loss = {Tensor: (8, 1)} tensor([[112.2190],\n [ 31.7906],\n [ 26.6447],\n [111.6561],\n [ 7.4291],\n [ 98.2707],\n [ 32.9161],\n [232.8672]]) loss = loss.sum() # loss = {Tensor: ()} tensor(653.7937)
dloss = 1 dyy = dloss * (yy - y) # dyy = {Tensor: (8, 1)} tensor([[-14.9813],\n [ -7.9738],\n [ -7.3000],\n [-14.9436],\n [ -3.8546],\n [-14.0193],\n [ -8.1137],\n [-21.5809]]) dw = x.t().mm(dyy) # dw = {Tensor: (1, 1)} tensor([[-525.1661]]) db = dyy.sum() # db = {Tensor: ()} tensor(-92.7672) # print(dw,db) w.sub_(lr * dw) b.sub_(lr * db) if i % 1000 == 0: print('loss=', loss) print(w, b)
print(w, b) # 20000次 lr=0.001 tensor([[1.8863]]) tensor([[3.0359]]) # 50000次 lr=0.001 tensor([[2.1000]]) tensor([[2.9335]]) # 100000次 lr=0.001 tensor([[1.9338]]) tensor([[3.0801]])
# 20000次 lr=0.002 tensor([[-4.2102e+27]]) tensor([[2.4097e+28]])
# 50000次 lr=0.0005 tensor([[2.1000]]) tensor([[2.9335]])
# 100000次 lr=0.0005 tensor([[2.0071]]) tensor([[3.0708]]) # 100000次 lr=0.0001 tensor([[2.0124]]) tensor([[3.0179]]) |
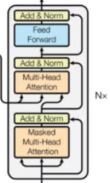
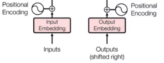
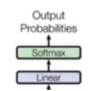
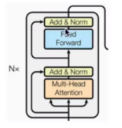
transformer的结构
|
输入部分 |
源文本嵌入层及其位置编码器 目标文本嵌入层及其位置编码器 |
|
|
输出部分 |
线性层 softmax处理器 |
|
|
编码部分
|
l 由N个编码器堆叠而成 l 每个编码器层由两个子层连接结构组成 l 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接 l 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接 |
|
|
解码部分
|
由N个解码器堆叠而成 每个解码器层由三个子层连接结构组成 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接 |
 |
设置打印精度
# cuda=t.cuda.is_available()
# print(cuda)#False
a=t.arange(0,200000000)
print(a[-1],a[-2])
b=t.LongTensor()
t.arange(0,200000000,out=b)
print(b[-1],b[-2])
# tensor(199999999) tensor(199999998)
# tensor(199999999) tensor(199999998)
a=t.randn(2,3)
print(a)
t.set_printoptions(precision=10)
print(a)
t.set_printoptions(precision=1)
print(a)
# tensor([[-2.2942, -0.4601, 0.1074],
# [-2.9773, 1.0079, 0.2336]])
# tensor([[-2.2942085266, -0.4601041079, 0.1074189320],
# [-2.9773204327, 1.0079128742, 0.2335681021]])
# tensor([[-2.3, -0.5, 0.1],
# [-3.0, 1.0, 0.2]])
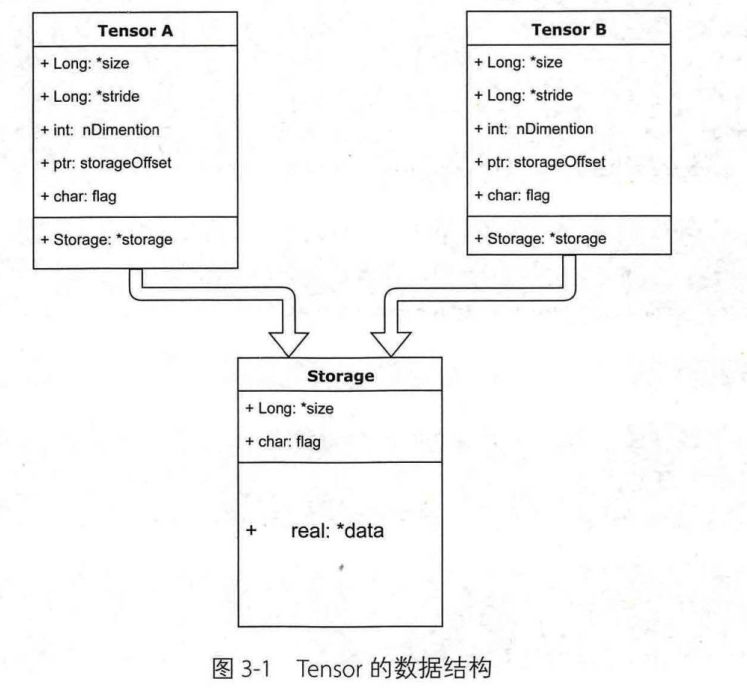
Tensor的数据结构和物理结构(存储)
|
import torch as t a=t.arange(0,6) print(a.storage()) b=a.view(2,3) print(b.storage()) # 0 # 1 # 2 # 3 # 4 # 5 # [torch.LongStorage of size 6] # 0 # 1 # 2 # 3 # 4 # 5 # [torch.LongStorage of size 6] print(id(a.storage())) print(id(b.storage())) # 2171445425992 # 2171445425992 #存储地址完全相同,表示共享同一块内存空间 #不同的Tensor的头信息一般不同,但是可能使用相同的storage
|
import torch as t a=t.arange(0,6) b=a.view(2,3) print(a) print(b) a[1]=666 print(a) print(b)
# tensor([0, 1, 2, 3, 4, 5]) # tensor([[0, 1, 2], # [3, 4, 5]]) # tensor([ 0, 666, 2, 3, 4, 5]) # tensor([[ 0, 666, 2], # [ 3, 4, 5]]) c=a[:3] print(c) c[0]=222 print(a) print(b) print(c) # tensor([ 0, 666, 2]) # tensor([222, 666, 2, 3, 4, 5]) # tensor([[222, 666, 2], # [ 3, 4, 5]]) # tensor([222, 666, 2]) # a,b=a.view(2,3) ,c=a[:3]共享同一块内存 |
expand向左扩展维度、扩展元素个数
a=t.ones(2,3)
只能在左侧增加维度,而不能在右侧增加维度,也不能在中间增加维度
新增维度的元素个数可以为任意数字
|
a2=a.expand(1,2,3) print(a2.shape)#torch.Size([1, 2, 3])
|
左侧增加一个维度,元素个数为1 |
|
a2=a.expand(1,1,2,3) print(a2.shape)#torch.Size([1, 1, 2, 3])
|
左侧增加1个维度,元素个数1 |
|
a2=a.expand(3,2,3) print(a2.shape)#torch.Size([3, 2, 3]) |
左侧增加1个维度,元素个数复制为3份 |
|
# a2=a.expand(2,3,1) # print(a2.shape) # RuntimeError: The expanded size of the tensor (1) must match the existing size (3) at non-singleton dimension 2. Target sizes: [2, 3, 1]. Tensor sizes: [2, 3] |
Error:右侧增加维度,报错 |
|
a2=a.expand(2,1,3) print(a2.shape) # RuntimeError: The expanded size of the tensor (1) must match the existing size (2) at non-singleton dimension 1. Target sizes: [2, 1, 3]. Tensor sizes: [2, 3] |
Error:中间增加维度,报错 |
view扩展一个或者多个维度
a=t.ones(2,3)
扩展维度上的数字(元素个数)只能是1
|
a2=a.view(1,2,3) print(a2.shape)#torch.Size([1, 2, 3]) |
扩展第0维:[2, 3]→[1, 2, 3] |
|
a2=a.view(2,1,3) print(a2.shape)#torch.Size([2, 1, 3]) |
扩展第1维:[2, 3]→[2, 1, 3] |
|
a2=a.view(2,3,1) print(a2.shape)#torch.Size([2, 3, 1]) |
扩展第2维:[2, 3]→[2, 3, 1] |
|
a2=a.view(1,1,2,3) print(a2.shape)#torch.Size([1, 1, 2, 3]) |
扩展多个维度:[2, 3]→[1, 1, 2, 3] |
|
a2=a.view(1,1,2,1,1,3,1,1) print(a2.shape)#torch.Size([1, 1, 2, 1, 1, 3, 1, 1]) |
扩展多个维度:[2, 3]→[1, 1, 2, 1, 1, 3, 1, 1] |
|
a2=a.view(1,1,3,1,1,2,1,1) print(a2.shape)#torch.Size([1, 1, 3, 1, 1, 2, 1, 1]) |
扩展多个维度:[2, 3]→[1, 1, 3, 1, 1, 2, 1, 1] |
unsqueeze扩展一个维度
a=t.ones(2,3)
|
a2=a.unsqueeze(0) print(a2.shape)# torch.Size([1, 2, 3]) |
扩展第0维:[2, 3]→[1, 2, 3] |
|
a2=a.unsqueeze(1) print(a2.shape)# torch.Size([2, 1, 3]) |
扩展第1维:[2, 3]→[2, 1, 3] |
|
a2=a.unsqueeze(2) print(a2.shape)# torch.Size([2, 3, 1]) |
扩展第2维:[2, 3]→[2, 3, 1] |
|
a2=a.unsqueeze(3) #IndexError: Dimension out of range (expected to be in range of [-3, 2], but got 3) |
扩展第3维:Error |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号