
基于TensorFlow和Python的机器学习(笔记3)
基于TensorFlow和Python的机器学习(笔记3)
# region 中文情感分析任务 参数配置
task_name = 'CC' # Chinese_classification
do_train = True
do_eval = True
data_dir = '../GLUE/glue_data/Chinese_classification'
vocab_file = '../GLUE/BERT_BASE_DIR/chinese_L-12_H-768_A-12/vocab.txt'
bert_config_file = '../GLUE/BERT_BASE_DIR/chinese_L-12_H-768_A-12/bert_config.json'
init_checkpoint = '../GLUE/BERT_BASE_DIR/chinese_L-12_H-768_A-12/bert_model.ckpt'
max_seq_length = 128
train_batch_size = 32
learning_rate = 2e-5
num_train_epochs = 3.0
output_dir = '../GLUE/output_CC'
do_predict = False
# do_train = False
# do_eval = False
# init_checkpoint='../GLUE/output_CC'
# do_predict=True
# endregion
train.tsv

_read_tsv
|
@classmethod #读取tsv文件每一行,并且把每一行用分隔符切割开来,返回一个嵌套列表 def _read_tsv(cls, input_file, quotechar=None): """Reads a tab separated value file.""" with tf.gfile.Open(input_file, "r") as f: reader = csv.reader(f, delimiter="\t", quotechar=quotechar) lines = [] for line in reader: lines.append(line) return lines #按行读取,并将每行用delimiter进行切分 |
读取的行数据
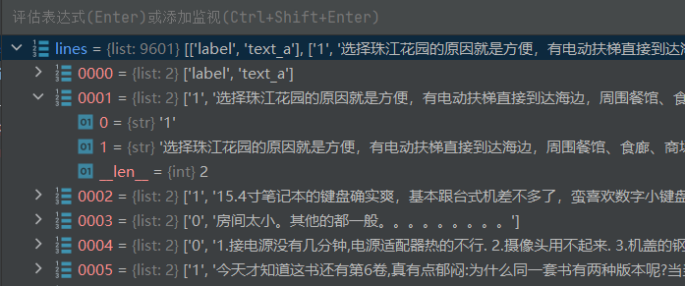
创建例子
|
def _create_examples(self, lines, set_type): """Creates examples for the training and dev sets.""" #lines 读取tsv文件所获取的每一行文本数据,并且用分隔符切分成列表格式 #set_type 数据集类型"train"表示训练集 "dev"评估数据集 "test"测试数据集 examples = [] for (i, line) in enumerate(lines): if i == 0: continue guid = "%s-%s" % (set_type, i) #获取编号 guid = {str} 'train-1' text_a = tokenization.convert_to_unicode(line[1]) # text_a = {str} '选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般' text_b = None #情感分类任务没有句子b,设置为None值 text_b = {NoneType} None label = tokenization.convert_to_unicode(line[0]) # 读取标签 字符串格式 1表示正面评价,0表示负面评价 label = {str} '1' examples.append( InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label)) return examples |
例子数据
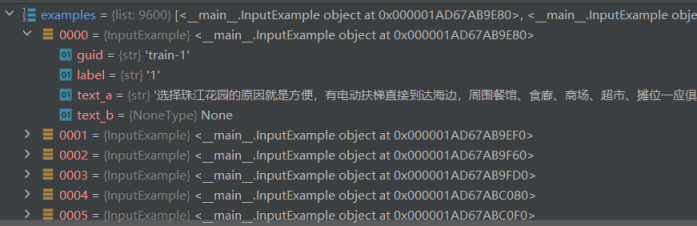
解析特征
|
def convert_single_example(ex_index, example, label_list, max_seq_length, tokenizer): """Converts a single `InputExample` into a single `InputFeatures`.""" # 如果是假例子,就返回一个空的特征数据,所有特征值全为0 if isinstance(example, PaddingInputExample): return InputFeatures( input_ids=[0] * max_seq_length, input_mask=[0] * max_seq_length, segment_ids=[0] * max_seq_length, label_id=0, is_real_example=False)
label_map = {} # 创建标签的映射字典 for (i, label) in enumerate(label_list): label_map[label] = i
tokens_a = tokenizer.tokenize(example.text_a) tokens_b = None if example.text_b: tokens_b = tokenizer.tokenize(example.text_b)
if tokens_b: # 有句子b的情况下,按照句子对进行截断操作,总长度要扣除3个标志位[CLS], [SEP], [SEP] # Modifies `tokens_a` and `tokens_b` in place so that the total # length is less than the specified length. # Account for [CLS], [SEP], [SEP] with "- 3" _truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3) else: # 没有句子b的情况下,按照单个句子进行截断操作,总长度要扣除2个标志位[CLS], [SEP] # Account for [CLS] and [SEP] with "- 2" if len(tokens_a) > max_seq_length - 2: tokens_a = tokens_a[0:(max_seq_length - 2)]
# The convention in BERT is: # (a) For sequence pairs: # tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP] # type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1 # (b) For single sequences: # tokens: [CLS] the dog is hairy . [SEP] # type_ids: 0 0 0 0 0 0 0 # # Where "type_ids" are used to indicate whether this is the first # sequence or the second sequence. The embedding vectors for `type=0` and # `type=1` were learned during pre-training and are added to the wordpiece # embedding vector (and position vector). This is not *strictly* necessary # since the [SEP] token unambiguously separates the sequences, but it makes # it easier for the model to learn the concept of sequences. # # For classification tasks, the first vector (corresponding to [CLS]) is # used as the "sentence vector". Note that this only makes sense because # the entire model is fine-tuned. tokens = [] segment_ids = [] tokens.append("[CLS]") # 标记符号序列以[CLS]开头 segment_ids.append(0) # [CLS]属于句子a,所以分割标志设置为0 for token in tokens_a: # 首先对句子a进行处理 tokens.append(token) # 挨个将字符添加到字符序列 segment_ids.append(0) # 句子a的分割标志都是0 tokens.append("[SEP]") # 句子a要以[SEP]为结束标志 segment_ids.append(0)
if tokens_b: # 如果有句子b,则对句子b进行处理 for token in tokens_b: tokens.append(token) # 挨个将字符添加到字符序列 segment_ids.append(1) # 句子b的分割标志都是1 tokens.append("[SEP]") # 句子b要以[SEP]为结束标志 segment_ids.append(1) # 最后一个[SEP]标志属于句子b,所以分割标志设置为1 # 按照字典的映射关系,将分割的符号全部转换为数字 input_ids = tokenizer.convert_tokens_to_ids(tokens)
# The mask has 1 for real tokens and 0 for padding tokens. Only real # tokens are attended to. input_mask = [1] * len(input_ids) # 实际添加的字符的掩码全部设置为1,表示真实的字符 # 为了长度一致而补充的字符,掩码全部设置为0,表示无意义的字符 # Zero-pad up to the sequence length. while len(input_ids) < max_seq_length: input_ids.append(0) input_mask.append(0) segment_ids.append(0) # 断言:所有长度都是相同的,并且都等于序列的最大允许长度, # 如有长度不同的情况,就触发异常 assert len(input_ids) == max_seq_length assert len(input_mask) == max_seq_length assert len(segment_ids) == max_seq_length
label_id = label_map[example.label] # 通过标签字典,将标签值映射为数值 if ex_index < 5: # 打印一些信息 tf.logging.info("*** Example ***") tf.logging.info("guid: %s" % (example.guid)) tf.logging.info("tokens: %s" % " ".join( [tokenization.printable_text(x) for x in tokens])) tf.logging.info("input_ids: %s" % " ".join([str(x) for x in input_ids])) tf.logging.info("input_mask: %s" % " ".join([str(x) for x in input_mask])) tf.logging.info("segment_ids: %s" % " ".join([str(x) for x in segment_ids])) tf.logging.info("label: %s (id = %d)" % (example.label, label_id)) # 通过获取的数据,构建特征对象,并将该对象返回 feature = InputFeatures( input_ids=input_ids, input_mask=input_mask, segment_ids=segment_ids, label_id=label_id, is_real_example=True) return feature |
特征数据
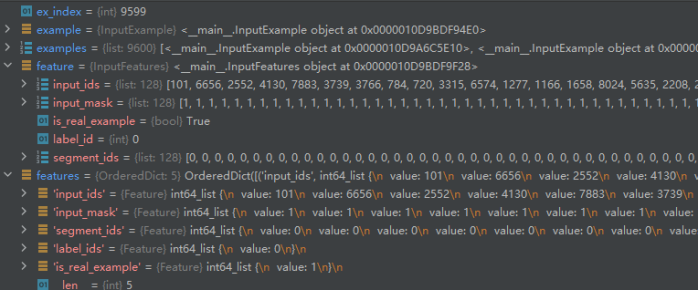
bert模型配置参数
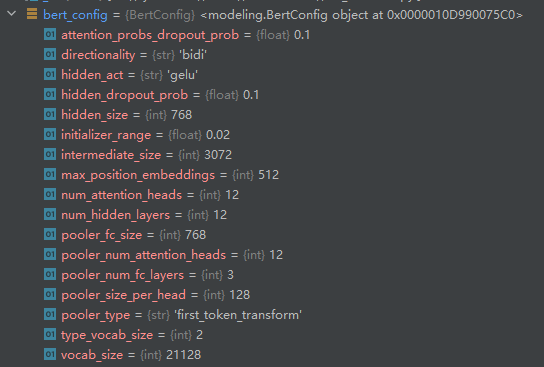
数据处理器
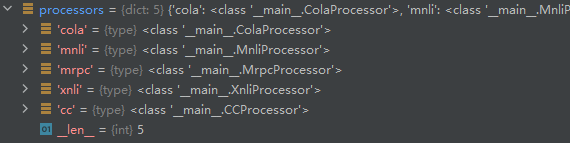
estimator配置参数
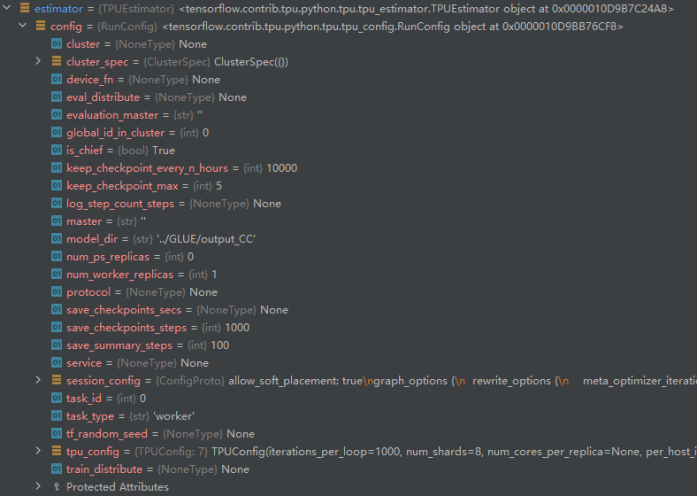
运行配置参数
分词器-完全分词

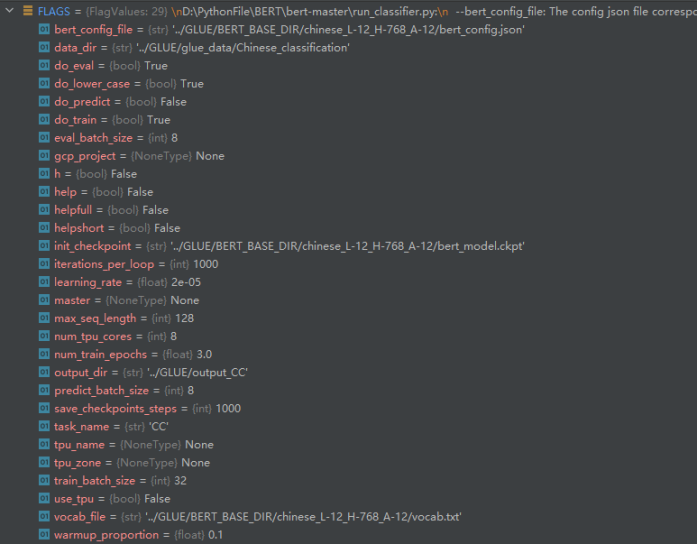
FLAGS参数
训练过程截图
评估结果

eval_results.txt
eval_accuracy = 0.93416667
eval_loss = 0.24893652
global_step = 900
loss = 0.24893652
检查点

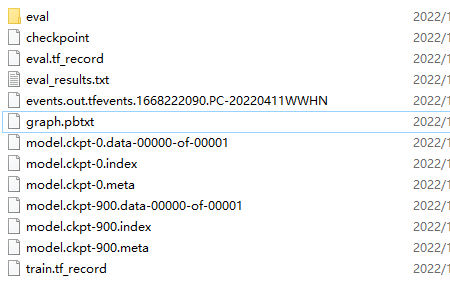
输出文件清单
进行预测
参数设置
do_train = False
do_eval = False
init_checkpoint='../GLUE/output_CC'
do_predict=True
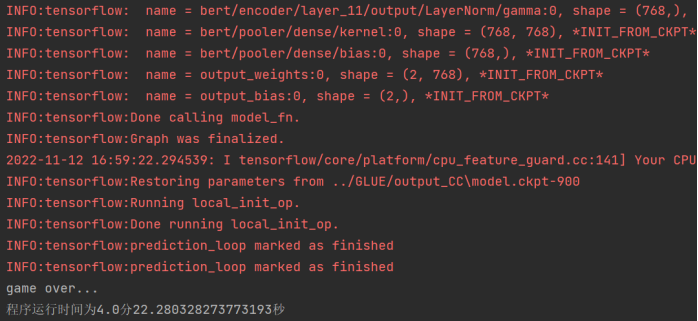
预测过程截图
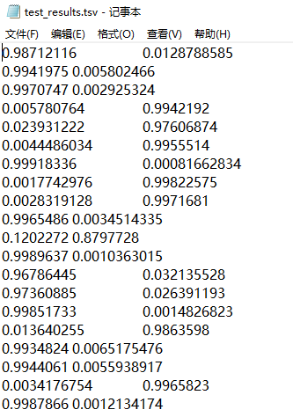
预测结果
|
|
|

unicodedata.category(chr)
把一个字符返回它在UNICODE里分类的类型。具体类型如下:
Code Description
[Cc] Other, Control
[Cf] Other, Format
[Cn] Other, Not Assigned (no characters in the file have this property)
[Co] Other, Private Use
[Cs] Other, Surrogate
[LC] Letter, Cased
[Ll] Letter, Lowercase
[Lm] Letter, Modifier
[Lo] Letter, Other
[Lt] Letter, Titlecase
[Lu] Letter, Uppercase
[Mc] Mark, Spacing Combining
[Me] Mark, Enclosing
[Mn] Mark, Nonspacing
[Nd] Number, Decimal Digit
[Nl] Number, Letter
[No] Number, Other
[Pc] Punctuation, Connector
[Pd] Punctuation, Dash
[Pe] Punctuation, Close
[Pf] Punctuation, Final quote (may behave like Ps or Pe depending on usage)
[Pi] Punctuation, Initial quote (may behave like Ps or Pe depending on usage)
[Po] Punctuation, Other
[Ps] Punctuation, Open
[Sc] Symbol, Currency
[Sk] Symbol, Modifier
[Sm] Symbol, Math
[So] Symbol, Other
[Zl] Separator, Line
[Zp] Separator, Paragraph
[Zs] Separator, Space
Bert模型数据流向图
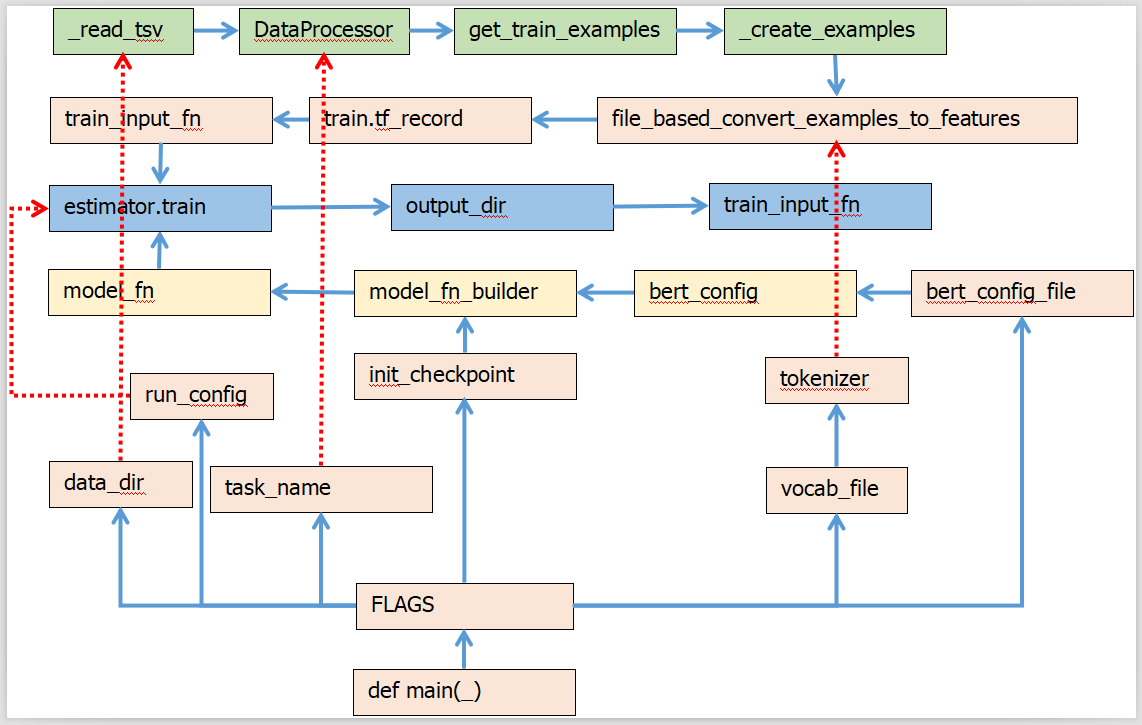
TensorFlow框架图

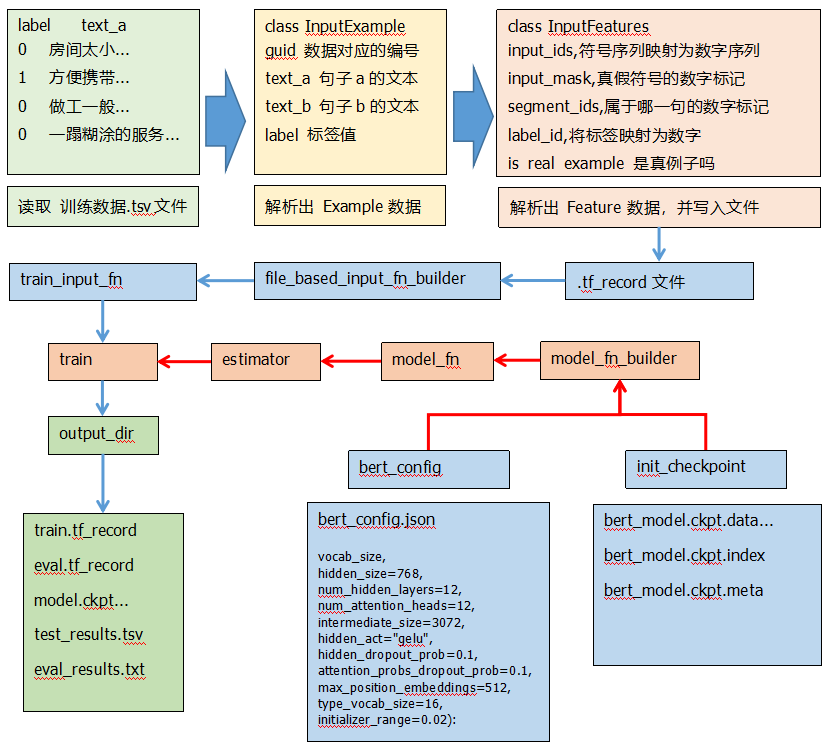
Bert模型流程图
variable_scope()是作用域,和tf.get_variable()搭配使用
variable_scope也是个作为上下文管理器的角色,
下文管理器:意思就是,在这个管理器下做的事情,会被这个管理器管着。
variable_scope 主要是因为 变量共享 的需求。
|
tf.name_scope()和tf.variable_scope()
|
tf.name_scope()和tf.variable_sc tf.name_scope()和tf.variable_scope()是两个作用域,一般与两个创建/调用变量的函数tf.variable() 和tf.get_variable()搭配使用。 tf.name_scope和 variable_scope也是个作为上下文管理器的角色, 下文管理器:意思就是,在这个管理器下做的事情,会被这个管理器管着。 name_scope 和 variable_scope的用途: name_scope 和 variable_scope 主要是因为 变量共享 的需求。 |
|
tf.transpose转置
|
perm:控制转置的操作,以perm = [0,1,2] 3个维度的数组为例, 0–代表的是最外层的一维, 1–代表外向内数第二维, 2–代表最内层的一维,这种perm是默认的值.如果换成[1,0,2],就是把最外层的两维进行转置,比如原来是2乘3乘4,经过[1,0,2]的转置维度将会变成3乘2乘4
|
|
tf.gather( )收集
|
tf.gather(params,indices,axis=0 ) 从params的axis维根据indices的参数值获取切片
将张量中对应索引的元素全部取出,组成一个新的张量,
|
|
tf.slice()切片
|
函数:tf.slice(inputs, begin, size, name) 作用:从列表、数组、张量等对象中抽取一部分数据 begin和size是两个多维列表,他们共同决定了要抽取的数据的开始和结束位置 begin表示从inputs的哪几个维度上的哪个元素开始抽取 size表示在inputs的各个维度上抽取的元素个数 若begin[]或size[]中出现-1,表示抽取对应维度上的所有元素 begin = [0,1] # 从x[0,1],即元素2开始抽取 size = [2,1] # 从x[0,1]开始,对x的第一个维度(行)抽取2个元素,在对x的第二个维度(列)抽取1个元素
|
|
tf.get_variable |
该函数共有十一个参数,常用的有:名称name、变量规格shape、变量类型dtype、变量初始化方式initializer、所属于的集合collections。 get_variable函数的作用是创建新的tensorflow变量,常见的initializer有:常量初始化器tf.constant_initializer、正太分布初始化器tf.random_normal_initializer、截断正态分布初始化器tf.truncated_normal_initializer、均匀分布初始化器tf.random_uniform_initializer。
|
|
tf.control_dependencies()
|
tf.control_dependencies是tensorflow中的一个flow顺序控制机制,作用有二: 插入依赖(dependencies)和清空依赖(依赖是op或tensor)。 常见的tf.control_dependencies是tf.Graph.control_dependencies的装饰器,它们用法是一样的。 |
|
tf.assert_less_equal() |
断言条件:如果 x <= y 保持元素,如果x>y就抛出异常 tf.compat.v1.assert_less_equal 与即刻执行和 tf.function 兼容。迁移到 TF2 时,请改用tf.debugging.assert_less_equal。除了 data 之外,所有参数都支持相同的参数名称。 |
|
tf.one_hot() |
tf.one_hot()函数是将input转化为one-hot类型数据输出,相当于将多个数值联合放在一起作为多个相同类型的向量,可用于表示各自的概率分布,通常用于分类任务中作为最后的FC层的输出,有时翻译成“独热”编码。 tensorflow的help中相关说明如下: one_hot(indices, depth, on_value=None, off_value=None, axis=None, dtype=None, name=None) Returns a one-hot tensor. indices表示输入的多个数值,通常是矩阵形式; depth表示输出的尺寸,也就是向量的维度。
|
|
tf.truncated_normal_initializer |
从截断的正态分布中输出随机值。 生成的值服从具有指定平均值和标准偏差的正态分布, 如果生成的值大于平均值2个标准偏差的值则丢弃重新选择。 标准差stdev可以可以看成是生成随机数的一个范围;
|
|
tf.reshape -1 |
函数用于张量维度调整,但是不会修改内部元素的数量以及相对顺序 shape中-1表示这个维度的大小,程序运行时会自动计算填充(因为变换前后元素数量不变,我们可以根据其他维度的大小,最终确定-1这个位置应该表示的数字) 如果需要通过修改内部元素的存储顺序以实现维度调整,需要使用tf.transpose函数 与常用的更改结构的函数的最大不同在于tf.reshape()函数中经常会用到-1; 哪一维使用了-1,那这一维度就不定义大小,而是根据你的数据情况进行匹配。即先不管-1的那一个维度,先看其他维度,然后用原矩阵的总元素个数除以确定的维度,就能得到-1维度的值。 不过要注意:但列表中只能存在一个-1。 |
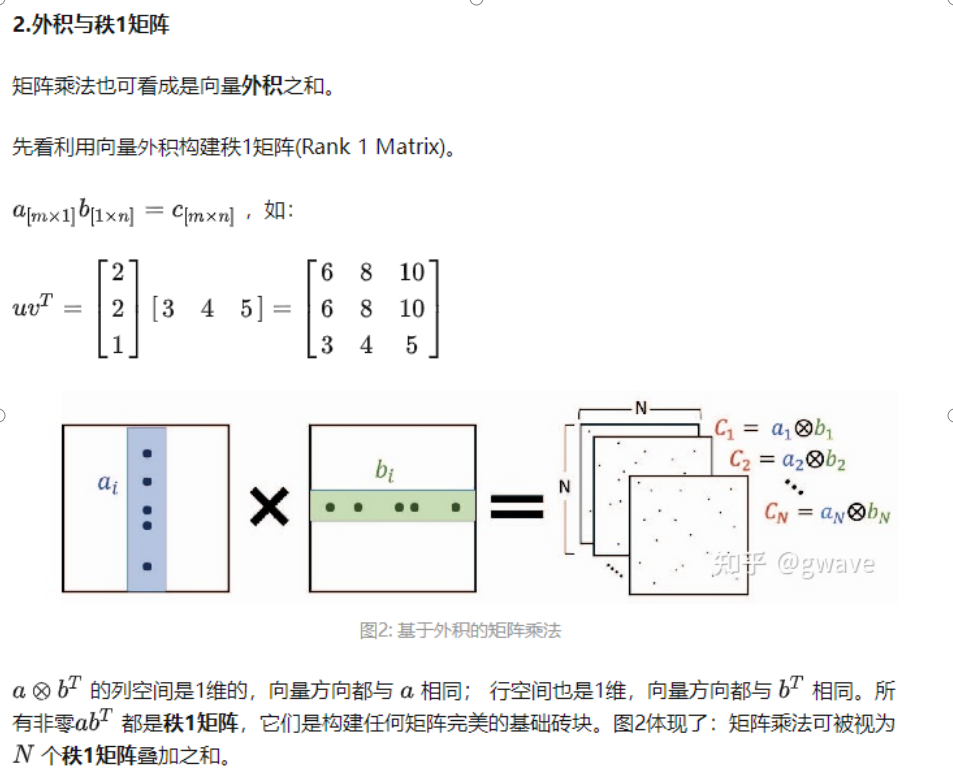
矩阵乘法:1 内积拼装法 2 外积求和法
矩阵乘法,向量内积计算每个元素,然后得到新的矩阵

先计算向量的外积,得到很多矩阵,然后矩阵相加,得到结果
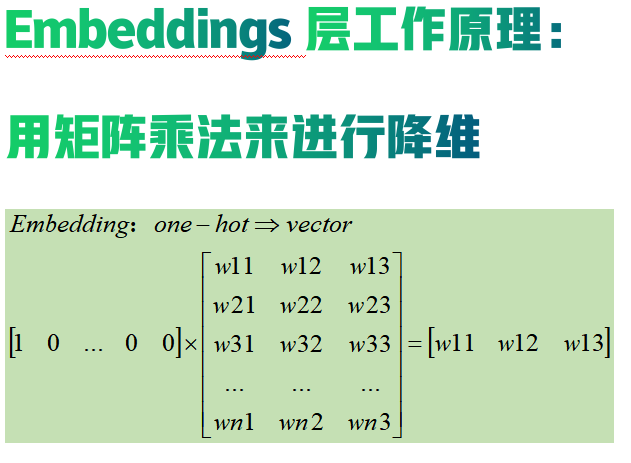
embedding的原理是使用矩阵乘法来进行降维,
从而达到节约存储空间的目的。
word2vector工作流程图
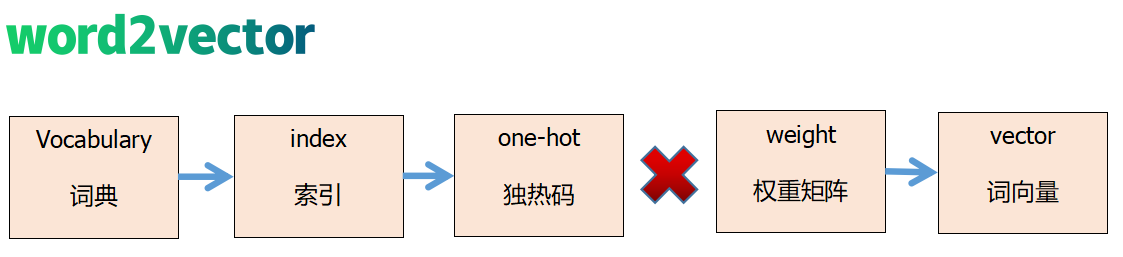
embedding 有以下 3 个主要目的:
- 在 embedding 空间中查找最近邻,这可以很好的用于根据用户的兴趣来进行推荐。
- 作为监督性学习任务的输入。
- 用于可视化不同离散变量之间的关系。
One-hot 编码是一种最普通常见的表示离散数据的表示,首先我们计算出需要表示的离散或类别变量的总个数 N,然后对于每个变量,我们就可以用 N-1 个 0 和单个 1 组成的 vector 来表示每个类别。
One-hot有两个很明显的缺点:
- 对于具有非常多类型的类别变量,变换后的向量维数过于巨大,且过于稀疏。
- 映射之间完全独立,并不能表示出不同类别之间的关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号