
自然语言处理NLP与深度学习(学习笔记)
自然语言处理NLP与深度学习(学习笔记)
字母转有声调的字母

Jieba词性标注集
a 形容词
ad 副形词
an 名形词
ag 形容词性语素
al 形容词性惯用语
区别词(1个一类,2个二类)
b 区别词
bl 区别词性惯用语
连词(1个一类,1个二类)
c 连词
cc 并列连词
副词(1个一类)
d 副词
叹词(1个一类)
e 叹词
方位词(1个一类)
f 方位词
前缀(1个一类)
h 前缀
后缀(1个一类)
k 后缀
数词(1个一类,1个二类)
m 数词
mq 数量词
名词 (1个一类,7个二类,5个三类)
名词分为以下子类:
n 名词
nr 人名
nr1 汉语姓氏
nr2 汉语名字
nrj 日语人名
nrf 音译人名
ns 地名
nsf 音译地名
nt 机构团体名
nz 其它专名
nl 名词性惯用语
ng 名词性语素
拟声词(1个一类)
o 拟声词
介词(1个一类,2个二类)
p 介词
pba 介词“把”
pbei 介词“被”
量词(1个一类,2个二类)
q 量词
qv 动量词
qt 时量词
代词(1个一类,4个二类,6个三类)
r 代词
rr 人称代词
rz 指示代词
rzt 时间指示代词
rzs 处所指示代词
rzv 谓词性指示代词
ry 疑问代词
ryt 时间疑问代词
rys 处所疑问代词
ryv 谓词性疑问代词
rg 代词性语素
处所词(1个一类)
s 处所词
时间词(1个一类,1个二类)
t 时间词
tg 时间词性语素
助词(1个一类,15个二类)
u 助词
uzhe 着
ule 了 喽
uguo 过
ude1 的 底
ude2 地
ude3 得
usuo 所
udeng 等 等等 云云
uyy 一样 一般 似的 般
udh 的话
uls 来讲 来说 而言 说来
uzhi 之
ulian 连 (“连小学生都会”)
动词(1个一类,9个二类)
v 动词
vd 副动词
vn 名动词
vshi 动词“是”
vyou 动词“有”
vf 趋向动词
vx 形式动词
vi 不及物动词(内动词)
vl 动词性惯用语
vg 动词性语素
标点符号(1个一类,16个二类)
w 标点符号
wkz 左括号,全角:( 〔 [ { 《 【 〖 〈 半角:( [ { <
wky 右括号,全角:) 〕 ] } 》 】 〗 〉 半角: ) ] { >
wyz 左引号,全角:“ ‘ 『
wyy 右引号,全角:” ’ 』
wj 句号,全角:。
ww 问号,全角:? 半角:?
wt 叹号,全角:! 半角:!
wd 逗号,全角:, 半角:,
wf 分号,全角:; 半角: ;
wn 顿号,全角:、
wm 冒号,全角:: 半角: :
ws 省略号,全角:…… …
wp 破折号,全角:—— -- ——- 半角:--- ----
wb 百分号千分号,全角:% ‰ 半角:%
wh 单位符号,全角:¥ $ £ ° ℃ 半角:$
字符串(1个一类,2个二类)
x 字符串
xx 非语素字
xu 网址URL
语气词(1个一类)
y 语气词(delete yg)
状态词(1个一类)
z 状态词
北大/北京大学/北大计算所词性标注集
|
标记 |
词性 |
说明 |
举例 |
|
ag |
形语素 |
形容词语素,形容词代码a,语素代码b前置a |
喜/v 煞/ag 人/n |
|
a |
形容词 |
取英文单词adjective首字母 |
最/d 大/a 的/u |
|
ad |
副形词 |
直接作状语的形容词,形容词a和副词d组合 |
一定/d 能够/v 顺利/ad 实现/v 。/w |
|
an |
名形词 |
具有名词功能的形容词,形容词a和名词n组合 |
人民/n 的/u 根本/a 利益/n 和/c 国家/n 的/u 安稳/an 。/w |
|
b |
区别词 |
汉字‘别’的首字母 |
副/b 书记/n 王/nr 思齐/nr |
|
c |
连词 |
conjunction的首字母 |
全军/n和/c武警/n先进/a典型/n代表/n |
|
dg |
副语素 |
副词性语素,副词d语素g组合 |
用/v 不/d 甚/dg 流利/a 的/u中文/nz 主持/v 节目/n 。/w |
|
d |
副词 |
adverb的第二个字母 |
两侧/f 台柱/n 上/分别/d雄踞/v着/u |
|
e |
叹词 |
exclamation首字母 |
嗬/e !/w |
|
f |
方位词 |
汉字‘方’ |
从/p 一/m 大/a 堆/q 档案/n 中/f 发现/v 了/u |
|
g |
语素 |
绝大多数语素都能作为合成词的词根,取汉字‘根’ |
例如dg 或ag |
|
h |
前接成分 |
英语head首字母 |
目前/t 各种/r 非/h 合作制/n 的/u 农产品/n |
|
i |
成语 |
idiom首字母 |
提高/v 农民/n 讨价还价/i 的/u 能力/n 。/w |
|
j |
简称略语 |
‘简’首字母 |
民主/ad 选举/v 村委会/j 的/u 工作/vn |
|
k |
后接成分 |
|
权责/n 明确/a 的/u 逐级/d 授权/v 制/k |
|
l |
习用语 |
习用语尚未成为成语,有点临时性,取‘临’ |
是/v 建立/v 社会主义/n 市场经济/n 体制/n 的/u 重要/a 组成部分/l 。/w |
|
m |
数词 |
numeral第三个字母,nu已被占用 |
科学技术/n 是/v 第一/m 生产力/n |
|
ng |
名语素 |
名词性语素,名词n语素g |
希望/v 双方/n 在/p 市政/n 规划/vn |
|
n |
名词 |
noun首字母 |
就此/d 分析/v 时/Ng 认为/v |
|
nr |
人名 |
名词n ‘人’首字母r组合 |
建设部/nt 部长/n 侯/nr 捷/nr |
|
ns |
地名 |
名词n 处所词s组合 |
北京/ns 经济/n 运行/vn 态势/n 喜人/a |
|
nt |
机构团体 |
名词n ‘团’首字母t |
[冶金/n 工业部/n 洛阳/ns 耐火材料/l 研究院/n]nt |
|
nx |
字母专名 |
名词n 非语素字x |
ATM/nx 交换机/n |
|
nz |
其他名词 |
名词n ‘专’首字母z |
德士古/nz 公司/n |
|
o |
拟声词 |
onomatopoeria首字母 |
汩汩/o 地/u 流/v 出来/v |
|
p |
介词 |
prepositonal首字母 |
往/p 基层/n 跑/v 。/w |
|
q |
量词 |
quantity首字母 |
不止/v 一/m 次/q 地/u 听到/v ,/w |
|
r |
代词 |
pronoun第二个字母,p已被介词占用 |
有些/r 部门/n |
|
s |
处所词 |
space首字母 |
移居/v 海外/s 。/w |
|
tg |
时语素 |
时间词性语素,时间t语素g |
秋/Tg 冬/tg 连/d 旱/a |
|
t |
时间词 |
time首字母 |
当前/t 经济/n 社会/n 情况/n |
|
u |
助词 |
auxiliary首字母 |
工作/vn 的/u 政策/n |
|
ud |
结构助词 |
|
有/v 心/n 栽/v 得/ud 梧桐树/n |
|
ug |
时态助词 |
|
你/r 想/v 过/ug 没有/v |
|
uj |
结构助词的 |
助词u ‘结’首字母j |
迈向/v 充满/v 希望/n 的/uj 新/a 世纪/n |
|
ul |
时态助词了 |
助词u ‘了’首字母l |
完成/v 了/ ul |
|
uv |
结构助词地 |
|
满怀信心/l 地/uv 开创/v 新/a 的/u 业绩/n |
|
uz |
时态助词着 |
助词u ‘着’首字母z |
眼看/v 着/uz |
|
vg |
动语素 |
动词性语素,动词v语素g |
做好/v 尊/vg 干/j 爱/v 兵/n 工作/vn |
|
v |
动词 |
verb首字母 |
举行/v 老/a 干部/n 迎春/vn 团拜会/n |
|
vd |
副动词 |
直接作状语的动词,动词v副词d |
强调/vd 指出/v |
|
vn |
名动词 |
具有名词功能的动词,动词v名词n |
股份制/n 这种/r 企业/n 组织/vn 形式/n ,/w |
|
w |
标点符号 |
|
生产/v 的/u 5G/nx 、/w 8G/nx 型/k 燃气/n 热水器/n |
|
x |
非语素字 |
非语素字只是一个符号,x通常表示未知、符号 |
|
|
y |
语气词 |
‘语’首字母 |
已经/d 30/m 多/m 年/q 了/y 。/w |
|
z |
状态词 |
‘状’首字母 |
势头/n 依然/z 强劲/a ;/w |
生词表:
conjunction英 [kənˈdʒʌŋkʃn] 美 [kənˈdʒʌŋkʃ(ə)n]n. 结合,同时发生;连词;
exclamation英 [ˌekskləˈmeɪʃ(ə)n] 美 [ˌekskləˈmeɪʃn]n. 惊叫,感叹;感叹语,感叹词
onomatopoeia英 [ˌɒnəˌmætəˈpiːə] 美 [ˌɑːnəˌmætəˈpiːə]n. 拟声,象声;声喻法
prepositional英 [ˌprepəˈzɪʃənl] 美 [ˌprepəˈzɪʃənl]adj. 介词的;前置词的
pronoun英 [ˈprəʊnaʊn] 美 [ˈproʊnaʊn]n. 代词
auxiliary英 [ɔːɡˈzɪliəri] 美 [ɔːɡˈzɪliəri]adj. 辅助的;备用的,后备的
idiom英 [ˈɪdiəm] 美 [ˈɪdiəm]n. 习语,成语;方言,土话;
noun英 [naʊn] 美 [naʊn]n. 名词
verb英 [vɜːb] 美 [vɜːrb]n. 动词;动词词性;动词性短语或从句
adverb英 [ˈædvɜːb] 美 [ˈædvɜːrb]n. 副词adj. 副词的
adjective英 [ˈædʒɪktɪv] 美 [ˈædʒɪktɪv]n. 形容词adj. 形容词的;从属的
Torch
|
创建张量 Create Tensor |
a=torch.rand(4,3) 随机张量,每个元素都是0-1之间的随机浮点数 a=torch.zeros(2,4) 零张量,每个元素都是0 a=torch.ones(3,4) 一张量,每个元素都是1 a=torch.empty(5,3) 空张量,每个元素都是混乱值 a=torch.tensor([1.2,2.3]) 中括号初始化张量 a=torch.tensor((22,33)) 小括号初始化张量 a=torch.tensor({100,200}) ✖错误 b=torch.ones_like(a) 相同尺寸的全1矩阵 b=torch.randint_like(a,10,20) 相同尺寸的随机数张量,随机空间10-20 b=torch.randint(100,200,(3,5)) 随机数矩阵 随机空间100-200,矩阵尺寸3*5 |
|
张量运算 |
c=a+b ab必须尺寸相同 c=torch.add(a,b) torch.add(a,b,out=c)abc必须尺寸相同,c是预先定义好的张量 print(a[:,1])张量切片,:表示所有行,1表示第一列 a=torch.rand(3,5) b=a.view(5,3) 改变形状,3行5列变为5行3列,元素顺序不变(行优先) a.item()取出元素只,只能一个元素,否则报错
|
|
张量转换 |
关于Torch Tensor和Numpy array之间的相互转换 Torch Tensor和Numpy array共享底层的内存空间, 因此改变其中一个的值, 另一个也会随之被改变. a=torch.ones(2,3) b=a.numpy() print(type(a)) #<class 'torch.Tensor'> print(type(b)) #<class 'numpy.ndarray'> 其中一个改变,二者同时改变;a+=1 b+=1 a=numpy.ones(5) b=torch.from_numpy(a) print(type(a)) #<class 'numpy.ndarray'> print(type(b)) #<class 'torch.Tensor'>
|
|
自动求导 终止求导 |
requires_grad_(True) x = torch.ones(2, 3, requires_grad=True) out.backward() print(x.grad) y = x.detach() with torch.no_grad(): torch.ones(n, n, requires_grad=True) x.grad_fn a.requires_grad_(True) 学习了关于Gradients的属性:x.grad 可以通过.detach()获得一个新的Tensor, 拥有相同的内容但不需要自动求导. |
什么是停用词Stop Words?
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。但是,并没有一个明确的停用词表能够适用于所有的工具。甚至有一些工具是明确地避免使用停用词来支持短语搜索的。
对于一个给定的目的,任何一类的词语都可以被选作停用词。通常意义上,停用词大致分为两类。一类是人类语言中包含的功能词,这些功能词极其普遍,与其他词相比,功能词没有什么实际含义,比如'the'、'is'、'at'、'which'、'on'等。
在信息检索中,这些功能词的另一个名称是:停用词(stopword)。称它们为停用词是因为在文本处理过程中如果遇到它们,则立即停止处理,将其扔掉。将这些词扔掉减少了索引量,增加了检索效率,并且通常都会提高检索的效果。停用词主要包括英文字符、数字、数学字符、标点符号及使用频率特高的单汉字等。
中文分词技术
|
规则分词 |
正向最大匹配法Maximum Match Method=MM法 逆向最大匹配法Reverse Maximum Match Method=RMM法 双向最大匹配法Bi-direction Match Method=IMM法(正向+ 逆向) |
|
统计分词 |
字与字相邻出现的频率高于某个临界值,就认为可能是一个词; 1建立统计语言模型;2对不同划分方案计算概率,取概率最大的作为结果; HMM 隐含马尔可夫模型,将分词转化为字在字符串中的序列标注任务; 词位:每个字在构造一个特定词语时都占据一个确定的构词位置,称为词位; 词位划分为4个,B词首、M词中、E词尾、S单独成词; CRF条件随机场模型,也是基于马尔可夫思想的统计模型; 神经网络分词算法,是深度学习方法在NLP上的应用; 1通常采用CNN、LSTM等深度学习网络自动发现一些模式和特征; 2然后通过CRF、softmax等分类方法进行分词预测; |
|
混合分词 (规则+统计) |
基于规则的算法、基于概率的算法 、基于DeepLearning的算法,分词效果差距不明显; 通常基于一种分词算法,然后用其他分词算法加以辅助; 最常用:先基于词典分词,然后基于统计分词辅助(例如Jieba分词); |
什么是张量
A tensor is a generalization of vectors and matrices to potentially higher dimensions
张量是向量和矩阵向潜在的更高维度的推广
|
发明与发展 |
根据 维基百科 的介绍,“张量”一词最初由威廉·罗恩·哈密顿在1846年引入。对,就是那个发明四元数的哈密顿; 1890年格雷戈里奥·里奇-库尔巴斯托罗的《绝对微分几何》、1900年列维-奇维塔的《绝对微分》进一步在数学上发展了“张量”的概念。 伟大的物理学家,爱因斯坦为了描述他的天才想法,恶补了黎曼几何和张量分析,终于在这两大数学工具的帮助下,创立了他最为得意的弯曲时空的物理理论:广义相对论。至此张量在物理上大放光彩。如果想学习广义相对论,张量肯定是需要学习的。 |
|
TensorFlow的定义 |
现在机器学习很火,知名开源框架tensor-flow是这么定义tensor(张量)的: A tensor is a generalization of vectors and matrices to potentially higher dimensions 也就是说,张量(tensor)是多维数组,目的是把向量、矩阵推向更高的维度。 |
|
4个定义 |
“张量”在不同的运用场景下有不同的定义。 第一个定义,张量是多维数组,这个定义常见于各种人工智能软件。听起来还好理解。 第二个定义,张量是某种几何对象,不会随着坐标系的改变而改变。 第三个定义,张量是向量和余向量(covector)通过张量积(tensor product)组合而成的。 第四个定义,张量是多重线性映射, |
|
张量本质 |
张量这一概念的核心在于,它是一个数据容器。它包含的数据几乎总是数值数据,因此它是数字的容器。你可能对矩阵很熟悉,它是二维张量。张量是矩阵向任意维度的推广[注意,张量的维度(dimension)通常叫作轴(axis)]。 |
|
标量=0D张量 |
仅包含一个数字的张量叫作标量(scalar,也叫标量张量、零维张量、0D 张量)。在 Numpy中,一个 float32 或 float64 的数字就是一个标量张量(或标量数组)。你可以用 ndim 属性来查看一个 Numpy 张量的轴的个数。标量张量有 0 个轴( ndim == 0 )。张量轴的个数也叫作阶(rank)。下面是一个 Numpy 标量。 |
|
向量=1D张量 |
数字组成的数组叫作向量(vector)或一维张量(1D 张量)。一维张量只有一个轴。下面是一个 Numpy 向量。 |
|
矩阵=2D张量
|
向量组成的数组叫作矩阵(matrix)或二维张量(2D 张量)。矩阵有 2 个轴(通常叫作行和列)。你可以将矩阵直观地理解为数字组成的矩形网格。下面是一个 Numpy 矩阵。 |
|
3D+ 张量 |
将多个矩阵组合成一个新的数组,可以得到一个 3D 张量,你可以将其直观地理解为数字组成的立方体。下面是一个 Numpy 的 3D 张量。 |
|
张量的轴 |
轴的个数(阶)。例如,3D 张量有 3 个轴,矩阵有 2 个轴。这在 Numpy 等 Python 库中也叫张量的 ndim 。 |
|
张量的形状 |
形状。这是一个整数元组,表示张量沿每个轴的维度大小(元素个数)。例如,前面矩阵示例的形状为 (3, 5) ,3D 张量示例的形状为 (3, 3, 5) 。向量的形状只包含一个元素,比如 (5,) ,而标量的形状为空,即 () 。(张量的形状) |
|
张量的数据类型 |
数据类型(在 Python 库中通常叫作 dtype )。这是张量中所包含数据的类型,例如,张量的类型可以是 float32 、 uint8 、 float64 等。在极少数情况下,你可能会遇到字符( char )张量。注意:Numpy(以及大多数其他库)中不存在字符串张量,因为张量存储在预先分配的连续内存段中,而字符串的长度是可变的,无法用这种方式存储。 |
|
现实中的张量 |
向量数据:2D 张量,形状为 (samples, features) 。 时间序列数据或序列数据:3D 张量,形状为 (samples, timesteps, features) 。 图像:4D张量,形状为 (samples, height, width, channels) 或 (samples, channels, height, width) 。 视频:5D张量,形状为 (samples, frames, height, width, channels) 或 (samples,frames, channels, height, width) 。 |
NPL的层次
|
1 |
词法分析 |
分词+词性标注 汉语处理的首要工作就是将输入的文本切分为单独的词语; 词性标注的目的是为每一个词赋予一个类别; |
|
2 |
句法分析 |
以句子为单位,进行分析以得到句子的句法结构; 作用1:帮助理解句子的含义,作用2:为高级处理提供支持; 3种主流句法分析方法:短语结构句法体系、依存结构句法体系、深层文法句法体系; |
|
3 |
语义分析 |
语义分析的最终目的是理解句子表达的真实含义; 语义采用什么表示形式,至今没有统一答案; 语义角色标注semantic role labeling是目前比较成熟的浅层语义分析技术; |
术语
|
分词 segment |
词是最小的能够独立活动的有意义的语言成分; 英语分词以空格作为分界符; 汉语以字为基本的书写单位,词语之间没有明显的区分标记; 中文分词常用手段是基于字典的最长串匹配; 歧义分词是一个难点; |
|
词性标注 part of speech tagging |
基于机器学习的方法里,需要对词性进行标注; 标注的目的是表征词的一种隐藏状态,隐藏状态构成的转移就构成了状态转移序列; |
|
命名实体识别NER named entity recognition |
命名实体指人名、地名、机构名、转悠名词等; |
|
句法分析 syntax parsing |
句法分析是一种基于规则的专家系统; 句法分析的目的是解析句子中各个成分的依赖关系; 句法分析的结果是一颗句法分析树; 句法分析可以解决传统词袋模型不考虑上下文的问题; |
|
指代消解 anaphora resolution |
将代词替换为所指示的实体名; 北京是中国的首都,他历时悠久;将他替换为北京; |
|
情感识别 emotion recognition |
情感识别,本质是分类问题,常应用在舆情分析领域; 情感一般可以分为2类(正面、负面)或者3类(正面、负面、中性); 可以基于词袋模型+ 分类器,或者词向量模型+RNN; |
|
纠错 correction |
可以基于N-Gram进行纠错; 也可以通过字典树、有限状态机等方法进行纠错; |
|
问答系统 QA system |
比较著名的有:苹果Siri、IBM Watson、微软小冰等; 问答系统需要语音识别、合成、自然语言理解、知识图谱等多项技术; |

NLP可以被应用于很多领域:
机器翻译:计算机将一种语言翻译成另一种语言;
情感分析:计算机判定用户评论是否积极;
只能问答:计算机正确回答人类的问题;
文摘生成:计算机准确归纳、总结并产生文本摘要;
文本分类:计算机采集各种文章,进行主题分体系,从而自动分类;
舆论分析:计算机判断当前舆论导向;
知识图谱:知识点相互连接而成的语义网络;
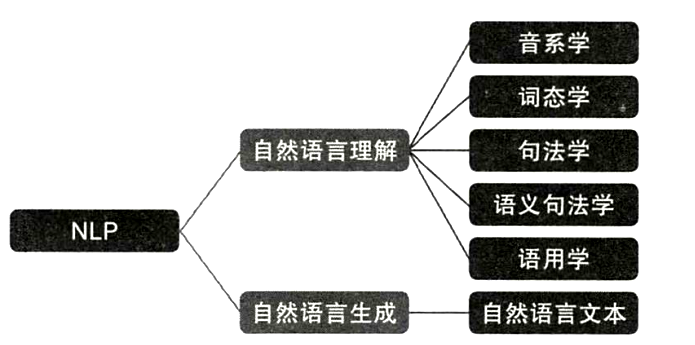
NLP=natural language processing=自然语言处理,是计算机科学领域以及人工智能领域的一个重要的研究方向;
NLP研究用计算机来处理、理解以及运用人类语言(如中文、英文等),达到人与计算机之间进行有效通讯;
所谓“自然”乃是寓意自然进化而成,是为了区分一些人造语言,如C++、Java等人为设计的语言;

文本预处理
|
文本预处理及其作用
|
文本语料在输送给模型前一般需要一系列的预处理工作, 才能符合模型输入的要求, 如:将文本转化成模型需要的张量, 规范张量的尺寸等, 而且科学的文本预处理环节还将有效指导模型超参数的选择, 提升模型的评估指标. |
|
文本预处理中包含的主要环节
|
文本处理的基本方法 文本张量表示方法 文本语料的数据分析 文本特征处理 数据增强方法 |
|
文本处理的基本方法 |
分词 词性标注 命名实体识别 |
|
文本张量表示方法 |
one-hot编码 Word2vec Word Embedding |
|
文本语料的数据分析 |
标签数量分布 句子长度分布 词频统计与关键词词云 |
|
文本特征处理 |
添加n-gram特征 文本长度规范 |
|
数据增强方法 |
回译数据增强法 |
|
什么是分词
|
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符, 分词过程就是找到这样分界符的过程. |
|
分词举例 |
工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作 ==> ['工信处', '女干事', '每月', '经过', '下属', '科室', '都', '要', '亲口', '交代', '24', '口', '交换机', '等', '技术性', '器件', '的', '安装', '工作'] |
|
分词的作用
|
词作为语言语义理解的最小单元, 是人类理解文本语言的基础. 因此也是AI解决NLP领域高阶任务, 如自动问答, 机器翻译, 文本生成的重要基础环节.
|
|
jieba分词 |
愿景: “结巴”中文分词, 做最好的 Python 中文分词组件. |
|
jieba的特性 |
支持多种分词模式:精确模式、全模式、搜索引擎模式 支持中文繁体分词 支持用户自定义词典 |
|
jieba的使用 |
精确模式分词:试图将句子最精确地切开,适合文本分析. jieba.cut(content, cut_all=False) 全模式分词:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能消除 歧义.jieba.cut(content, cut_all=True) 搜索引擎模式分词:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词.jieba.cut_for_search(content) 中文繁体分词:针对中国香港, 台湾地区的繁体文本进行分词. jieba.lcut(content) |
|
自定义词典 |
使用用户自定义词典: 添加自定义词典后, jieba能够准确识别词典中出现的词汇,提升整体的识别准确率. 词典格式: 每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒. 词典样式如下, 具体词性含义请参照附录: jieba词性对照表, 将该词典存为userdict.txt, 方便之后加载使用. 云计算 5 n 李小福 2 nr easy_install 3 eng 好用 300 韩玉赏鉴 3 nz 八一双鹿 3 nz |
|
hanlp |
流行中英文分词工具: 中英文NLP处理工具包, 基于tensorflow2.0, 使用在学术界和行业中推广最先进的深度学习技术. # 使用pip进行安装 pip install hanlp |
|
hanlp使用 |
>>> import hanlp # 加载CTB_CONVSEG预训练模型进行分词任务 >>> tokenizer = hanlp.load('CTB6_CONVSEG') >>> tokenizer("工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作") ['工信处', '女', '干事', '每', '月', '经过', '下', '属', '科室', '都', '要', '亲口', '交代', '24口', '交换机', '等', '技术性', '器件', '的', '安装', '工作'] |
|
命名实体 |
什么是命名实体识别 命名实体: 通常我们将人名, 地名, 机构名等专有名词统称命名实体. 如: 周杰伦, 黑山县, 孔子学院, 24辊方钢矫直机. 顾名思义, 命名实体识别(Named Entity Recognition,简称NER)就是识别出一段文本中可能存在的命名实体. 举个栗子: 鲁迅, 浙江绍兴人, 五四新文化运动的重要参与者, 代表作朝花夕拾.==> 鲁迅(人名) / 浙江绍兴(地名)人 / 五四新文化运动(专有名词) / 重要参与者 / 代表作 / 朝花夕拾 |
|
命名实体识别 |
使用hanlp进行中文命名实体识别: >>> import hanlp # 加载中文命名实体识别的预训练模型MSRA_NER_BERT_BASE_ZH >>> recognizer = hanlp.load(hanlp.pretrained.ner.MSRA_NER_BERT_BASE_ZH) # 这里注意它的输入是对句子进行字符分割的列表, 因此在句子前加入了list() # >>> list('上海华安工业(集团)公司董事长谭旭光和秘书张晚霞来到美 国纽约现代艺术博物馆参观。') # ['上', '海', '华', '安', '工', '业', '(', '集', '团', ')', '公', '司', '董', '事', '长', '谭', '旭', '光', '和', '秘', '书', '张', '晚', '霞', '来', '到', '美', '国', '纽', '约', '现', '代', '艺', '术', '博', '物', '馆', '参', '观', '。'] >>> recognizer(list('上海华安工业(集团)公司董事长谭旭光和秘书张晚霞来到美国纽约现代艺术博物馆参观。')) [('上海华安工业(集团)公司', 'NT', 0, 12), ('谭旭光', 'NR', 15, 18), ('张晚霞', 'NR', 21, 24), ('美国', 'NS', 26, 28), ('纽约现代艺术博物馆', 'NS', 28, 37)] # 返回结果是一个装有n个元组的列表, 每个元组代表一个命名实体, 元组中的每一项分别代表具体的 |
|
词性标注 |
什么是词性标注 词性: 语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果, 常见的词性有14种, 如: 名词, 动词, 形容词等. 顾名思义, 词性标注(Part-Of-Speech tagging, 简称POS)就是标注出一段文本中每个词汇的词性. |
|
词性标注 |
词性标注的作用: 词性标注以分词为基础, 是对文本语言的另一个角度的理解, 因此也常常成为AI解决NLP领域高阶任务的重要基础环节. 使用jieba进行中文词性标注: |
|
jieba词性标注 |
>>> import jieba.posseg as pseg >>> pseg.lcut("我爱北京天安门") [pair('我', 'r'), pair('爱', 'v'), pair('北京', 'ns'), pair('天安门', 'ns')] # 结果返回一个装有pair元组的列表, 每个pair元组中分别是词汇及其对应的词性, 具体词性含义请参照 |
|
hanlp词性标注 |
>>> import hanlp# 加载中文命名实体识别的预训练模型CTB5_POS_RNN_FASTTEXT_ZH>>> tagger = hanlp.load(hanlp.pretrained.pos.CTB5_POS_RNN_FASTTEXT_ZH)# 输入是分词结果列表>>> tagger(['我', '的', '希望', '是', '希望', '和平'])# 结果返回对应的词性['PN', 'DEG', 'NN', 'VC', 'VV', 'NN'] |
什么是文本张量表示
|
文本张量表示 |
将一段文本使用张量进行表示,其中一般将词汇为表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示.
|
|
举例 |
["人生", "该", "如何", "起头"]==> # 每个词对应矩阵中的一个向量 [[1.32, 4,32, 0,32, 5.2], [3.1, 5.43, 0.34, 3.2], [3.21, 5.32, 2, 4.32], [2.54, 7.32, 5.12, 9.54]] |
|
文本张量表示的作用 |
将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,进行接下来一系列的解析工作. |
|
文本张量表示的方法 |
one-hot编码、Word2vec、Word Embedding |
|
one-hot词向量表示
|
又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数. |
|
one-hot举例 |
["改变", "要", "如何", "起手"]` ==> [[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]] |
|
one-hot优劣 |
one-hot编码的优劣势: 优势:操作简单,容易理解. 劣势:完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存. 说明: 正因为one-hot编码明显的劣势,这种编码方式被应用的地方越来越少,取而代之的是接下来我们要学习的稠密向量的表示方法word2vec和word embedding. |
|
word2vec |
什么是word2vec 是一种流行的将词汇表示成向量的无监督训练方法, 该过程将构建神经网络模型, 将网络参数作为词汇的向量表示, 它包含CBOW和skipgram两种训练模式. |
|
CBOW |
CBOW(Continuous bag of words)模式: 给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用上下文词汇预测目标词汇.
图中窗口大小为9, 使用前后4个词汇对目标词汇进行预测. |
|
skipgram |
skipgram模式: 给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用目标词汇预测上下文词汇.
图中窗口大小为9, 使用目标词汇对前后四个词汇进行预测. |
|
fasttext |
使用fasttext工具实现word2vec的训练和使用 第一步: 获取训练数据 第二步: 训练词向量 第三步: 模型超参数设定 第四步: 模型效果检验 第五步: 模型的保存与重加载 |
文本数据分析
|
文本数据分析的作用 |
文本数据分析的作用: 文本数据分析能够有效帮助我们理解数据语料, 快速检查出语料可能存在的问题, 并指导之后模型训练过程中一些超参数的选择. |
|
文本数据分析方法 |
常用的几种文本数据分析方法: 标签数量分布 句子长度分布 词频统计与关键词词云 |
|
文本特征处理的作用 |
文本特征处理的作用: 文本特征处理包括为语料添加具有普适性的文本特征, 如:n-gram特征, 以及对加入特征之后的文本语料进行必要的处理, 如: 长度规范. 这些特征处理工作能够有效的将重要的文本特征加入模型训练中, 增强模型评估指标. |
|
文本特征处理方法 |
常见的文本特征处理方法: 添加n-gram特征 文本长度规范 |
|
n-gram特征 |
什么是n-gram特征 给定一段文本序列, 其中n个词或字的相邻共现特征即n-gram特征, 常用的n-gram特征是bi-gram和tri-gram特征, 分别对应n为2和3. |
|
n-gram举例 |
假设给定分词列表: ["是谁", "敲动", "我心"] 对应的数值映射列表为: [1, 34, 21] 我们可以认为数值映射列表中的每个数字是词汇特征. 除此之外, 我们还可以把"是谁"和"敲动"两个词共同出现且相邻也作为一种特征加入到序列列表中, 假设1000就代表"是谁"和"敲动"共同出现且相邻 此时数值映射列表就变成了包含2-gram特征的特征列表: [1, 34, 21, 1000] 这里的"是谁"和"敲动"共同出现且相邻就是bi-gram特征中的一个. "敲动"和"我心"也是共现且相邻的两个词汇, 因此它们也是bi-gram特征. 假设1001代表"敲动"和"我心"共同出现且相邻 那么, 最后原始的数值映射列表 [1, 34, 21] 添加了bi-gram特征之后就变成了 [1, 34, 21, 1000, 1001] |
|
提取n-gram |
提取n-gram特征: # 一般n-gram中的n取2或者3, 这里取2为例 ngram_range = 2 def create_ngram_set(input_list): """ description: 从数值列表中提取所有的n-gram特征 :param input_list: 输入的数值列表, 可以看作是词汇映射后的列表, 里面每个数字的取值范围为[1, 25000] :return: n-gram特征组成的集合 eg: >>> create_ngram_set([1, 4, 9, 4, 1, 4]) {(4, 9), (4, 1), (1, 4), (9, 4)} """ return set(zip(*[input_list[i:] for i in range(ngram_range)])) 调用:input_list = [1, 3, 2, 1, 5, 3] res = create_ngram_set(input_list) print(res)输出效果:# 该输入列表的所有bi-gram特征 {(3, 2), (1, 3), (2, 1), (1, 5), (5, 3)} |
|
文本长度规范 |
文本长度规范及其作用 · 一般模型的输入需要等尺寸大小的矩阵, 因此在进入模型前需要对每条文本数值映射后的长度进行规范, 此时将根据句子长度分布分析出覆盖绝大多数文本的合理长度, 对超长文本进行截断, 对不足文本进行补齐(一般使用数字0), 这个过程就是文本长度规范.
|
|
|
|
jieba词性对照表:
- a 形容词
- ad 副形词
- ag 形容词性语素
- an 名形词
- b 区别词
- c 连词
- d 副词
- df
- dg 副语素
- e 叹词
- f 方位词
- g 语素
- h 前接成分
- i 成语
- j 简称略称
- k 后接成分
- l 习用语
- m 数词
- mg
- mq 数量词
- n 名词
- ng 名词性语素
- nr 人名
- nrfg
- nrt
- ns 地名
- nt 机构团体名
- nz 其他专名
- o 拟声词
- p 介词
- q 量词
- r 代词
- rg 代词性语素
- rr 人称代词
- rz 指示代词
- s 处所词
- t 时间词
- tg 时语素
- u 助词
- ud 结构助词 得
- ug 时态助词
- uj 结构助词 的
- ul 时态助词 了
- uv 结构助词 地
- uz 时态助词 着
- v 动词
- vd 副动词
- vg 动词性语素
- vi 不及物动词
- vn 名动词
- vq
- x 非语素词
- y 语气词
- z 状态词
- zg
hanlp词性对照表:
【Proper Noun——NR,专有名词】
【Temporal Noun——NT,时间名词】
【Localizer——LC,定位词】如“内”,“左右”
【Pronoun——PN,代词】
【Determiner——DT,限定词】如“这”,“全体”
【Cardinal Number——CD,量词】
【Ordinal Number——OD,次序词】如“第三十一”
【Measure word——M,单位词】如“杯”
【Verb:VA,VC,VE,VV,动词】
【Adverb:AD,副词】如“近”,“极大”
【Preposition:P,介词】如“随着”
【Subordinating conjunctions:CS,从属连词】
【Conjuctions:CC,连词】如“和”
【Particle:DEC,DEG,DEV,DER,AS,SP,ETC,MSP,小品词】如“的话”
【Interjections:IJ,感叹词】如“哈”
【onomatopoeia:ON,拟声词】如“哗啦啦”
【Other Noun-modifier:JJ】如“发稿/JJ 时间/NN”
【Punctuation:PU,标点符号】
【Foreign word:FW,外国词语】如“OK
|
实词 |
名词 |
nouns-n. |
名词是词性的一种,也是实词的一种,是指代人、物、事、时、地、情感、概念等实体或抽象事物的词.名词可以独立成句.在短语或句子中通常可以用代词来替代.名词可以分为专有名词(Proper Nouns)和普通名词 (Common Nouns),专有名词是某个(些)人,地方,机构等专有的名称,如Beijing,China等.普通名词是一类人或东西或是一个抽象概念的名词,如:book,sadness等. |
|
动词 |
verb-v. |
动词是表示动作、行为、心理活动或存在变化等的词。例如: 表示动作行为:走、坐、听、看、批评、宣传、保卫、学习、研究、进行、开始、停止、禁止。 |
|
|
形容词 |
adjective-adj. |
形容词是表示人和事物的形状、性质或表示动作、行为的性质状态的词。例如: 表性质的:好、坏、伟大、勇敢、优秀、聪明、老实、鲁莽、大方、软、硬、苦、甜、冷、热、坚固、平常。 |
|
|
数词 |
numeral-num. |
数词是表示数目和次序的词。表示数目多少的叫基数词。如“一、二、三、四、五、六、七、八、九、十、百、千、万、亿、零”。表示次序先后的叫序数词。如“第一、第二、第三”等等。此外还有倍数、分数、概数。 |
|
|
量词 |
|
量词是表示计算单位的词。可分两类: 名量词表示人和事物的单位,动量词表示动作的量,也有专用和借用两类。专用的如“去一次”“念一遍”“哭—场”“走一趟”的“次、遍、场、趟”。借用的如“砍一刀”,“玩一天”的“眼、刀、天。 |
|
|
代词 |
pronoun-pron. |
代词是代替名词的一种词类.大多数代词具有名词和形容词的功能.英语中的代词,按其意义、特征及在句中的作用分为:人称代词、物主代词、指示代词、反身代词、相互代词、疑问代词、关系代词、连接代词和不定代词九种. |
|
|
虚词 |
副词 |
adverb-adv. |
副词是一种用来修饰动词、形容词、全句的词,说明时间、地点、程度、方式等概念的词.副词是一种半虚半实的词.副词可分为:时间副词、地点副词、方式副词、程度副词、疑问副词、连接副词、关系副词、频率副词和说明性副词等. |
|
介词 |
preposition-prep. |
介词(preposition 简写prep.)又称作前置词,表示名词、代词等与句中其他词的关系,在句中不能单独作句子成分。介词后面一般有名词、代词或相当于名词的其他词类、短语或从句作它的宾语,表示与其他成分的关系。介词和它的宾语构成介词词组,在句中作状语,表语,补语,定语或介词宾语。同时介词的用法也很灵活,同一个介词可以表达多种意义,介词可以分为时间介词、地点介词、方式介词、原因介词、数量介词和其他介词。 |
|
|
连词 |
连词conjunction-conj. |
连词(conj conjunction)是一种虚词, 它不能独立担任句子成分而只起连接词与词,短语与短语以及句与句的作用。连词主要可分为4类:并列连词.转折连词.选择连词和因果连词。连词也可以分为2类:并列连词和从属连词。 |
|
|
助词 |
|
英语助动词是与实义动词也叫行为动词相对而言的。协助主要动词构成谓语动词词组的词叫助动词,被协助的动词称作主要动词。 |
|
|
拟声词 |
|
所有的语言都有一个特殊的现象,那就是拟声词,也叫象声词。比如汉语中的“叮个啷当窿咚呛”,实际上就是英语中的jingle-jangle-cling-clang-clank 的重复。 拟声词作为模仿大自然声音的词汇,如cacklc(咯咯声,咯咯笑),crash(哗啦),clank(当啷),croak(呱呱),dingdong(叮当声),splash(扑通),yelp(汪汪)等,都是英语中使用得非常多的拟声词。这些拟声词表达丰富、形象,极大地增强了英语表现力的多样性和生动性。 |
|
|
感叹词 |
|
表示说话时喜悦、惊讶等感情的词就是感叹词。感叹词有oh,hello,goodbye,耶,啊,哇等。感叹词一般放在句首,后用逗号隔开,感情强烈时,可用感叹号表示。 |
NLP的概念
自然语言处理,英文Natural Language Processing,简写NLP。NLP这个概念本身过于庞大,可以把它分成“自然语言”和“处理”两部分。
|
自然语言 |
先来看自然语言。区分于计算机语言,自然语言是人类发展过程中形成的一种信息交流的方式,包括口语及书面语,反映了人类的思维,都是以自然语言的形式表达。现在世界上所有的语种语言,都属于自然语言,包括汉语、英语、法语等。 |
|
处理 |
然后再来看“处理”。如果只是人工处理的话,那原本就有专门的语言学来研究,也没必要特地强调“自然”。因此,这个“处理”必须是计算机处理的。但计算机毕竟不是人,无法像人一样处理文本,需要有自己的处理方式。因此自然语言处理,简单来说即是计算机接受用户自然语言形式的输入,并在内部通过人类所定义的算法进行加工、计算等系列操作,以模拟人类对自然语言的理解,并返回用户所期望的结果。 |
正如机械解放人类的双手一样,自然语言处理的目的在于用计算机代替人工来处理大规模的自然语言信息。它是人工智能、计算机科学、信息工程的交叉领域,涉及统计学、语言学等的知识。由于语言是人类思维的证明,故自然语言处理是人工智能的最高境界,被誉为“人工智能皇冠上的明珠”。
NPL发展历程
|
NLP 规则时代 |
1948年,香农提出信息熵的概念。此时尚未有NLP,但由于熵也是NLP的基石之一,在此也算作是NLP的发展历程。 按照维基百科的说法,NLP发源于1950年。图灵于该年提出“图灵测试”,用以检验计算机是否真正拥有智能。 1950-1970年,模拟人类学习语言的习惯,以语法规则为主流。除了参照乔姆斯基文法规则定义的上下文无关文法规则外,NLP领域几乎毫无建树。 |
|
NLP统计时代
|
20世纪70年代开始统计学派盛行,NLP转向统计方法,此时的核心是以具有马尔科夫性质的模型(包括语言模型,隐马尔可夫模型等)。 2001年,神经语言模型,将神经网络和语言模型相结合,应该是历史上第一次用神经网络得到词嵌入矩阵,是后来所有神经网络词嵌入技术的实践基础。也证明了神经网络建模语言模型的可能性。 2001年,条件随机场CRF,从提出开始就一直是序列标注问题的利器,即便是深度学习的现在也常加在神经网络的上面,用以修正输出序列。 2003年,LDA模型提出,概率图模型大放异彩,NLP从此进入“主题”时代。Topic模型变种极多,参数模型LDA,非参数模型HDP,有监督的LabelLDA,PLDA等。 2008年,分布式假设理论提出,为词嵌入技术的理论基础。 在统计时代,NLP专注于数据本身的分布,如何从文本的分布中设计更多更好的特征模式是这时期的主流。在这期间,还有其他许多经典的NLP传统算法诞生,包括tfidf、BM25、PageRank、LSI、向量空间与余弦距离等。值得一提的是,在20世纪80、90年代,卷积神经网络、循环神经网络等就已经被提出,但受限于计算能力,NLP的神经网络方向不适于部署训练,多停留于理论阶段。 |
|
NLP深度时代
|
2013年,word2vec提出,NLP的里程碑式技术。 2013年,CNNs/RNNs/Recursive NN,随着算力的发展,神经网络可以越做越深,之前受限的神经网络不再停留在理论阶段。在图像领域证明过实力后,Text CNN问世;同时,RNNs也开始崛起。在如今的NLP技术上,一般都能看见CNN/LSTM的影子。 本世纪算力的提升,使神经网络的计算不再受限。有了深度神经网络,加上嵌入技术,人们发现虽然神经网络是个黑盒子,但能省去好多设计特征的精力。至此,NLP深度学习时代开启。 2014年,seq2seq提出,在机器翻译领域,神经网络碾压基于统计的SMT模型。 2015年,attention提出,可以说是NLP另一里程碑式的存在。带attention的seq2seq,碾压上一年的原始seq2seq。记得好像17年年初看过一张图,调侃当时学术界都是attention的现象,也证明了attention神一般的效果。 2017年末,Transformer提出。似乎是为了应对Facebook纯用CNN来做seq2seq的“挑衅”,google就纯用attention,并发表著名的《Attention is All You Need》。初看时以为其工程意义大于学术意义,直到BERT的提出才知道自己还是too young。 2018年末,BERT提出,横扫11项NLP任务,奠定了预训练模型方法的地位,NLP又一里程碑诞生。光就SQuAD2.0上前6名都用了BERT技术就知道BERT的可怕。 深度学习时代,神经网络能够自动从数据中挖掘特征,人们从复杂的特征中脱离出来,得以更专注于模型算法本身的创新以及理论的突破。并且深度学习从一开始的机器翻译领域逐渐扩散到NLP其他领域,传统的经典算法地位大不如前。但神经网络似乎一直是个黑箱,可解释性一直是个痛点,且由于其复杂度更高,在工业界经典算法似乎还是占据主流。 |
基本分类
NLP里细分领域和技术实在太多,根据NLP的终极目标,大致可以分为自然语言理解(NLU)和自然语言生成(NLG)两种。
NLU侧重于如何理解文本,包括文本分类、命名实体识别、指代消歧、句法分析、机器阅读理解等。
NLG则侧重于理解文本后如何生成自然文本,包括自动摘要、机器翻译、问答系统、对话机器人等。两者间不存在有明显的界限,如机器阅读理解实际属于问答系统的一个子领域。
大致来说,NLP可以分为以下几个领域:
|
文本检索 |
多用于大规模数据的检索,典型的应用有搜索引擎。 |
|
信息抽取 |
从不规则文本中抽取想要的信息,包括命名实体识别、关系抽取、事件抽取等。应用极广。 |
|
序列标注 |
给文本中的每一个字/词打上相应的标签。是大多数NLP底层技术的核心,如分词、词性标注、关键词抽取、命名实体识别、语义角色标注等等。曾是HMM、CRF的天下,近年来逐步稳定为BiLSTM-CRF体系。 |
|
文本摘要 |
从给定的文本中,聚焦到最核心的部分,自动生成摘要。 |
|
机器翻译 |
跨语种翻译,该领域目前已较为成熟。目前谷歌翻译已用上机翻技术。 |
|
文本分类/情感分析
|
本质上就是个分类问题。目前也较为成熟,难点在于多标签分类(即一个文本对应多个标签,把这些标签全部找到)以及细粒度分类(二极情感分类精度很高,即好中差三类,而五级情感分类精度仍然较低,即好、较好、中、较差、差) |
|
问答系统 |
接受用户以自然语言表达的问题,并返回以自然语言表达的回答。常见形式为检索式、抽取式和生成式三种。近年来交互式也逐渐受到关注。典型应用有智能客服 |
|
对话系统 |
与问答系统有许多相通之处,区别在于问答系统旨在直接给出精准回答,回答是否口语化不在主要考虑范围内;而对话系统旨在以口语化的自然语言对话的方式解决用户问题。对话系统目前分闲聊式和任务导向型。前者主要应用有siri、小冰等;后者主要应用有车载聊天机器人。(对话系统和问答系统应该是最接近NLP终极目标的领域) |
|
知识图谱 |
从规则或不规则的文本中提取结构化的信息,并以可视化的形式将实体间以何种方式联系表现出来。图谱本身不具有应用意义,建立在图谱基础上的知识检索、知识推理、知识发现才是知识图谱的研究方向。 |
|
文本聚类 |
一个古老的领域,但现在仍未研究透彻。从大规模文本数据中自动发现规律。核心在于如何表示文本以及如何度量文本之间的距离。 |
基本技术
|
分词 |
基本算是所有NLP任务中最底层的技术。不论解决什么问题,分词永远是第一步。 |
|
词性标注 |
判断文本中的词的词性(名词、动词、形容词等等),一般作为额外特征使用。 |
|
句法分析 |
分为句法结构分析和依存句法分析两种。 |
|
词干提取 |
从单词各种前缀后缀变化、时态变化等变化中还原词干,常见于英文文本处理。 |
|
命名实体识别 |
识别并抽取文本中的实体,一般采用BIO形式。 |
|
指代消歧 |
文本中的代词,如“他”“这个”等,还原成其所指实体。 |
|
关键词抽取 |
提取文本中的关键词,用以表征文本或下游应用。 |
|
词向量与词嵌入 |
把单词映射到低维空间中,并保持单词间相互关系不变。是NLP深度学习技术的基础。 |
|
文本生成 |
给定特定的文本输入,生成所需要的文本,主要应用于文本摘要、对话系统、机器翻译、问答系统等领域。 |
常用算法
tfidf、BM25、TextRank、HMM、CRF、LSI、主题模型、word2vec、GloVe、LSTM/GRU、CNN、seq2seq、Attention……
终极目标
从计算机诞生,NLP这个概念被提出伊始,人们便希望计算机能够理解人类的语言,于是便有了图灵测试。
尽管google I/O大会上的Google Assistant宣称已经通过了图灵测试,但离真正理解人类语言仍有很长的距离,让计算机能够确切理解人类的语言,并自然地与人进行交互是NLP的最终目标,也是大多数NLPer的最高信仰。为此各路大佬挥舞手中的代码不断挖坑填坑,攻克一个又一个难题,推动NLP一直往前发展。
研究难点
仍有很多制约NLP发展的因素,这些因素构成了NLP的难点。而且要命的是,大多数是基础技术的难点。
|
中文分词 |
中文分词,这条是专门针对中文说的。众所周知汉语博大精深,老外学汉语尚且虐心,更别提计算机了。同一个任务,同一个模型在英文语料的表现上一般要比中文语料好。无论是基于统计的还是基于深度学习的NLP方法,分词都是第一步。分词表现不好的话,后面的模型最多也只能尽力纠偏
|
|
词义消歧 |
词义消歧:很多单词不只有一个意思,但这个在今年BERT推出后应该不成问题,可以通过上下文学到不同的意思。另一个较难的是 |
|
指代消歧 |
指代消歧,即句子中的指代词还原,如“小明受到了老师的表扬,他很高兴”,这个“他”是指“小明”还是指“老师”。 |
|
二义性 |
有些句子,往往有多种理解方式,其中以两种理解方式的最为常见,称二义性。 |
|
OOV问题 |
随着词嵌入技术大热后,使用预训练的词向量似乎成为了一个主流。但有个问题就是,数据中的词很可能不在预训练好的词表里面,此即OOV(out of vocabulary)。主流方法是要么当做UNK处理,要么生成随机向量或零向量处理,当然都存在一定的弊端。 |
|
文本生成的评价指标 |
文本生成的评价指标多用BLEU或者ROUGE,但尴尬的是,这两个指标都是基于n-gram的,也就是说会判断生成的句子与标签句子词粒度上的相似度。然而由于自然语言的特性(同一个意思可以有多种不同的表达),会出现生成的句子尽管被人为判定有意义,在BLEU或ROUGE上仍可能会得到很低的分数的情况。这两个指标用在机翻领域倒是没多大问题(本身就是机翻的评价指标),但用在文本摘要和对话生成就明显不合适了。 |
|
文本相似度计算 |
是的你没有看错。文本相似度计算依旧算是难点之一。不过与其说难点,主要是至今没有一种方法能够从理论证明。主流认可的是用余弦相似度。但看论文就会发现,除了余弦相似度外,有人用欧式距离,有人用曼哈顿距离,有人直接向量內积,且效果还都不错。 |
社会影响
由于自然语言作为人类社会信息的载体,使得NLP不只是计算机科学的专属。在其他领域,同样存在着海量的文本,NLP也成为了重要支持技术:
在社会科学领域,关系网络挖掘、社交媒体计算、人文计算等,国内一些著名的大学实验室,如清华的自然语言处理与社会人文计算实验室、哈工大的社会计算与信息检索研究中心均冠有社会计算的关键词。
在金融领域,单A股就有3000多家上市公司,这些公司每年都有年报、半年报、一季报、三季报等等,加上瞬息万变的金融新闻,金融界的文本数量是海量的。金融领域的NLP公司举例:李纪为大佬的香侬科技。
在法律领域,中国裁判文书网上就有几千万公开的裁判文书,此外还有丰富的流程数据、文献数据、法律条文等,且文本相对规范。该领域已经有不少公司在做,如涂存超大佬的幂律智能;
在医疗健康领域,除了影像信息,还有大量的体检数据、临床数据、诊断报告等,同样也是NLP大展身手的地方。该领域的NLP公司:碳云智能。
在教育领域,智能阅卷、机器阅读理解等都可以运用NLP技术。国内这方面目前领先者应该是科大讯飞和猿辅导。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号