

Python学习笔记2
Python学习笔记2(未完待续)
|
# 解决plt中文乱码问题-方法1 # plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体 # plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题
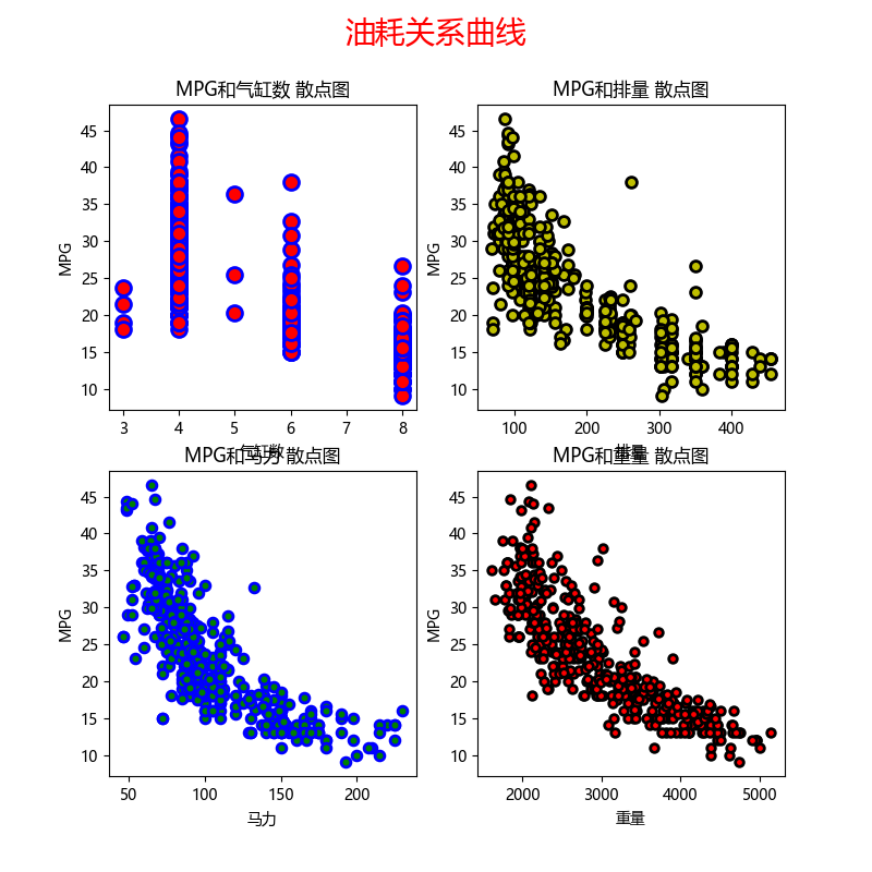
#创建一个有4个子图表的图表,2行2列 # 接收数据格式要写成2*2的矩阵形式 #2 2表示图表行数和列数 #figsize表示图表尺寸 #fig用于接收整个图表 #ax1用于接收第1行第1列的子图表 #ax2用于接收第1行第2列的子图表 #ax3用于接收第2行第1列的子图表 #ax4用于接收第2行第2列的子图表 fig, [[ax1, ax2], [ax3, ax4]] = plt.subplots(2, 2, figsize=(8, 8)) #设置图标的居中标题,字号fontsize为20,颜色c为红色 fig.suptitle('油耗关系曲线',fontsize=20,c='red') #绘制第1个子图表 #scatter表示绘制散点图 #X数据为dataset中的名称为Cylinders的列数据 #Y数据为dataset中名称为MPG的列数据 #c表示散点的颜色为red #edgecolors表示散点的边缘颜色 #s表示散点的大小size #linewidth表示边缘的线宽 ax1.scatter(dataset['Cylinders'], dataset['MPG'], c='red', edgecolors='blue', s=100, linewidth=2) #设置子图表1的标题 ax1.set_title('MPG和气缸数 散点图') #设置子图表1的x轴标签/名称 ax1.set_xlabel('气缸数') #设置子图表1的y轴标签/名称 ax1.set_ylabel('MPG') #绘制第2个子图表 ax2.scatter(dataset['Displacement'], dataset['MPG'], c='y', edgecolors='k', s=50, linewidth=2) ax2.set_title('MPG和排量 散点图') ax2.set_xlabel('排量') ax2.set_ylabel('MPG') #绘制第3个子图表 ax3.scatter(dataset['Horsepower'], dataset['MPG'], c='g', edgecolors='b', s=40, linewidth=2) ax3.set_title('MPG和马力 散点图') ax3.set_xlabel('马力') ax3.set_ylabel('MPG') #绘制第4个子图表 ax4.scatter(dataset['Weight'], dataset['MPG'], c='r', edgecolors='k', s=30, linewidth=2) ax4.set_title('MPG和重量 散点图') ax4.set_xlabel('重量') ax4.set_ylabel('MPG') #显示图表 plt.show() |
PyCharm最高效的快捷键集合
|
1.注释/取消注释
|
Ctrl + /:快速注释(选中多行后可以批量注释) 注释后,再次按Ctrl + /取消注释 |
|
2.缩进/取消缩进
|
Tab:缩进当前行(选中多行后可以批量缩进) Shift + Tab:取消缩进(选中多行后可以批量取消缩进) |
|
10.快速排版 |
快捷键:CTRL + Alt + L |
|
4.复制当前行 |
快捷键:Ctrl + D |
|
8.删除选定的行 |
快速删除选定的行,不用再一格一格回退了 快捷键:Ctrl + Y |
|
9.智能提示
|
快捷键:Alt + Enter 智能提示当前光标处可以进行的操作,快速给出语法提示。
|
|
5.快速查看文档
|
快速查看方法、库等文档说明 快捷键:Ctrl+Q
|
|
6.简介及代码定义
|
快速查看源码 快捷键:Ctrl + 左键
|
|
7.快速查找
|
快捷键:双击shift 万能搜索,不管是IDE功能、文件、方法、变量等都能搜索。 |
|
|
|
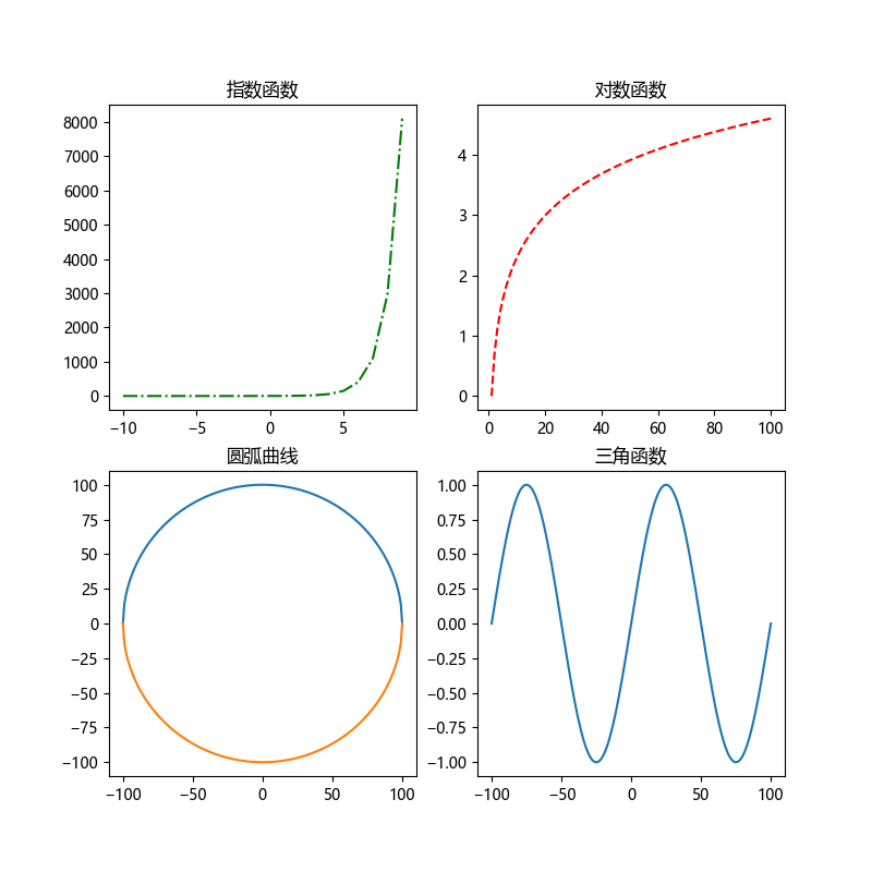
import matplotlib.pyplot as plt import numpy as np
X =range(-100, 101) print(type(X)) Y1 = [np.e ** x for x in X] Y2 = [np.log(max(1,x)) for x in X] Y3=[np.sqrt(10000-x**2) for x in X] Y4=[-1*y for y in Y3] Y5=[np.sin(x/100*2*np.pi ) for x in X] #plt.title('一图多表 示例') fig,[[ax1,ax2],[ax3,ax4]]=plt.subplots(2,2,figsize=(8,8)) ax1.plot(X[90:110],Y1[90:110]) ax1.set_title('指数函数')
print(type(ax1)) ax2.plot(X[101:],Y2[101:]) ax2.set_title('对数函数')
ax3.plot(X,Y3) ax3.plot(X,Y4) ax3.set_title('圆弧曲线')
ax4.plot(X,Y5) ax4.set_title('三角函数')
plt.show() |
matplotlib绘制图形
|
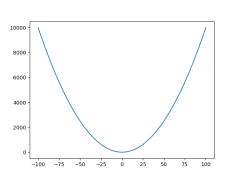
import numpy import matplotlib.pyplot as plt #绘制二次曲线y=x^2 x=range(-100,101)#创建x值 y=[xx**2 for xx in x]#计算对应的y值 plt.plot(x,y)#绘制曲线 plt.savefig('plot1.jpg')#曲线保存为图片 plt.show()#显示曲线 |
|
|
import numpy import matplotlib.pyplot as plt #绘制正弦曲线,余弦曲线 X=numpy.linspace(0,2*numpy.pi,100)#起始点,结束点,等分的份数 Y1=numpy.sin(X) #计算正弦值 Y2=numpy.cos(X)#计算余弦值 plt.plot(X,Y1)#绘制正弦曲线 plt.plot(X,Y2)#绘制余弦曲线 plt.show()#显示曲线 |
|
|
import matplotlib.pyplot as plt import random
count=1024 #生成X数据 X=[random.random()*100 for i in range(count)] #生成Y数据 Y=[random.random()*100 for i in range(count)] plt.scatter(X,Y)#绘制散点图 plt.show()#显示散点图 |
|
|
import matplotlib.pyplot as plt #绘制柱状图 #设置X值 X=[2015,2016,2017,2018,2019,2020] #设置Y值 Y=[10,30,50,40,60,30] #绘制柱状图 plt.bar(X,Y,width=0.8) #显示柱状图 plt.show() |
|
|
import numpy import matplotlib.pyplot as plt #绘制直方图和盒状图 #随机产生100个正态分布数 data=numpy.random.randn(100) #行数、列数,尺寸 fig,(ax1,ax2)=plt.subplots(nrows=1,ncols=2,figsize=(8,4)) ax1.hist(data,100)#绘制直方图 ax2.boxplot(data)#绘制盒状图 plt.show()#显示 |
|
|
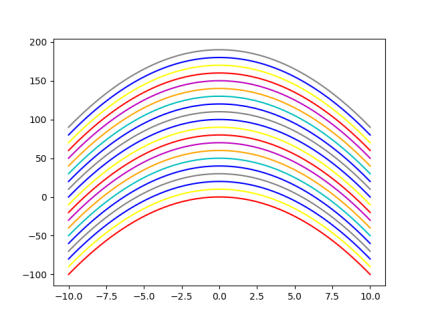
import numpy as np import random import matplotlib.pyplot as plt
X=np.linspace(start=-10,stop=10,num=100)#X值 #颜色 colors=['red','yellow','blue','gray','b','c','orange','m'] for i in range(20):#绘制
plt.plot(X,-X**2+i*10,color=colors[i%len(colors)]) plt.show()#显示 r——red |
 |
|
根据姓名判定男女的简单算法 通过字在男生姓名和女生姓名中出现的频次,进行统计过,男+1女-1 最后根据频次计算某个名字的得分,>0为男,否则为女 姓氏不参与性别判定,认为姓氏是中性的
path=r'C:\Users\Administrator\Desktop\name.txt' f=open(path,mode='r',encoding='utf-8') lines=f.readlines() dic=dict() for line in lines: name,sex= line.split('\t') name=name[1:] for zi in name: if zi in dic:#字典中已经存在该键 if '男' in sex: dic[zi]+=1 else : dic[zi] -= 1 else:#字典不存在该键 if '男' in sex: dic[zi] = 1 else: dic[zi] = -1
print(len(dic))
test_path=r'C:\Users\Administrator\Desktop\testname.txt' ff=open(test_path,mode='r',encoding='utf-8') test=ff.readlines() print(len(test)) for name in test: name=name.replace('\n','') if len(name)==3: name2=name[1:] elif len(name)==4: name2=name[2:]
score=0 for zi in name2: if zi in dic: score+=dic[zi] sex='男' if score>0 else '女' print(f'name= {name} ,sex= {sex},score= {score}\n')
name= 龚尧莞 ,sex= 女,score= -25
name= 齐新燕 ,sex= 女,score= -121
name= 车少飞 ,sex= 男,score= 1038
name= 龙家铸 ,sex= 男,score= 1770
name= 赖鸿华 ,sex= 男,score= 2228
name= 龙宣霖 ,sex= 男,score= 805
name= 连丽英 ,sex= 女,score= -1120
name= 齐晓巍 ,sex= 男,score= 351
name= 连俊勤 ,sex= 男,score= 2408
name= 齐明星 ,sex= 男,score= 2784
name= 黄相杰 ,sex= 男,score= 2019
name= 龚小虎 ,sex= 男,score= 499
name= 连传杰 ,sex= 男,score= 2273
name= 宇文献花 ,sex= 女,score= -83
name= 龙川凤 ,sex= 男,score= 60
name= 黄益泉 ,sex= 男,score= 434
name= 黄益波 ,sex= 男,score= 705
name= 米培燕 ,sex= 女,score= -366
name= 连保健 ,sex= 男,score= 652
name= 齐旺梅 ,sex= 女,score= -205
进程已结束,退出代码0
|
符号和容器
|
小括号 |
( ) |
元组 |
tuple |
|
中括号 |
[ ] |
列表 |
list |
|
大括号 |
{ } |
集合 |
set |
|
大括号 |
{ : } |
字典 |
dict |
|
单引号 |
' ' |
单行字符串 |
str |
|
双引号 |
" " |
单行字符串 |
str |
|
单引号*3 |
''' ''' |
多行字符串 |
str |
|
双引号*3 |
""" """ |
多行字符串 |
str |
Python容器总结2
|
容器*5 |
列表[ ] |
元组( ) |
字符串’ ’“ ” |
集合{ } |
字典{ : } |
|
元素类型 |
* |
* |
字符 |
* |
*:* |
|
下标索引 |
✔ |
✔ |
✔ |
✖ |
✖ |
|
重复元素 |
✔ |
✔ |
✔ |
✖ |
✖ |
|
有序 |
✔ |
✔ |
✔ |
✖ |
✖ |
|
可修改 |
✔ |
✖ |
✖ |
✔ |
✔ |
|
0 |
x=[] #list 列表 x=list() |
x=() #tuple 元组 x=tuple() |
x=str() x='' x="" |
x=set() |
x={}#dict字典 x=dict() |
|
1 |
x=[1] |
x=(1,) |
|
x={1} |
x={1:2} |
|
++ |
my_list=[1,2,3]
|
my_tuple=(1,2,3)
|
|
my_set={1,2,3}
|
my_dic={'n':22,'a':18} |
|
混合 |
a=['hello',False,488] |
a=('hello',False,488) |
|
a={'hello',False,488} |
a={'hello':123,False:"混合",488:'world'} |
模块搜索目录
- 当前目录(执行的py文件所在目录);
- 环境变量PYTHONPATH下的所有目录;
- Python的默认安装目录;
添加目录
|
1 |
sys.path.append(‘path’) |
只在当前文件的窗口中有效,窗口关闭后失效; |
|
2 |
Python安装目录下Lib\site-packages创建.pth文件,文件中添加目录即可(推荐) |
要重新打开执行导入的文件,方可生效; 只在当前版本的Python中有效; |
|
3 |
PYTHONPATH中添加指定目录,用;分隔 |
在不同版本的Python中共享; |

Python的类
|
创建类 |
class Dog: |
|
构造函数 |
def __init__(self,name='汪汪',color='黑'): |
|
字段/成员变量 |
__name ='' __color ='' 私有字段,默认为空 |
|
属性/访问字段 |
def set_name(self, name):self.__name = name def get_name(self):return self.__name def set_color(self ,color):self.__color =color def get_color(self):return self.__color |
|
成员函数 |
def say(self): print(f"我的名字叫 {self.__name}") print(f"我是一条 {self.__color} 色的狗") |
|
访问权限 |
用下划线的个数表示字段或方法的访问权限; _*0表示公开权限_*1表示保护权限_*2表示私有权限 __init__前后各2个下划线,表示系统函数,也叫魔法函数; |
|
实例化 |
dog1 =Dog() dog2 =Dog('二蛋' ,'白') |
|
访问属性 访问成员变量 |
print(dog2.get_name()) print(dog2.get_color()) |
|
访问成员函数 |
dog2.say() |
函数参数类型
|
|
名称 |
含义 |
e.g. |
|
1 |
位置参数 |
参数位置、个数、顺序必须一致 |
show("Tom",22,'London') |
|
2 |
关键字参数 |
参数顺序任意 |
show(age=33,name='Kara',add='Newyork') |
|
3 |
变长参数 |
参数个数任意,类型任意 *参数为任意类型 **参数必须为键值对类型 |
def show2(*args) show2('Jim',88,True,[1,2,3]) def show(**args) show(name='Tom',age=99,add='Heilongjiang') |
|
4 |
缺省参数 |
有默认值的参数,必须放在最后面 |
def show(name,age,add='Nanchang') |
Python容器总结
|
容器*5 |
列表 |
元组 |
字符串 |
集合 |
字典 |
|
元素类型 |
* |
* |
字符 |
* |
Key*:Value* |
|
下标索引 |
✔ |
✔ |
✔ |
✖ |
✖ |
|
重复元素 |
✔ |
✔ |
✔ |
✖ |
✖ |
|
有序 |
✔ |
✔ |
✔ |
✖ |
✖ |
|
可修改 |
✔ |
✖ |
✖ |
✔ |
✔ |
|
0 |
x=[] #list 列表 x=list() |
x=() #tuple 元组 x=tuple() |
x=str() x='' x="" |
x=set() |
x={}#dict字典 x=dict() |
|
1 |
x=[1] |
x=(1,) |
|
x={1} |
x={1:2} |
|
++ |
my_list=[1,2,3]
|
my_tuple=(1,2,3)
|
|
my_set={1,2,3}
|
my_dic={'n':22,'a':18} |
|
函数 |
index/len/append/insert/ extend/clear/remove/ pop/count/reverse/sort/copy/[index] |
count/index/[index] |
[]+* [:] in not in r f ''' ''' count/encode/decode/min-max/ lower-upper/split-replace/join/rfind-find-index |
add/clear/copy/difference/intersection/union/ update/discard/remove/pop/ |
clear/copy/[key] /get /setdefault/keys/ values/items/pop/popitem/update/fromkeys |
小知识
打印Python歌,在解释器窗口中输入import this,运行即可打印出Python歌;
打印所有Python关键字,import keyword print(keyword.kwlist)
大小写问题
|
Python大小写 |
标识符是大小写敏感的,是区分大小写的 |
|
变量名 |
统一用小写(编码规范)count=0 |
|
常量名 |
统一用大写(编码规范)PI=3.14 |
|
函数名 |
小写加下划线 company_name,white_dog 小驼峰(除第一个单词外,其余单词首字母均大写)companyName,whiteDog |
|
类名 |
大驼峰(每个单词首字母都大写)CompanyName,WhiteDog |
符号
|
; |
不需要用;表示语句结束,回车换行即可表示语句的结束; |
|
{} |
不需要使用{}表示代码块,用相同缩进表示属于同一个代码块; |
|
# |
单行注释 |
|
''' ''' """ """ |
3个单引号或者双引号 表示多行注释 |
|
'' "" |
单引号等价于双引号, 表示字符串 |
|
r |
原生字符串(禁止转义)raw,s=r'hello \n world' |
变量
|
声明 |
变量无需声明,而直接赋值使用;a=1 print(a)✔ |
|
使用 |
只声明而不赋值的变量,相当于没有;a print(a)✖ |
|
连续赋值 |
a=b=c=1 |
|
分别赋值 |
a,b,c=1,2,3 |
|
常量 |
PI=3.14,常量全大写,其实PI仍然是变量,可以随便赋值,Python中没有真正的常量 |
|
类型转换 |
s=’123’ a=int(s) s=’tom’if s.isdigit() a=int(s) |
|
|
|
运算符
|
**幂运算 |
a=2**3 print(a) 8 |
|
/浮点除法 |
print(3/2) →1.5 print(19/10) →1.9 |
|
//整除 |
print(3//2) →1 只取商的整数部分 print(19//10) →1 |
|
商和余数 |
a=divmod(10,3) print(a) →(3, 1) |
|
!=不等于 |
print(3!=2)✔ →True |
|
<>不等于 |
print(3<>2)✖ →invalid syntax语法错误 |
|
|
|
|
True/False |
True就是1,Flase就是0 print(True==1) →True print(False==0) →True |
|
连续比较 |
相当于两个比较,再与,print(3>2>1)等价于3>2&&2>1 →True print((3>2)>1) →False print((3>2)>0) →True |
|
**= |
a=2 a**=3 (a=a**3,a=2**3,2的3次幂,a=8 ) |
|
/= |
a=3 a/=2 (a=a/2 ,a=3/2,a=1.5) |
|
//= |
a=3 a//=2 (a=a//2 ,a=3//2,a=1) |
|
&& || ! |
Python不支持✖ |
|
++ -- |
Python不支持✖ |
|
and or not |
逻辑与、逻辑或、逻辑非 |
|
in not in |
成员运算符,表示某个元素是否属于集合,或者集合是否包含该元素 arr=[1,2,3,4,5] print(2 in arr) →True print(8 in arr) →False |
|
三元? : |
Python不支持✖ c=a>b?a:b |
|
三元= if else |
c=a if a>b else b |
|
is is not |
身份运算符 引用同一个对象就相同,否则不同 |
|
== |
数值相等就相同,否则不同 |
|
id() |
相当于取地址,a=2 id(a) b=’hello’ id(b) print(id(1)) →3189075149040 print(id('hello')) →3189110885360 |
数据类型
|
整数 |
0x十六进制数 0xabff,0o八进制 0o4567, |
|
浮点数 |
1.23e9 (1.23*10^9) 0.000012 1.2e-5 |
|
复数 |
a+bj complex(a,b) |
|
转换 |
int(x) float(x) complex(x)虚部为0 complex(x,y) |
|
布尔 |
True False 首字母大写;bool(8) →True bool({})→False bool(-1)→ True bool('false')→True bool(-0.00000)→False bool(0.00000001)→True bool(None )→False bool(not None )→True |
|
[]列表 |
定义['1',2,'hello'] # 列表 遍历(元素)for i in ['1',2,'hello']: print(i) 遍历(下标→元素)for i in range(len(a)) print(a[i]) 删除lis=['a','b','c'] del lis[0] lis →['b', 'c'] 弹出lis.pop() →'c' lis →['b'] 合并[1,2,3]+[2,3,4] →[1, 2, 3, 2, 3, 4] 重复[1,2,3]*3 →[1, 2, 3, 1, 2, 3, 1, 2, 3] 最值a=[1,2,3,4,5] max(a)→5 min(a)→1 len(a)→5 反序a.reverse() a→[5, 4, 3, 2, 1] 升序a.sort() a→[1, 2, 3, 4, 5] 连续切片a[0:4] →[1, 2, 3, 4] 前闭后开相当于>=0 且 <4, a[0] a[1] a[2] a[3] 步距切片a[0:4:2]→[1, 3] 范围0-3步长2,a[0] 0+2=2 a[2] |
|
()元组 |
('1',2,'hello') # 元组 不可变序列,相当于内容不可修改 不可变更的列表 元组只保证一级元素不可变,无法保证二级子元素不可变 tup = ('a', 'b', ['A', 'B']) tup[2][0] = 'a' |
|
{}集合 |
{'1',2,'hello'} # 集合 {'name':'juran','age':18} |
|
字典 |
hash散列算法 实现的, 采用 键值对(key:value) 的形式,它是无序的, 包含的元素个数不限, 值的类型也可以是其它任何数据类型! 字典的key必须是不可变的对象, 例如 整数 、 字符串 、 bytes 和 元组 , 但使用最多的还是字符串。 列表、 字典、 集合等就不可以作为key。 同时, 同一个字典内的key必须是唯一的, 但值则不必。 创建test = {} # 创建空字典 test = {"a":'123','b':'2',"c":3} dict([('name', 'juran'), ('age', 18), ('addr', 'cs')]) {'name': 'juran', 'age': 18, 'addr': 'cs'} dict(a=1, b=2, jack=4098) {'a':1,'b':2} dic={'name':'Tom','age':18} 访问dic['name']→'Tom' dic['age']→18 添加dic['address']='NanChang' 修改 dic['name']='Json' 删除del dic['name'] 访问dic.get('age') dic.get('sex')访问不存在的键不会报错dic['sex']访问不存在的键会报错 dic.items()所有键值对 dic.keys()所有键 dic.values()所有值 遍历键for key in dic: print(key,dic[key]) 遍历键和值for a,b in dic.items(): print(a,b) a是key,b是value for k in dic.keys() for v in dic.values
|
|
bytes |
bytes处理以字节为单位;字符串的处理以字符为单位; b=b'' b=bytes() b=bytes('hello world','utf8') s=b.decode() s.encode () s=b'hello world'.decode()字节串解密成字符串 b='hello world'.encode()字符串加密成字节串 |
|
set |
set集合 是一个 无序不重复 元素的集, 基本功能包括关系测试和消除重复元素。 集合使用大括号 ({}) 框定元素, 并以 逗号 进行分隔。 但是注意: 如果要创建一个空集合, 必须用 set() 而不是 {} , 因为后者创建的是一个 空字典 。 集合数据类型的核心在于 自动去重 空集合s=set() s=set({1,2,2,3,3,5,5,6,7,}) s{1, 2, 3, 5, 6, 7} 自动去重 s=set([1,1,2,2,3,3,4,5,5]) s{1, 2, 3, 4, 5} 自动去重 s=set('hello world')s{' ', 'd', 'w', 'l', 'h', 'o', 'r', 'e'} 拆成字符,并自动去重 添加s.add(4) 合并s.update([3,4,5,6]) s.pop()删除第一个 s.remove(5)删除指定元素 x & y # 交集 x | y # 并集 x - y # 差集
|
Python代码在执行过程中, 遵循下面的基本原则:
- 普通语句, 直接执行;
- 碰到函数, 将函数体载入内存, 并不直接执行
- 碰到类, 执行类内部的普通语句, 但是类的方法只载入, 不执行
- 碰到if、 for等控制语句, 按相应控制流程执行
- 碰到@, break, continue等, 按规定语法执行
- 碰到函数、 方法调用等, 转而执行函数内部代码, 执行完毕继续执行原有顺序代码
流程控制
|
switch-case |
Python不支持✖ |
|
if |
if elif else三个关键词 条件不用放入小括号; 以冒号作为语句结束标志; 以缩进区分所属语句块; |
|
do while |
Python不支持✖ |
|
for while |
i=1 s=0 while i<=10 : s+=i i+=1 print(s) for i in arr: break直接退出循环,本循环后面的代码不再执行,剩余的循环也不再执行; continue,跳过本次循环,本次循环后面的代码不再执行,开始下一次循环; |
函数
|
range |
for i in range(5): print(i)相当于[0,5]前闭后开 for i in range(1, 12, 2):print(i) for i in range(len(a)):print(i, a[i])
|
|
lambda |
匿名函数lambda x: x * x 等价于 def f(x):return x*x
|
|
推导式 |
列表推导式是一种快速生成列表的方式。 其形式是用方括号括起来的一段语句 列表推导式lis = [x * x for x in range(1, 10)] 字典推导式dic = {i:i**3 for i in range(5)} 集合推导式s = {i for i in 'abasrdfsdfa' if i not in 'abc'}
|
|
迭代器 |
在Python中, list/tuple/string/dict/set/bytes 都是可以迭代的数据类型。 可以通过collections模块的 Iterable 类型来判断一个对象是否可迭代 from collections.abc import Iterable b=isinstance('abc', Iterable) print(b) ”from collections import interable“,在3.6版本之前collections后面是不需要带.abc的,3.7之后就会提醒需要加.abc,现在3.10版本停止使用不加.abc的情况。 s='hello world' it=iter(s) next(it) lis = [1,2,3,4] it = iter(lis) # 创建迭代器对象 for x in it: # 使用for循环遍历迭代对象 print (x, end=" ")
|
|
生成器 |
一边循环一边计算出元素的机制, 称为生成器: generator。 g = (x * x for x in range(1, 4)) next(g)
|
|
装饰器 |
装饰器( Decorator) : 从字面上理解, 就是装饰对象的器件。 可以在不修改原有代码的情况下, 为被装饰的对象增加新的功能或者附加限制条件或者帮助输出。 @dec def func():pass |
|
内置函数 |
all()接收一个可迭代对象, 如果对象里的所有元素的bool运算值都是True, 那么返回True, 否则False any()接收一个可迭代对象, 如果迭代对象里有一个元素的bool运算值是True, 那么返回True, 否则False。 globals() dir(__builtins__) bin()、 oct()、 hex()三个函数是将十进制数分别转换为2/8/16进制 bool()测试一个对象或表达式的执行结果是True还是False。 bytes()将对象转换成字节类型。 str()将对象转换成字符串类型, 同样也可以指定编码方式。 str()将对象转换成字符串类型, 同样也可以指定编码方式。 ord()与chr()相反, 返回某个ASCII字符对应的十进制数 chr(55)'7' ord('a')97 compile()将字符串编译成Python能识别或执行的代码。 s = "print('helloworld')" r = compile(s,"<string>","exec") exec(r) # 执行的话需要用exec complex()通过数字或字符串生成复数类型对象。 dir()显示对象所有的属性和方法。 divmod()除法, 同时返回商和余数的元组。 globals()列出当前环境下所有的全局变量。 注意要与global关键字区分! hash()为不可变对象, 例如字符串生成哈希值的函数! hash('nihao')-1572772467903848751 hash('good')4260910284722868626 id()返回对象的内存地址,常用来查看变量引用的变化, 对象是否相同等。 iter()制造一个迭代器, 使其具备next()能力。 filter()过滤器, 用法和map类似。 在函数中设定过滤的条件, 逐一循环对象中的元素, 将返回值为True时的元素留下( 注意, 不是留下返回值! ) , 形成一个filter类型的迭代器。 zip()组合对象。 将对象逐一配对。 list_1 = [1,2,3]list_2 = ['a','b','c']s = zip(list_1,list_2) print(list(s))运行结果:[(1, 'a'), (2, 'b'), (3, 'c')] 那么如果对象的长度不一致呢? 多余的会被抛弃! 以最短的为基础!
|
文件读写
|
打开 读取 写入 关闭
while
with
改名 删除 创建
|
f = open(filename, mode) f = open('gbk.txt', 'r', encoding='gbk') f.read() path=r'C:\Users\Administrator\Desktop\111.txt' f=open(path,'r',encoding='gbk')s=f.read()print(s) f.readline()'日照香炉生紫烟,\n' f.readline()'遥看瀑布挂前川。\n' f.readlines()将文件中所有的行, 一行一行全部读入一个列表内, 按顺序一个一个作为列表的元素, 并返回这个列表 f.write()将字符串或bytes类型的数据写入文件内。 write()动作可以多次重复进行, 其实都是在内存中的操作, 并不会立刻写回硬盘, 直到执行close()方法后, 才会将所有的写入操作反映到硬盘上 # 打开一个文件f = open("foo.txt", "w")f.write("人生苦短我用Python!\n") # 关闭打开的文件f.close() 大文件读写: while True:content = filename.read(1024) 每次读取1024个字节 if len(content)==0: 如果读取内容长度等于0, 意味着文件读取完毕break 文件的定位读写- f.seek() f.tell()返回文件读写指针当前所处的位置,它是从文件开头开始算起的字节数。 一定要注意了, 是字节数, 不是字符数。 with open('test.txt', 'w') as f: 修改文件名称import os os.rename(filename,newfilename) 删除文件os.remove(filename) 创建文件夹os.mkdir(dirname) 获取当前目录os.getcwd() 改变默认路径os.chdir("../") 删除文件夹os.rmdir(dirname) 列出当前目录下的文件os.listdir()
|
面向对象
|
定义 |
class 类名(父类列表):pass |
|
变量 |
可以通过类名或者实例名加圆点的方式访问类变量, 比如: Student.room Student.address li.room zhang.address 在使用实例变量和类变量的时候一定要注意, 使用类似zhang.name访问变量的时候, 实例会先在自己的实例变量列表里查找是否有这个实例变量, 如果没有, 那么它就会去类变量列表里找, 如果还没有, 弹出异常。 |
|
方法 |
实例方法 def print_age(self): #调用方法li.print_age() 静态方法@staticmethoddef static_method():pass #调用方法Foo.static_method() 类方法:建议只使用类名.类方法的调用方式。 @classmethod def class_method(cls):pass #调用方法Foo.class_method() |
|
封装 继承 多态 |
类通过将函数和变量封装在内部, 实现了比函数更高一级的封装 ;
# 父类定义class people:# 单继承示例class student(people): Python3的继承机制 子类在调用某个方法或变量的时候, 首先在自己内部查找, 如果没有找到, 则开始根据继承机制在父类里查找。 调用父类方法super(B, self).__init__(name=name)
多态def show_kind(animal):animal.kind() 狗、 猫、 猪 都继承了动物类, 并各自重写了 kind 方法。 show_kind() 函数接收一个 animal 参数, 并调用它的 kind 方法。 可以看出, 无论我们给 animal 传递的是 狗、 猫还是猪 , 都能正确的调用相应的方法, 打印对应的信息。 这就是多态。 |
|
访问权限 |
Python不支持private关键字;✖ 两个下划线 __ 表示私有;
类的成员与下划线总结: _name 、 _name_ 、 _name__ :建议性的私有成员, 不要在外部访问。 __name 、 __name_ :强制的私有成员, 但是你依然可以蛮横地在外部危险访问。 __name__ :特殊成员, 与私有性质无关, 例如 __doc__ 。 name_ 、 name__ :没有任何特殊性, 普通的标识符, 但最好不要这么起名。✖ |
|
魔法 |
Python中有大量类似 __doc__ 这种以双下划线开头和结尾的特殊成员及“魔法方法” , 它们有着非常重要的 __init__() 实例化方法, 通过类创建实例时, 自动触发执行。 __module__ 表示当前操作的对象在属于哪个模块。 __del__() 析构方法, 当对象在内存中被释放时, 自动触发此方法。 __call__() 如果为一个类编写了该方法, 那么在该类的实例后面加括号, 可会调用这个方法。 __str__() 如果一个类中定义了 __str__() 方法, 那么在打印对象时, 默认输出该方法的返回值。 这也是一个非常重要 __getitem__() 、 __setitem__() 、 __delitem__()取值、 赋值、 删除这“三剑客” a = 标识符[] : 执行__getitem__方法 __iter__() 这是迭代器方法! 列表、 字典、 元组之所以可以进行for循环, 是因为其内部定义了 __iter__() 这个方法。 __slots__ Python作为一种动态语言, 可以在类定义完成和实例化后, 给类或者对象继续添加随意个数或者任意类型的变量
|
|
|
使用占位符格式化字符串:
使用占位符格式化输出时:在%后面加数字表示给这个字符多少个位置,不足电脑会自动使用空格补齐。正数表示左对齐,负数表示右对齐。如:%4d表示左对齐一共占4的位置,%-8d表示右对齐一共占8个位置
占位符:
%s :字符串的格式化,也是最常用的
%d :格式化整数,也比较常用
%c :格式化字符及ASCII码
%f :格式化浮点数,可以指定小数后面的精度,默认是小数点6位
%o :格式化无符号八进制数
%x :格式化无符号十六进制数
%e : 将整数、浮点数转换成科学计数法
%%: 当字符串中存在格式化标志时,需要用 %%表示一个百分号;
————————————————
|
a=input('first number=') a=int(a) b=input('second number=') b=int(b) s=a+b print('sum= '+str(s)) |
a=input('first number=') a=int(a) b=input('second number=') b=int(b) s=a+b s=str(s) print('sum= '+s) |
|
arr='#!/usr/bin/python'.split('/') print(arr) ['#!', 'usr', 'bin', 'python'] |
first number=100 second number=200 sum= 300 |
|
def print_hi(name): # 在下面的代码行中使用断点来调试脚本。 print(f'Hi, {name}') # 按 Ctrl+F8 切换断点。
def sum2(a, b): return a + b |
def sum2(a, b): return a + b # 定义一个函数 单行注释,需要在语句后面隔两个空格,写#,然后再隔一个空格,写注释; |
|
''' if __name__ == '__main__': print_hi('PyCharm') print(sum2(1, 2)) print('hello world') s = sum2(2, 3) print(s) print('C:\\doc\\') print(random.randint(1 , 10)) '''
多行注释用3个单引号或者双引号 """
|
a=input('input a integer number=') a=int(a) if(a>0):print('this is a positive number') else: if(a<0):print('this is a negative number') else:print('this is a zero number')
a = input('input a integer number=') a = int(a) if a > 0: print('this is a positive number') elif a < 0: print('this is a negative number') else: print('this is a zero number') |
|
s1 = 'hello' s2 = 'world' s = s1 + ' ' + s2 + ' !' print(s)
name = 'Tom' age = 18 print('my name is %s , i am %d years old' % (name,age)) print('my name is {name} , i am {age} years old'.format(name=name,age=age)) |
字符串拼接
|
import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律