

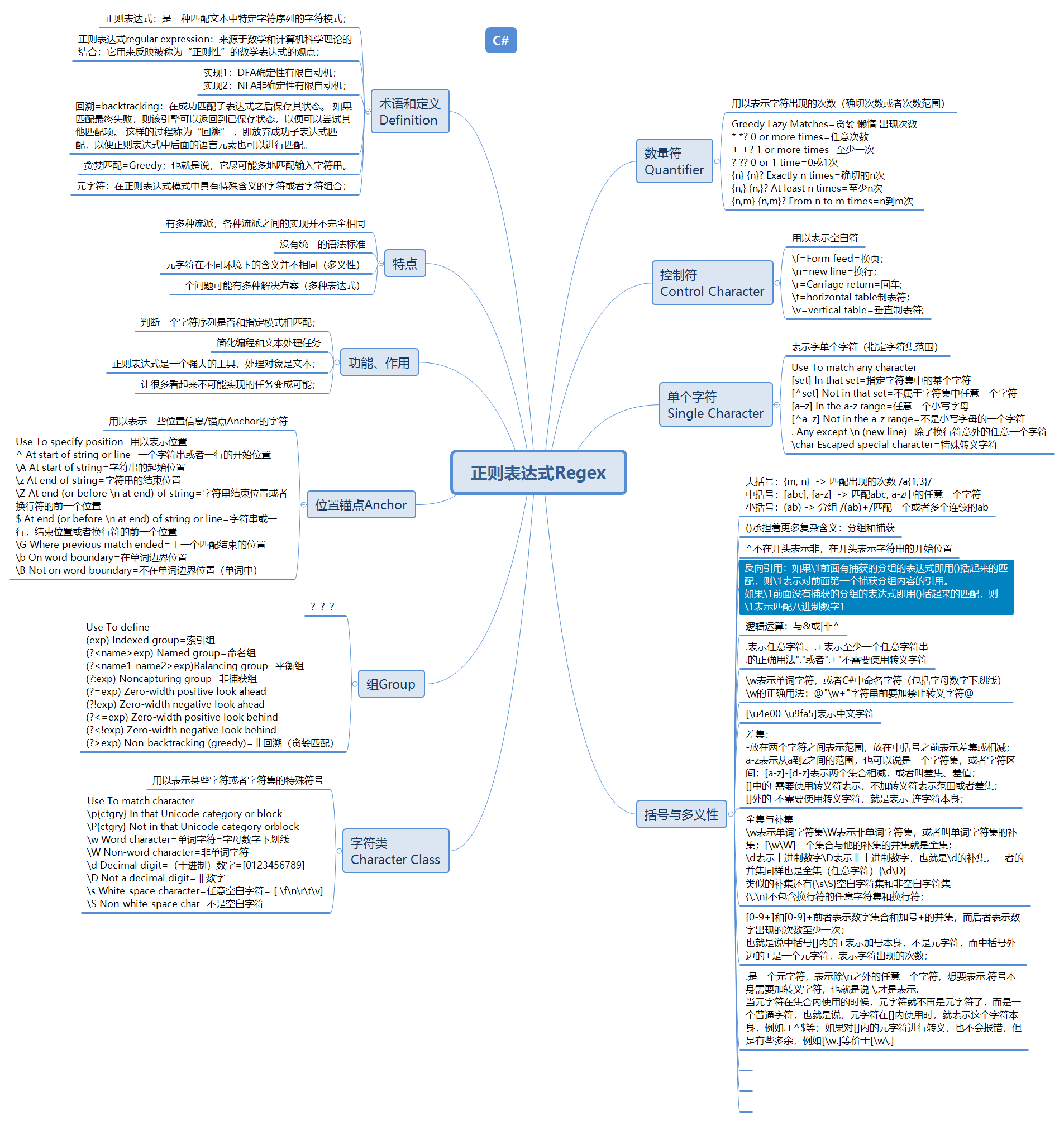
正则表达式=Regex=regular expression
正则表达式=Regex=regular expression
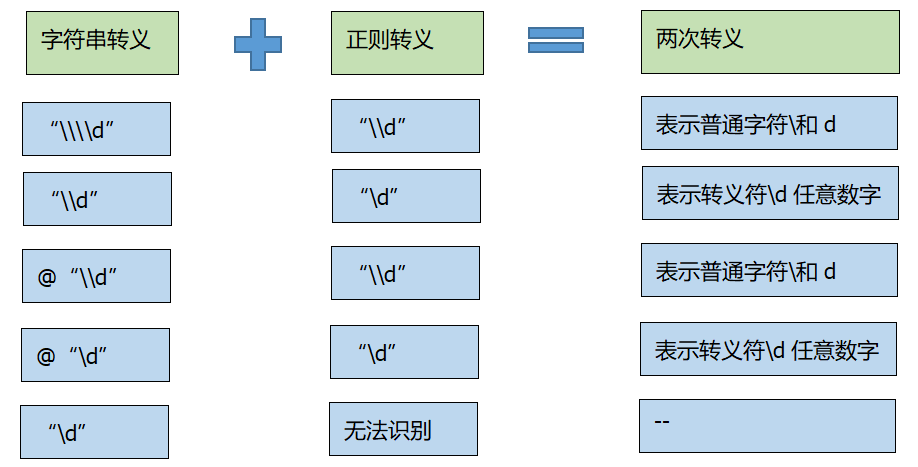
反向引用*2
|
\index索引引用 |
\b(\w+)\b\s+\1\b |
|
\k<name>命名引用 |
\b(?<name>\w+)\b\s+\k<name>\b |
数量符/限定符*6*2
|
贪婪Greedy |
懒惰Lazy(加一个?) |
含义 |
|
? |
?? |
0或1次 |
|
* |
*? |
至少0次 |
|
+ |
+? |
至少1次 |
|
{m} |
{m}? |
必须m次 |
|
{m,} |
{m,}? |
至少m次 |
|
{m,n} |
{m,n}? |
至少m次,至多n次 |
空白符\s*5
|
\f |
Form feed=换页 |
|
\n |
new line=换行 |
|
\r |
Carriage return=回车 |
|
\t |
horizontal table=水平制表符 |
|
\v |
vertical table=垂直制表符 |
转义符*22
|
表示位置的转义符*8
|
^$\b\B\A\z\Z\G ^表示行首位置$表示行尾位置 \b表示单词边界位置\B非单词边界位置 \A字符串开始位置\z字符串结束位置 \Z字符串结束位置或\n前一个位置 \G上一个匹配结束位置 |
|
表示字符集的转义符*7 |
.\w\W\d\D\s\S .表示除了\n之外的所有字符 \w表示字母数字下划线和汉字\W表示取反或者补集 \d表示0-9的任意一个数字\D表示取反或者补集 \s表示空白符集合\S表示取反或者补集 |
|
表示其他含义的转义符*7 |
|(){} |表示逻辑或运算 ()表示提高运算优先级、或者表示提取组、或者表示子表达式 []表示字符集 |
[]内的元字符都表示元字符本身所表示的符号,也就是说[]会使元字符失效;[?$^*+]
然而在[]外使用这些元字符本身所表示的字符,则必须加转义字符;\?\*\+\^
\s=space=空白符;\w=word=单词符(字母+数字+下划线)
\d=decimal digit=十进制数字=0123456789
\s=[\f\n\r\t\v]=[换页、换行、回车、水平制表符、垂直制表符]
\S=[^\f\n\r\t\v]=[^换页、换行、回车、水平制表符、垂直制表符]
\f=Form feed=换页;\n=new line=换行;\r=Carriage return=回车;
\t=horizontal table水平制表符;\v=vertical table=垂直制表符;
\w=[A-Za-z0-9_]=[ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789_]
\W=[^A-Za-z0-9_]=[^ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789_]
\d=[0-9]=[0123456789],\D=[^0-9]=[^0123456789]
apple a[\w]+\b IsMatch=True Match=apple
orange a[\w]+\b IsMatch=True Match=ange
apple \ba[\w]+\b IsMatch=True Match=apple
orange \ba[\w]+\b IsMatch=False Match=
a[\w]+\b
解释: a开头,后面接一个或者多个单词符\w(字母、数字、下划线)然后到单词边界\b
\ba[\w]+\b
解释: 从单词边界开始,第一个字母是a开头,后面接一个或者多个单词符\w(字母、数字、下划线)然后到单词边界\b;总的来说就是a开头的单词
注意:正则表达式前要加禁止转义字符@,也就是string regex=@"\ba[\w]+\b";
$%^&*()+= .+ IsMatch=True Match=$%^&*()+=
解释:
a开头 .+ IsMatch=True Match=解释:
.表示任意字符\n换行符除外,.+表示至少一个任意字符
对于 "解释: \na开头" .+只能匹配到\n之前的内容;
guangjia@mail.com [\w]+@([\w]+.)+[\w]+ IsMatch=True Match=guangjia@mail.com
XXX@abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijk.com [\w]+@([\w]+.)+[\w]+ IsMatch=True Match=XXX@abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijk.com
p = @"[\w]+@([\w]+.)+[\w]+";为邮箱正则表达式
解释:[\w]表示单个字符(数字、字母或者下划线),[\w]+可以理解为一个单词
([\w]+.)表示单词加.的组合,()叫做组Group,组后面的+表示该组出现一次或多次;例如sina.com.cn,其中的sina.和com.都是和([\w]+.)匹配match的
总的来说,邮箱格式就是 邮箱名 +@+ 若干个(单词.) + 单词
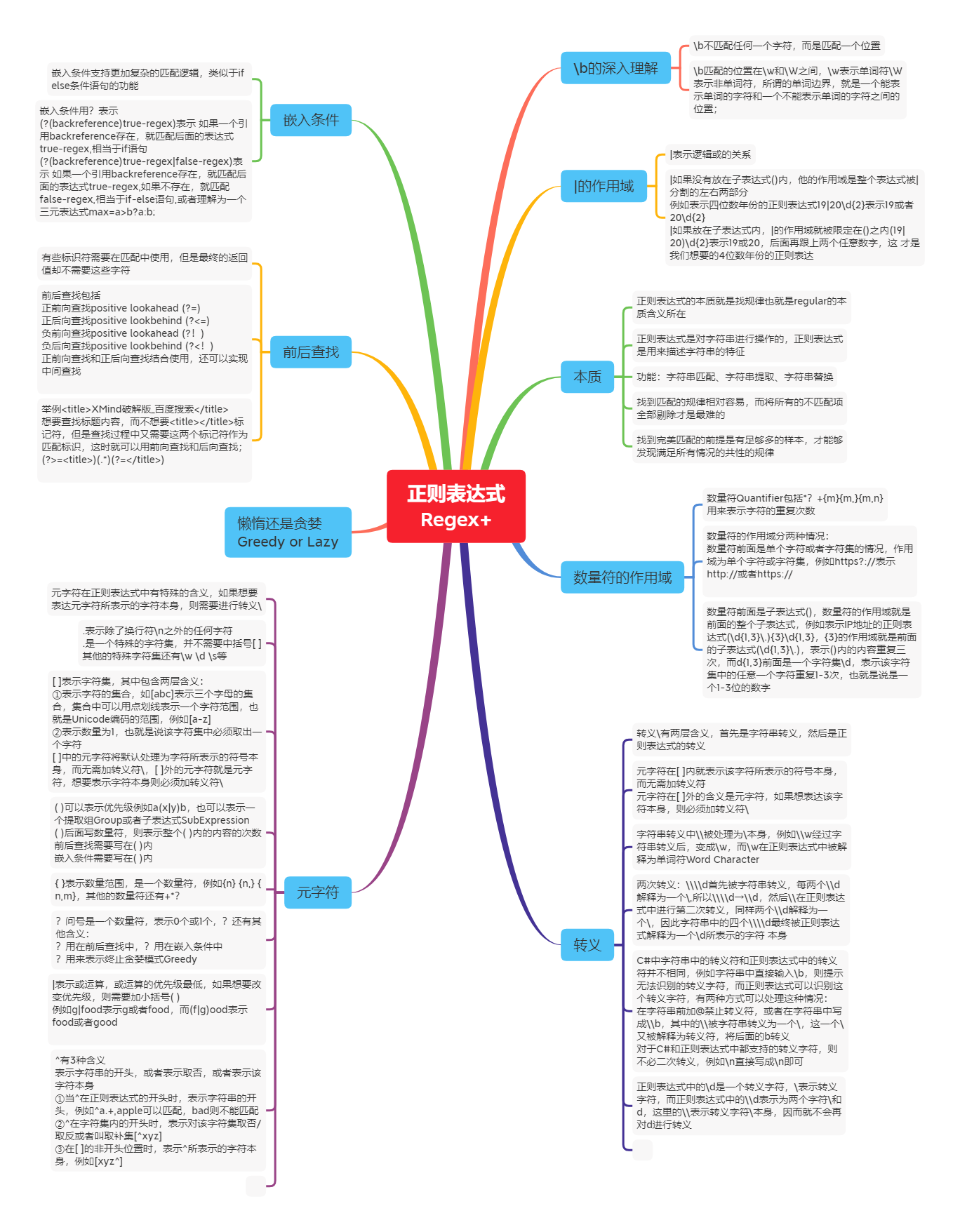
重复单词的检测
i want an an apple ([\w]+) \1 IsMatch=True Match=an an
dog dog ([\w]+) \1 IsMatch=True Match=dog dog
解释: ([\w]+)表示一个单词,\1表示对这个单词的引用,也叫反向引用;就是说前面出现apple,后面的\1也必须是apple,才能match匹配
\1表示对之前的第一个小括号组的引用
white cat white cat ([\w]+) ([\w]+) \1 \2 IsMatch=True Match=white cat white cat
解释:\1 \2分别表示对前面的第一个小括号组的引用,和对第二个小括号组的引用,引用的意思就是内容必须相同,第一个小括号是red \1也必须是red 第二个小括号是green\2也必须是green,两个引用同时匹配的才能match
hot hot dog dog ([\w]+) \1 ([\w]+) \2 IsMatch=True Match=hot hot dog dog
www.9377.com www.([\w]+.)+[a-z]+ IsMatch=True Match=www.9377.com
解释:www网址匹配,以www.开头,后跟若干个(单词.)最后再跟一个单词(例如顶级域名com cn等等)
https://partners.adobe.com/ http[s]?://([\w]+.)+[a-z]+ IsMatch=True Match=https://partners.adobe.com
解释:htttp网址,以http://或者https://开头,?表示[s]出现的次数为0或1,后面的匹配项与www网址类似,不再赘述;
A Chinese defense spokesperson on Thursday responded to provocative acts of Australian and Canadian military aircraft, and warned that those who come uninvited will bear the consequences.
\b[aA][\w]* IsMatch=True Match=A,acts,Australian,and,aircraft,and,
解释:a或A开头的所有单词,\b表示单词的边界,也就是开头,[aA]表示a或者A,默认出现一次;[\w]* 表示单词的后续部分,可以有0个或多个任意单词符;
A Chinese defense spokesperson on Thursday responded to provocative acts of Australian and Canadian military aircraft, and warned that those who come uninvited will bear the consequences.
[\w]+a[\w]+ IsMatch=True Match=Thursday,provocative,Australian,Canadian,military,aircraft,warned,that,bear,
解释:中间(不在开头或结尾)有a的单词,第一个[\w]+表示a前面至少有一个单词符,第二个[\w]+表示a后面至少有一个单词符,这样就保证a不会位于单词边界了;
A Chinese defense spokesperson on Thursday responded to provocative acts of Australian and Canadian military aircraft, and warned that those who come uninvited will bear the consequences.
\b[a-z-[a-h]][\w]* IsMatch=True Match=spokesperson,on,responded,to,provocative,of,military,warned,that,those,who,uninvited,will,the,
解释:[a-z]表示a-z之间任意一个小写字母[a-h]表示a-h之间的任意一个小写字母,[a-z-[a-h]]表示[a-z]减去[a-h],也就是差集的意思;
匹配年份
1998\10\20 \d?\d?\d\d[\\.\-/]\d?\d[\\.\-/]\d?\d IsMatch=True Match=1998\10\20
22-12-31 \d?\d?\d\d[\\.\-/]\d?\d[\\.\-/]\d?\d IsMatch=True Match=22-12-31
p = @"\d?\d?\d\d[\\.\-/]\d?\d[\\.\-/]\d?\d";//日期:年月日
解析:\\表示反斜杠、\-表示连字符,这里虽然放置了禁止转义符@,里面仍要加转义字符\,否则转义字符识别失败;
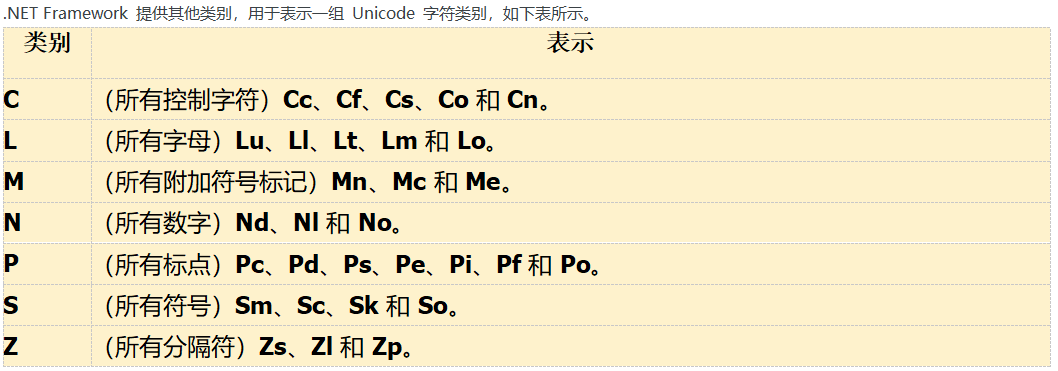
|
|
成员名称 |
说明 |
|
Lu |
UppercaseLetter |
指示字符是大写字母。 |
|
Ll |
LowercaseLetter |
指示字符是小写字母。 |
|
Lt |
TitlecaseLetter |
指示字符是词首字母大写字母。 |
|
Lm |
ModifierLetter |
指示字符是修饰符字母,它是独立式的间距字符,指示前面字母的修改。 |
|
Lo |
OtherLetter |
指示字符是字母,但它不是大写字母、小写字母、词首字母大写或修饰符字母。 |
|
Mn |
NonSpacingMark |
指示字符是非间距字符,这指示基字符的修改。 |
|
Mc |
SpacingCombiningMark |
指示字符是间距字符,这指示基字符的修改并影响该基字符的标志符号的宽度。 |
|
Me |
EnclosingMark |
指示字符是封闭符号,封闭符号是非间距组合字符,它环绕直到基字符(并包括基字符)的所有前面的字符。 |
|
Nd |
DecimalDigitNumber |
指示字符是十进制数字,即在范围 0 到 9 内。 |
|
Nl |
LetterNumber |
指示字符是由字母表示的数字,而不是十进制数字,例如,罗马数字 5 由字母“V”表示。 |
|
No |
OtherNumber |
指示字符是数字,但它既不是十进制数字也不是字母数字,例如分数 1/2。 |
|
Zs |
SpaceSeparator |
指示字符是空白字符,它不具有标志符号,但不是控制或格式字符。 |
|
Zl |
LineSeparator |
指示字符用于分隔文本各行。 |
|
Zp |
ParagraphSeparator |
指示字符用于分隔段落。 |
|
Cc |
Control |
指示字符是控制代码,其 Unicode 值是 U+007F,或者位于 U+0000 到 U+001F 或 U+0080 到 U+009F 范围内。 |
|
Cf |
Format |
指示字符是格式字符,格式字符是通常不呈现的字符,但它影响文本布局或文本处理操作。 |
|
Cs |
Surrogate |
指示字符是高代理项还是低代理项。代理项代码值在范围 U+D800 到 U+DFFF 内。 |
|
Co |
PrivateUse |
指示字符是专用字符,其 Unicode 值在范围 U+E000 到 U+F8FF 内。 |
|
Pc |
ConnectorPunctuation |
指示字符是连接两个字符的连接符标点。 Punctuation英 /ˌpʌŋktʃuˈeɪʃn/ 美 /ˌpʌŋktʃuˈeɪʃn/ n. 标点符号 |
|
Pd |
DashPunctuation |
指示字符是短划线或连字符。 |
|
Ps |
OpenPunctuation |
指示字符是成对的标点符号(例如括号、方括号和大括号)之一的开始字符。 |
|
Pe |
ClosePunctuation |
指示字符是成对的标点符号(例如括号、方括号和大括号)之一的封闭字符。 |
|
Pi |
InitialQuotePunctuation |
指示字符是开始或前引号。 |
|
Pf |
FinalQuotePunctuation |
指示字符是封闭或后引号。 |
|
Po |
OtherPunctuation |
指示字符是标点,但它不是连接符标点、短划线标点、开始标点、结束标点、前引号标点或后引号标点。 |
|
Sm |
MathSymbol |
指示字符是数学符号,例如“+”或“=”。 |
|
Sc |
CurrencySymbol |
指示字符是货币符号。 |
|
Sk |
ModifierSymbol |
指示字符是修饰符符号,这指示环绕字符的修改。例如,分数斜线号指示其左侧的数字为分子,右侧的数字为分母。 |
|
So |
OtherSymbol |
指示字符是符号,但它不是数学符号、货币符号或修饰符符号。 |
|
Cn |
OtherNotAssigned |
指示字符未被分配给任何 Unicode 类别。 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律