


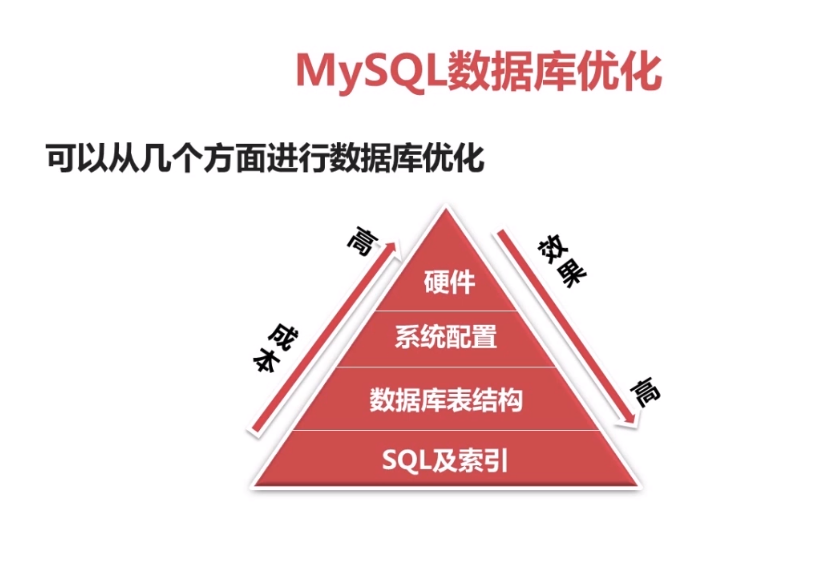
一,架构层面
1.做主从复制
2.实现读写分离
3.分库分表
二.系统层面
1.增加内存
2.硬盘使用固态硬盘SSD
3.给磁盘做raid0或者raid5以增加磁盘的读写速度
4.可以重新挂载磁盘,并加上noatime参数,这样可以减少磁盘的I/O
三.mysql本身的优化
1.如果未配置主从同步,可以把bin-log功能关闭,减少磁盘I/O
2.在my,cnf中加上skip-name-resolve这样可以避免由于解析主机名延迟造成mysql执行慢
3.调整几个关键的buffer和cache,调整的依据,主要根据数据库的状态来调整,如何调优可以参考5
四.应用层次
查看慢查询日志,根据慢查询日志优化程序中的SQL语句,比如增加索引
五。调整关键的buffer和cache
1.key_buffer_size
首先可以根据系统的内存大小设定它,大概的一个参数值:1G以下内存设定128M;2G/256M;4G/384;8G/1024;16G/2048.这个值可以通过检查状态值key_read_requests和key_reads,可以指定key_buffer_size设置是否合理,比例key_reads / key_read_requests应该尽可能的低,至少是1:100,1:1000更好()上述状态值可以使用:show status like ‘key_read%’ 来获得,注意:该参数设置的过大反而会使服务器整体效率降低
2.table_open_cache
打开一个表的时候,会临时把表里面的护具放到这部分内存中,一般设置成1024就够了,它的大小我们可以通过这样的方法来衡量:如果你发现open_table等于table_cache,并且opend_tables在不断增长,那么你就需要增加table_cache的值了(上述状态值可以使用SHOW STATUS LIKE 'oPen%tables'获得)注意,不能盲目地把table_cache设置成最大值,如果设置的太高,可能会造成文件描述不足,从而造成性能不稳定或者连接失败
3.sort_buffer_size
查询排序时所能使用的缓冲区大小,该参数对应的分配内存是每个连接独占,如果有100个连接,那么实际分配的总共缓冲区大小为100x4 = 400M,所以,对于内存在4G左右的服务器推荐配置为;4-8M
4.read_buffer_size
读查询操作所能使用的缓冲区大小,和sort_buffer-size一样,该参数对应的分配内存也是每个连接独享
5.join_buffer_size
联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享
6.myisam_sort_buffer_size
这个缓冲区主要用于修复表过程中排序索引使用的内存或者是建立索引时排序索引用到的内存大小,一般4G内存给64M即可
7.query_cache_size
mysql查询操作缓冲区的大小,通过以下做法调整:show status like ‘Qchche%’;如果Qcache_lowmem_prunes该参数记录有多少条查询内存不足而被移出查询内存,通过这个值,用户可以适当的调整缓存大小。如果该值非常大,则表明经常出现缓存不够的情况,需要增加缓存大小Qcache_free_memory;查询缓存的内存大小,通过这个参数可以很清晰的知道当前系统的查询内存是否够用,是多了,还是不够用,我们可以根据实际情况做出调整,一般情况下4G内存设置64M足够了
8.thread_cache_size
表示可以重新利用保存在缓存中线程的数,参考如下设置:1G->8;2G->16;3G->32;4G->64,除此之外,还有几个比较关键的参数
9.thread_concurrency
这个值可以设置为CPU核数的2倍即可
10.wait_timeout
表示空闲的连接超时时间,默认是:28800s,这个参数是和interactive_timeout一起使用的,也就是说要想让wait_timeout生效,必须同时设置interactive_timeout,建议它们两个都设置为10
11.max_connect_errors
是一个mysql中与安全有关的计数器值,它负责阻止过多尝试失败的客户端以防止暴力破解密码的情况,与性能并无太大关系,为了避免一些错误我们一般都设置比较大
12.max_connctions
最大的连接数,根据业务请求量适当调整,设置500足够
13.max_user_connections
是指同一个账号能够同时连接到mysql服务的最大连接数,设置为9表示不限制,通常我们设置为100足够
14.
最主要的是打开文件数,mysql数据库实际上是基于文件的,每查询一个
表都要打开一个文件,如果文件数达到限制,就文件无法打开,频繁的I/O操作
内存越大,对数据库的性能越好,但是CPU越多,并不见得对数据库造成更好得影响,因为mysql对cpu活泼得个数进行限制,并不会用到太多得核数,并不是说核数越多越好
IO磁盘等硬件并不能减少数据库锁得机制,虽然IO很快,但是并不能减少阻塞,所以硬件是成本最高,但是效果不一定最好的
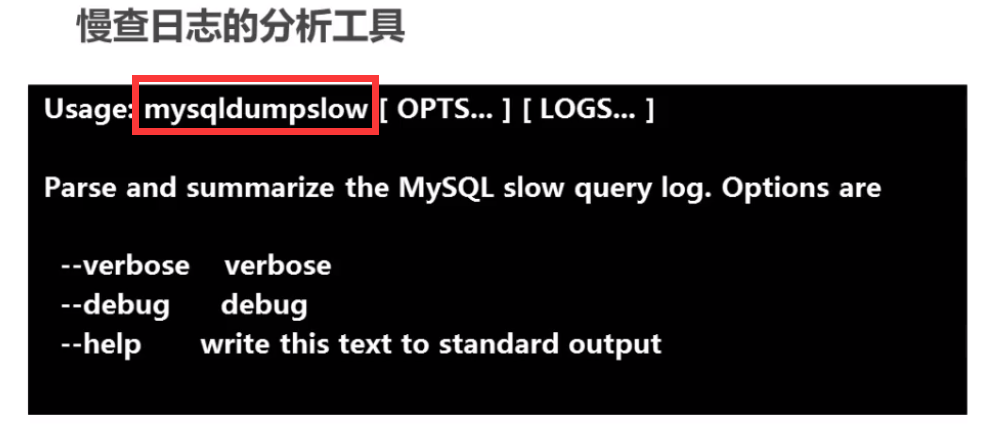
15.使用mysql慢查日志对有效率问题的SQL进行监控
show variables like 'slow_query_log'
指定慢查询日志的位置:
set global slow_quert_log_file='/home/mysql/sql_log/mysql-slow.log'
是否把没有使用索引的日志记录到慢查询日志当中:
set global log_queries_not_using_indexes = on
超过多少秒的记录大查询日志当中
set global long_query_time=0.01s
查看日志设置变量
show variables like ‘%log%’;
16.查看前50个慢查询日志
tail -50 /home/mysql/data/mysql-slow,log

17.
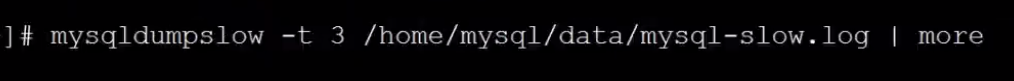
用more查看

18.慢查询工具:digest

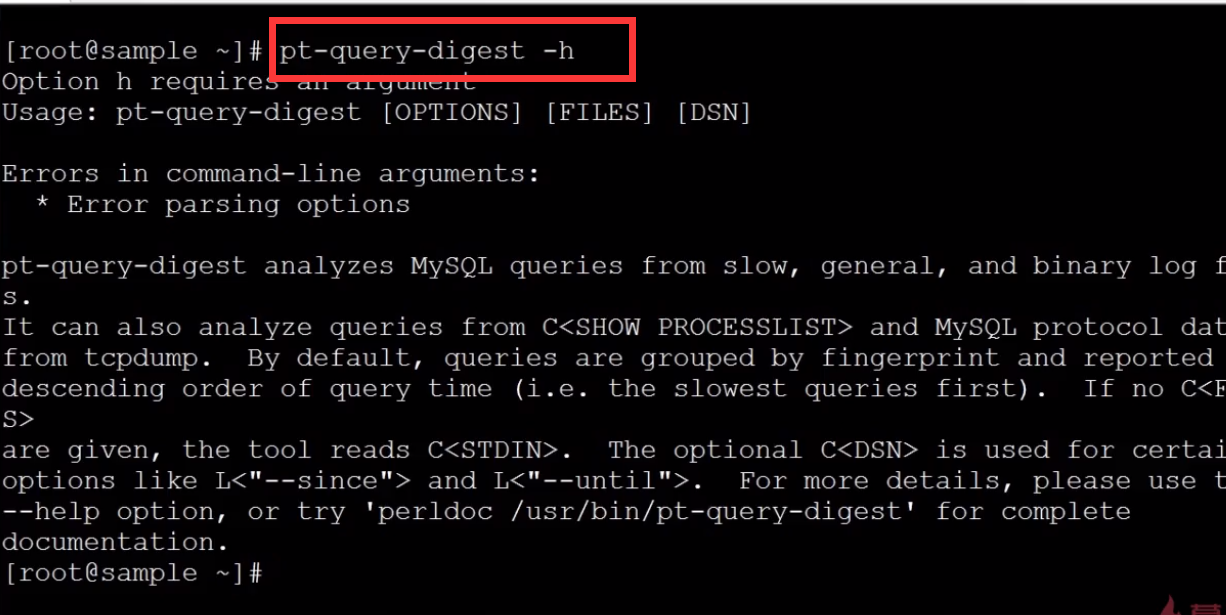
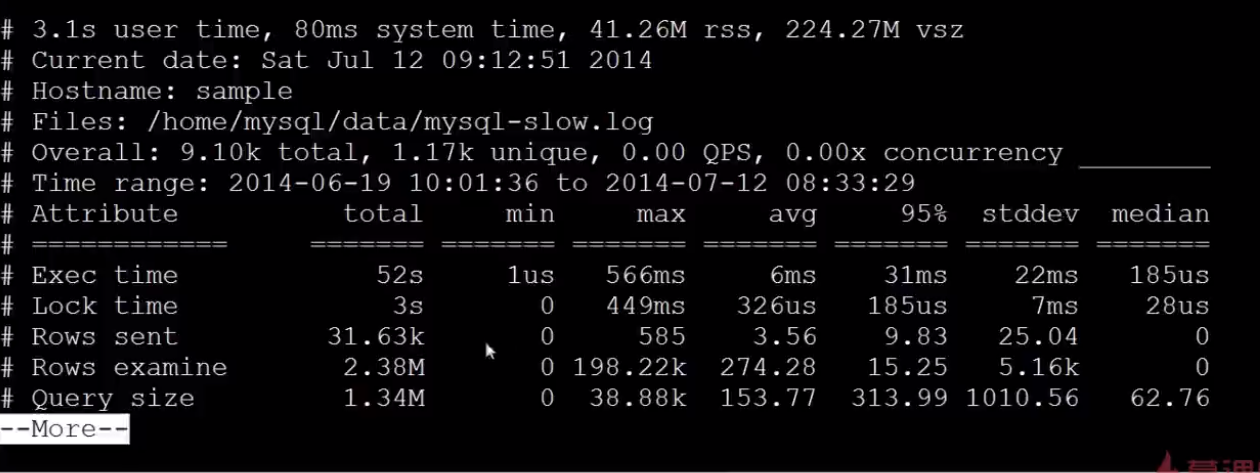
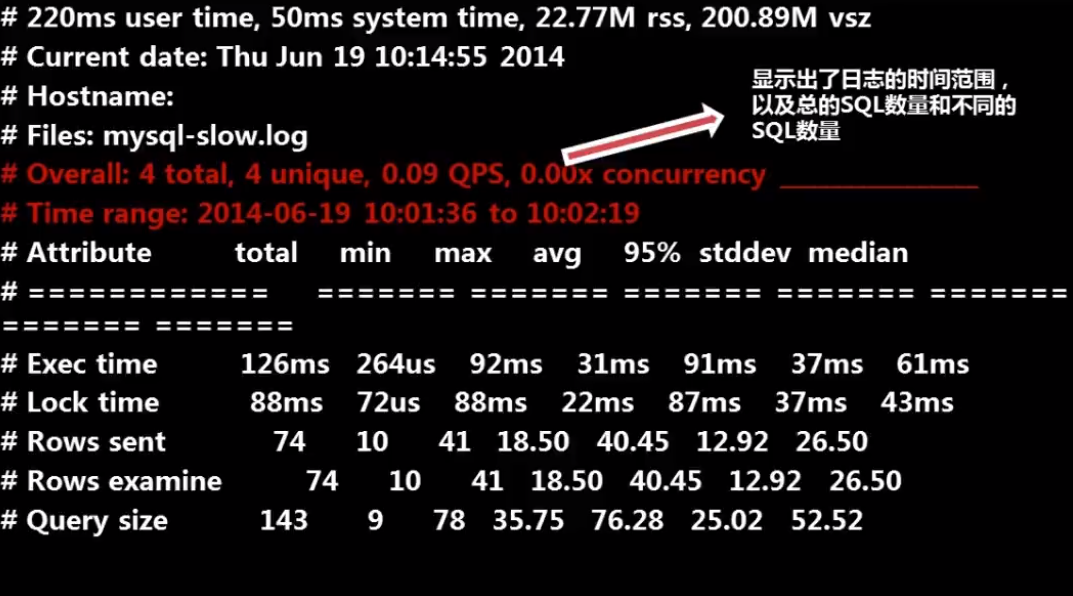

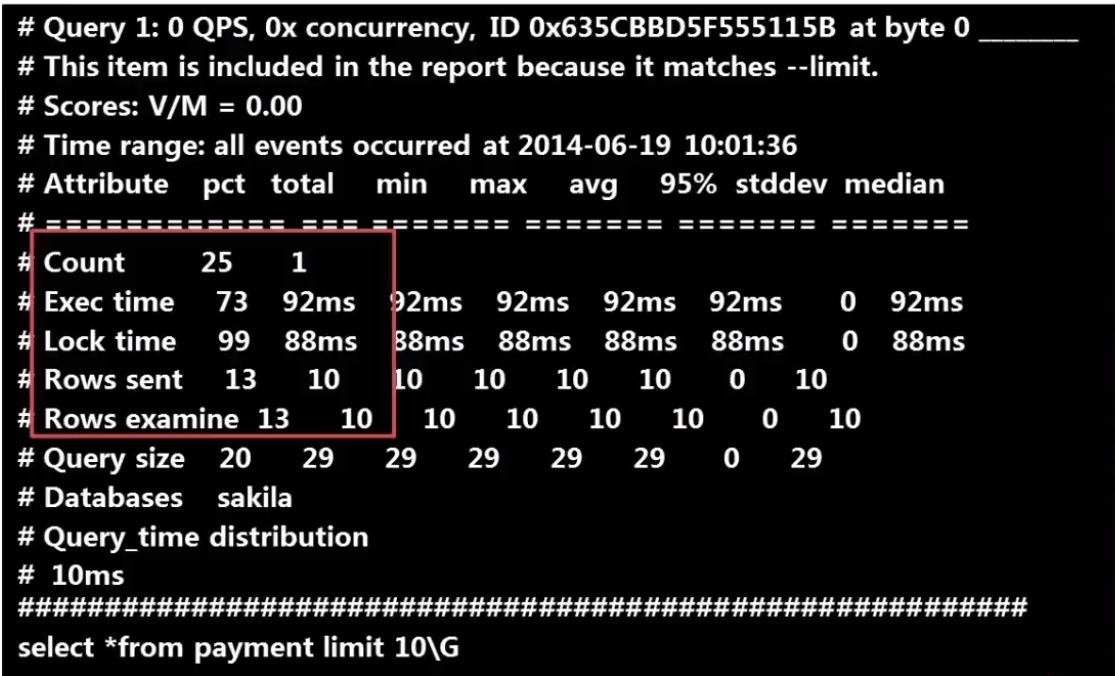


数据库的主要瓶颈是IO


索引是顺序排列的,通过索引的最大值即可知道MAX(字段)的值
count(*)和count(某一列)不一样,count(某一列)是计算不包含NULL的数量


查看mysql配置文件目录,如果存在多个位置存在配置文件,则后面的会覆盖前面的
分类:
mysql


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异