
Mysql索引底层数据结构
最近在学习mysql索引的一些底层数据结构;在这里做个备查。
msql索引帮助MySQL高效获取数据的排好序的数据结构;
我们平时碰到的数据结构可以用来存储索引的数据结构有---二叉树 红黑树 Hash表 B-Tree;
二叉树:在存放依次递增的索引的时候,会变成链表,这样如果查询最大的值,需要从头到尾查找n-1次,也就意味着要进行n-1次的磁盘I/O将数据从二叉树中依次取出来,与被比较的值进行比较;这样就完全发挥不出来二叉树的有点了;这种数据结构只适应大小随机的索引值。
红黑树:跟二叉树相比树的高度有所降低,分布也不是一条链表了,查找速度也比二叉树有了提高,但是每个节点只能存放一个索引,如果数据量特别大,那么树的高度也会比较高会是求log以2为底的结点数的对数下取整+1;
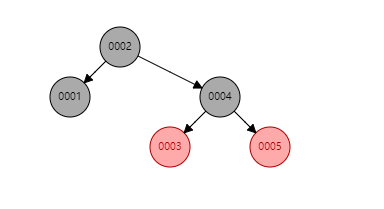
可以看到无论是二叉树还是红黑树,都有一个共同的缺点那就是每个节点只能存放一个索引,当数据量很大的时候会出现树的高度很高,查找数据会需要进行大量的i/o操作;不符合索引快速查找元素的要求;比较合适做索引的也就有hash和b-tree这两种数据结构了。但是b-tree并不适合范围查询,所以mysql就选择了B+TREE这种数据结构,并针对B+TREE进行了优化
b-tree:叶节点具有相同的深度,叶节点的指针为空;
所有索引元素不重复;
节点中的数据索引从左到右递增排列
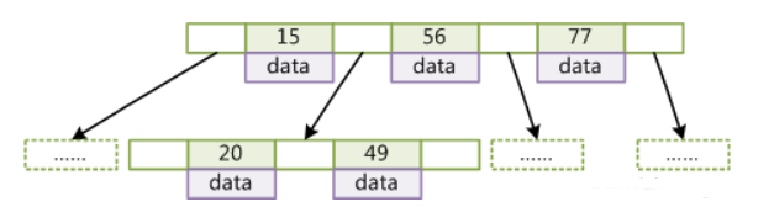
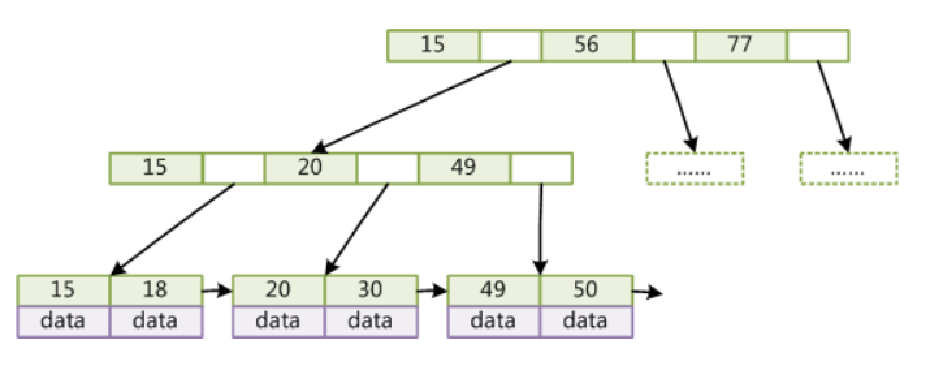
b+tree:
非叶子节点不存储data,只存储索引(冗余),可以放更多的索引;
叶子节点包含所有索引字段;
叶子节点用指针连接,提高区间访问的性能。
MySql的索引数据结构有Hash和B+TREE两种;
如果mysql的索引类型选择的是hash就会先对查询条件进行一次hash然后再去hash表中找对应,但是没法儿很好的支持范围查找、模糊查询、order by这些都支持不了;
适合表中只存在查找都是等值查找的情况,这种情形下HASH会比btree更快。
但是平时使用的场景中很少有等值查找,往往出来等值查找之外还有范围查找、模糊查找、order by这些所以采用B+TREE方式组织索引还是比较常见的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律