玩转 Pod 调度
玩转 Pod 调度
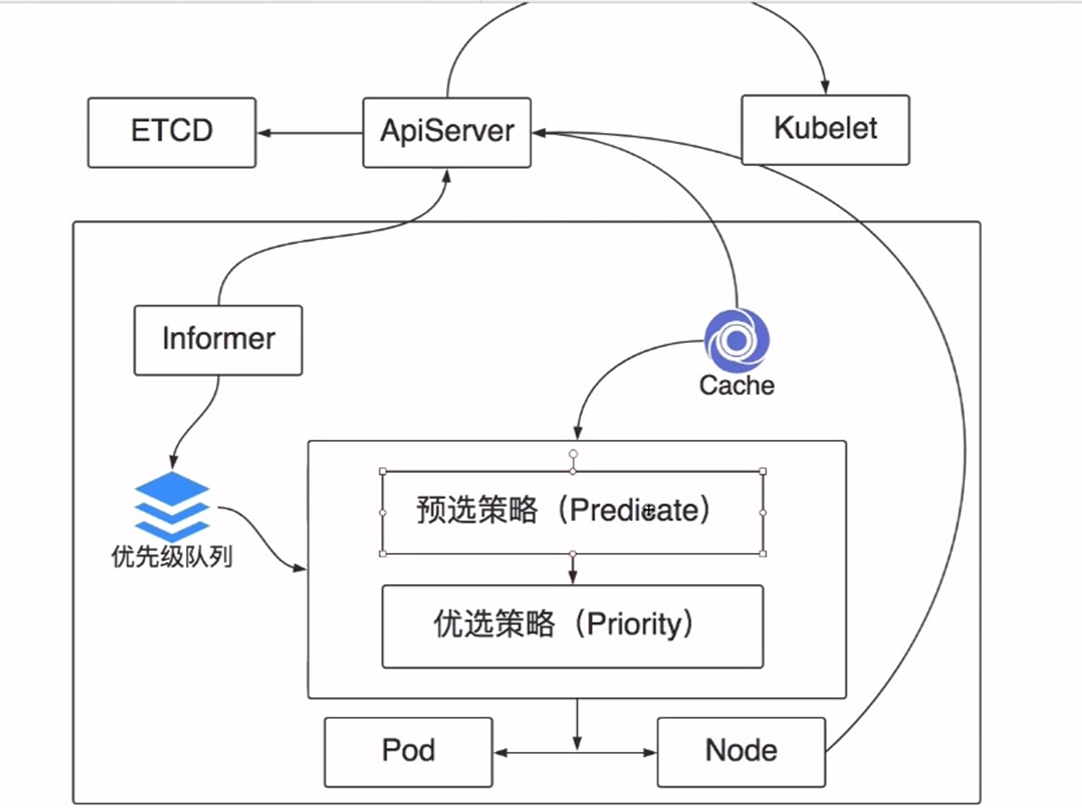
调度过程
首先需要知道调度哪个pod,pod的信息 pod的信息需要去优先级队列里拿.优先级队列用于存储等待调度的pod的信息,每个pod并不是对等,优先级高的需要提前调度.
informer会通用apiserver 去监听etcd的数据变化,如果发现有等待调度的pod,那就把pod的信息放到优先级队列中,然后informer的工作就完成了.然后循环开始工作.(新增的pod在刚刚创建的时候是没有nodeName的,只有在调度之后才会有.)
cache会从apiserver 拿到节点列表,以及节点的详细信息(cpu mem disk images pods),并缓存在cache中.
然后开始调度,调度一般分为两步,1 预选策略(predicate) 排除不满足要求的节点 剩余的资源满足要求,端口不冲突,vpc满足需要,node状态属于健康. 2 优选策略,对上述节点进行评分,选择最高分的node 成为最终调度的节点.
然后Pod和Node就建立一个绑定关系,并把信息告诉apiserver,然后apiserver就会去更新pod的nodename的字段.
然后指定node上的kubelet会把服务给调度起来
可以通过修改label,影响这个预选策略.
Deployment 或 RC :全自动调度
全自动调度
Deployment或RC的主要功能之一就是自动部署容器应用的多份副本,以及持续监控副本的数量,在集群内始终维护用户指定的副本数量。
1. kubectl create -f nginx-three-deployment.yaml
2. kubcelt get deployments
3. kubectl get rs
4. kubectl get pod
总结:
1.使用nginx-three-deployment.yaml文件创建一个deployment,还会创建一个ReplicaSet,这个ReplicaSet会创建3个Nginx应用的Pod。
2.从调度策略上来说,这3个Nginx Pod由系统全自动完成调度。他们各自最终运行在哪个节点上,完全由Master和Scheduler经过一系列算法计算得出,用户无法干预调度过程和结果。
什么是Replicaset?
ReplicaSet是下一代复本控制器。ReplicaSet和 Replication Controller之间的唯一区别是现在的选择器支持。Replication Controller只支持基于等式的selector(env=dev或environment!=qa),但ReplicaSet还支持新的,基于集合的selector(version in (v1.0, v2.0)或env notin (dev, qa))。在试用时官方推荐ReplicaSet。
虽然ReplicaSets可以独立使用,但是今天它主要被 Deployments 作为协调pod创建,删除和更新的机制。当您使用Deployments时,您不必担心管理他们创建的ReplicaSets。Deployments拥有并管理其ReplicaSets。
什么是Deployment?
Deployment为Pod和Replica Set(下一代Replication Controller)提供声明式更新。
你只需要在Deployment中描述你想要的目标状态是什么,Deployment controller就会帮你将Pod和Replica Set的实际状态改变到你的目标状态。你可以定义一个全新的Deployment,也可以创建一个新的替换旧的Deployment。
NodeSelector:定向调度
Kubernetes Master上的Scheduler服务(kube-scheduler进程)负责实现Pod的调度,整个调度过程通过执行一系列复杂的算法,最终为每个Pod都计算处一个最佳的目标节点,这一过程是自动完成的,通常我们无法知道Pod最终会被调度到哪个节点上。但在实际情况下,也可能需要将Pod调度到指定的一些Node上,可以通过Node的标签(Label)和Pod的nodeSelector属性相匹配,来达到这一目的。需要注意的是:如果集群中没有拥有该标签的Node,则这个Pod也无法被成功调度。
1.给node-2添加labels
[root@node-1 demo]# kubectl label node node-2 app=web
node/node-2 labeled
2.查看校验labels设置情况,node-2增加多了一个app=web的labels
[root@node-1 demo]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
node-1 Ready master 15d v1.15.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node-1,kubernetes.io/os=linux,node-role.kubernetes.io/master=
node-2 Ready <none> 15d v1.15.3 app=web,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node-2,kubernetes.io/os=linux
node-3 Ready <none> 15d v1.15.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node-3,kubernetes.io/os=linux
3.通过nodeSelector将pod调度到app=web所属的labels
[root@node-1 demo]# cat nginx-nodeselector.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-run-on-nodeselector
annotations:
kubernetes.io/description: "Running the Pod on specific node by nodeSelector"
spec:
containers:
- name: nginx-run-on-nodeselector
image: nginx:latest
ports:
- name: http-80-port
protocol: TCP
containerPort: 80
nodeSelector: #通过nodeSelector将pod调度到特定的labels
app: web
4.应用yaml文件生成pod
[root@node-1 demo]# kubectl apply -f nginx-nodeselector.yaml
pod/nginx-run-on-nodeselector created
5.检查验证pod的运行情况,已经运行在node-2节点
[root@node-1 demo]# kubectl get pods nginx-run-on-nodeselector -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-run-on-nodeselector 1/1 Running 0 51s 10.244.1.24 node-2 <none>
NodeAffinity:Node亲和性调度
NodeAffinity 意为 Node 亲和性的调度策略,适用于替换NodeSelector的全新调度策略。
IgnoredDuringExecution的意思是:如果一个Pod所在的节点在Pod运行期间标签发生了变更,不再符合该Pod的节点亲和性需求,则系统将忽略Node上Label的变化,该Pod能继续在该节点运行。
- RequiredDuringSchedulingIgnoredDuringExecution:依据强制的节点亲和性调度 Pod,相当于硬限制
pods/pod-nginx-required-affinity.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
这意味着 pod 只会被调度到具有 disktype=ssd 标签的节点上。
- PreferredDuringSchedulingIgnoredDuringExecution:使用首选的节点亲和性调度 Pod,相当于软限制
pods/pod-nginx-preferred-affinity.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
这意味着 pod 将首选具有 disktype=ssd 标签的节点。
从上面的配置中可以看到In操作符,NodeAffinity语法支持的操作符包括In、NotIng、Exists、DoesNotExist、Gt、Lt。虽然没有节点排斥功能,但是用NotIn和DoesNotExist就可以实现排斥的功能了。
PodAffinity:Pod亲和与互斥调度策略
Taints 和 Tolerations (污点和容忍)
概述
Node亲和性,详细参考这里,指pod的一种属性,以偏好或者硬性要求的方式指示将pod部署到相关的node集合中。Taints与此相反,允许node抵制某些pod的部署,注意taints是node的属性,affinity是pod的属性。
Taints与tolerations一起工作确保pod不会被调度到不合适的节点上。单个节点可以应用多个taint,node应该不接受无法容忍taint的pod调度。Toleration是pod的属性,允许(非强制)pod调度到taints相匹配的node上去。
Pod Priority Preemption:Pod优先级调度
DaemonSet:在每个Node上都调度一个Pod
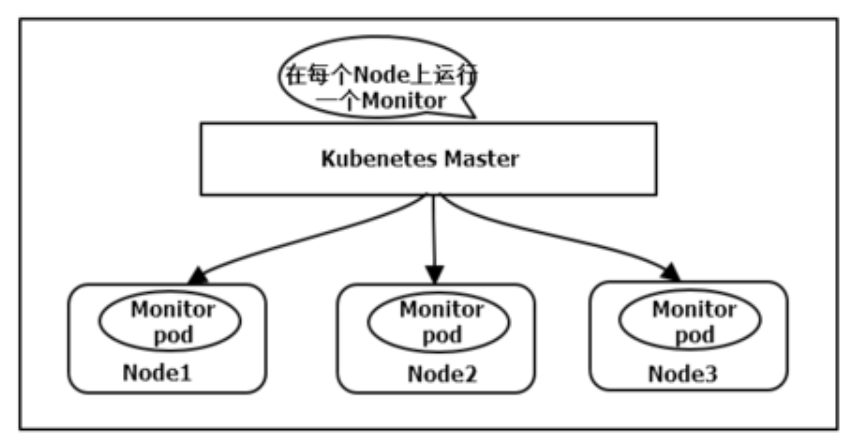
这种用法适合一些有下列需求的应用:
- 在每个Node上运行个以GlusterFS存储或者ceph存储的daemon进程
- 在每个Node上运行一个日志采集程序,例如fluentd或者logstach
- 在每个Node上运行一个健康程序,采集Node的性能数据。例如prometheus Node Exporter
DaemonSet的Pod调度策略类似于RC,除了使用系统内置的算法在每台Node上进行调度,也可以在Pod的定义中使用NodeSelector或NodeAffinity来指定满足条件的Node范围来进行调度。
NodeSelector NodeAffinity PodAffinity Pod驱逐

 浙公网安备 33010602011771号
浙公网安备 33010602011771号