一次老生代内存使用占比飙升问题解决
一次老生代内存使用占比飙升问题解决
老生代内存使用占比图示
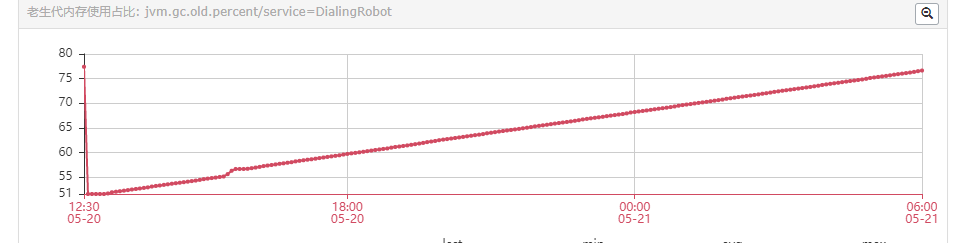
如图所示老生代内存占比不断增加,超过80%系统自动报警,之前的解决方案是手动重启😜。
1、保存现场
为了解决上面老生代问题,首先需要dump下堆文件
命令:
ps -ef|grep DialingRobot
DialingRobot是服务名称,找到对应的pid
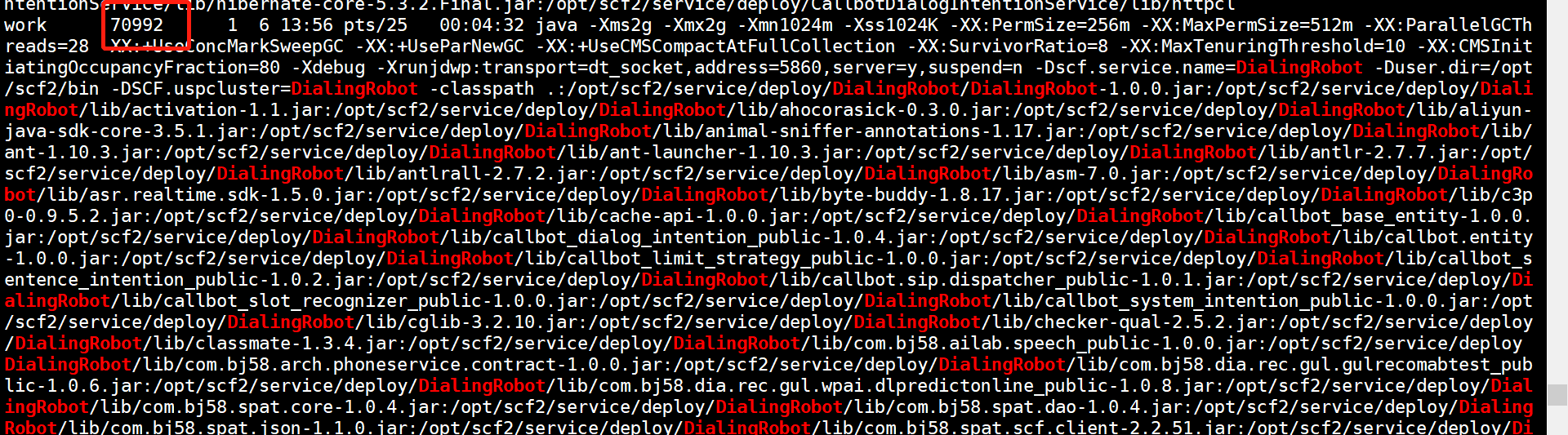
pid:70992
dump堆内存
jmap -dump:format=b,file=1.dump 70992
将堆内存dump下来
为了分析内存的变化,可以在不同的时间进行dump操作,可以分析前后的内存变化,更方便查找问题
2、分析问题
1、jprofiler分析dump文件
将文件重命名为20200520.hprof(.hprof是可以分析的堆文件)
打开后长这样
可以去看一下biggest对象
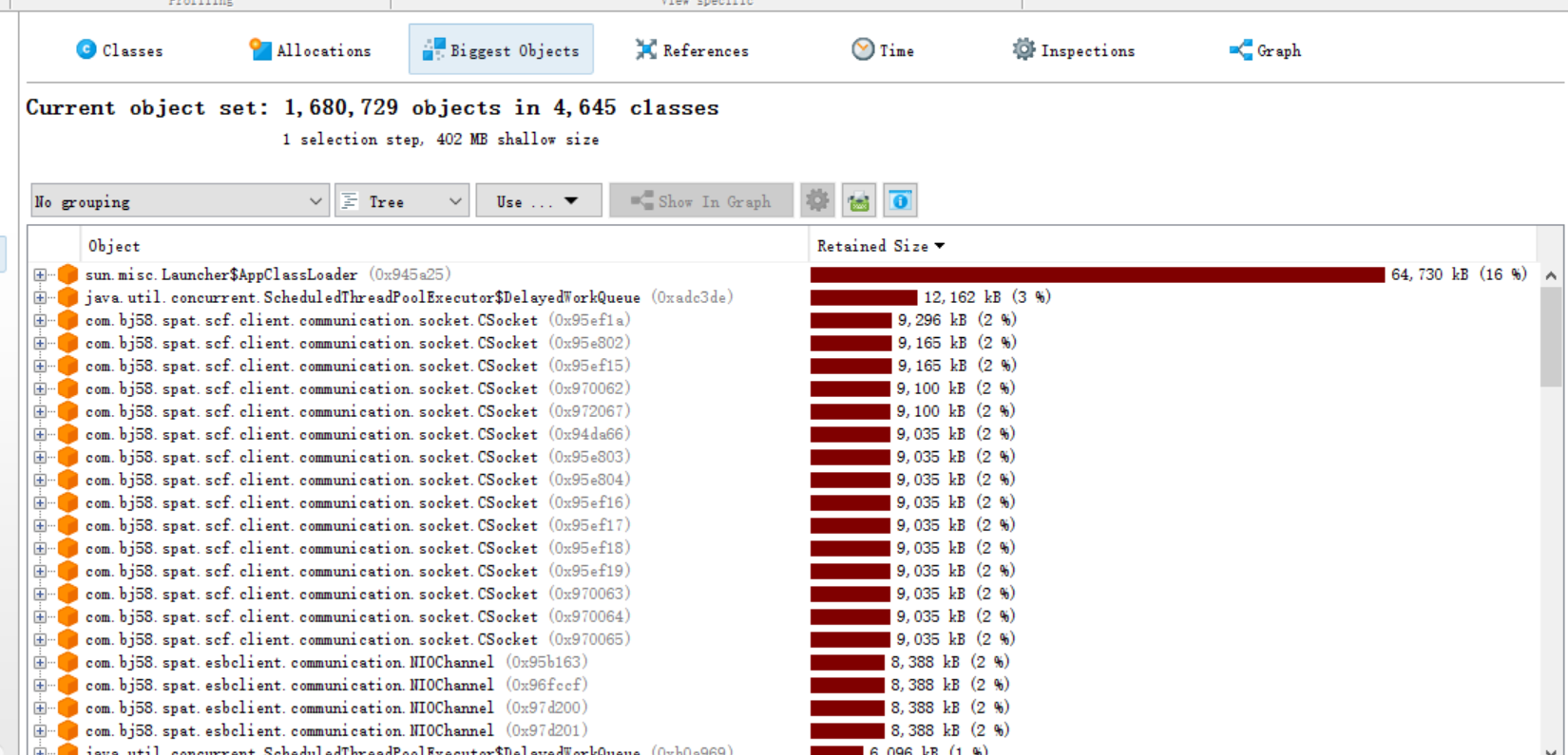
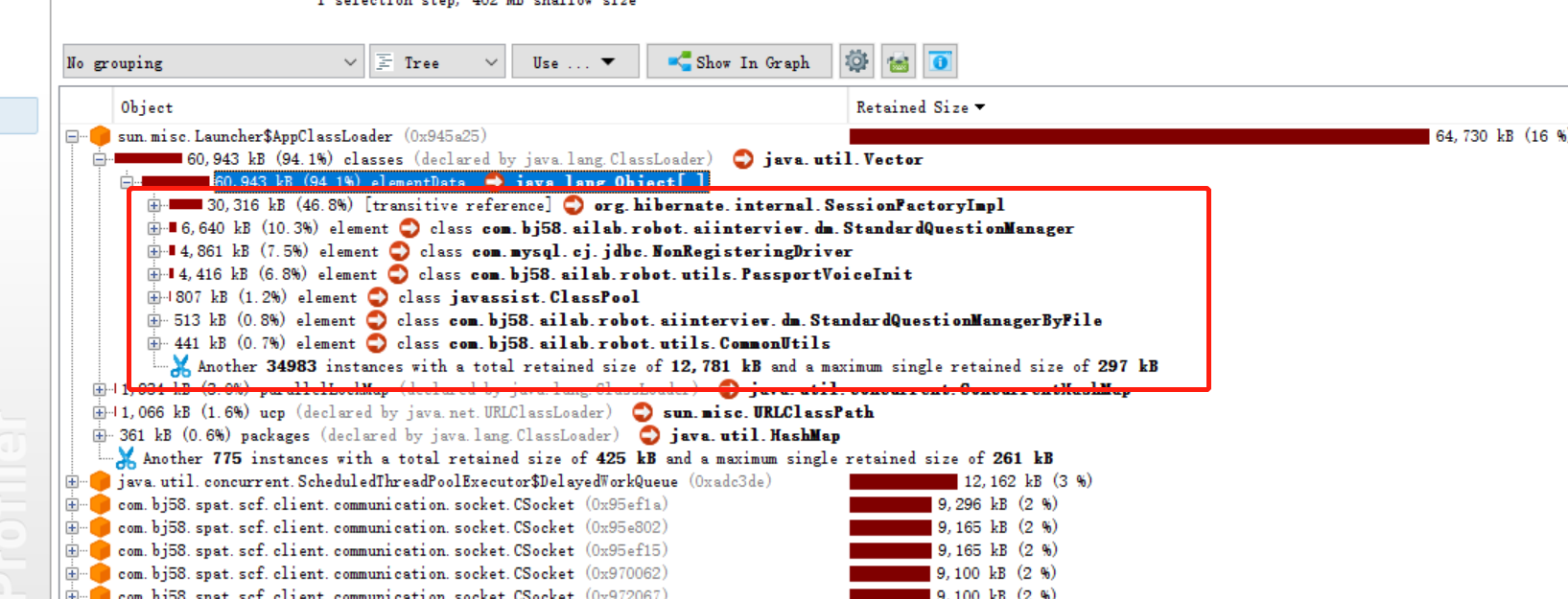
点开之后发现,占有内存比较大是正常的,这些类里面都存放着大量的内存缓存。
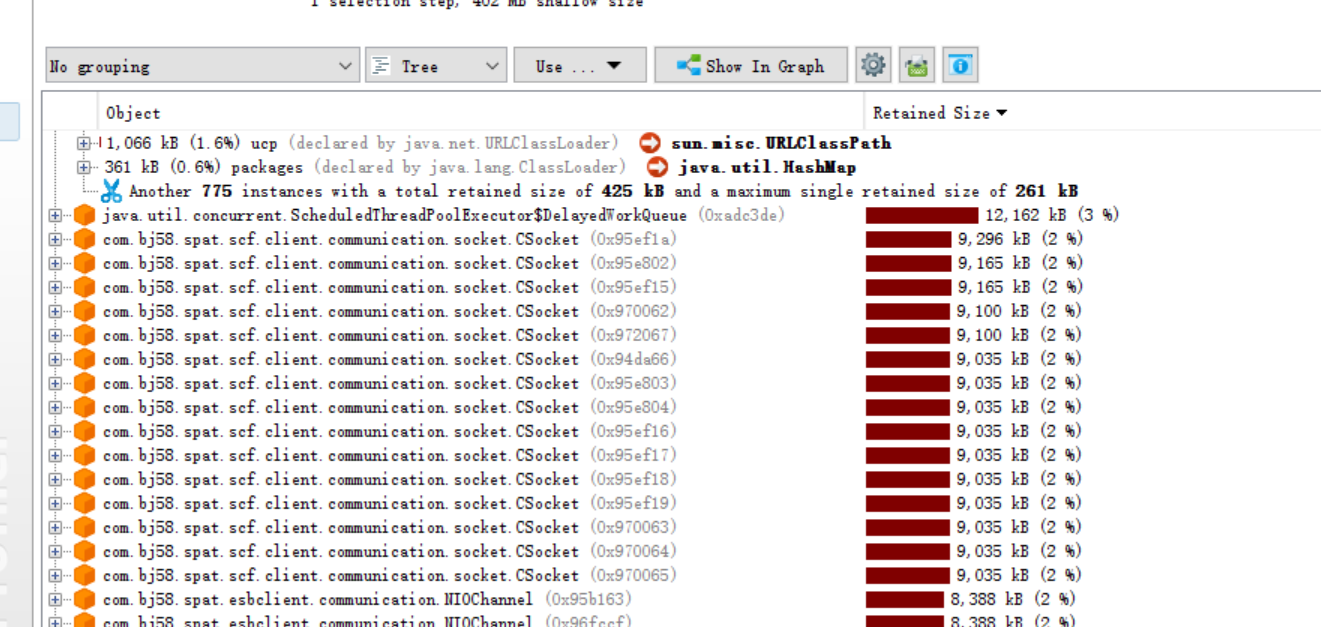
第二考虑是不是这个类太多了,没有释放,分析两个时间段的堆内存,两个dump中的这个对象的数量大小差异不大。尝试mat去分析下dump文件。
2、mat分析dump文件
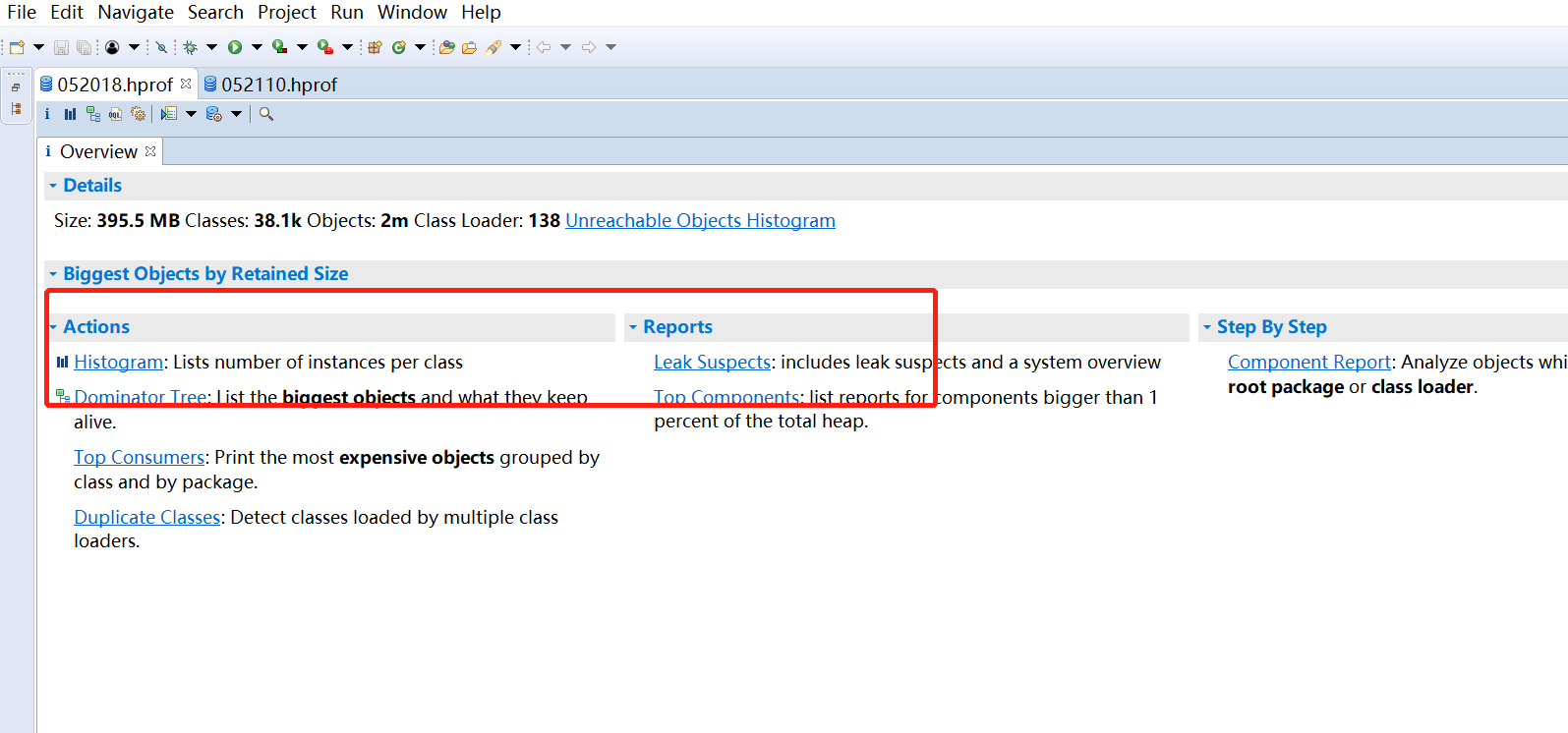
主要使用两个模块:Histogram和LeakSuspects
Histogram主要展示堆内的各个对象的大小
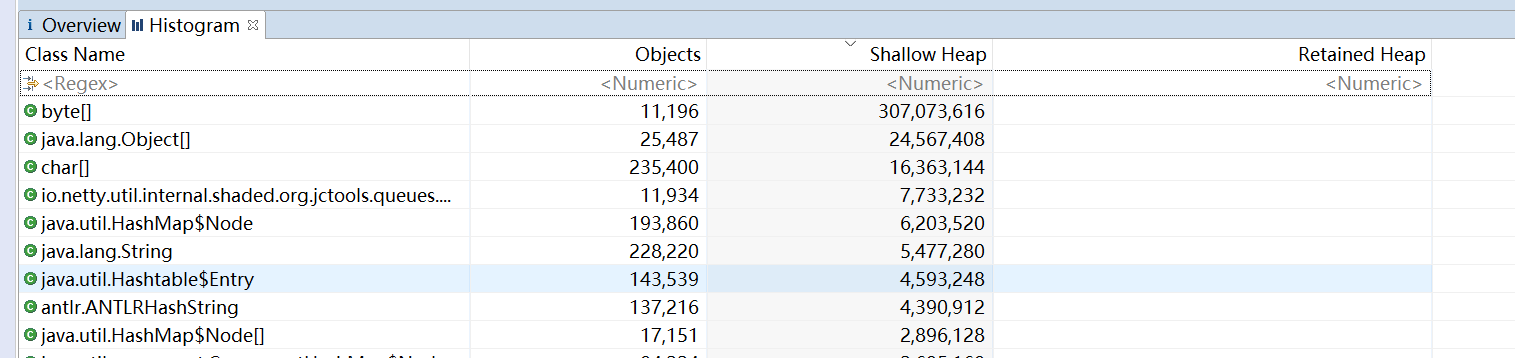
将两个hprof文件导入mat,可以使用比较去分析两个内存的前后的变化
两个hprof文件前后对象的差异、内存的差异
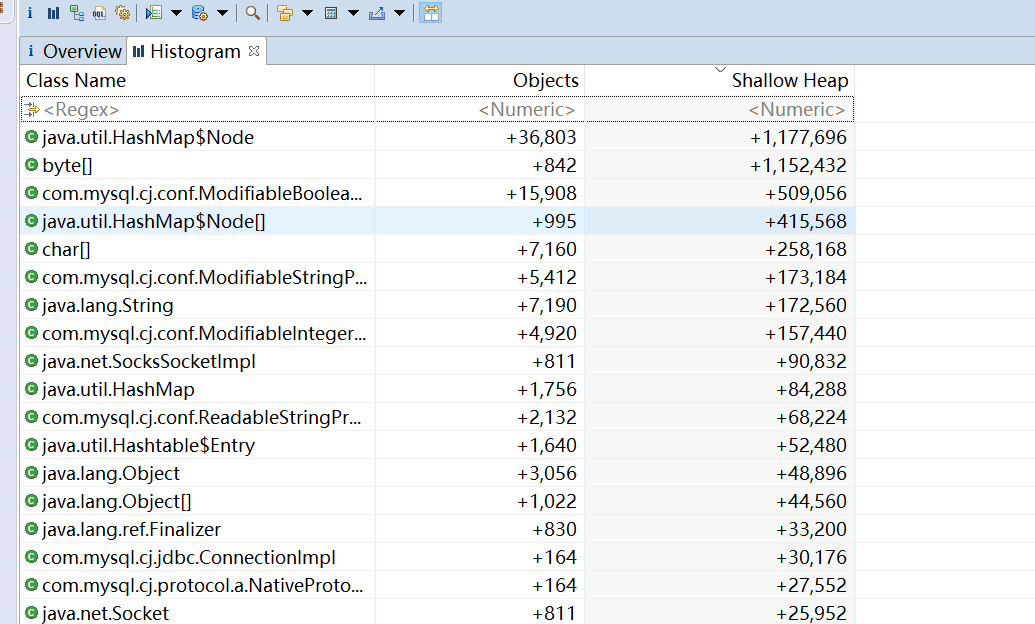
分析这些差异,没有看到什么有用的信息。
尝试使用第二个mat的工具:Leak Suspects
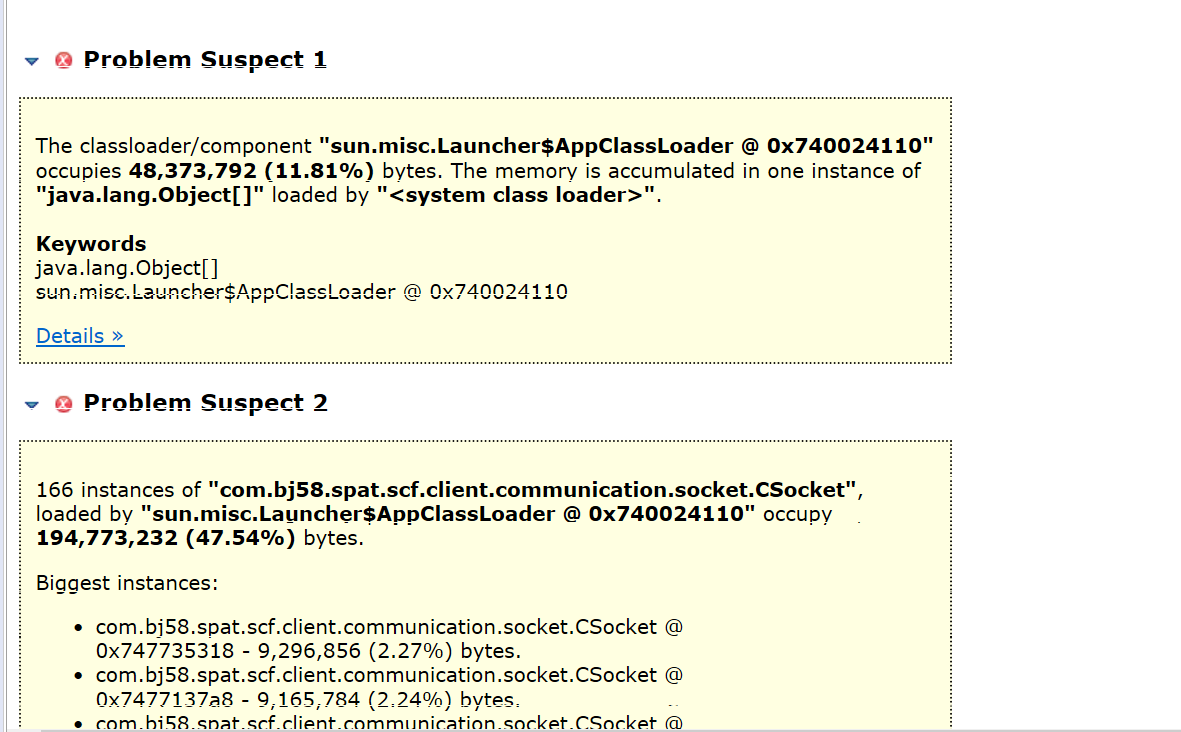
mat给出两个suspect,可以分析下,第一个还是之前的class文件过大,但是是由于内部维护了一部分缓存造成的,第二个cs csSocket也不是,跟JProfiler差异不大。
这个时候分析到达一个比较艰难的时候。
这个时候查看下jvm的参数设置:
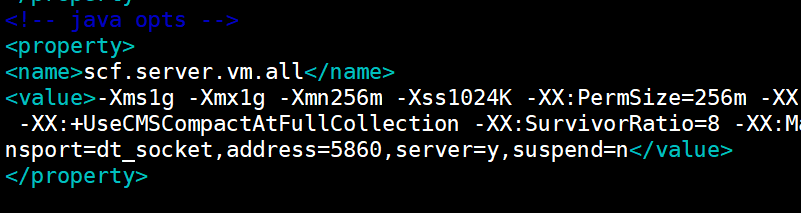
可以看出来整个堆的大小是:1g,新生代是256mb,老年代是1024-256=768mb,看上去没有什么问题。
这个时候需要分析我们的应用,我们的应用中的对象的特征,我们应用中的对象很少有需要一直存在的对象,更多是朝生夕死的对象,这样的话,这个的是不是有问题呢?
我们去看看新生代的内存、回收情况。
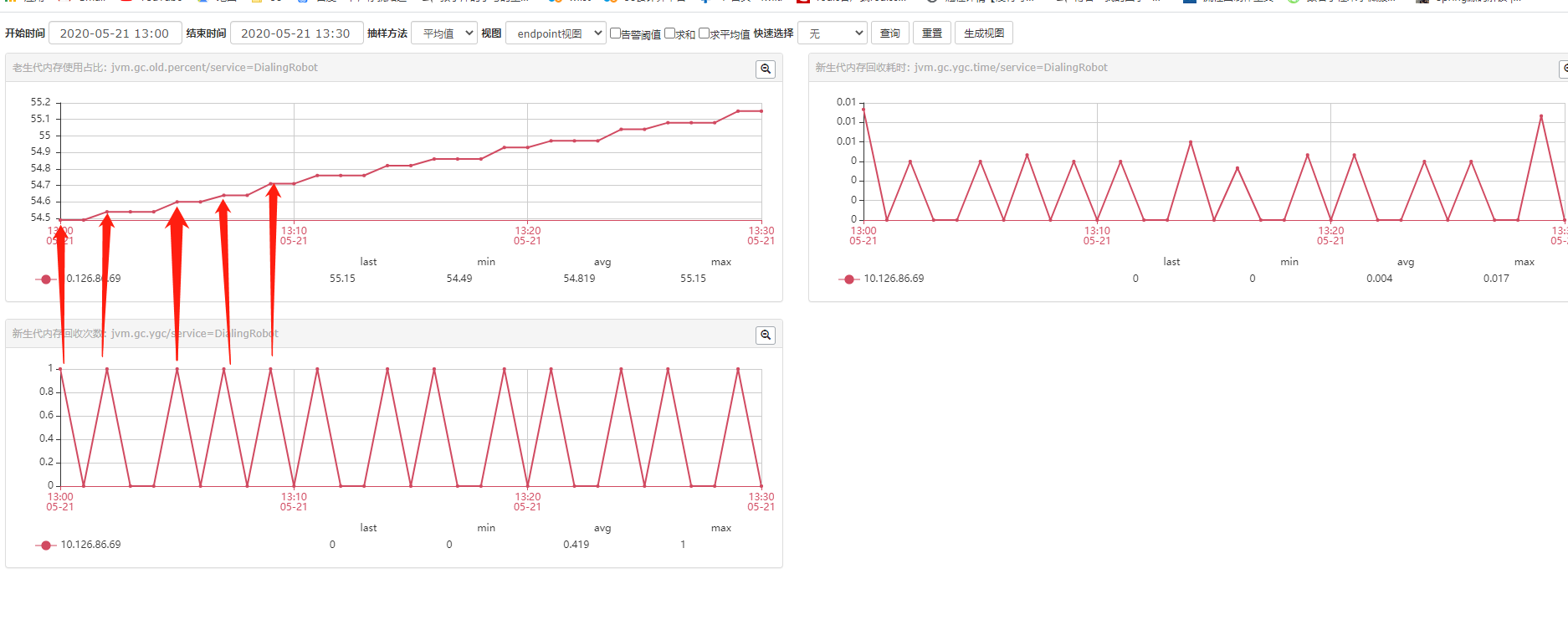
可以看出来,老生代内存使用率的增加和新生代的gc强相关,新生代gc一次,老生代的内存使用率升高一点
3、解决问题
修改jvm参数
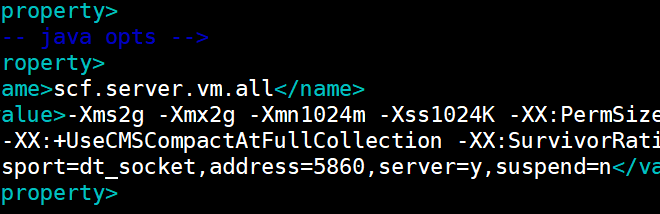
将堆内存从1g->2g,新生代256m->1024m,观察老生代情况。
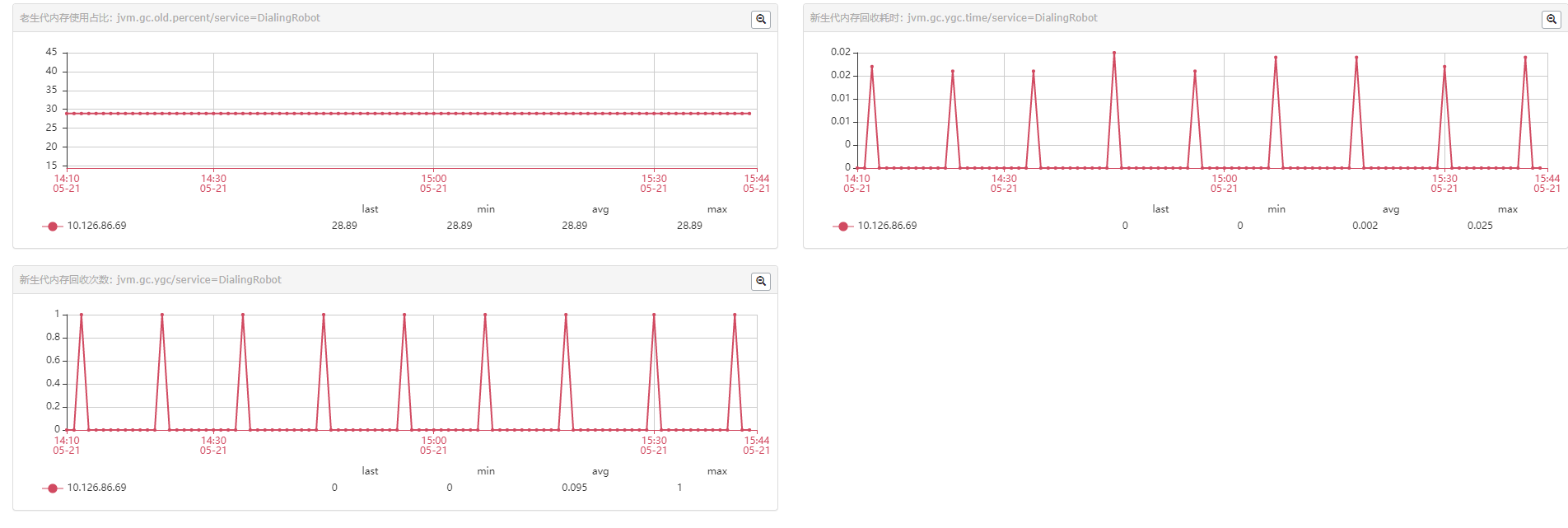
可以看出来:老生代内存使用占比稳定,新生代回收频率也降低了很多(13 -> 3 /30min),单次耗时:(10ms -> 20ms),30分钟内gc时间从130ms -> 60ms,降低了一倍
由此可见,服务中存在大量短期临时对象,扩容新生代空间后,Minor GC频率降低,对象在新生代得到充分回收,只有生命周期长的对象才进入老年代。这样老年代增速变慢,Major GC频率自然也会降低。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号