
Data-Stash数据导出分库分表、多活部署
分库分表
分库分表配置
system.db.sharding=false //是否进行分库分表
system.db.shardingNumberPerDatasource=0 //分表个数
//数据源连接,用户名,登录密码
system.db0.dbUrl=
system.db0.user=
system.db0.password=
原理
分库分表的方式分为垂直拆分和水平拆分,而数据仓库采用的是水平拆分即通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中。数据仓库根据配置的导出数据数据源个数确定分多少个库,根据配置shardingNumberPerDatasource确定每个库的每张表(block_task_pool,contract_info除外)有多少份,表的名称方式为表名+i(第几份)。数据仓库根据每张表的block_height字段(块高)进行分库分表,分库规则为block_height%数据库个数,分表规则为block_height%shardingNumberPerDatasource。即如果分两个库每个库每一张表有两份,区块高度为5的区块数据会被保存在第二个库的第二份表中,区块高度为6的区块数据会被保存在第一个库的第一份表中。
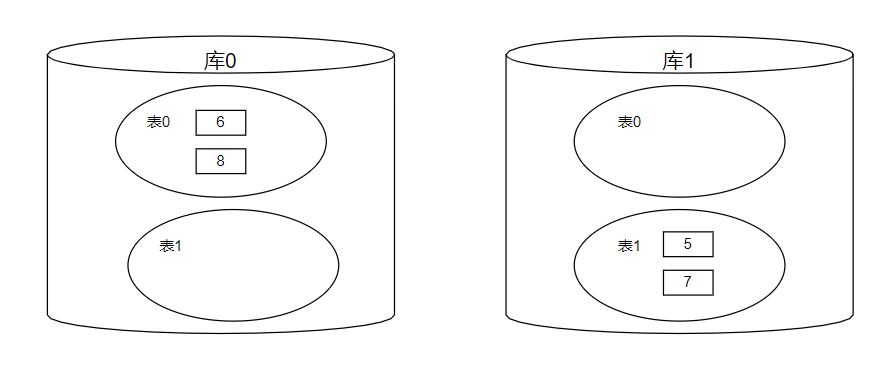
数据仓库使用sharding-jdbc来支撑分库分表增删改查功能。Sharding-JDBC尽量透明化水平分库分表所带来的影响,让使用方尽量像使用一个数据库一样使用水平分片之后的数据库集群,或者像使用一个数据表一样使用水平分片之后的数据表。
多活部署
多活部署配置
system.multiLiving=false // 启动多活开关
system.zookeeperServiceLists=IP:2181 // zk服务节点列表
system.zookeeperNamespace= //zk命名空间
system.prepareTaskJobCron= //任务准备job定时配置 ,主要用于读取当前区块链块高,将未抓取过的块高存储到数据库中
system.dataFlowJobCron= //任务分片执行job定时配置,主要用于执行区块下载任务
system.dataFlowJobItemParameters= //分片序列号和参数用等号分隔,多个键值对用逗号分隔,分片序列号从0开始,不可大于或等于作业分片总数
system.dataFlowJobShardingTotalCount= //任务分片数目
原理
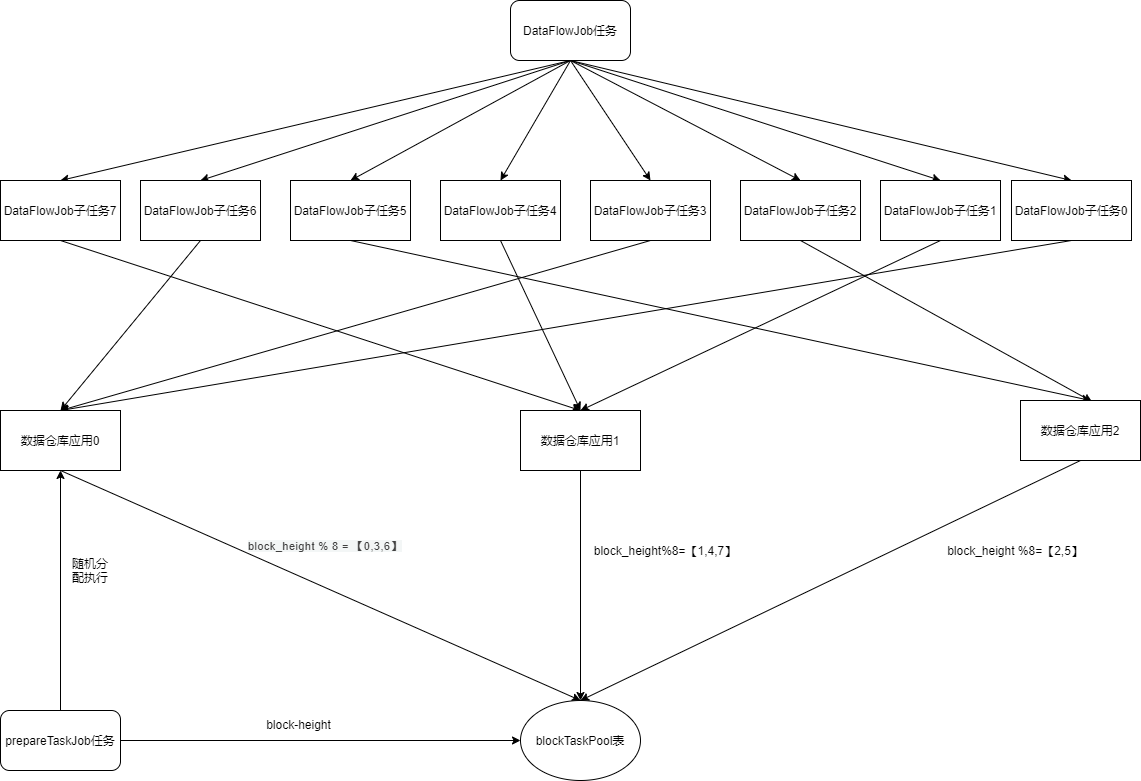
数据导出组件使用Elastic-Job来调配数据导出应用集群,保证集群只保存一份区块数据,而不是每一个数据导出应用都保存同一份区块数据。根据数据导出流程,数据导出组件数据导出流程分成了两个任务,一个任务是prepareTask任务即将要从节点或者数据仓库获取区块数据的区块高度保存到blockTaskPool表中,状态设为0(init状态)。另一个任务DataFlowJob任务即从blockTaskPool中获取init状态的区块高度,然后从节点或者数据仓库中获取区块数据、解析、然后保存从区块数据中解析出来的数据到数据库各个表中。
prepareTaskJob任务被配置为一次只能有一个数据仓库应用执行。DataFlowJob任务则根据dataFlowJobShardingTotalCount参数拆分为多个子任务,分发集群中各个数据导出应用完成。如dataFlowJobShardingTotalCount = 8,数据导出集群为3,那么按照平均分配的策略,数据导出应用0将分配到【0,3,6】子任务,数据导出应用1将分配到【1,4,7】子任务,数据导出应用2将分配到【2,5】子任务。那么对应到要处理的区块数据的区块高度分别是 block_height % 8 = 【0,3,6】归数据导出应用0,block_height%8=【1,4,7】归数据导出应用1,block_height %8=【2,5】归数据导出应用。当集群中新群或者下线数据导出应用,将会重新分配子任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号