雪花算法
 高并发场景下ID生成算法
高并发场景下ID生成算法
1.什么是雪花算法
在分布式系统中,生成全局唯一的ID是一个常见的需求。为了解决这个问题,Twitter提出了一种名为雪花算法(Snowflake)的解决方案。雪花算法通过一种巧妙的设计,能够在分布式系统中生成全局唯一的ID,且具有良好的性能和可伸缩性。
雪花算法的核心思想是利用64位的长整型数字作为全局唯一的ID。这64位数字被分为几个部分,分别表示不同的含义,以确保ID的全局唯一性和趋势递增性。
首先,我们来看一下雪花算法的组成部分:
最高位是符号位
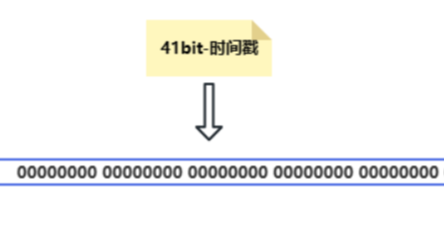
时间戳(41位):占据ID的最高位,用于记录ID生成的时间。由于时间戳是毫秒级的,因此可以保证在单个节点上生成的ID是递增的。同时,时间戳也起到了区分不同节点生成ID的作用。
工作机器ID(10位):包括5位的数据中心ID和5位的机器ID。这部分用于标识生成ID的节点,确保不同节点生成的ID不会冲突。
序列号(12位):用于记录同一毫秒内生成的ID序号。由于序列号部分有12位,因此可以在同一毫秒内生成4096个不同的ID。

2.雪花算法的优势
在我们单体项目的开发过程中,一般使用默认的自增ID,但是这种算法不适用于分布式系统的ID生成,因为我们要确保全局ID是唯一的。
另外一种常见的ID生成方式是使用UUID,但是UUID从整体上看不是自增的,在插入新数据时会有性能的损失。
第三种方法是采用系统当前的时间戳作为ID,但是这种方式不适用于高并发场景。

